【PyTorch模型评估】:选择最佳性能指标的策略指南
发布时间: 2024-12-11 12:15:53 阅读量: 16 订阅数: 12 

PyTorch模型评估全指南:技巧与最佳实践

# 1. PyTorch模型评估概述
在机器学习和深度学习领域中,模型评估是确保模型有效性的关键步骤。一个良好的评估流程可以帮助我们了解模型在未知数据上的表现,并指导我们进行模型的优化和调整。本章将介绍模型评估的目的和重要性,并探讨如何根据任务特点选择合适的性能指标。
## 模型评估的目的和重要性
模型评估不仅仅是为了验证模型的准确性,它还涉及对模型泛化能力的测试,确保模型不仅对训练数据表现良好,而且对未见过的数据也能够做出准确的预测。此外,评估过程可以帮助识别模型的不足,比如过拟合或欠拟合现象,从而为后续的模型改进提供方向。
## 性能指标的选择标准
在选择性能指标时,需要考虑多个因素。首先,指标应当与问题类型相匹配,如分类问题和回归问题各自有适用的指标。其次,指标应能够反映模型的核心性能,并且容易解释。最后,根据实际需求考虑指标的计算成本和实际意义,确保指标在实际应用中的可行性。接下来的章节将详细讲解不同类型的性能指标及其应用场景。
# 2. 基本性能指标的理论与实践
## 2.1 分类问题的性能指标
### 2.1.1 准确率(Accuracy)
在机器学习和数据挖掘领域,准确率是衡量模型预测效果最基本的指标之一。它直接描述了模型预测正确的样本数占总样本数的比例。准确率的数学表达式为:
\[ \text{Accuracy} = \frac{\text{Correct Predictions}}{\text{Total Predictions}} \]
在实际应用中,准确率虽然直观,但在数据不平衡的情况下可能会产生误导。例如,在一个数据集中,如果一个类别占了绝大多数,即使模型简单地将所有样本都预测为这个多数类,也能获得很高的准确率,但这并不意味着模型具有良好的泛化能力。
为了更全面地评估模型,通常会结合其他指标一起使用,例如精确率(Precision)和召回率(Recall)。
### 2.1.2 精确率(Precision)和召回率(Recall)
精确率和召回率是评估分类问题中模型性能的两个重要指标,它们从不同的角度衡量模型的表现。
- 精确率(Precision)衡量的是模型预测为正的样本中,有多少是真正的正样本。数学表达式为:
\[ \text{Precision} = \frac{\text{True Positives}}{\text{True Positives} + \text{False Positives}} \]
- 召回率(Recall)衡量的是模型实际为正的样本中,有多少被正确预测为正。数学表达式为:
\[ \text{Recall} = \frac{\text{True Positives}}{\text{True Positives} + \text{False Negatives}} \]
精确率和召回率之间的关系通常是此消彼长的。一个模型如果追求高精确率可能会牺牲召回率,反之亦然。为了平衡这两者之间的关系,引入了F1分数。
### 2.1.3 F1分数:精确率与召回率的调和平均
F1分数是精确率和召回率的调和平均数,它提供了一个单一的指标来衡量模型的性能,尤其在两者都很重要的情况下。其计算公式为:
\[ \text{F1 Score} = 2 \times \frac{\text{Precision} \times \text{Recall}}{\text{Precision} + \text{Recall}} \]
F1分数的值域在0到1之间,值越高表示模型的性能越好。当精确率和召回率都较高时,F1分数也会较高。
## 2.2 回归问题的性能指标
### 2.2.1 均方误差(MSE)和均方根误差(RMSE)
均方误差(Mean Squared Error, MSE)和均方根误差(Root Mean Squared Error, RMSE)是衡量回归模型预测性能常用的指标。MSE是预测值与实际值差的平方的平均值,数学表达式为:
\[ \text{MSE} = \frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2 \]
其中 \( y_i \) 是实际值,\( \hat{y}_i \) 是预测值,n是样本数量。MSE关注的是误差的平方,因此对大的误差会给予更多的惩罚。
RMSE是MSE的平方根,数学表达式为:
\[ \text{RMSE} = \sqrt{\text{MSE}} \]
RMSE与MSE的关系是,RMSE将误差回归到了原始的度量单位,便于解释。
### 2.2.2 平均绝对误差(MAE)
平均绝对误差(Mean Absolute Error, MAE)是另一个衡量回归模型性能的指标,它计算的是预测值与实际值差的绝对值的平均。MAE的数学表达式为:
\[ \text{MAE} = \frac{1}{n} \sum_{i=1}^{n} |y_i - \hat{y}_i| \]
MAE相对于MSE和RMSE而言,对异常值的敏感度较低,因为绝对值相较于平方在处理大误差时不会放大误差的影响。
### 2.2.3 决定系数(R^2)
决定系数(R-squared, R^2)是衡量回归模型拟合优度的一个指标,它衡量了模型对数据的解释能力。R^2的值域从0到1,值越接近1,表示模型解释的变异越多,拟合得越好。其数学表达式为:
\[ \text{R}^2 = 1 - \frac{\sum_{i=1}^{n} (y_i - \hat{y}_i)^2}{\sum_{i=1}^{n} (y_i - \bar{y})^2} \]
其中 \( \bar{y} \) 是实际值的均值。
## 2.3 概率评分指标
### 2.3.1 对数损失(Log Loss)
对数损失(Log Loss),也称为交叉熵损失,是衡量模型预测概率分布准确性的指标。对于二分类问题,其数学表达式为:
\[ \text{Log Loss} = -\frac{1}{N} \sum_{i=1}^{N} [y_i \log(p_i) + (1 - y_i) \log(1 - p_i)] \]
其中,\( y_i \) 是实际的类别标签(0或1),\( p_i \) 是模型预测样本为正类的概率。
Log Loss的值越低,说明模型预测的概率分布越接近实际的分布,因此模型性能越好。Log Loss对于概率预测的小概率预测错误惩罚较大,适合概率分类问题的性能评估。
### 2.3.2 AUC-ROC曲线
受试者工作特征曲线(Receiver Operating Characteristic, ROC)及其下的面积(Area Under Curve, AUC)是评估二分类模型性能的另一种方式。ROC曲线以假正例率(False Positive Rate, FPR)为横坐标,真正例率(True Positive Rate, TPR)为纵坐标,绘制出模型在不同阈值下的分类表现。AUC值反映了模型区分正负样本的能力,AUC值越接近1,模型性能越好。
```python
from sklearn.metrics import roc_curve, auc
import matplotlib.pyplot as plt
# 假设y_true为真实标签,y_score为模型预测的得分(概率)
fpr, tpr, thresholds = roc_curve(y_true, y_score)
roc_auc = auc(fpr, tpr)
plt.figure()
plt.plot(fpr, tpr, color='darkorange', lw=2, label='ROC curve (area = %0.2f)' % roc_auc)
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False P
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了使用PyTorch进行模型评估的具体方法和关键指标。它提供了对精确度、召回率和F1分数等7大性能指标的全面解析,并指导读者如何利用混淆矩阵来提升模型性能。专栏还介绍了PyTorch评估指标的实际应用,帮助读者掌握深度学习模型评估的最佳实践。通过了解这些指标和方法,读者可以有效评估和优化其PyTorch模型,从而提升其性能和可靠性。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【PCB设计黄金法则】:JESD22-B116B规范影响下的创新设计策略
参考资源链接:[【最新版可复制文字】 JESD22-B116B.pdf](https://wenku.csdn.net/doc/2y9n9qwdiv?spm=1055.2635.3001.10343)
# 1. JESD22-B116B规范概述
## 1.1 JESD22-B116B的历史地位与影响
JESD22-B1
PSS_E脚本自动化:提升工作效率的终极武器
参考资源链接:[PSS/E程序操作手册(中文)](https://wenku.csdn.net/doc/6401acfbcce7214c316eddb5?spm=1055.2635.3001.10343)
# 1. PSS_E脚本自动化概览
在现代IT运维管理中,自动化技术是提升效率、降低人为错误的重要手段。PSS_E脚本作为一种自动化工具,它将复杂的运维任务简化为可执行的脚本,使得重复性工作自动
GS+高级功能解锁:5个技巧提升你的数据分析效率

参考资源链接:[GS+软件入门教程:地统计学分析详解](https://wenku.csdn.net/doc/5x96ur27gx?spm=1055.2635.3001.10343)
# 1. GS+软件概述与界面介绍
## 1.1 GS+软件功能概述
GS+软件是一
全志F133+JD9365液晶屏驱动优化技巧:提升显示性能的有效方法

参考资源链接:[全志F133+JD9365液晶屏驱动配置操作流程](https://wenku.csdn.net/doc/1fev68987w?spm=1055.2635.3001.10343)
# 1. 全志F133+JD9365液晶屏驱动概述
在信息时代,显示技术的进步为用户带来了更丰富、更直观的交互体验。全志F133处理器与JD9365液晶屏的结合,为嵌入式系统领域提供了强大的显示解决方案。本章将从液
【C语言字符串处理秘籍】:解析与优化用户交互

参考资源链接:[编写一个支持基本运算的简单计算器C程序](https://wenku.csdn.net/doc/4d7dvec7kx?spm=1055.2635.3001.10343)
# 1. C语言字符串处理基础
字符串在C语言中扮演着不可或缺的角色,从基本的字符串声明到复杂的数据结构处理,它为开发者提供了强大的数据操作能力。本章将为您介绍C语言中字符串处理的基础
【UDS协议入门到精通】:IT专家的汽车诊断接口技术全景

参考资源链接:[UDS诊断协议ISO14229中文版:汽车总线诊断标准解析](https://wenku.csdn.net/doc/6401abcecce7214c316e992c?spm=1055.2635.3001.10343)
# 1. UDS协议概述与历史背景
## 1.1 UDS协议的起源与发展
统一诊断服务(UDS
【数据仓库架构理解】:云服务背后的技术原理及优化策略
参考资源链接:[LMS Virtual.Lab 13.6 安装教程:关闭安全软件与启动证书服务](https://wenku.csdn.net/doc/29juxzo4p6?spm=1055.2635.3001.10343)
# 1. 数据仓库架构概览
数据仓库作为现代企业决策支持系统的核心,扮演着不可或缺的角色。它不是一个单一的技术或产品,而是一个综合系统,包括数据的整
BCH码在数据存储中的应用案例:4个实战技巧助你提升性能
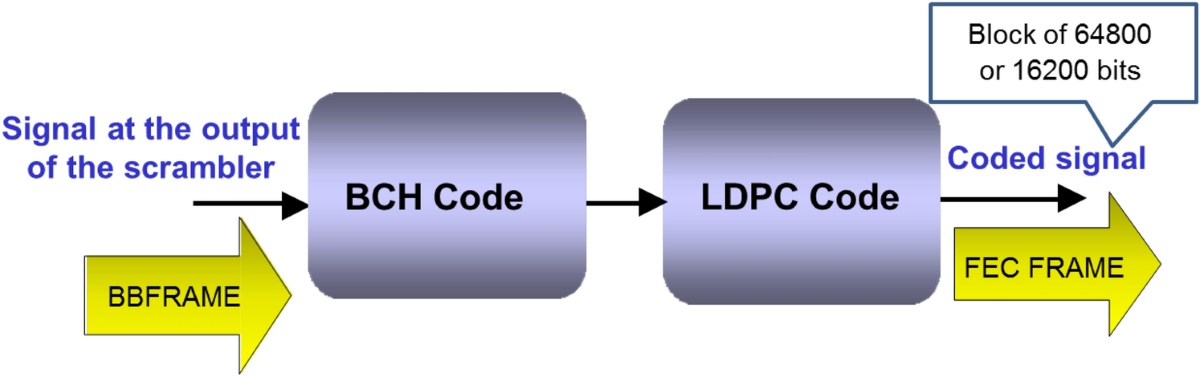
参考资源链接:[BCH码编解码原理详解:线性循环码构造与多项式表示](https://wenku.csdn.net/doc/832aeg621s?spm=1055.2635.3001.10343)
# 1. BCH码基础知识与原理
BCH码(Bose
PowerBuilder错误处理与调试技巧:掌握调试艺术,优化代码质量
参考资源链接:[PowerBuilder6.0/6.5基础教程:入门到精通](https://wenku.csdn.net/doc/6401abbfcce7214c316e959e?spm=1055.2635.3001.10343)
# 1. PowerBuilder错误处理概述
在现代软件开发过程中,错误处理是一项至关重要的环节,它直接影响程序的健壮性和用户的体验
【掌握Python包管理】:Anaconda包管理器与conda命令详解
参考资源链接:[图文详述:Anaconda for Python的高效安装教程](https://wenku.csdn.net/doc/5cnjdkbbt6?spm=1055.2635.3001.10343)
# 1. Python包管理概述
在当今数据驱动的时代,Python已经成为了科学计
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )