深入揭秘:C++ std::any类型安全容器的工作原理
发布时间: 2024-10-22 17:50:31 阅读量: 46 订阅数: 31 

C++ 容器大比拼:std::array与std::vector深度解析

# 1. C++ std::any类型概述
C++中的`std::any`类型是从C++17标准开始提供的一个类型安全的任意类型容器。它可以存储任意类型的对象,而不需要在编译时知道对象的具体类型,且保持类型信息直到真正需要使用该值时。这种能力在多种场景中非常有用,比如,当你需要处理多种不同类型的集合,或者实现一个能够接受不同类型参数的接口时。`std::any`是通过类型擦除技术实现的,这意味着它可以隐藏并保护存储对象的具体类型信息,只提供一个统一的接口供使用者操作,从而提高了代码的灵活性和通用性。本章将初步介绍`std::any`的功能和特性,并简要探讨其在C++程序中的基本应用方式。
# 2. std::any类型的核心机制
## 2.1 类型擦除技术
### 2.1.1 类型擦除的基本原理
类型擦除是C++中一种常见的技术,它允许我们使用同一接口处理多种类型,而不需要在编译时知道具体的类型信息。这种技术的关键在于隐藏类型信息,同时提供统一的操作接口。类型擦除可以通过模板、虚函数或联合体实现,而`std::any`采用的是模板技术。
在`std::any`的上下文中,类型擦除使得`std::any`可以存储任何类型的值,但是调用者在访问存储的值时不需要知道具体是什么类型。通过一系列统一的接口,`std::any`能够实现类型安全的存储、查询、访问等操作。类型擦除后的结果是一种泛型容器,它能够确保类型安全,同时避免了传统继承关系中出现的多重继承的复杂性。
### 2.1.2 在std::any中的应用分析
`std::any`中的类型擦除使得它能够将存储的值封装成一个"匿名"类型。当值被存储到`std::any`时,它就失去了原有的类型信息,只留下一个可以识别的"任何类型"。这个过程不仅隐藏了存储值的类型信息,同时也保证了运行时类型安全。
在`std::any`的实现中,类型擦除依赖于`std::aligned_storage`,这是一个允许存储任意类型数据的底层存储机制。`std::any`类内部维护了一个`std::aligned_storage`实例,并在其中存储实际的数据对象。为了提供类型安全的操作,`std::any`还维护了一个类型信息,这个类型信息在对象创建时由模板参数推导得到,但在运行时是不可见的。
为了实现类型安全访问,`std::any`提供了一种类型检查机制,通过`std::type_info`来检查存储值的类型。这种机制允许`std::any`在保持类型擦除的同时,提供安全的类型转换和访问功能。
## 2.2 存储机制
### 2.2.1 内部存储模型的设计
`std::any`的内部存储模型是实现其功能的关键部分。它需要足够灵活以存储任何类型的值,同时还要能够维护类型信息,以便在需要时能够安全地访问和操作这些值。为了达到这些要求,`std::any`利用了C++的类型系统和内存管理特性。
`std::any`的内部存储通常通过模板和联合体实现。模板允许`std::any`在编译时推导出存储对象的类型信息,而联合体则提供了一个共享内存区域,用于存储不同类型的值。联合体的每个成员可以存储一个潜在的类型,但是同一时间只有一个成员被激活。这样,`std::any`就能够动态地存储任何类型的数据,而不需要为每种可能的类型都分配额外的内存空间。
为了跟踪当前存储的类型,`std::any`类还包含了一个类型标识信息,它在存储值时记录下当前的类型,然后在访问时进行核对。这允许`std::any`提供类型安全的操作,而不会牺牲封装和抽象的原则。
### 2.2.2 存储动态类型信息的方法
在`std::any`中,动态类型信息是通过`std::type_info`对象来存储和管理的。当一个值被存储到`std::any`中时,其类型信息会被捕获,并存储在内部的一个`std::type_info`对象中。这个对象记录了值的类型信息,并在之后的类型检查中起到关键作用。
`std::type_info`是C++标准库中提供的一个类,它封装了关于类型的静态信息。通过`typeid`操作符可以获得一个对象的`std::type_info`实例。`std::any`利用这个特性,将存储值的类型信息保存为`std::type_info`对象的一个实例。当需要进行类型安全的操作时,如检查存储值的类型或安全转换,`std::any`通过与`std::type_info`对象的比较来执行。
这种使用`std::type_info`的方法保证了类型的动态信息得以保留和查询,即使在编译时我们并不知道具体是什么类型。这样`std::any`就能够提供如`has_value()`和`type()`这样的方法,前者检查是否有值被存储,后者则可以返回存储值的类型信息。
## 2.3 类型安全与异常处理
### 2.3.1 类型安全的保证机制
类型安全是指程序在运行时不会出现类型相关的错误。`std::any`提供了一种机制来确保类型安全,即便它可以存储任意类型的值。这种机制依赖于编译时的类型信息和运行时的类型检查。
`std::any`内部使用`std::type_info`记录了存储值的类型信息,并且所有对值的访问都是通过类型安全的接口进行。这意味着在尝试访问或转换存储在`std::any`中的值时,必须使用`std::any_cast`,它会执行运行时类型检查。如果类型匹配,`std::any_cast`将返回正确的类型;如果不匹配,则抛出一个`std::bad_any_cast`异常。这种检查机制确保了只有在类型确实匹配的情况下,才会允许转换。
此外,`std::any`的操作(如`has_value()`或`type()`)都提供了类型安全的保证。它们允许查询和操作`std::any`对象中的值,而不会导致未定义行为,从而避免了类型安全的潜在问题。
### 2.3.2 异常处理的策略和实例
在C++中,异常处理是一种常见的错误处理机制。`std::any`为了保持类型安全,利用了异常机制来处理错误情况。特别是当类型转换失败时,`std::any`会抛出`std::bad_any_cast`异常。这允许调用者捕捉并处理这种错误情况,而不是让程序崩溃。
例如,考虑以下代码:
```cpp
#include <any>
#include <iostream>
#include <typeinfo>
int main() {
std::any obj = 42;
try {
auto& value = std::any_cast<int&>(obj);
std::cout << "Value is: " << value << std::endl;
} catch (const std::bad_any_cast& e) {
std::cout << "Exception occurred: " << e.what() << std::endl;
}
return 0;
}
```
在上面的代码中,我们尝试将`std::any`对象`obj`转换为一个`int`的引用。如果`obj`实际上存储的是一个不同的类型,`std::any_cast`将会抛出`std::bad_any_cast`异常。这个异常被捕捉并处理,避免了程序的非正常终止。
异常处理策略不仅保护了程序的稳定运行,还提高了用户体验。通过异常,`std::any`允许开发者在类型转换失败时得到明确的反馈,这使得调试和错误处理变得更加容易。
# 3. std::any的接口和使用方法
### 3.1 构造和赋值操作
std::any作为C++17标准库中引入的一个类型,允许存储任意类型的值。它提供了一种类型安全的方式,以存储不共享公共基类或接口的不同类型的对象。
#### 3.1.1 构造std::any对象的方法
std::any类型支持多种构造函数,允许从不同类型的值构造出一个std::any对象。根据C++标准,std::any可以使用值、const引用、非const引用以及std::in_place_type等方式进行构造:
```cpp
#include <any>
#include <string>
#include <iostream>
int main() {
// 从值构造
std::any a1 = 123;
// 从const引用构造
const std::string s = "hello";
std::any a2 = s;
// 从非const引用构造
std::string ss = "world";
std::any a3 = std::move(ss);
// 使用std::in_place_type构造器进行原位构造
std::any a4 = std::in_place_type<std::string>, "in_place";
// 输出所有std::any对象
std::cout << std::any_cast<int>(a1) << std::endl; // 输出: 123
std::cout << std::any_cast<std::string>(a2) << std::endl; // 输出: hello
std::cout << std::any_cast<std::string>(a3) << std::endl; // 输出: world
std::cout << std::any_cast<std::string>(a4) << std::endl; // 输出: in_place
return 0;
}
```
**参数说明:**
- `a1`:使用值初始化。
- `a2`:使用const引用初始化,复制`s`的值。
- `a3`:使用非const引用初始化,并通过移动语义将`ss`的值转移。
- `a4`:使用`std::in_place_type`来原地构造一个`std::string`对象。
#### 3.1.2 赋值与类型转换的机制
std::any对象间可以进行赋值操作,这包括将一个std::any对象的值赋给另一个std::any对象。std::any还支持显式的类型转换,如果存储的类型与目标类型不匹配,则会抛出一个`std::bad_any_cast`异常。
```cpp
std::any a5 = 123;
std::any a6;
a6 = a5; // 赋值操作
try {
// 尝试显式类型转换
std::string str = std::any_cast<std::string>(a6);
} catch (const std::bad_any_cast& e) {
// 类型转换异常处理
std::cerr << "Bad any cast: " << e.what() << std::endl;
}
```
**代码逻辑分析:**
- `a5` 被赋值为整数类型。
- `a6` 初始时没有存储任何类型。
- 执行`a6 = a5;`后,`a6`和`a5`均存储相同值。
- 在尝试将`a6`转换为`std::string`时,因类型不匹配,导致抛出`std::bad_any_cast`异常。在异常处理部分,捕获异常并输出错误信息。
### 3.2 查询和访问
std::any提供了丰富的接口用于查询和访问存储的值。其中,`has_value()`方法可以用来检查std::any对象是否持有一个值,而`type()`方法可以返回存储值的类型信息。
#### 3.2.1 类型信息的查询接口
通过`type()`方法,可以获取到存储值的类型信息,返回类型为`std::type_info`。这个方法对于进行运行时类型检查非常有用。
```cpp
if(a1.has_value() && a1.type() == typeid(int)) {
std::cout << "a1 contains an integer." << std::endl;
} else {
std::cout << "a1 does not contain an integer." << std::endl;
}
```
**参数说明:**
- `a1.has_value()` 检查`a1`是否包含值。
- `a1.type()` 获取存储在`a1`中的值的类型信息。
- `typeid(int)` 获取int类型的信息。
#### 3.2.2 访问和检索对象值的策略
std::any的值通过`std::any_cast`或`std::any::type()`方法访问。`std::any_cast`提供了转换存储值到特定类型的机制,并且这个方法在类型不匹配时会抛出异常。
```cpp
if(a1.has_value()) {
try {
int value = std::any_cast<int>(a1); // 安全地访问值
std::cout << "Retrieved value from a1: " << value << std::endl;
} catch (const std::bad_any_cast& e) {
// 异常处理代码,会在类型不匹配时执行
std::cerr << "Bad type casting attempt: " << e.what() << std::endl;
}
}
```
**代码逻辑分析:**
- 使用`has_value()`检查`a1`是否有存储值。
- 使用`std::any_cast<int>`尝试将`a1`中的值转换为`int`类型。
- 如果`a1`不包含`int`类型的值,将会抛出`std::bad_any_cast`异常,并通过`catch`块处理。
### 3.3 交换和比较
std::any允许用户进行对象之间的交换操作,并且支持基本的比较操作符以比较两个std::any对象。通过交换操作,两个std::any对象可以互换存储的值。
#### 3.3.1 std::any对象的交换操作
std::any类提供了`swap()`方法,允许交换两个std::any对象中的值。这个操作是原子的,保证了线程安全。
```cpp
std::any a7 = 123;
std::any a8 = std::string("swap");
// 交换a7和a8中的值
a7.swap(a8);
if (a7.has_value()) {
try {
std::cout << "Value in a7 after swap: "
<< std::any_cast<std::string>(a7) << std::endl;
} catch (const std::bad_any_cast& e) {
std::cerr << "Bad type casting attempt: " << e.what() << std::endl;
}
}
if (a8.has_value()) {
try {
std::cout << "Value in a8 after swap: "
<< std::any_cast<int>(a8) << std::endl;
} catch (const std::bad_any_cast& e) {
std::cerr << "Bad type casting attempt: " << e.what() << std::endl;
}
}
```
**参数说明:**
- `a7` 被初始化为整数类型。
- `a8` 被初始化为字符串类型。
- `a7.swap(a8);` 交换`a7`和`a8`中的值。
**逻辑分析:**
- 交换之后,原本`a7`中的整数与`a8`中的字符串互换了位置。
- 通过`std::any_cast`来安全地获取交换后的类型和值。
#### 3.3.2 对象间的比较规则和实现
std::any支持比较操作符,如`==`、`!=`、`<`、`<=`、`>`和`>=`。比较时,如果两个std::any对象的类型相同,并且存储的值可比较,则根据值的比较结果返回比较结果;如果类型不同,则返回相应类型定义的比较结果。
```cpp
std::any a9 = 10;
std::any a10 = 10.0f;
std::cout << "a9 == a10? " << (a9 == a10) << std::endl; // 输出 false
```
**代码逻辑分析:**
- 在这个例子中,`a9`存储的是整数,而`a10`存储的是浮点数。
- 即使整数值与浮点数值相同,由于类型不同,因此`a9 == a10`的结果为`false`。
### 3.4 示例表格
以下表格展示了std::any几种常见的使用场景及其结果:
| 场景描述 | std::any使用示例 | 结果示例 |
|-----------------------------|---------------------|---------|
| 从值构造std::any对象 | `std::any a = 123;` | 成功,a包含int类型值123 |
| 从引用构造std::any对象 | `std::string s = "str"; std::any b = s;` | 成功,b包含string类型值"str" |
| std::any对象间的赋值操作 | `c = std::move(b);` | 成功,c现在包含b的值 |
| 类型安全地访问std::any对象中的值 | `try{ auto v = std::any_cast<int>(a); } catch(...){}` | 成功访问或异常处理 |
| std::any对象间的比较操作 | `bool result = (a == b);` | 比较a和b的值,结果为false |
在表格中,对于每种使用场景,给出了一个示例代码,并假设了可能的结果。这有助于理解在不同情境下std::any的使用方式和预期行为。
# 4. std::any在实际项目中的应用
在现代软件开发中,灵活性和可扩展性是项目成功的关键因素之一。std::any作为C++17标准库的一部分,提供了一种在类型安全的前提下存储任意类型对象的能力,这对于实际项目中的动态类型处理有着极其重要的意义。本章节将深入探讨std::any在实际项目中的应用,包括设计模式中的应用案例、动态类型处理以及异构容器设计。
## 4.1 设计模式中的应用案例
设计模式是软件工程中解决常见问题的模板,std::any为这些模式提供了更灵活的实现方式,特别是当类型信息在编译时未知时。
### 4.1.1 std::any在策略模式中的应用
策略模式(Strategy Pattern)定义了一系列算法,并将每个算法封装起来,使它们可以互相替换,且算法的变化不会影响到使用算法的客户端。在策略模式中,通常使用接口或基类来定义算法的结构,然后使用具体类来实现算法的细节。std::any可以用来存储这些算法的具体实现,允许在运行时动态地更换策略。
```cpp
#include <any>
#include <iostream>
#include <memory>
#include <vector>
// 抽象策略基类
class Strategy {
public:
virtual ~Strategy() = default;
virtual void execute() const = 0;
};
// 具体策略A
class ConcreteStrategyA : public Strategy {
public:
void execute() const override {
std::cout << "Executing strategy A\n";
}
};
// 具体策略B
class ConcreteStrategyB : public Strategy {
public:
void execute() const override {
std::cout << "Executing strategy B\n";
}
};
// 策略上下文
class Context {
private:
std::any strategy;
public:
Context(std::any strat) : strategy(std::move(strat)) {}
void set_strategy(std::any strat) {
strategy = std::move(strat);
}
void execute_strategy() const {
if(strategy.has_value()) {
auto& s = std::any_cast<const Strategy&>(strategy);
s.execute();
}
}
};
int main() {
Context context(std::make_any<ConcreteStrategyA>());
context.execute_strategy();
context.set_strategy(std::make_any<ConcreteStrategyB>());
context.execute_strategy();
return 0;
}
```
在上述代码中,我们定义了一个抽象的策略基类`Strategy`和两个具体的策略类`ConcreteStrategyA`和`ConcreteStrategyB`。`Context`类利用`std::any`存储策略对象,并在执行时动态地调用具体策略的`execute`方法。这种实现方式使得`Context`类可以灵活地切换策略,而不需要修改类的内部结构。
### 4.1.2 与工厂模式结合的实例分析
工厂模式(Factory Pattern)是一种创建型模式,它提供了一种创建对象的最佳方式。在工厂模式中,创建对象的逻辑通常依赖于输入参数,并且需要根据这些参数创建不同类型的对象。std::any可以用来作为工厂方法的返回类型,允许动态地返回不同类型的对象。
```cpp
#include <any>
#include <iostream>
#include <memory>
#include <string>
// 产品基类
class Product {
public:
virtual ~Product() = default;
virtual void doSomething() const = 0;
};
// 具体产品A
class ConcreteProductA : public Product {
public:
void doSomething() const override {
std::cout << "ConcreteProductA does something.\n";
}
};
// 具体产品B
class ConcreteProductB : public Product {
public:
void doSomething() const override {
std::cout << "ConcreteProductB does something.\n";
}
};
// 抽象工厂类
class Factory {
public:
virtual std::any createProduct(const std::string& type) = 0;
};
// 具体工厂A
class ConcreteFactoryA : public Factory {
public:
std::any createProduct(const std::string& type) override {
if (type == "A") {
return std::make_unique<ConcreteProductA>();
}
return nullptr;
}
};
// 具体工厂B
class ConcreteFactoryB : public Factory {
public:
std::any createProduct(const std::string& type) override {
if (type == "B") {
return std::make_unique<ConcreteProductB>();
}
return nullptr;
}
};
int main() {
std::unique_ptr<Factory> factoryA = std::make_unique<ConcreteFactoryA>();
auto productA = factoryA->createProduct("A");
if (productA.has_value()) {
auto& product = std::any_cast<Product&>(*productA);
product.doSomething();
}
std::unique_ptr<Factory> factoryB = std::make_unique<ConcreteFactoryB>();
auto productB = factoryB->createProduct("B");
if (productB.has_value()) {
auto& product = std::any_cast<Product&>(*productB);
product.doSomething();
}
return 0;
}
```
在上述代码中,我们定义了一个产品基类`Product`和两个具体的产品类`ConcreteProductA`与`ConcreteProductB`。我们同时创建了一个抽象工厂`Factory`和两个具体工厂`ConcreteFactoryA`与`ConcreteFactoryB`。每个工厂根据类型名称生产相应的具体产品对象,并返回一个`std::any`类型对象。这种方式使得客户端可以灵活地创建不同类别的产品对象,而不需要在编译时知晓具体类型。
## 4.2 动态类型处理
动态类型处理是C++中非常有用的特性,它允许程序在运行时处理不同类型的对象。std::any的出现,进一步简化了这一过程,尤其是在处理多态场景时。
### 4.2.1 模拟动态类型系统的实现
在C++中,动态类型系统通常是通过继承和虚函数来模拟的,std::any的引入为模拟动态类型系统提供了更安全、更简洁的替代方案。
```cpp
#include <any>
#include <iostream>
#include <string>
class Animal {
public:
virtual std::string speak() const = 0;
virtual ~Animal() = default;
};
class Dog : public Animal {
public:
std::string speak() const override {
return "Woof!";
}
};
class Cat : public Animal {
public:
std::string speak() const override {
return "Meow!";
}
};
class Lion : public Animal {
public:
std::string speak() const override {
return "Roar!";
}
};
// 使用std::any存储不同类型的Animal对象
std::vector<std::any> animals = {Dog(), Cat(), Lion()};
for (const auto& animal : animals) {
if (animal.type() == typeid(Dog)) {
std::cout << "A dog says: " << std::any_cast<Dog&>(animal).speak() << '\n';
} else if (animal.type() == typeid(Cat)) {
std::cout << "A cat says: " << std::any_cast<Cat&>(animal).speak() << '\n';
} else if (animal.type() == typeid(Lion)) {
std::cout << "A lion says: " << std::any_cast<Lion&>(animal).speak() << '\n';
}
}
```
在这个例子中,我们定义了一个基类`Animal`和三个派生类`Dog`、`Cat`和`Lion`。所有的派生类都实现了一个`speak`方法,用于输出动物的叫声。然后我们创建了一个`std::any`类型的`animals`向量,用于存储不同类型的动物对象。在遍历这个向量时,我们使用`std::any_cast`和`type`方法来检查和获取具体对象,然后调用它们的`speak`方法输出相应的叫声。这种方法比传统的多态指针更加安全,因为`std::any`会负责类型检查,避免了类型安全问题。
### 4.2.2 std::any在多态场景下的运用
std::any不仅限于存储对象,它还可以用来在运行时存储任何类型的数据,这在某些多态场景下非常有用。特别是在需要对不同类型的数据进行相同操作时,std::any可以简化代码并保持类型安全。
```cpp
#include <any>
#include <iostream>
#include <string>
void processAnimal(std::any& animal) {
if (animal.type() == typeid(Dog)) {
std::cout << "Processing dog, " << std::any_cast<Dog&>(animal).speak() << '\n';
} else if (animal.type() == typeid(Cat)) {
std::cout << "Processing cat, " << std::any_cast<Cat&>(animal).speak() << '\n';
} else if (animal.type() == typeid(Lion)) {
std::cout << "Processing lion, " << std::any_cast<Lion&>(animal).speak() << '\n';
}
}
int main() {
Dog dog;
Cat cat;
Lion lion;
std::vector<std::any> animals = {dog, cat, lion};
for (auto& animal : animals) {
processAnimal(animal);
}
return 0;
}
```
在这个例子中,`processAnimal`函数接受一个`std::any`类型的引用,然后根据存储的类型调用相应类的`speak`方法。这种方式的好处是,函数签名与处理的具体类型无关,能够通过调用`std::any_cast`来访问任何存储在`std::any`中的对象,而无需关心其类型。如果`std::any`中存储的对象类型不匹配,`std::any_cast`将会抛出一个`std::bad_any_cast`异常。
## 4.3 异构容器设计
在处理不同类型的元素集合时,传统的容器如`std::vector`或`std::list`只能存储同一类型的数据。std::any允许我们设计能够存储任意类型数据的容器,这种容器被称为异构容器。
### 4.3.1 异构容器的设计思路
异构容器的主要优点是提供了极高的灵活性。它们允许存储不同类型的数据,而不需要知道具体类型,这样可以轻松地在容器中添加、删除或修改元素,而无需担心类型不匹配的问题。
```cpp
#include <any>
#include <iostream>
#include <vector>
#include <string>
class PolymorphicContainer {
private:
std::vector<std::any> items;
public:
template <typename T>
void add(const T& item) {
items.emplace_back(item);
}
template <typename T>
void remove() {
items.erase(std::remove_if(items.begin(), items.end(),
[](const std::any& anyItem) { return anyItem.type() == typeid(T); }),
items.end());
}
template <typename T>
void process() {
for (auto& item : items) {
if (item.type() == typeid(T)) {
std::cout << "Processing: " << std::any_cast<T&>(item).speak() << '\n';
}
}
}
};
int main() {
PolymorphicContainer container;
container.add(Dog());
container.add(Cat());
container.add(Lion());
container.process<Dog>();
container.process<Cat>();
container.process<Lion>();
return 0;
}
```
在这个例子中,我们定义了一个`PolymorphicContainer`类,它内部使用一个`std::vector<std::any>`来存储任意类型的数据。我们提供了模板方法`add`来添加元素,`remove`来移除特定类型的元素,以及`process`来处理特定类型的元素。这种设计使得`PolymorphicContainer`可以灵活地处理任意类型的数据,同时保持了类型安全。
### 4.3.2 std::any在构建异构容器中的作用
std::any在构建异构容器中的作用是非常关键的。它不仅提供了一种类型安全的方式来存储不同类型的数据,还提供了一种方式来访问存储在其中的对象。我们可以用std::any来模拟一个泛型容器,这个容器可以存储任何类型的对象。
```cpp
#include <any>
#include <iostream>
#include <vector>
#include <string>
// 定义一个异构容器
using AnyContainer = std::vector<std::any>;
// 向异构容器添加元素的函数
template <typename T>
void addAny(AnyContainer& container, const T& element) {
container.emplace_back(element);
}
// 从异构容器中提取元素的函数
template <typename T>
void removeAny(AnyContainer& container) {
container.erase(std::remove_if(container.begin(), container.end(),
[](const std::any& element) { return element.type() == typeid(T); }),
container.end());
}
int main() {
AnyContainer container;
addAny(container, Dog());
addAny(container, Cat());
addAny(container, Lion());
// 假设我们要移除所有的Dog对象
removeAny<Dog>(container);
// 进行遍历处理
for (auto& item : container) {
if (item.type() == typeid(Dog)) {
std::cout << "Processing Dog\n";
} else if (item.type() == typeid(Cat)) {
std::cout << "Processing Cat\n";
} else if (item.type() == typeid(Lion)) {
std::cout << "Processing Lion\n";
}
}
return 0;
}
```
在这个例子中,我们定义了一个`AnyContainer`类型别名,它是一个可以存储任意类型元素的`std::vector`。然后我们定义了两个模板函数`addAny`和`removeAny`,它们分别用于向容器中添加和移除特定类型的元素。在主函数中,我们使用这些函数来操作`AnyContainer`,添加和移除特定类型的对象。这种方法允许我们构建出真正的异构容器,它能够在不牺牲类型安全的前提下,存储不同类型的对象。
通过上述例子,我们可以看出std::any在实际项目中的应用是多方面的,不仅可以用于设计模式的实现,还能在动态类型处理和异构容器设计中发挥关键作用。std::any的引入极大地增强了C++语言的灵活性,使得开发者可以更轻松地处理多态和不同类型数据的存储问题。
# 5. std::any的性能考量
## 5.1 内存使用分析
在设计和实现程序时,内存使用往往是开发者关注的焦点之一。std::any作为一种能够存储任意类型数据的容器,其内存使用策略和开销影响着它的性能。本章节将深入探讨std::any在内存分配和管理方面的工作原理,以及如何合理评估和优化内存使用。
### 5.1.1 内存分配策略
std::any在存储不同大小的数据时采取了灵活的内存分配策略。它需要能够处理从基本数据类型到复杂对象的存储,因此在内存分配上必须兼顾效率和灵活性。
在存储小对象时,std::any可能会使用一个固定大小的内部buffer,以避免动态分配内存的开销。这样做可以减少分配内存所需的系统调用次数,加快程序的执行速度,同时也减少了内存碎片的产生。例如,当存储一个整型(int)或浮点型(float)等小数据类型时,std::any可以直接使用这个buffer。
对于较大对象,std::any通常会使用动态内存分配,例如通过`std::allocate`进行分配。动态分配允许std::any存储任意大小的对象,但也带来了额外的开销,如内存分配和释放的时间消耗以及碎片化问题。
```cpp
#include <any>
#include <iostream>
#include <memory>
int main() {
std::any small{42}; // 可能直接使用内部buffer存储小对象
std::any large = std::make_any<std::vector<int>>(1000); // 使用动态内存分配
return 0;
}
```
### 5.1.2 内存管理的开销讨论
std::any的内存管理涉及对象的存储、拷贝、移动和析构等操作。每当std::any对象存储一个新的对象时,都需要进行相应的内存分配。如果std::any存储了动态分配的对象,则需要跟踪这些对象,当std::any对象被析构时,需要确保相应动态内存被正确释放。
除了内存分配和释放带来的开销,std::any还需要处理异常安全问题。当std::any内部对象的构造函数抛出异常时,std::any需要释放已分配的资源以维持异常安全。因此,std::any可能需要使用某些形式的异常安全机制,例如RAII(Resource Acquisition Is Initialization)模式,以确保资源在异常发生时能够被正确释放。
```cpp
#include <any>
#include <exception>
#include <iostream>
#include <string>
class MyException : public std::exception {
public:
const char* what() const throw() {
return "MyException occurred!";
}
};
int main() {
try {
std::any a;
a = std::string("Hello World");
// 假设std::string的构造函数在某些情况下会抛出异常
throw MyException();
} catch (const std::exception& e) {
std::cout << e.what() << '\n';
}
return 0;
}
```
本节内容展现了std::any的内存使用策略和开销讨论。在下一小节中,我们将探讨std::any的性能优化技巧,以及如何在实际使用中应用这些技巧来提升程序的性能。
# 6. std::any的未来展望与替代方案
C++标准库中的类型是经过精心设计和优化的,但随着语言的发展,新的特性和改进不断被引入以满足日益复杂的应用需求。std::any作为C++17引入的一种类型,它提供了存储任意类型的能力,但正如所有技术解决方案一样,std::any也有其局限性,并且在C++20中引入了新的特性和改进,提供了更多的选择。
## 6.1 C++20中std::any的改进
### 6.1.1 C++20对std::any的增强
C++20标准对std::any进行了重要的增强,这些增强进一步简化了std::any的使用,并提高了其性能。具体来说,C++20为std::any引入了直接访问存储值的能力,类似于std::variant的访问方式。此外,C++20还增强了异常安全性,确保std::any在异常抛出时能更好地保持状态的一致性。
#### 示例代码
```cpp
#include <any>
#include <iostream>
int main() {
std::any a = 42;
// C++20之前,需要先检查类型
if(a.has_value<int>()) {
int value = std::any_cast<int>(a);
std::cout << "The value is: " << value << '\n';
}
// C++20中可以直接访问
if(auto value = a.try_cast<int>()) {
std::cout << "The value is: " << *value << '\n';
}
return 0;
}
```
### 6.1.2 C++20新特性的实际应用场景
在C++20中,我们可以使用std::any来构建更加复杂的数据结构,比如异构容器、配置系统等。由于std::any提供了类型安全的访问方式,使得它在处理多类型数据时更为方便。
#### 示例代码
```cpp
#include <any>
#include <vector>
#include <iostream>
int main() {
std::vector<std::any> vec = {1, 2.5, std::string("Hello"), std::vector<int>{1, 2, 3}};
for(auto& item : vec) {
// C++20中可以直接判断和访问
if (auto i = item.try_cast<int>()) {
std::cout << "Integer: " << *i << '\n';
} else if (auto s = item.try_cast<std::string>()) {
std::cout << "String: " << *s << '\n';
} else if (auto v = item.try_cast<std::vector<int>>()) {
std::cout << "Vector: ";
for(auto& x : *v) {
std::cout << x << ' ';
}
std::cout << '\n';
}
}
return 0;
}
```
## 6.2 std::variant与std::optional对比分析
std::variant和std::optional是与std::any紧密相关的类型,它们在C++17标准中被引入,提供了与std::any不同的能力。
### 6.2.1 std::variant的特点与使用场景
std::variant代表了一个可以存储多种类型之一的类型,其中每种类型都是显式列出的。它主要用于存储一组固定类型的选项。与std::any相比,std::variant在编译时就知道所有可能的类型,因此可以提供更好的类型检查和访问效率。
#### 示例代码
```cpp
#include <variant>
#include <iostream>
int main() {
std::variant<int, float, std::string> v = 42;
std::cout << std::get<int>(v) << '\n';
v = 3.14f;
std::cout << std::get<float>(v) << '\n';
v = "Hello World";
std::cout << std::get<std::string>(v) << '\n';
return 0;
}
```
### 6.2.2 std::optional的引入及其与std::any的比较
std::optional则用于表示一个可能不存在的值。它可以有值或者为空。与std::any不同的是,std::optional不需要存储类型信息,这使得它在某些场景下更加高效。
#### 示例代码
```cpp
#include <optional>
#include <iostream>
int main() {
std::optional<int> opt = 42;
if (opt) {
std::cout << "Value: " << *opt << '\n';
}
opt.reset();
if (!opt.has_value()) {
std::cout << "Optional is empty\n";
}
return 0;
}
```
## 6.3 自定义类型安全容器的可行性探讨
### 6.3.1 自定义容器的设计理念
在一些特定的场景下,开发者可能会考虑到std::any、std::variant和std::optional的局限性,并考虑设计自定义的类型安全容器。自定义容器可以为特定用例量身定做,提供更优的性能或额外的功能。
### 6.3.2 实现自定义类型安全容器的建议
在实现自定义类型安全容器时,首先需要考虑其设计目标和性能需求。此外,应该提供清晰的API和文档,确保容器的易用性和可维护性。使用模板元编程和现代C++特性可以提高容器的灵活性和性能。
#### 示例代码
```cpp
template<typename T>
class MyAny {
public:
template<typename... Args>
MyAny(Args&&... args) : content(std::in_place_type<T>, std::forward<Args>(args)...) {}
T& get() & { return std::any_cast<T&>(content); }
const T& get() const& { return std::any_cast<const T&>(content); }
T&& get() && { return std::any_cast<T&&>(content); }
const T&& get() const&& { return std::any_cast<const T&&>(content); }
private:
std::any content;
};
```
这个自定义的MyAny类类似于std::any,但为T类型提供了直接的get访问接口,同时保持类型安全。实现时要注意异常安全和内存管理问题。
通过以上章节的探讨,我们可以看到std::any的未来展望以及在C++20中增强后的实际应用场景。同时,std::variant和std::optional提供了std::any之外的其他选项。最后,我们也探讨了自定义类型安全容器的可能性,为开发者在面对特定问题时提供了更多的选择。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探索 C++ 中的 std::any,这是一款强大的类型安全容器。通过 20 个技巧、工作原理解析、案例研究和比较,它提供了一个全面的指南,涵盖从入门到精通的各个方面。从 void* 的演变到 std::variant 的对比,再到内存管理、多态实现和性能分析,该专栏揭示了 std::any 的强大功能。它还探讨了异常安全性、初始化和赋值技巧、类型识别、异常处理、跨框架兼容性、线程安全性和序列化,为开发人员提供了在现代 C++ 开发中有效利用 std::any 的全面见解。此外,它还讨论了 std::any 的局限性、替代方案和在数据结构、软件架构和泛型编程中的应用,为开发人员提供了全面的资源,以充分利用 std::any 的潜力。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
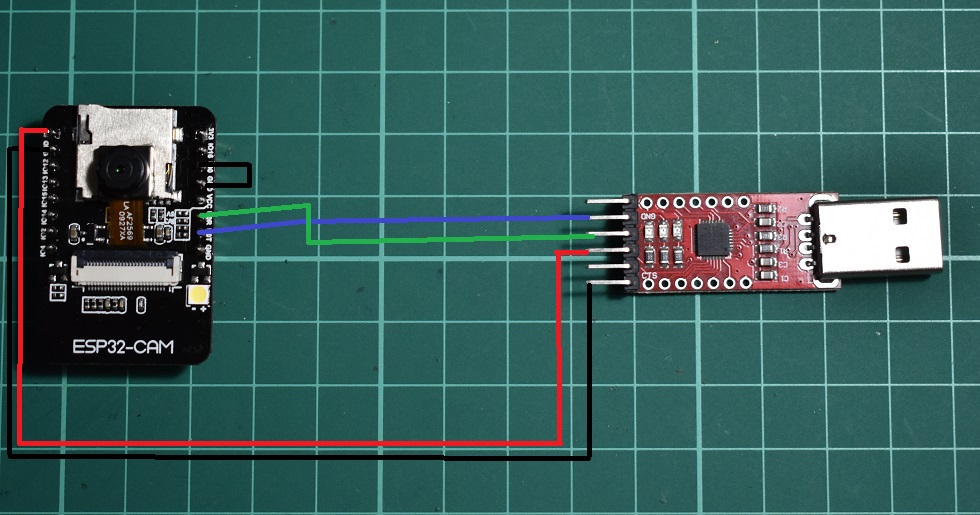
【Proteus高级操作】:ESP32模型集成与优化技巧
# 摘要
本文深入探讨了ESP32模型的集成与性能优化技巧,涉及理论基础、集成过程、系统性能优化以及高级功能的实现与应用。首先介绍了ESP32集成的准备工作,包括软件环境配置和硬件模型的导入。然后详细描述了硬件模拟、软件编程的集成过程,以及如何在Proteus中进行代码调试。接下来,文章着重讲述系统性能优化,涵盖电源管理、代码效率提升以及硬件与固件的协同优化。此外,还介绍了ESP
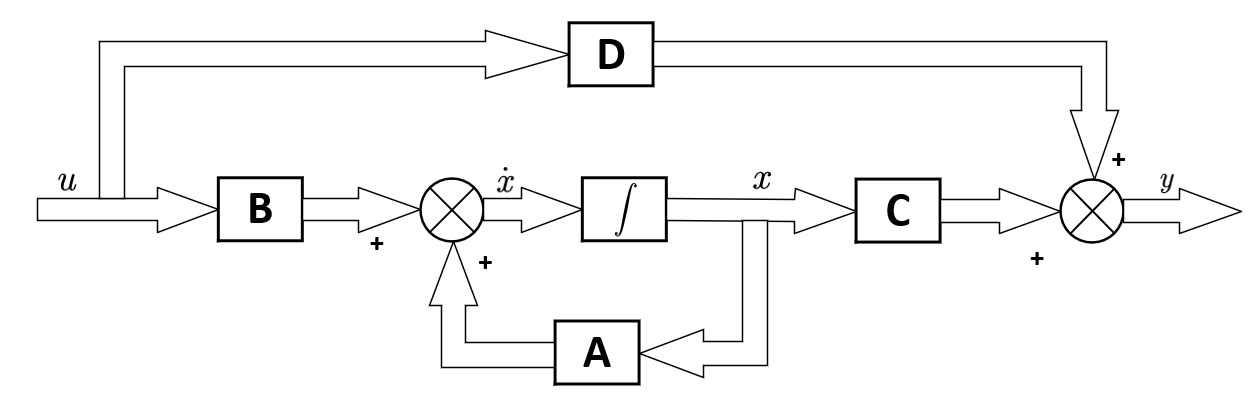
自动控制原理课件深度分析:王孝武与方敏的视角
# 摘要
本文对自动控制原理课程进行了全面的概述,重点探讨了控制系统的基本理论,包括线性系统分析、非线性系统与混沌现象、以及控制器设计的原则与方法。随后,文章引入了控制理论的现代方法,如状态反馈、鲁棒控制、自适应控制以及智能控制算法,并分析了其在实际应用中的重要性。此外,本文还详细介绍了控制系统的软件实现与仿真,以及如何利用常用软件工具如MATLAB、Simulink和LabVIEW进行控制工
【QSPr工具全方位攻略】:提升高通校准综测效率的10大技巧
# 摘要
本文旨在全面介绍QSPr工具,该工具基于高通综测技术,具备强大的校准流程和高效的数据处理能力。首先,从理论基础出发,详细阐述了QSPr工具的工作原理和系统架构,强调了校准流程和系统集成的重要性。随后,针对实践技巧进行了深入探讨,包括如何高效设置、配置QSPr工具,优化校准流程,以及如何进行数据分析和结果解读。在高级应用章节,本文提供了自动化脚本编写、第三方工具集成和性能监
【鼎捷ERP T100性能提升攻略】:让系统响应更快、更稳定的5个方法
# 摘要
鼎捷ERP T100系统在面对高性能挑战时,需要从硬件、数据库和软件等多方面进行综合优化。本文首先概述了ERP T100系统的特点及性能挑战。随后,重点探讨了硬件优化策略,包括硬件升级的必要性、存储系统与内存管理的优化。在数据库性能调优方面,本文提出了结构优化、查询性能提升和事务处理效率增强的方法。此外,还分析了软件层面的性能提升手段,如ERP软件配置优化、业务流程重组与简化
STM32F334外设配置宝典:掌握GPIO, ADC, DAC的秘诀

# 摘要
本文全面介绍STM32F334微控制器的基础知识,重点阐述了GPIO、ADC和DAC外设的配置及实践操作,并通过应用实例深入分析了其在项目中的运用。通过系统配置策略、调试和性能优化的讨论,进一步探索了在综合应用中的系统优化方法。最后,结合实际项目案例,分享了开发过程中的经验总结和技巧,旨在为工程师在微
跨平台开发者必备:Ubuntu 18.04上Qt 5.12.8安装与调试秘籍
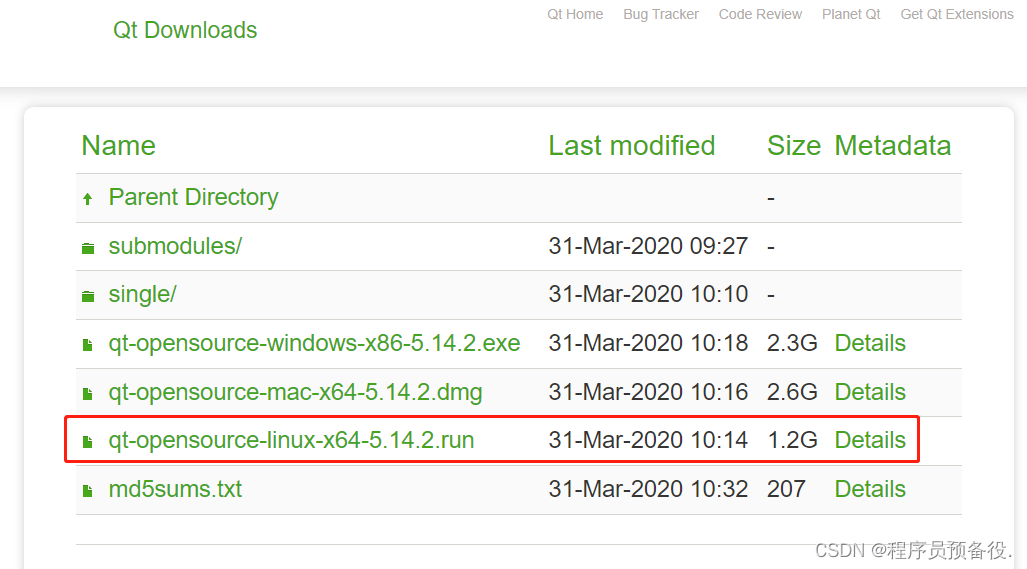
# 摘要
本文针对Ubuntu系统环境下Qt 5.12.8的安装、配置及优化进行了全面的流程详解,并深入探讨了跨平台开发实践技巧与案例研究。首先,介绍了系统环境准备和Qt安装流程,强调了官方源与第三方源的配置及安装过程中的注意事项。随后,文章详细阐述了Qt Creator的环境配置、编译器与工具链设置,以及性能调优和内存管理技术。在跨平台开发部分,本文提出了有效的项目配置、界面设
【多云影像处理指南】:遥感图像去云算法实操与技巧
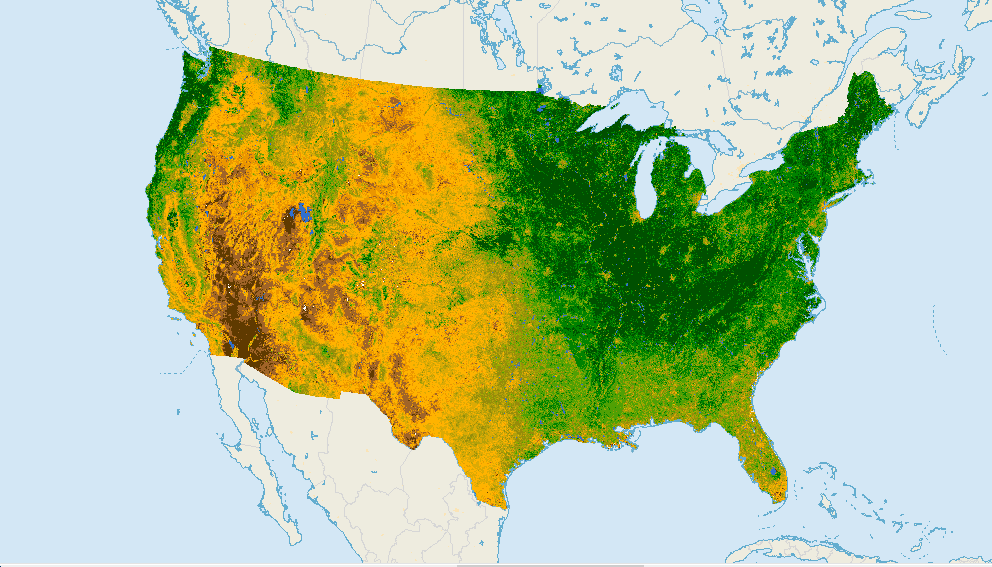
# 摘要
本文全面探讨了多云影像处理的理论与实践,从遥感影像的云污染分析到去云算法的分类原理、性能评估,再到实际操作的技巧和案例研究。重点介绍了遥感影像去云的重要性、常用去云软件工具、操作流程以及后处理技术。同时,文章也研究了多云影像处理在农业、城市规划和灾害监测中的应用,并讨论了人工智能技术如何优化去云算法,展望了多云影像处理的未来趋势和面临的挑战。通过对多云影像处理技术的深入剖析
波形发生器频率控制艺术

# 摘要
波形发生器作为电子工程中的关键组件,其技术进步对频率控制领域产生了深远影响。本文综合概述了波形发生器技术,深入探讨了频率控制的基础理论,包括频率与波形生成的关系、数字频率控制理论以及频率合成技术。在实践应用部分,详细分析了频率调整的硬件和软件实现方法,以及提高频率控制精确度和稳定性的技术。先进方法章节讨论了自适应和智能化频率调整方法,以及多波形系统
延长标签寿命:EPC C1G2协议的能耗管理秘籍
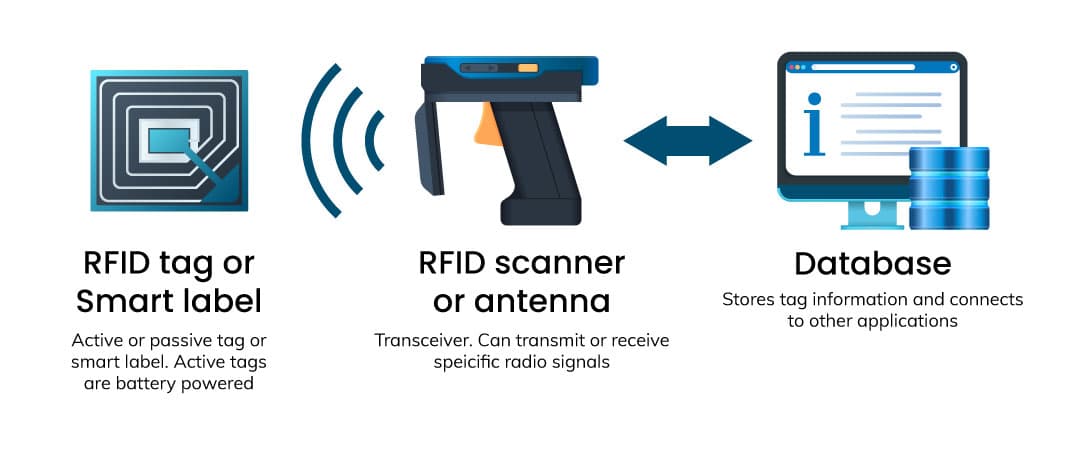
# 摘要
本文针对EPC C1G2协议在实际应用中面临的能耗问题进行了深入研究,首先介绍了EPC C1G2协议的基本概念及能耗问题现状。随后,构建了基于EPC C1G2协议架构的能耗模型,并详细分析了通信过程中关键能耗因素。通过理论与实践相结合的方式,本文探讨了静态和动态节能技术,并对EPC C1G2标签的寿命延长技术进行了实验设计和评估。最后,文章展望了EPC C1G2协议能耗管理的未来趋势,
【热参数关系深度探讨】:活化能与其他关键指标的关联

# 摘要
本论文对热化学动力学中一个核心概念——活化能进行系统性探讨。首先介绍了活化能的基本理论及其在化学反应中的重要性,随后详述了活化能的计算方法,包括阿伦尼乌斯方程以及实验技术的应用。本文深入分析了活化能与其他动力学参数如速率常数、反应焓变和熵的关系,并探讨了在工业化学反应和新能源领域中活化能的应用与优化。此外,文中还讨论了现代实验技术在活化能测定中的重要性以及实
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )