异常处理升级:std::any在捕获和存储异常中的应用
发布时间: 2024-10-22 18:32:22 阅读量: 2 订阅数: 2 
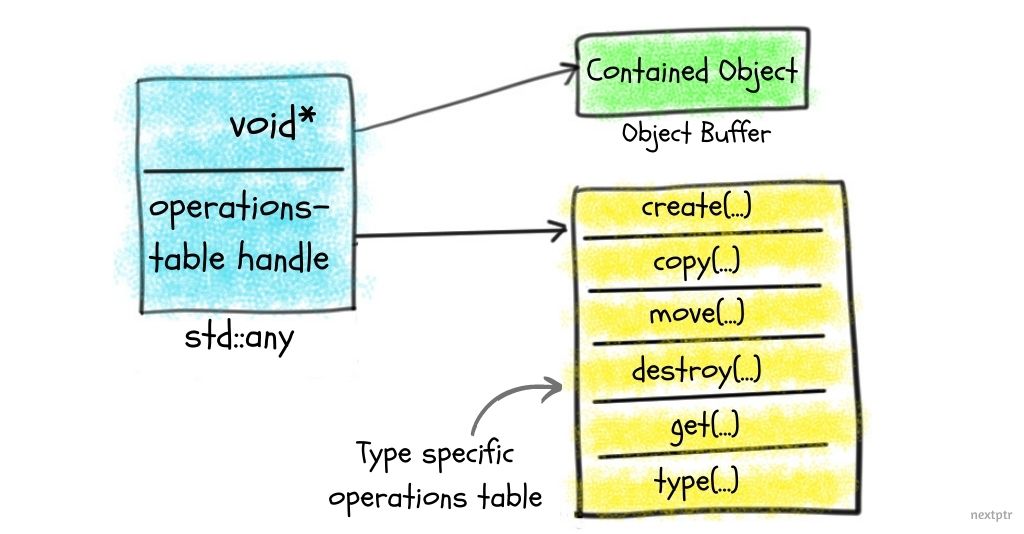
# 1. std::any的简介与异常处理基础
## 1.1 C++异常处理概述
C++中的异常处理是一种处理程序运行时错误的机制,允许程序在检测到错误时,通过抛出异常对象来分发错误信息,并在调用栈的其他地方捕获这些信息。这使得错误处理代码与常规业务逻辑分离,提高了代码的可读性和可维护性。
## 1.2 std::any的引入
从C++17开始,标准库中引入了`std::any`类型,它允许存储任意类型的值。`std::any`提供了一种类型安全的方式来处理不固定类型的值,在异常处理中尤其有用,因为异常对象可以是任意类型。
## 1.3 异常与std::any的结合
异常处理与`std::any`的结合为开发者提供了一种新的视角。通过`std::any`,可以将异常对象存储和传递,同时保持类型信息的安全。这对于动态类型语言或者需要延迟绑定的场景特别有用。
接下来的章节将深入探讨`std::any`如何在异常捕获、存储、以及优化策略中发挥作用。
# 2. std::any在异常捕获中的应用
### 2.1 std::any的数据封装机制
在C++中,`std::any`是一种类型安全的容器,可以存储任意类型的值。它使得在设计库或应用程序时能够支持多种不同类型的对象,而不必在编译时就确定其具体类型。这为异常处理提供了极大的灵活性。
#### 2.1.1 任意类型数据的封装
`std::any`的灵活性体现在它能够封装任何类型的数据,包括内置类型、自定义类型、甚至是可以被复制或者移动的类实例。下面是一个`std::any`封装任意类型数据的例子:
```cpp
#include <any>
#include <iostream>
#include <string>
int main() {
std::any a; // 默认初始化为空
a = 1; // 存储int类型的数据
a = std::string("Hello, any!"); // 存储std::string类型的数据
try {
if (a.type() == typeid(int)) {
// 如果是int类型,执行int相关的操作
int i = std::any_cast<int>(a);
std::cout << "a is int: " << i << std::endl;
} else if (a.type() == typeid(std::string)) {
// 如果是std::string类型,执行std::string相关操作
std::string s = std::any_cast<std::string>(a);
std::cout << "a is string: " << s << std::endl;
} else {
std::cout << "存储的是其他类型" << std::endl;
}
} catch (const std::bad_any_cast& e) {
std::cerr << "转换失败: " << e.what() << std::endl;
}
return 0;
}
```
#### 2.1.2 std::any与类型安全
虽然`std::any`提供了类型不安全容器的功能,但其内部实现确保了类型安全。它在运行时检查类型信息,确保`std::any_cast`转换的正确性。这为异常处理提供了保障,避免了类型错误导致的运行时错误。
### 2.2 异常捕获的实践技巧
#### 2.2.1 使用std::any捕获异常
在C++17中引入的`std::any`可以与异常处理机制结合使用,以便存储和传递异常信息。由于异常可能具有多种类型,我们可以使用`std::any`来捕获并存储这些类型各异的异常对象。
```cpp
#include <any>
#include <iostream>
#include <stdexcept>
void throw_exception() {
throw std::runtime_error("Example error");
}
int main() {
try {
throw_exception();
} catch (const std::exception& e) {
std::any exception_container = std::current_exception();
// 处理异常信息
// ...
std::cout << "Exception caught: " << e.what() << std::endl;
}
return 0;
}
```
#### 2.2.2 异常信息的存储与管理
存储异常信息是异常处理的重要方面,尤其是在多线程环境中,可能需要将异常信息传递到线程之外进行记录或者进一步处理。`std::any`可以在异常处理流程中用来安全地存储异常对象,从而避免资源泄漏,并允许后续的异常信息分析。
```cpp
#include <any>
#include <exception>
#include <iostream>
#include <string>
#include <thread>
void thread_function() {
try {
throw std::runtime_error("Thread error");
} catch (...) {
std::any exception_container = std::current_exception();
// 在线程中存储异常信息
// ...
}
}
int main() {
std::thread t(thread_function);
t.join(); // 等待线程结束
// 在主线程中处理线程的异常信息
// ...
return 0;
}
```
### 2.3 异常处理的优化策略
#### 2.3.1 性能考量
在使用`std::any`进行异常处理时,我们需要考虑其性能影响。由于`std::any`涉及到类型信息的存储和类型转换,所以在处理大量或高频的异常时可能会带来性能负担。因此,设计和实现时需要权衡`std::any`带来的便利性和性能开销。
#### 2.3.2 异常安全的编程实践
异常安全是C++编程中重要的实践,意味着在异常发生时程序仍能保持其资源的完整性。使用`std::any`可以更好地实现异常安全,因为可以通过异常来转移对象的所有权或执行清理工作,确保资源被正确释放,避免内存泄漏等问题。
```cpp
#include <any>
#include <iostream>
#include <string>
#include <memory>
void unsafe_function() {
std::unique_ptr<int> resource = std::make_unique<int>(42);
// 假设这里发生了异常
// ...
// 在异常安全的情况下,确保资源被释放
}
int main() {
try {
unsafe_function();
} catch (...) {
// 异常被安全地处理
}
return 0;
}
```
在本章节的介绍中,我们探讨了`std::any`的数据封装机制,它为我们提供了灵活且类型安全的数据存储能力。通过实际代码示例,我们说明了如何使用`std::any`进行异常捕获和异常信息的存储。同时,我们也探讨了使用`std::any`进行异常处理时的性能考量和异常安全的编程实践。这些知识将为下一章的内容打下坚实的基础。在下一章中,我们将深入探讨`std::any`在异常存储中的应用,包括异常对象的存储技术、异常信息的检索与分析以及异常存储的最佳实践。
# 3. std::any在异常存储中的应用
### 3.1 异常对象的存储技术
在现代的C++编程中,异常对象的存储是异常处理的一个重要方面。它确保了异常信息能够在应用程序中保持一致性和可检索性。
#### 3.1.1 标准异常类的使用
C++标准库中定义了多种标准异常类,如`std::exception`、`std::runtime_error`和`std::logic_error`等。开发者通过继承这些标准异常类来创建自定义的异常对象,这使得异常处理既灵活又易于使用。
```cpp
#include <stdexcept>
#include <iostream>
class MyException : public std::runtime_error {
public:
MyException(const std::string& message) : std::runtime_error(message) {}
};
void functionThatMightThrow() {
throw MyException("Something went wrong!");
}
int main() {
try {
functionThatMightThrow();
} catch (const MyException& e) {
std::cerr << "Caught exception: " << e.what() << std::endl;
}
return 0;
}
```
在上面的代码示例中,我们定义了一个`MyException`类,继承自`std::ru

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Go并发网络编程】:Fan-out_Fan-in模式在HTTP服务中的优化

# 1. Go并发网络编程概述
Go语言凭借其简洁的语法和高效的并发模型,成为了现代网络编程领域中备受欢迎的编程语言。在本章中,我们将从宏观的角度审视Go语言在网络编程中的应用,特别是其在并发控制方面的独特优势。我们将探讨为什么Go语言特别适合编写网络服务
【日志保留策略制定】:有效留存日志的黄金法则

# 1. 日志保留策略制定的重要性
在当今数字化时代,日志保留策略对于维护信息安全、遵守合规性要求以及系统监控具有不可或缺的作用。企业的各种操作活动都会产生日志数据,而对这些数据的管理和分析可以帮助企业快速响应安全事件、有效进行问题追踪和性能优化。然而,随着数据量的激增,如何制定合理且高效的数据保留政策,成为了一个亟待解决的挑战。
本章将探讨制定日志保留策略的重要性,解释为什么正确的保
微服务架构中的***配置管理:服务发现与配置中心实战
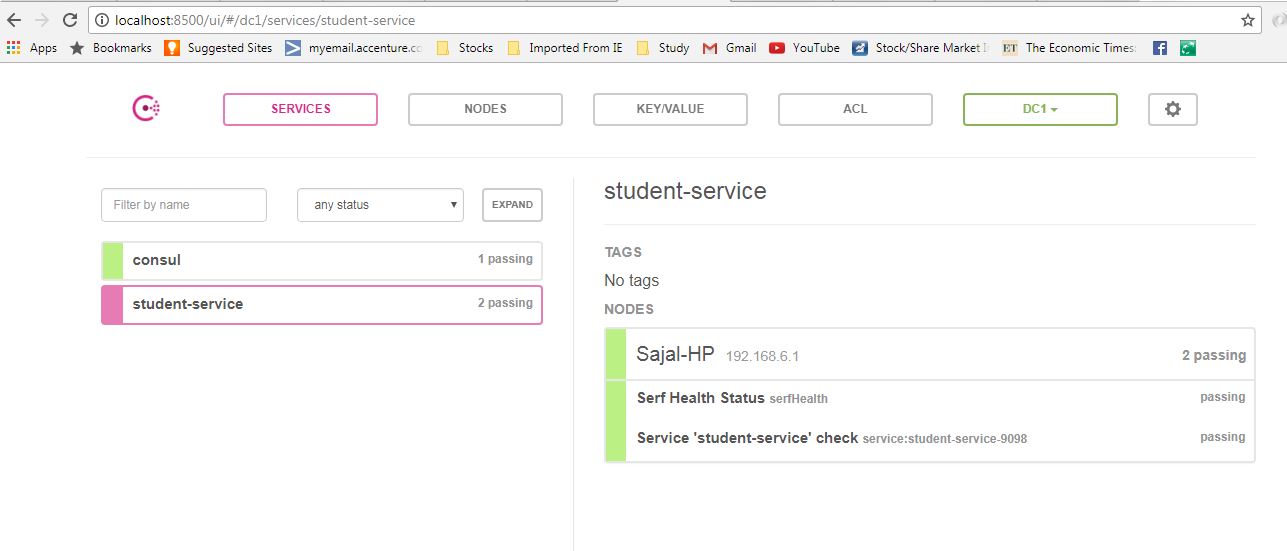
# 1. 微服务架构的基本概念和挑战
微服务架构作为现代软件开发和部署的一种流行模式,它将一个大型复杂的应用分解成一组小服务,每个服务运行在其独立的进程中,服务间通过轻量级的通信机制进行交互。这种模式提高了应用的模块性,使得各个服务可以独立开发、部署和扩展。然而,在实践中微服务架构也带来了诸多挑战,包括但不限于服务治理、数据一致性、服
Java EE中的设计模式应用:构建可扩展企业系统的高级技巧
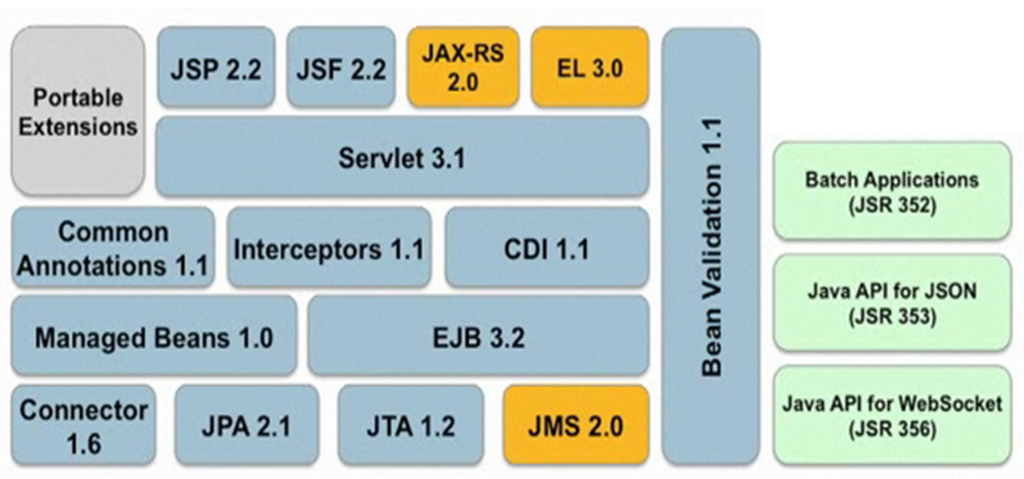
# 1. Java EE与设计模式概述
在软件开发领域,设计模式是解决特定问题的一般性模板,Java EE(Java Platform, Enterprise Edition)作为企业级应用开发的核心技术,其架构和代码组织常常需要依赖于设计模式来实现高度的可扩展性、可维护性和灵活性。本章我们将探讨设计模式的基本概念,以及它们在Java EE环境下的应用价值。
首先,设计模式为我们提供了一种通用语言,帮助开发者交流
大数据环境下的JSON-B性能评估:优化策略与案例分析

# 1. JSON-B简介与大数据背景
## JSON-B简介
JavaScript Object Notation Binary (JSON-B) 是一种基于 JSON 的二进制序列化规范,它旨在解决 JSON 在大数据场景下存在的性能和效率问题。与传统文本格式 JSON 相比,JSON-B 通过二进制编码大幅提高了数据传输和存储的效率。
【Go API设计蓝图】:构建RESTful和GraphQL API的最佳实践

# 1. Go语言与API设计概述
## 1.1 Go语言特性与API设计的联系
Go语言以其简洁、高效、并发处理能力强而闻名,成为构建API服务的理想选择。它能够以较少的代码实现高性能的网络服务,并且提供了强大的标准库支持。这为开发RESTful和GraphQL API提供了坚实的基础。
## 1.2 API设计的重要性
应用程序接口(AP
Go语言命名歧义避免策略:清晰表达与避免误导的6大建议

# 1. Go语言命名基础与歧义问题概述
## 1.1 命名的重要性
在Go语言中,良好的命名习惯是编写高质量、可维护代码的关键。一个清晰的变量名、函数名或类型名能够极大地提高代码的可读性和团队协作效率。然而,命名歧义问题却常常困扰着开发者,使得原本意图清晰的代码变得难以理解。
## 1.2 命名歧义的影响
命名歧义会引发多
std::deque自定义比较器:深度探索与排序规则

# 1. std::deque容器概述与标准比较器
在C++标准模板库(STL)中,`std::deque`是一个双端队列容器,它允许在容器的前端和后端进行快速的插入和删除操作,而不影响容器内其他元素的位置。这种容器在处理动态增长和缩减的序列时非常有用,尤其是当需要频繁地在序列两端添加或移除元素时。
`std::deque`的基本操作包括插入、删除、访问元素等,它的内部实现通常采用一段连续的内存块,通
C++ std::array与STL容器混用:数据结构设计高级策略
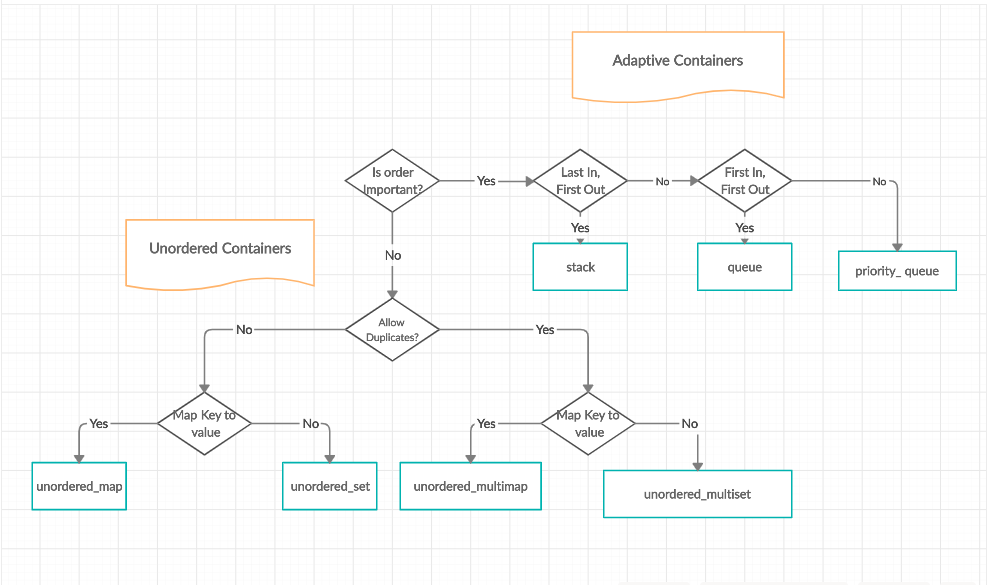
# 1. C++数据结构设计概述
C++语言凭借其丰富的特性和高性能,成为开发复杂系统和高效应用程序的首选。在C++中,数据结构的设计是构建高效程序的基石。本章将简要介绍C++中数据结构设计的重要性以及其背后的基本原理。
## 1.1 数据结构设计的重要性
数据结构是计算机存储、组织数
JAXB在大数据环境下的应用与挑战:如何在分布式系统中优化性能
# 1. JAXB基础与大数据环境概述
在本章中,我们将简要回顾Java Architecture for XML Binding (JAXB)的基础知识,并概述大数据环境的特征。JAXB是Java EE的一部分,它提供了一种将Java对象映射到XML表示的方法,反之亦然。这个过程称为绑定,JAXB使Java
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )