std::any的局限与替代:专家指导何时弃用std::any
发布时间: 2024-10-22 18:50:45 阅读量: 36 订阅数: 31 

使用c++实现boost::any类

# 1. std::any的介绍与基本使用
在C++编程中,`std::any`是一个允许存储任意类型值的通用容器,它从C++17标准开始被引入。`std::any`允许开发者在一个容器中存储不同类型的数据,而无需预先知道数据的具体类型,这为运行时类型多态提供了极大的灵活性。
## 基本概念和特性
`std::any`是类型安全的,它在编译时检查类型,但运行时却不保留类型信息,这被称为“类型擦除”。尽管类型信息在运行时不可用,我们仍可检查`std::any`中存储的对象类型,并将其转换回原始类型。
## 基本使用方法
要使用`std::any`,你需要包含头文件`<any>`。下面的代码展示了如何使用`std::any`来存储不同类型的值,并进行类型检查和类型转换。
```cpp
#include <any>
#include <iostream>
#include <string>
int main() {
std::any my_any = 42; // 存储一个int类型值
// 检查是否为int类型
if(my_any.type() == typeid(int)) {
// 安全地转换并访问int值
std::cout << std::any_cast<int>(my_any) << std::endl;
}
my_any = std::string("Hello std::any!"); // 存储一个std::string类型值
// 检查是否为std::string类型
if(my_any.type() == typeid(std::string)) {
// 安全地转换并访问std::string值
std::cout << std::any_cast<std::string>(my_any) << std::endl;
}
return 0;
}
```
通过上述示例,我们了解了`std::any`的基本概念和如何存储和检索不同类型的值。在接下来的章节中,我们将深入分析`std::any`的局限性,并探讨可能的替代方案。
# 2. std::any的局限性分析
## 2.1 类型擦除带来的性能问题
### 2.1.1 类型擦除机制介绍
在C++中,std::any是C++17标准中引入的一个类型安全的容器,用于存储任意类型的值。std::any的一个关键特性是类型擦除,这意味着它不保留其存储对象的类型信息。这种设计允许std::any持有不同类型的对象而无需指定或保留它们的类型信息。然而,正是这种灵活性带来了性能上的潜在问题。
类型擦除通常通过使用虚函数来实现。在std::any的情况下,这意味着可能涉及到间接调用、动态内存分配和对象切片,这些都是性能开销的常见来源。例如,当存储一个非多态类型(如int、float等基本类型)时,std::any可能需要将其包装在一个内部的多态类型中,这会增加额外的内存和间接调用的开销。
### 2.1.2 性能影响的具体案例分析
下面是一个简单的性能测试案例,用于展示类型擦除对性能的影响。我们将比较直接存储基本类型数据与存储在std::any中的性能差异。
```cpp
#include <any>
#include <chrono>
#include <iostream>
#include <random>
void performanceTestDirect() {
std::default_random_engine generator;
std::uniform_int_distribution<int> distribution(0, 1000000);
auto begin = std::chrono::high_resolution_clock::now();
int value = distribution(generator);
for (int i = 0; i < 1000000; ++i) {
value = distribution(generator);
}
auto end = std::chrono::high_resolution_clock::now();
std::chrono::duration<double, std::milli> diff = end - begin;
std::cout << "直接存储耗时: " << diff.count() << " ms\n";
}
void performanceTestAny() {
std::default_random_engine generator;
std::uniform_int_distribution<int> distribution(0, 1000000);
std::any value = distribution(generator);
auto begin = std::chrono::high_resolution_clock::now();
for (int i = 0; i < 1000000; ++i) {
value = distribution(generator);
}
auto end = std::chrono::high_resolution_clock::now();
std::chrono::duration<double, std::milli> diff = end - begin;
std::cout << "std::any存储耗时: " << diff.count() << " ms\n";
}
int main() {
performanceTestDirect();
performanceTestAny();
return 0;
}
```
上述代码中,`performanceTestDirect` 函数直接在int变量上执行操作,而 `performanceTestAny` 函数则在std::any对象上执行相同的操作。尽管std::any的实现可能会优化某些操作,但通常情况下,我们预期使用std::any会带来一些性能开销,特别是对于简单类型的存储和操作。
## 2.2 类型安全的缺失与风险
### 2.2.1 类型安全概念概述
类型安全(Type Safety)是指在程序执行期间,一个值的类型被正确地使用,并且没有被错误地解释或转换为其他类型。类型安全的系统可以确保各种类型的操作和数据处理是正确的,从而避免类型错误,提高代码的可靠性。
然而,std::any由于其设计目标是存储任意类型的值,因此它在类型安全方面存在先天不足。std::any本身并不知道它存储的是什么类型的对象,它允许你存储任意类型的数据,但同时也使得程序员或者程序在运行时需要承担类型转换的风险。这种设计虽然提供了灵活性,但当程序试图执行某个类型的操作但提供的不是正确类型时,可能会引发类型转换异常。
### 2.2.2 std::any使用中的类型安全问题实例
让我们来看一个例子,该例子演示了使用std::any时可能出现的类型安全问题:
```cpp
#include <any>
#include <iostream>
int main() {
std::any any_value = 42; // 存储一个int类型
// 尝试将存储在std::any中的值转换为float类型
try {
float f = std::any_cast<float>(any_value);
} catch (const std::bad_any_cast& e) {
std::cout << "类型转换失败: " << e.what() << '\n';
}
return 0;
}
```
在上述代码中,我们首先存储了一个int类型的值在std::any中,然后错误地尝试将其转换为float类型。由于类型不匹配,std::any_cast将抛出一个bad_any_cast异常。
## 2.3 std::any与异常安全性的关系
### 2.3.1 异常安全性的基本原理
异常安全性是C++程序设计中的一个重要概念,它是指当程序遇到错误或异常时,程序能够保持在一致的状态,并且资源得到正确的管理,即使程序无法完成其原先设定的任务。异常安全性通常分为以下三个级别:
- 基本异常安全性:确保异常发生时不会导致资源泄露,程序保持在异常发生之前的合法状态。
- 强异常安全性:保证异常发生时程序仍然保持在一致状态,并且所有操作都能回滚。
- 不抛出异常的安全性:程序在任何情况下都不抛出异常,确保不会给调用者带来异常负担。
### 2.3.2 std::any在异常处理中的挑战
std::any由于其类型擦除的特性,在异常处理方面面临一些挑战。例如,存储在std::any中的对象可能会在其生命周期结束时抛出异常,而std::any无法在异常抛出前执行任何清理操作。另外,在使用std::any_cast进行类型转换时,如果转换失败,则会抛出异常,这需要调用者妥善处理。
这种异常安全性挑战在处理包含资源管理的复杂类型时尤其明显。例如,假设std::any中存储了一个自定义类的实例,该类的析构函数会释放资源。如果在析构函数抛出异常,由于std::any已经丢失了类型信息,所以它无法知道如何正确地清理对

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探索 C++ 中的 std::any,这是一款强大的类型安全容器。通过 20 个技巧、工作原理解析、案例研究和比较,它提供了一个全面的指南,涵盖从入门到精通的各个方面。从 void* 的演变到 std::variant 的对比,再到内存管理、多态实现和性能分析,该专栏揭示了 std::any 的强大功能。它还探讨了异常安全性、初始化和赋值技巧、类型识别、异常处理、跨框架兼容性、线程安全性和序列化,为开发人员提供了在现代 C++ 开发中有效利用 std::any 的全面见解。此外,它还讨论了 std::any 的局限性、替代方案和在数据结构、软件架构和泛型编程中的应用,为开发人员提供了全面的资源,以充分利用 std::any 的潜力。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【概率论与数理统计:工程师的实战解题宝典】:揭示习题背后的工程应用秘诀

# 摘要
本文从概率论与数理统计的角度出发,系统地介绍了其基本概念、方法与在工程实践中的应用。首先概述了概率论与数理统计的基础知识,包括随机事件、概率计算以及随机变量的数字特征。随后,重点探讨了概率分布、统计推断、假设检验
【QSPr参数深度解析】:如何精确解读和应用高通校准综测工具

# 摘要
QSPr参数是用于性能评估和优化的关键工具,其概述、理论基础、深度解读、校准实践以及在系统优化中的应用是本文的主题。本文首先介绍了QSPr工具及其参数的重要性,然后详细阐述了参数的类型、分类和校准理论。在深入解析核心参数的同时,也提供了参数应用的实例分析。此外,文章还涵盖了校准实践的全过程,包括工具和设备准备、操作流程以及结果分析与优化。最终探讨了QSPr参数在系统优化中的
探索自动控制原理的创新教学方法

# 摘要
本文深入探讨了自动控制理论在教育领域中的应用,重点关注理论与教学内容的融合、实践教学案例的应用、教学资源与工具的开发、评估与反馈机制的建立以
Ubuntu 18.04图形界面优化:Qt 5.12.8性能调整终极指南

# 摘要
本文全面探讨了Ubuntu 18.04系统中Qt 5.12.8图形框架的应用及其性能调优。首先,概述了Ubuntu 18.04图形界面和Qt 5.12.8核心组件。接着,深入分析了Qt的模块、事件处理机制、渲染技术以及性能优化基
STM32F334节能秘技:提升电源管理的实用策略
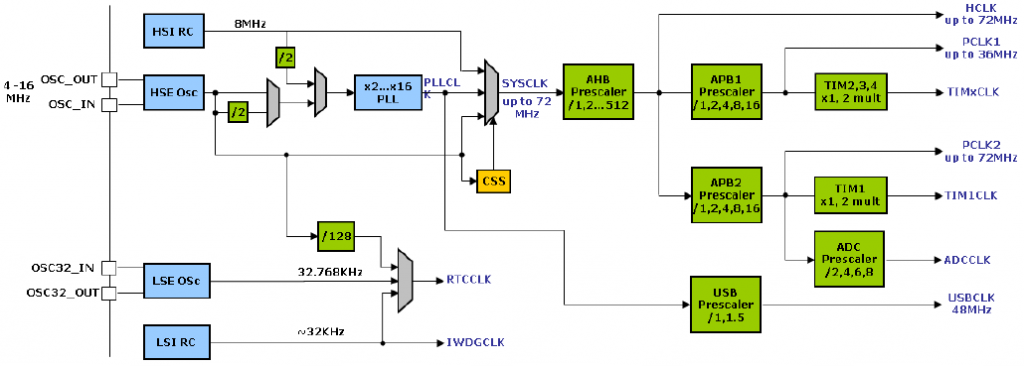
# 摘要
本文全面介绍了STM32F334微控制器的电源管理技术,包括基础节能技术、编程实践、硬件优化与节能策略,以及软件与系统级节能方案。文章首先概述了STM32F334及其电源管理模式,随后深入探讨了低功耗设计原则和节能技术的理论基础。第三章详细阐述了RTOS在节能中的应用和中断管理技巧,以及时钟系统的优化。第四章聚焦于硬件层面的节能优化,包括外围设备选型、电源管
【ESP32库文件管理】:Proteus中添加与维护技术的高效策略
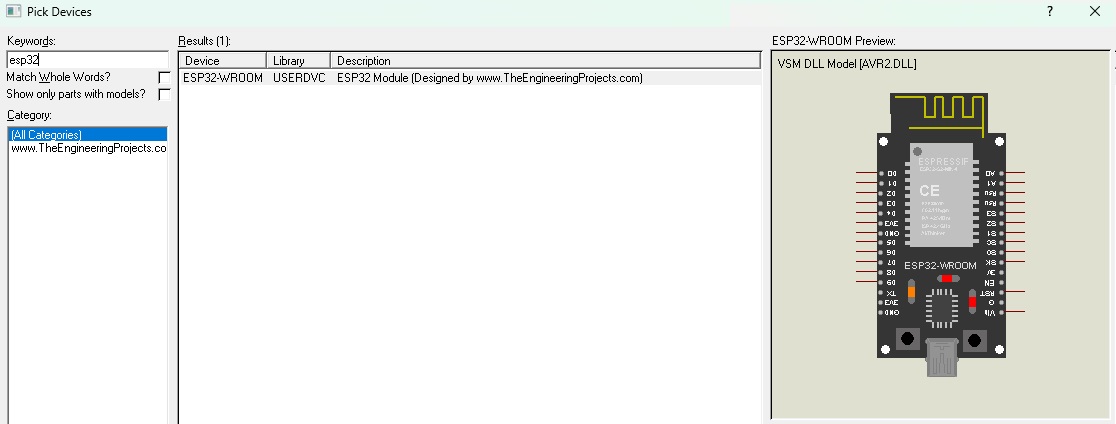
# 摘要
本文旨在全面介绍ESP32微控制器的库文件管理,涵盖了从库文件基础到实践应用的各个方面。首先,文章介绍了ESP32库文件的基础知识,包括库文件的来源、分类及其在Proteus平台的添加和配置方法。接着,文章详细探讨了库文件的维护和更新流程,强调了定期检查库文件的重要性和更新过程中的注意事项。文章的第四章和第五章深入探讨了ESP3
【实战案例揭秘】:遥感影像去云的经验分享与技巧总结

# 摘要
遥感影像去云技术是提高影像质量与应用价值的重要手段,本文首先介绍了遥感影像去云的基本概念及其必要性,随后深入探讨了其理论基础,包括影像分类、特性、去云算法原理及评估指标。在实践技巧部分,本文提供了一系列去云操作的实际步骤和常见问题的解决策略。文章通过应用案例分析,展示了遥感影像去云技术在不同领域中的应用效果,并对未来遥感影像去云技术的发
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )