C++17新特性剖析:std::any的深度解读与应用
发布时间: 2024-10-22 18:05:33 阅读量: 65 订阅数: 50 

ratptt:RATP时刻表

# 1. C++17新特性的概述与std::any简介
在本章中,我们首先将回顾C++17标准所引入的新特性,它为C++这一成熟语言增添了诸多便捷和强大的功能,对现代C++编程带来了显著的影响。我们将会了解新增的语法、库组件以及对现有语言和库的改进,这为我们引入std::any这一新的类型擦除工具铺平了道路。
接着,我们会介绍std::any的基本概念,它作为C++17中的一个全新的标准库类型,允许我们存储任意类型的数据而不失类型安全。std::any提供了一种在类型安全的情况下,将不同的类型值存储在一个单一容器中的方法,这使得在复杂的应用场景下,如多态容器和事件处理系统,能够更加灵活地管理不同类型的数据。
让我们从以下代码块开始理解std::any的实际用法:
```cpp
#include <any>
#include <iostream>
#include <string>
int main() {
std::any myAny = 123; // 存储一个整数
myAny = "Hello, World!"; // 存储一个字符串
if (myAny.type() == typeid(int)) {
std::cout << std::any_cast<int>(myAny) << std::endl;
} else if (myAny.type() == typeid(std::string)) {
std::cout << std::any_cast<std::string>(myAny) << std::endl;
}
return 0;
}
```
代码块展示了如何使用std::any存储不同类型的数据,并通过`type()`方法与`std::any_cast`来进行类型安全检查与数据提取。这仅是对std::any功能的浅尝辄止,接下来的章节我们将深入探讨其内部机制、类型安全检查、存储机制以及如何在日常开发中应用std::any。
# 2. std::any的内部机制与原理
## 2.1 std::any的基本概念
### 2.1.1 类型擦除技术的引入
类型擦除(Type Erasure)是C++中一种用于隐藏具体类型信息的技术。std::any是这种技术的一个典型应用,它允许我们存储任意类型的对象,而无需在编译时知道具体的类型。这一特性极大地提高了代码的灵活性与通用性,因为它可以在不改变接口的前提下,存储并操作任意类型的值。
类型擦除技术通常涉及以下几个关键步骤:
1. 创建一个抽象基类,定义所有具体类型必须实现的接口。
2. 为每种需要擦除的类型提供一个具体类,继承自抽象基类并实现接口。
3. 利用具体类的对象来存储数据,并通过基类指针操作这些对象。
std::any内部通过一个type-erasure的机制实现这一功能,其核心是包含了一个类型擦除的类。该类封装了一个指向堆内存的指针,存储具体类型对象的副本,并提供了运行时类型识别(RTTI)的能力。
### 2.1.2 std::any的构造和析构过程
std::any的构造过程涉及到对不同类型的处理。当构造一个std::any对象时,可以根据传入的对象类型,进行适当的复制或移动操作,具体实现可能使用了完美转发(perfect forwarding)。
析构过程是std::any生命周期的结束环节。std::any保证了内部存储的对象能够被正确销毁。当std::any对象被销毁时,析构函数会首先检查存储的对象是否存在,并调用其析构函数。然后释放存储该对象的堆内存,确保不会发生内存泄漏。
```cpp
#include <any>
#include <iostream>
#include <string>
int main() {
std::any a = 42; // 构造函数存储int类型
std::cout << "Stored type is int" << std::endl;
if (a.has_value()) {
a.reset(); // 显式调用析构函数,销毁内部对象并释放内存
}
// 这时,存储的对象不再存在,any对象变为空
}
```
在这个例子中,我们看到std::any能够存储一个int类型的值,并在不需要时通过reset()方法将其销毁。
## 2.2 std::any的类型安全检查
### 2.2.1 使用std::holds_alternative进行类型判断
std::holds_alternative是C++17提供的一个工具函数,用于检查std::any对象当前是否存储了特定类型。这个函数的使用非常简单,只需要传入一个any对象和一个类型作为模板参数。如果该any对象存储的是指定的类型,则返回true,否则返回false。这是一种安全且便捷的类型检查方式,能够确保程序在运行时类型安全。
```cpp
#include <any>
#include <iostream>
#include <string>
int main() {
std::any a = 42;
if (std::holds_alternative<int>(a)) {
std::cout << "a holds an int" << std::endl;
} else if (std::holds_alternative<std::string>(a)) {
std::cout << "a holds a string" << std::endl;
}
}
```
### 2.2.2 std::bad_any_cast异常处理
std::any_cast用于从std::any对象中检索存储的值,并且在类型不匹配时抛出std::bad_any_cast异常。std::bad_any_cast是一个继承自std::exception的类,可以用来处理类型不匹配的情况。
为了处理可能抛出的std::bad_any_cast异常,我们可以在调用std::any_cast时使用try-catch块,捕获异常并进行处理。这样能够避免程序因类型不匹配而异常终止。
```cpp
#include <any>
#include <iostream>
#include <stdexcept>
#include <string>
int main() {
std::any a = std::string("Hello, any!");
try {
int i = std::any_cast<int>(a); // 尝试转换错误类型
} catch (const std::bad_any_cast& e) {
std::cerr << "Caught exception: " << e.what() << '\n';
}
}
```
## 2.3 std::any的存储机制
### 2.3.1 内置类型与自定义类型存储对比
std::any内部存储机制对内置类型和自定义类型会有所区别。对于内置类型,std::any可能会直接存储值在栈上,而对于自定义类型,它通常将对象存储在堆上,并持有指向这些对象的指针。这种策略可以优化性能和内存使用,因为内置类型通常不需要动态分配内存。
### 2.3.2 动态内存管理和性能考量
std::any使用动态内存分配来存储可能的任何类型,这包括使用new和delete进行内存的分配与释放。使用动态内存的一个缺点是需要考虑内存泄漏的风险。std::any通过析构函数自动清理存储的值,从而避免内存泄漏。
性能考量方面,std::any需要在存储和检索值时进行动态类型检查和类型转换。这些操作相对于直接操作特定类型的变量,会产生额外的性能开销。在性能敏感的应用中,使用std::any应当谨慎,并在可能的情况下避免不必要的类型转换。
```cpp
#include <any>
#include <iostream>
#include <memory>
#include <string>
int main() {
// std::any存储自定义类型的例子
std::any a = std::make_unique<std::string>("Hello");
auto str = std::any_cast<std::unique_ptr<std::string>>(a);
std::cout << *str << std::endl;
}
```
在这个例子中,我们用std::any存储了一个std::unique_ptr<std::string>的自定义类型,并在之后通过std::any_cast检索并输出了字符串。
# 3. std::any在日常开发中的应用
在现代C++开发中,std::any为开发者提供了存储任意类型对象的能力,这极大地提高了代码的灵活性和可重用性。本章将深入探讨std::any在不同场景下的实际应用,包括如何在多态容器中使用std::any、与泛型编程结合的方法以及在错误处理中的创新应用。
## 3.1 std::any在多态容器中的使用
### 3.1.1 使用std::vector<std::any>存储不同类型数据
std::vector<std::any>提供了一种方便的方式来存储不同类型的对象,这是因为它能够容纳任何类型的数据,而不需要指定容器中对象的具体类型。这在处理不预先知道具体类型的对象集合时非常有用。
```cpp
#include <any>
#include <vector>
#include <iostream>
int main() {
std::vector<std::any> container;
container.push_back(10); // 存储int类型
container.push_back(3.14); // 存储double类型
container.push_back("Example"); // 存储const char*类型
// 遍历容器并输出存储的数据
for (const auto& element : container) {
if (element.type() == typeid(int)) {
std::cout << std::any_cast<int>(element) << std::endl;
} else if (element.type() == typeid(double)) {
std::cout << std::any_cast<double>(element) << std::endl;
} else if (element.type() == typeid(const char*)) {
std::cout << std::any_cast<const char*>(element) << std::endl;
}
}
return 0;
}
```
在这个例子中,我们创建了一个`std::vector<std::any>`类型的容器,然后依次将int、double和const char*类型的数据存入。通过`element.type()`我们可以判断元素的类型,并使用`std::any_cast<T>()`函数将std::any对象转换回原始类型进行访问。
### 3.1.2 标准库算法对std::any的支持
C++标准库提供了丰富的算法支持,但并没有直接为std::any定制。因此,在使用标准库算法处理std::any时,需要结合lambda表达式和类型判断来实现。
```cpp
#include <any>
#include <vector>
#include <algorithm>
#include <iostream>
int main() {
std::vector<std::any> container = {1, 2.5, "text"};
// 使用std::transform和lambda表达式来转换每个元素到string
std::transform(container.begin(), container.end(), container.begin(),
[](const std::any& element) -> std::string {
if (element.type() == typeid(int)) {
return "int: " + std::to_string(std::any_cast<int>(element));
} else if (element.type() == typeid(double)) {
return "double: " + std::to_string(std::any_cast<double>(element));
} else if (element.type() == typeid(const char*)) {
return "string: " + std::any_cast<const char*>(element);
}
return "";
});
// 输出转换后的结果
for (const auto& element : container) {
std::cout << element.type().name() << ": " << element.convert<std::string>() << std::endl;
}
return 0;
}
```
上述代码中,我们使用了`std::transform`算法和lambda表达式对容器中的每个元素进行了处理,将不同类型的元素转换成string类型并输出。这里使用了`std::any::type()`来获取元素的类型信息,并用`std::any_cast<T>()`进行了类型转换。
## 3.2 std::any与泛型编程
### 3.2.1 泛型编程中std::any的角色
泛型编程强调编写与数据类型无关的代码,std::any为泛型编程提供了存储任意类型值的能力,使得泛型容器和函数可以更加灵活地处理数据。
```cpp
#include <any>
#include <iostream>
#include <type_traits>
template<typename
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探索 C++ 中的 std::any,这是一款强大的类型安全容器。通过 20 个技巧、工作原理解析、案例研究和比较,它提供了一个全面的指南,涵盖从入门到精通的各个方面。从 void* 的演变到 std::variant 的对比,再到内存管理、多态实现和性能分析,该专栏揭示了 std::any 的强大功能。它还探讨了异常安全性、初始化和赋值技巧、类型识别、异常处理、跨框架兼容性、线程安全性和序列化,为开发人员提供了在现代 C++ 开发中有效利用 std::any 的全面见解。此外,它还讨论了 std::any 的局限性、替代方案和在数据结构、软件架构和泛型编程中的应用,为开发人员提供了全面的资源,以充分利用 std::any 的潜力。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
JY01A直流无刷IC全攻略:深入理解与高效应用

# 摘要
本文详细介绍了JY01A直流无刷IC的设计、功能和应用。文章首先概述了直流无刷电机的工作原理及其关键参数,随后探讨了JY01A IC的功能特点以及与电机集成的应用。在实践操作方面,本文讲解了JY01A IC的硬件连接、编程控制,并通过具体
【S参数转换表准确性】:实验验证与误差分析深度揭秘

# 摘要
本文详细探讨了S参数转换表的准确性问题,首先介绍了S参数的基本概念及其在射频领域的应用,然后通过实验验证了S参数转换表的准确性,并分析了可能的误差来源,包括系统误差和随机误差。为了减小误差,本文提出了一系列的硬件优化措施和软件算法改进策略。最后,本文展望了S参数测量技术的新进展和未来的研究方向,指出了理论研究和实际应用创新的重要性。
# 关键字
S参
【TongWeb7内存管理教程】:避免内存泄漏与优化技巧
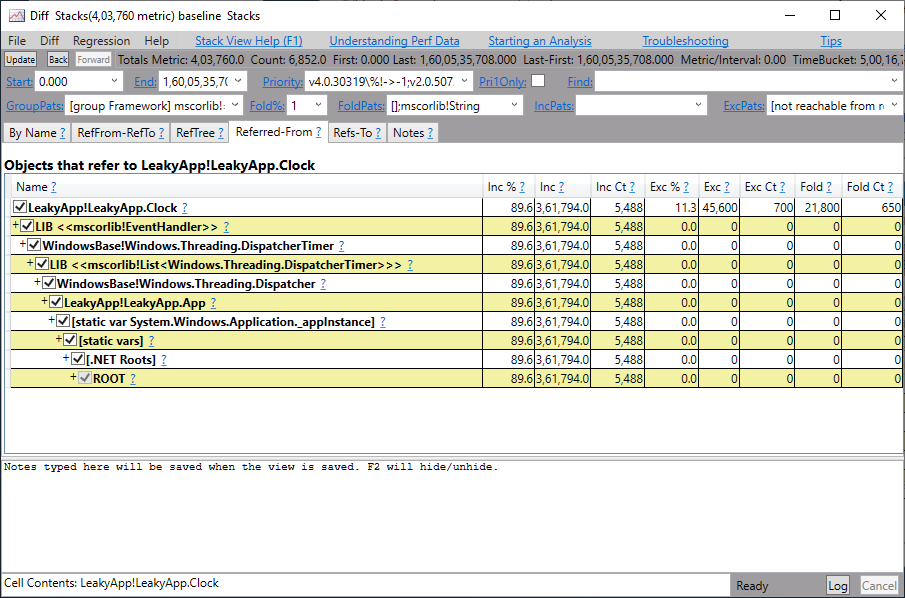
# 摘要
本文旨在深入探讨TongWeb7的内存管理机制,重点关注内存泄漏的理论基础、识别、诊断以及预防措施。通过详细阐述内存池管理、对象生命周期、分配释放策略和内存压缩回收技术,文章为提升内存使用效率和性能优化提供了实用的技术细节。此外,本文还介绍了一些性能优化的基本原则和监控分析工具的应用,以及探讨了企业级内存管理策略、自动内存管理工具和未来内存管理技术的发展趋
无线定位算法优化实战:提升速度与准确率的5大策略
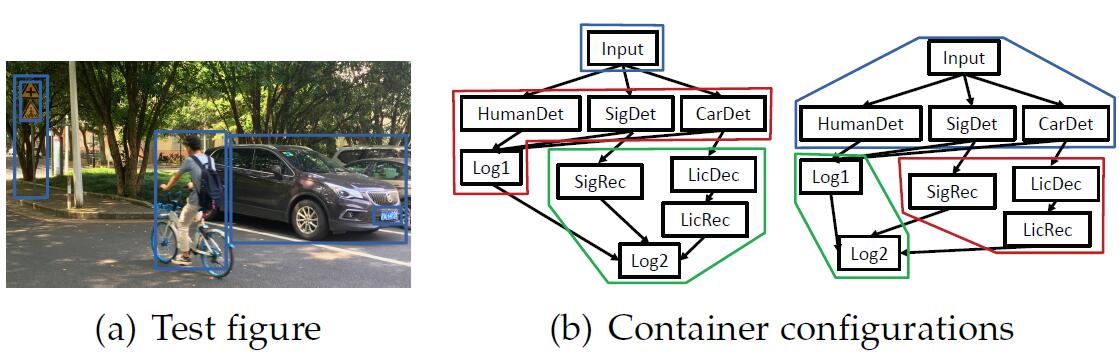
# 摘要
本文综述了无线定位技术的原理、常用算法及其优化策略,并通过实际案例分析展示了定位系统的实施与优化。第一章为无线定位技术概述,介绍了无线定位技术的基础知识。第二章详细探讨了无线定位算法的分类、原理和常用算法,包括距离测量技术和具体定位算法如三角测量法、指纹定位法和卫星定位技术。第三章着重于提升定位准确率、加速定位速度和节省资源消耗的优化策略。第四章通过分析室内导航系统和物联网设备跟踪的实际应用场景,说明了定位系统优化实施
成本效益深度分析:ODU flex-G.7044网络投资回报率优化
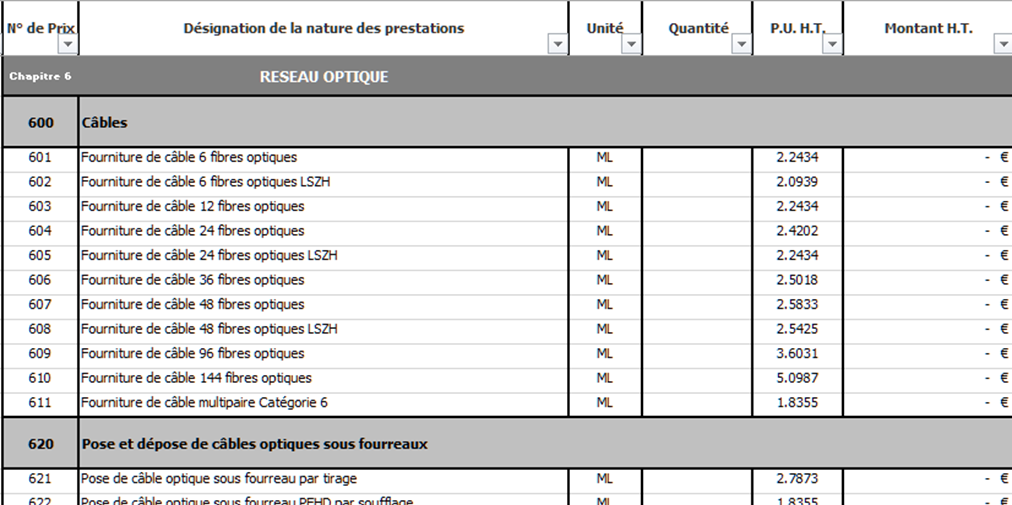
# 摘要
本文旨在介绍ODU flex-G.7044网络技术及其成本效益分析。首先,概述了ODU flex-G.7044网络的基础架构和技术特点。随后,深入探讨成本效益理论,包括成本效益分析的基本概念、应用场景和局限性,以及投资回报率的计算与评估。在此基础上,对ODU flex-G.7044网络的成本效益进行了具体分析,考虑了直接成本、间接成本、潜在效益以及长期影响。接着,提出优化投资回报
【Delphi编程智慧】:进度条与异步操作的完美协调之道

# 摘要
本文旨在深入探讨Delphi编程环境中进度条的使用及其与异步操作的结合。首先,基础章节解释了进度条的工作原理和基础应用。随后,深入研究了Delphi中的异步编程机制,包括线程和任务管理、同步与异步操作的原理及异常处理。第三章结合实
C语言编程:构建高效的字符串处理函数
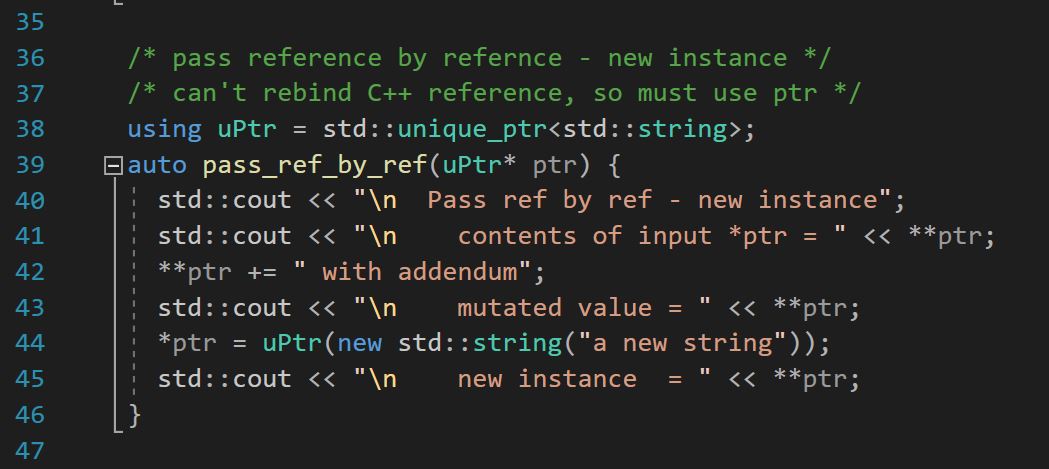
# 摘要
字符串处理是编程中不可或缺的基础技能,尤其在C语言中,正确的字符串管理对程序的稳定性和效率至关重要。本文从基础概念出发,详细介绍了C语言中字符串的定义、存储、常用操作函数以及内存管理的基本知识。在此基础上,进一步探讨了高级字符串处理技术,包括格式化字符串、算法优化和正则表达式的应用。
【抗干扰策略】:这些方法能极大提高PID控制系统的鲁棒性
# 摘要
PID控制系统作为一种广泛应用于工业过程控制的经典反馈控制策略,其理论基础、设计步骤、抗干扰技术和实践应用一直是控制工程领域的研究热点。本文从PID控制器的工作原理出发,系统介绍了比例(P)、积分(I)、微分(D)控制的作用,并探讨了系统建模、控制器参数整定及系统稳定性的分析方法。文章进一步分析了抗干扰技术,并通过案例分析展示了PID控制在工业温度和流量控制系统中的优化与仿真。最后,文章展望了PID控制系统的高级扩展,如
业务连续性的守护者:中控BS架构考勤系统的灾难恢复计划

# 摘要
本文旨在探讨中控BS架构考勤系统的业务连续性管理,概述了业务连续性的重要性及其灾难恢复策略的制定。首先介绍了业务连续性的基础概念,并对其在企业中的重要性进行了详细解析。随后,文章深入分析了灾难恢复计划的组成要素、风险评估与影响分析方法。重点阐述了中控BS架构在硬件冗余设计、数据备份与恢复机制以及应急响应等方面的策略。
自定义环形菜单

# 摘要
本文探讨了环形菜单的设计理念、理论基础、开发实践、测试优化以及创新应用。首先介绍了环形菜单的设计价值及其在用户交互中的应用。接着,阐述了环形菜单的数学基础、用户交互理论和设计原则,为深入理解环形菜单提供了坚实的理论支持。随后,文章详细描述了环形菜单的软件实现框架、核心功能编码以及界面与视觉设计的开发实践。针对功能测试和性能优化,本文讨论了测试方法和优化策略,确保环形菜单的可用性和高效性。最后,展望了环形菜单在新兴领域的
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )