PyTorch分布式数据加载优化:数据流水线最佳实践与性能提升
发布时间: 2024-12-12 05:56:08 阅读量: 15 订阅数: 15 

实现SAR回波的BAQ压缩功能
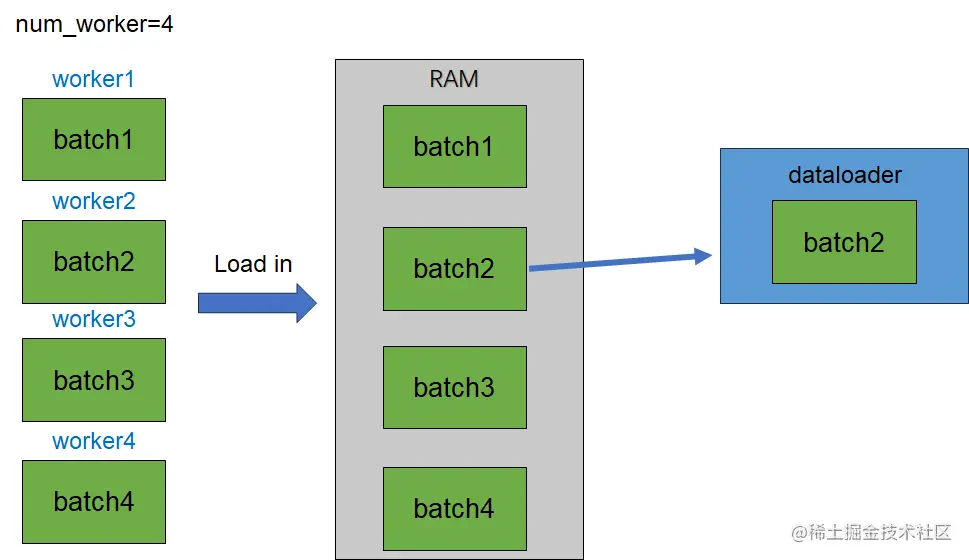
# 1. 分布式数据加载基础知识
## 1.1 分布式数据加载的重要性
在处理大规模数据时,单机资源往往无法满足需求。分布式数据加载应运而生,它允许我们将数据分布到多个设备上并行处理,极大地提高了数据处理的速度和效率。这种技术是构建高性能深度学习模型不可或缺的一部分。
## 1.2 分布式计算架构概述
分布式计算架构涉及多个计算节点,它们通过网络相互连接,并协调工作以共同完成任务。在这种架构下,数据通常被分割成小块,然后分布到各个节点上进行独立处理。数据加载需要特别设计以适应这种分布式环境,确保数据加载的效率和一致性。
## 1.3 分布式数据加载与传统加载方法的区别
传统的数据加载方法通常依赖于单机的内存和CPU资源,而分布式数据加载则需要考虑跨节点的数据传输、节点间同步以及容错等问题。为了实现高效的数据加载,需要在数据分布策略、负载均衡、容错机制等多方面进行优化。
## 1.4 分布式数据加载面临的挑战
分布式数据加载不仅需要高效的数据传输和节点协调策略,还需要关注数据一致性和系统稳定性。挑战包括但不限于网络带宽限制、不同节点处理速度差异、数据同步与一致性维护等。解决这些挑战对于提升分布式系统的性能至关重要。
# 2. PyTorch数据流水线优化理论
## 2.1 数据流水线概述
### 2.1.1 数据流水线的基本概念
数据流水线,亦称为数据管道(Data Pipeline),在深度学习框架中,是指将数据从原始状态加工处理为模型输入的过程。这一过程涉及到数据的加载、预处理、转换和批处理等多个步骤。理想的数据流水线能够保证模型训练的连续性和高效性,减少资源浪费,提升数据吞吐量。
数据流水线的优化,主要围绕提高数据加载效率、减少I/O瓶颈、并行化处理等方面进行。优化后的流水线不仅能够支持更高效的模型训练,同时也能满足大规模数据集上的实时数据处理需求。
### 2.1.2 传统数据加载方法的局限性
在深入介绍PyTorch优化之前,我们首先要理解传统数据加载方法的一些局限性:
1. **单线程加载限制**:传统方法往往依赖单线程进行数据加载,这在CPU和I/O资源较为紧张的情况下,会成为训练的瓶颈。
2. **内存使用不当**:不合理的内存管理会导致频繁的内存分配和释放,从而影响加载效率。
3. **缺乏灵活性**:固定的数据处理流程不利于针对特定任务做优化。
## 2.2 PyTorch中的数据加载工具
### 2.2.1 Dataset和DataLoader
在PyTorch中,`Dataset`是一个抽象类,它定义了数据集对象应提供的基本功能,例如`__len__`方法和`__getitem__`方法。`DataLoader`利用`Dataset`来提供批量数据迭代功能,它能够结合多线程进行数据预取(prefetching),从而提高数据加载效率。
```python
from torch.utils.data import Dataset, DataLoader
class CustomDataset(Dataset):
def __init__(self):
# 初始化数据集,加载数据等
pass
def __len__(self):
# 返回数据集大小
pass
def __getitem__(self, idx):
# 根据索引获取数据
pass
# 使用DataLoader
data_loader = DataLoader(dataset=CustomDataset(), batch_size=32, shuffle=True)
```
`DataLoader`主要参数如下:
- `batch_size`: 每个批次加载的数据样本数。
- `shuffle`: 在每个epoch开始时是否打乱数据。
- `num_workers`: 多线程加载数据的数量。
### 2.2.2 IterableDataset和自定义数据加载策略
除了`Dataset`,PyTorch还提供了`IterableDataset`。这个类更适合于那些无法按索引访问的数据集。例如,当数据是从数据库或其他复杂的数据流中读取时,`IterableDataset`就变得非常有用。
自定义数据加载策略,包括但不限于对数据进行实时的增广处理、多级缓存机制以及将数据加载到GPU内存等,这些都是提高数据加载效率的重要手段。
## 2.3 数据加载性能优化理论
### 2.3.1 缓存机制的引入
缓存机制在数据加载中扮演着重要角色。通过将频繁访问的数据保存在快速的存储介质上(如RAM或SSD),可以显著减少数据加载时间。
PyTorch提供了多种缓存策略,包括在内存中缓存整个数据集或仅缓存数据子集等。合理地设置缓存策略,可以使数据加载与模型训练之间实现更加平滑的衔接。
### 2.3.2 多线程和多进程的并行加载策略
为了充分利用现代多核处理器的计算能力,PyTorch引入了多线程或多进程并行加载数据的机制。在`DataLoader`中,参数`num_workers`可以设置为大于0的整数来启用多线程。
但是,在使用多进程加载数据时需要注意,由于进程间通信(IPC)的存在,进程间的开销可能会比多线程大。因此,在选择并行加载策略时,需要在多线程的简单和多进程的隔离之间做出权衡。
在实际操作中,多线程或多进程的使用会受到数据集特性和硬件资源的限制,因此在优化数据加载性能时,通常需要进行多次实验,找到最优解。
```mermaid
graph TD
A[开始数据加载优化]
A --> B[分析数据流水线瓶颈]
B --> C[引入缓存机制]
B --> D[设置合适的num_workers]
C -
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 PyTorch 分布式训练的方方面面,从零基础入门到高级优化实践,提供了全面的指南。它涵盖了分布式训练的秘诀、数据和模型并行策略、数据加载优化、进程组和初始化策略、性能监控、梯度累积和裁剪、模型保存和加载、自定义通信后端、通信瓶颈解决方案、跨网络环境的挑战、小批量数据训练加速以及 NCCL 通信库的应用。通过深入分析和实战演练,本专栏旨在帮助读者充分利用 PyTorch 的分布式训练功能,提升深度学习模型训练的效率和性能。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【电力驱动系统安全风险评估】:IEC 61800-5-1标准下的风险分析技巧

参考资源链接:[最新版IEC 61800-5-1标准:电力驱动系统安全要求](https://wenku.csdn.net/doc/7dpwnubzwr?spm=1055.2635.3001.10343)
# 1. IEC 61800-5-1标准概述
IEC 6
【硬件更新与维护攻略】:TIA博途V16维护经验分享

参考资源链接:[TIA博途V16仿真问题全解:启动故障与解决策略](https://wenku.csdn.net/doc/4x9dw4jntf?spm=1055.2635.3001.10343)
# 1. TIA博途V16基础介绍
## 1.1 TIA博途V16概览
TIA博途(Totally Integrated Automation Portal)是西门子公司
Altium 设计者的挑战:15分钟内解决元器件间距过小问题
参考资源链接:[altium中单个元器件的安全间距设置](https://wenku.csdn.net/doc/645e35325928463033a48e73?spm=1055.2635.3001.10343)
# 1. Altium Designer中的元器件布局挑战
在当今的电子设计自
MATLAB信号处理全攻略:一步到位掌握入门到高级技巧(限时免费教程)

参考资源链接:[MATLAB信号处理实验详解:含源代码的课后答案](https://wenku.csdn.net/doc/4wh8fchja4?spm=1055.2635.3001.10343)
# 1. MATLA
【BMC管理控制器深度剖析】:戴尔服务器专家指南

参考资源链接:[戴尔 服务器设置bmc](https://wenku.csdn.net/doc/647062d0543f844488e4644b?spm=1055.2635.3001.10343)
# 1. BMC管理控制器概述
BMC(Baseboard Management Controller)管理控制器是数据中心和企业级计算领域的核心组件之一。它负责监控和管理服务器的基础硬
PSCAD C语言接口实战秘籍:从零到精通的7天速成计划

参考资源链接:[PSCAD 4.5中C语言接口实战:简易积分器开发教程](https://wenku.csdn.net/doc/6472bc52d12cbe7ec306319f?spm=1055.2635.3001.10343)
# 1. PSCAD软件概述与C语言接口简介
在现代电力系统仿真领域,PSCAD(Power Systems Computer Aide
RK3588射频设计与布局:提升无线通信性能的关键技巧
参考资源链接:[RK3588硬件设计全套资料,原理图与PCB文件下载](https://wenku.csdn.net/doc/89nop3h5n
微信视频通话质量提升必杀技:虚拟摄像头高级设置全解

参考资源链接:[使用VTube Studio与OBS Studio在微信进行虚拟视频通话的探索](https://wenku.csdn.net/doc/85s1wr0wvy?spm=1055.2635.3001.10343)
# 1. 虚拟摄像头技术概述
在信息技术高速发展的今天,虚拟摄像头技术以其独特的魅力,成为了一个引人注目的
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )