【Trie树实战指南】:从构建到应用,全面掌握Trie树技术
发布时间: 2024-08-24 03:05:49 阅读量: 42 订阅数: 40 

Python实现Trie(前缀树):构建与应用
# 1. Trie树的基本原理和算法
Trie树,又称单词查找树,是一种高效的数据结构,用于存储和检索字符串。其基本原理是将字符串逐个字符插入树中,每个字符对应一个树节点,形成一个树形结构。
Trie树的算法主要包括插入和查找操作。插入操作将一个字符串逐个字符插入树中,如果遇到已存在的字符,则继续沿该分支插入,否则创建新节点。查找操作从树根开始,逐个字符比较,如果字符匹配则继续沿该分支查找,否则返回失败。
Trie树的优点在于其查询效率高,查找一个字符串的时间复杂度为 O(m),其中 m 为字符串的长度。此外,Trie树还支持前缀查找,可以快速找到所有以特定前缀开头的字符串。
# 2. Trie树的构建与优化
### 2.1 Trie树的构建算法
Trie树的构建算法包括插入和删除操作。
#### 2.1.1 插入操作
**代码块:**
```python
def insert(self, word):
"""
插入一个单词到Trie树中。
参数:
word: 要插入的单词。
"""
node = self.root
for char in word:
if char not in node.children:
node.children[char] = TrieNode()
node = node.children[char]
node.is_word = True
```
**逻辑分析:**
1. 从根节点开始遍历 Trie树。
2. 对于单词中的每个字符,检查当前节点的子节点中是否包含该字符。
3. 如果不包含,则创建一个新的子节点并将其添加到当前节点的子节点中。
4. 将当前节点更新为新创建的子节点。
5. 当遍历完单词中的所有字符后,将当前节点标记为单词结束节点。
**参数说明:**
* `self`: Trie树对象。
* `word`: 要插入的单词。
#### 2.1.2 删除操作
**代码块:**
```python
def delete(self, word):
"""
从Trie树中删除一个单词。
参数:
word: 要删除的单词。
"""
node = self.root
for char in word:
if char not in node.children:
return False # 单词不存在
node = node.children[char]
if not node.is_word:
return False # 单词不存在
node.is_word = False
if not node.children:
del node.children[char]
```
**逻辑分析:**
1. 从根节点开始遍历 Trie树。
2. 对于单词中的每个字符,检查当前节点的子节点中是否包含该字符。
3. 如果不包含,则返回 False,表示单词不存在。
4. 将当前节点更新为新创建的子节点。
5. 当遍历完单词中的所有字符后,将当前节点标记为非单词结束节点。
6. 如果当前节点没有子节点,则将其从父节点的子节点中删除。
**参数说明:**
* `self`: Trie树对象。
* `word`: 要删除的单词。
### 2.2 Trie树的优化策略
Trie树的优化策略包括节点合并和哈希表加速。
#### 2.2.1 节点合并
**代码块:**
```python
def merge_nodes(self):
"""
合并相邻的空节点。
"""
queue = [self.root]
while queue:
node = queue.pop()
if not node.children:
del node.parent.children[node.char]
else:
for child in node.children.values():
child.parent = node.parent
queue.append(child)
```
**逻辑分析:**
1. 从根节点开始,将所有节点加入队列。
2. 循环遍历队列,弹出当前节点。
3. 如果当前节点没有子节点,则将其从父节点的子节点中删除。
4. 否则,将当前节点的子节点加入队列。
**参数说明:**
* `self`: Trie树对象。
#### 2.2.2 哈希表加速
**代码块:**
```python
class TrieNode:
def __init__(self):
self.children = {}
self.is_word = False
self.hash_table = {}
```
**逻辑分析:**
在 Trie 节点中添加一个哈希表,用于存储子节点的字符和子节点的引用。
**参数说明:**
* `self`: Trie 节点对象。
# 3.1 文本处理
#### 3.1.1 单词查找和纠错
Trie树在文本处理中发挥着至关重要的作用,尤其是在单词查找和纠错方面。
**单词查找**
Trie树通过将单词存储在分支中,实现了高效的单词查找。当查询一个单词时,算法从根节点开始,沿着与单词第一个字母相对应的分支向下遍历。此过程一直持续到单词的最后一个字母,如果到达单词的叶节点,则说明单词存在于Trie树中。
**代码块:**
```python
def search(trie, word):
"""
在Trie树中查找单词。
参数:
trie: Trie树
word: 要查找的单词
返回:
True 如果单词存在,否则为 False
"""
node = trie.root
for char in word:
if char not in node.children:
return False
node = node.children[char]
return node.is_word
```
**逻辑分析:**
此代码块实现了Trie树中的单词查找操作。它从根节点开始,逐个字符地遍历单词,并检查每个字符是否在当前节点的子节点中。如果字符存在,则算法沿着该分支向下移动。如果到达单词的最后一个字符,并且该节点标记为单词结束符,则说明单词存在于Trie树中。
**单词纠错**
Trie树还可用于纠正拼写错误的单词。通过利用Trie树的结构,算法可以识别与查询单词相似的单词。
**代码块:**
```python
def spell_check(trie, word):
"""
纠正拼写错误的单词。
参数:
trie: Trie树
word: 拼写错误的单词
返回:
与拼写错误单词最相似的单词列表
"""
suggestions = []
queue = [trie.root]
while queue:
node = queue.pop()
if node.is_word:
suggestions.append(node.word)
for child in node.children.values():
if child.char in word:
queue.append(child)
return suggestions
```
**逻辑分析:**
此代码块实现了Trie树中的单词纠错操作。它从根节点开始,将所有可能的单词前缀添加到队列中。然后,它逐个处理队列中的每个节点,检查其是否为单词结束符。如果是,则将该单词添加到建议列表中。算法还检查每个节点的子节点,如果子节点的字符出现在拼写错误的单词中,则将其添加到队列中,以进一步探索可能的单词。
#### 3.1.2 文本压缩和分词
Trie树在文本压缩和分词中也扮演着重要的角色。
**文本压缩**
Trie树可以用于对文本进行无损压缩。通过将单词存储在Trie树中,算法可以消除文本中的冗余。当压缩文本时,算法将每个单词替换为其在Trie树中的索引。
**分词**
Trie树还可以用于对文本进行分词。通过利用Trie树的结构,算法可以识别文本中的单词边界。当对文本进行分词时,算法从文本的开头开始,逐个字符地遍历文本。如果当前字符与Trie树中的任何分支相匹配,则算法将该字符添加到当前单词中。如果当前字符不与任何分支相匹配,则算法将当前单词添加到单词列表中,并从当前字符开始一个新的单词。
# 4. Trie树的高级应用
### 4.1 机器学习
#### 4.1.1 特征工程和词嵌入
Trie树在机器学习中广泛用于特征工程和词嵌入。在特征工程中,Trie树可以将文本数据转换为数值特征,便于机器学习模型处理。例如,在文本分类任务中,Trie树可以将单词转换为唯一的整数 ID,从而构建单词-ID 映射。
词嵌入是将单词表示为低维向量的技术。Trie树可以帮助构建单词嵌入,方法是利用单词在树中的结构信息。例如,在 Word2Vec 模型中,单词嵌入是通过遍历 Trie 树并聚合单词上下文的共现信息来生成的。
#### 4.1.2 模型训练和评估
Trie树还可以用于机器学习模型的训练和评估。例如,在决策树模型中,Trie 树可以用于快速查找训练数据中的最佳分割点。在支持向量机模型中,Trie 树可以用于计算单词之间的相似度,从而构建核函数。
### 4.2 自然语言处理
#### 4.2.1 词性标注和句法分析
Trie树在自然语言处理中扮演着重要角色,尤其是在词性标注和句法分析中。词性标注是将单词标记为其词性(例如,名词、动词、形容词)。Trie 树可以存储单词和它们的词性,从而快速查找单词的词性。
句法分析是确定句子中单词之间的语法关系。Trie 树可以用于构建句法分析器,该分析器可以识别句子中的短语和从句。
#### 4.2.2 机器翻译和文本摘要
Trie树还用于机器翻译和文本摘要。在机器翻译中,Trie 树可以存储目标语言的单词和短语,从而快速生成翻译结果。在文本摘要中,Trie 树可以用于提取文本中的关键短语和句子,从而生成摘要。
### 代码示例
#### 词性标注
```python
import nltk
# 创建 Trie 树存储词性和单词
trie = nltk.Trie()
trie["apple"] = "noun"
trie["eat"] = "verb"
trie["the"] = "determiner"
# 查找单词的词性
word = "apple"
pos = trie[word]
print(f"词性:{pos}")
```
#### 句法分析
```python
import nltk
# 创建 Trie 树存储句法规则
trie = nltk.Trie()
trie["NP"] = ["DT", "NN"]
trie["VP"] = ["VB", "NP"]
trie["S"] = ["NP", "VP"]
# 解析句子
sentence = "The apple is red."
tokens = nltk.word_tokenize(sentence)
tags = nltk.pos_tag(tokens)
# 使用 Trie 树查找句子的语法结构
tree = nltk.Tree.fromstring("S")
for token, tag in tags:
if tag in trie:
tree.append(nltk.Tree(tag, [token]))
print(f"语法结构:{tree}")
```
# 5. Trie树的实现与扩展
### 5.1 不同语言中的Trie树实现
Trie树的实现因编程语言而异,但核心算法和数据结构基本相同。以下介绍两种流行语言中的Trie树实现:
#### 5.1.1 C++中的Trie树
```cpp
class TrieNode {
public:
bool is_word;
unordered_map<char, TrieNode*> children;
TrieNode() : is_word(false) {}
};
class Trie {
public:
TrieNode* root;
Trie() : root(new TrieNode()) {}
void insert(const string& word) {
TrieNode* curr = root;
for (char c : word) {
if (!curr->children.count(c)) {
curr->children[c] = new TrieNode();
}
curr = curr->children[c];
}
curr->is_word = true;
}
bool search(const string& word) {
TrieNode* curr = root;
for (char c : word) {
if (!curr->children.count(c)) {
return false;
}
curr = curr->children[c];
}
return curr->is_word;
}
};
```
**逻辑分析:**
* TrieNode类表示Trie树中的节点,包含一个布尔值`is_word`表示该节点是否代表一个单词的结尾,以及一个`unordered_map<char, TrieNode*>`表示该节点的子节点。
* Trie类表示整个Trie树,包含一个根节点`root`。
* `insert`函数用于插入一个单词到Trie树中。它遍历单词的每个字符,并在Trie树中创建或查找相应的节点。如果单词的最后一个字符的节点不存在,则创建一个新的节点并标记为单词结尾。
* `search`函数用于在Trie树中查找一个单词。它遍历单词的每个字符,并在Trie树中查找相应的节点。如果任何字符的节点不存在,则返回false。如果单词的最后一个字符的节点存在且标记为单词结尾,则返回true。
#### 5.1.2 Python中的Trie树
```python
class TrieNode:
def __init__(self):
self.children = {}
self.is_word = False
class Trie:
def __init__(self):
self.root = TrieNode()
def insert(self, word):
curr = self.root
for char in word:
if char not in curr.children:
curr.children[char] = TrieNode()
curr = curr.children[char]
curr.is_word = True
def search(self, word):
curr = self.root
for char in word:
if char not in curr.children:
return False
curr = curr.children[char]
return curr.is_word
```
**逻辑分析:**
* TrieNode类表示Trie树中的节点,包含一个字典`children`表示该节点的子节点,以及一个布尔值`is_word`表示该节点是否代表一个单词的结尾。
* Trie类表示整个Trie树,包含一个根节点`root`。
* `insert`函数用于插入一个单词到Trie树中。它遍历单词的每个字符,并在Trie树中创建或查找相应的节点。如果单词的最后一个字符的节点不存在,则创建一个新的节点并标记为单词结尾。
* `search`函数用于在Trie树中查找一个单词。它遍历单词的每个字符,并在Trie树中查找相应的节点。如果任何字符的节点不存在,则返回false。如果单词的最后一个字符的节点存在且标记为单词结尾,则返回true。
### 5.2 Trie树的扩展和变体
Trie树是一种灵活的数据结构,可以扩展和修改以满足不同的需求。以下介绍两种常见的Trie树扩展:
#### 5.2.1 前缀树
前缀树是一种Trie树的变体,它存储所有以特定前缀开头的单词。它通常用于快速查找所有以特定前缀开头的单词,例如自动补全功能。
#### 5.2.2 后缀树
后缀树是一种Trie树的变体,它存储所有以特定后缀结尾的单词。它通常用于快速查找所有以特定后缀结尾的单词,例如模式匹配和字符串搜索。
# 6. Trie树的性能分析与调优
### 6.1 性能瓶颈分析
#### 6.1.1 内存占用
Trie树的内存占用与树的深度和节点数呈正相关。对于大型数据集,Trie树可能占用大量内存,导致性能下降。
#### 6.1.2 查询效率
Trie树的查询效率取决于树的深度和匹配字符串的长度。对于深度较深的Trie树,查询需要遍历多个节点,导致查询效率下降。
### 6.2 调优策略
#### 6.2.1 存储结构优化
* **前缀压缩:**对于具有大量公共前缀的字符串,可以采用前缀压缩技术,将公共前缀存储在单个节点中,从而减少内存占用。
* **哈希表加速:**对于频繁查询的字符串,可以采用哈希表加速查询。将字符串映射到哈希表中,查询时直接查找哈希表,避免遍历Trie树。
#### 6.2.2 算法优化
* **并行查询:**对于多核处理器,可以采用并行查询技术,将查询任务分配到不同的核上执行,提高查询效率。
* **剪枝策略:**在查询过程中,可以采用剪枝策略,提前终止不匹配的查询,减少不必要的遍历。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏全面介绍了 Trie 树技术,从构建原理到实战应用。它涵盖了 Trie 树在文本处理、网络路由、词典构建、机器学习等领域的应用,并提供了性能优化技巧。此外,专栏还深入探讨了数据库索引失效、死锁问题、性能提升秘籍、表锁问题等数据库相关技术。对于分布式系统,专栏分析了架构设计、数据一致性保障、高可用性设计和负载均衡策略,为读者提供了全面而实用的技术指南。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
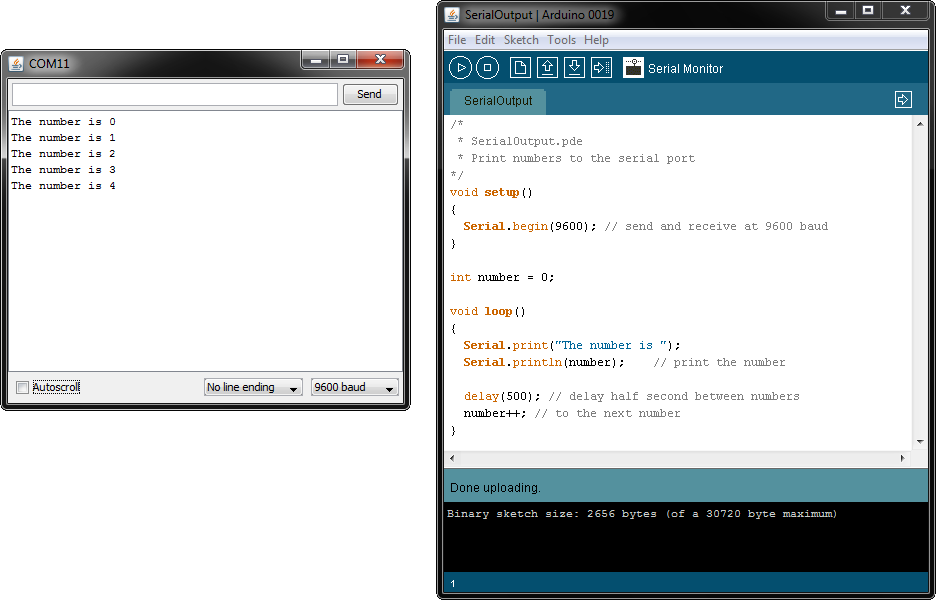
微机接口技术深度解析:串并行通信原理与实战应用
# 摘要
微机接口技术是计算机系统中不可或缺的部分,涵盖了从基础通信理论到实际应用的广泛内容。本文旨在提供微机接口技术的全面概述,并着重分析串行和并行通信的基本原理与应用,包括它们的工作机制、标准协议及接口技术。通过实例介绍微机接口编程的基础知识、项目实践以及在实际应用中的问题解决方法。本文还探讨了接口技术的新兴趋势、安全性和兼容
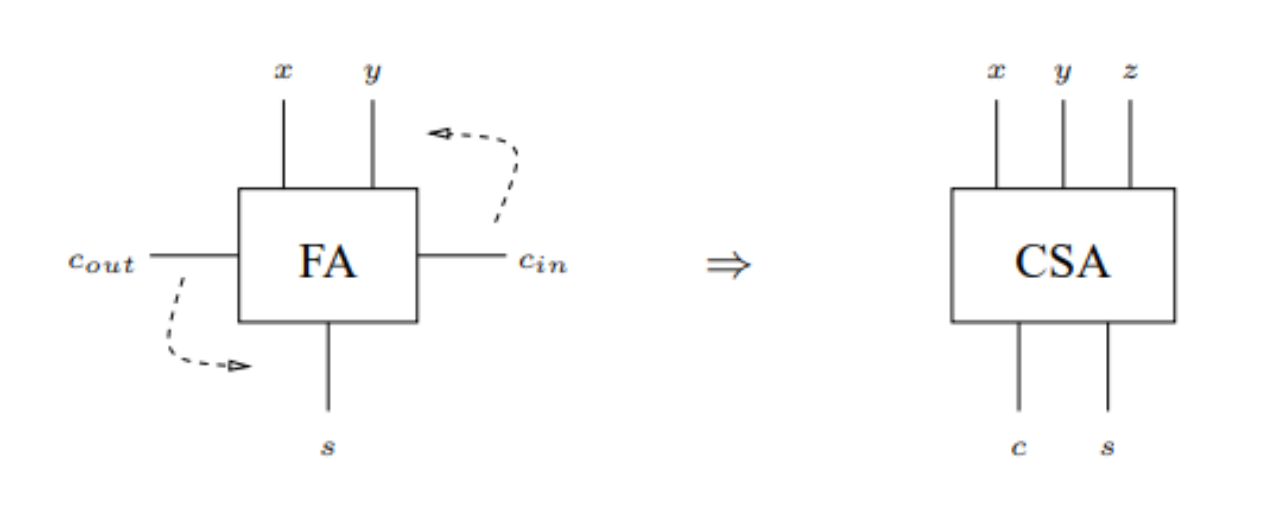
【进位链技术大剖析】:16位加法器进位处理的全面解析
# 摘要
进位链技术是数字电路设计中的基础,尤其在加法器设计中具有重要的作用。本文从进位链技术的基础知识和重要性入手,深入探讨了二进制加法的基本规则以及16位数据表示和加法的实现。文章详细分析了16位加法器的工作原理,包括全加器和半加器的结构,进位链的设计及其对性能的影响,并介绍了进位链优化技术。通过实践案例,本文展示了进位链技术在故障诊断与维护中的应用,并探讨了其在多位加法器设计以及多处理器系统中的高级应用。最后,文章展望了进位链技术的未来,
【均匀线阵方向图秘籍】:20个参数调整最佳实践指南
# 摘要
均匀线阵方向图是无线通信和雷达系统中的核心技术之一,其设计和优化对系统的性能至关重要。本文系统性地介绍了均匀线阵方向图的基础知识,理论基础,实践技巧以及优化工具与方法。通过理论与实际案例的结合,分析了线阵的基本概念、方向图特性、理论参数及其影响因素,并提出了方向图参数调整的多种实践技巧。同时,本文探讨了仿真软件和实验测量在方向图优化中的应用,并介绍了最新的优化算法工具。最后,展望了均匀线阵方向图技术的发展趋势,包括新型材料和技术的应用、智能化自适应方向图的研究,以及面临的技术挑战与潜在解决方案。
# 关键字
均匀线阵;方向图特性;参数调整;仿真软件;优化算法;技术挑战
参考资源链
ISA88.01批量控制:制药行业的实施案例与成功经验

# 摘要
ISA88.01标准为批量控制系统提供了框架和指导原则,尤其是在制药行业中,其应用能够显著提升生产效率和产品质量控制。本文详细解析了ISA88.01标准的概念及其在制药工艺中的重要
实现MVC标准化:肌电信号处理的5大关键步骤与必备工具

# 摘要
本文探讨了MVC标准化在肌电信号处理中的关键作用,涵盖了从基础理论到实践应用的多个方面。首先,文章介绍了
【FPGA性能暴涨秘籍】:数据传输优化的实用技巧
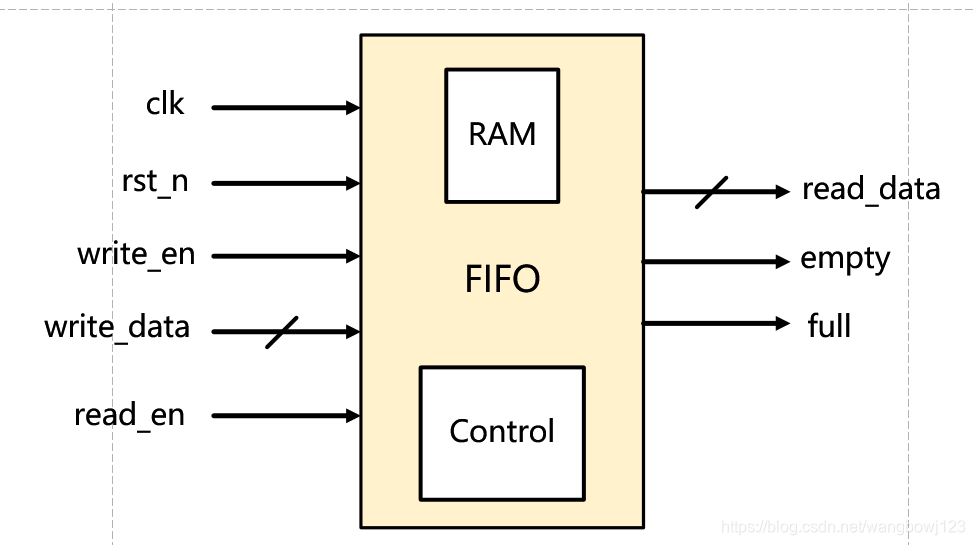
# 摘要
本文全面介绍了FPGA在数据传输领域的应用和优化技巧。首先,对FPGA和数据传输的基本概念进行了介绍,然后深入探讨了FPGA内部数据流的理论基础,包
PCI Express 5.0性能深度揭秘:关键指标解读与实战数据分析

# 摘要
PCI Express(PCIe)技术作为计算机总线标准,不断演进以满足高速数据传输的需求。本文首先概述PCIe技术,随后深入探讨PCI Express 5.0的关键技术指标,如信号传输速度、编码机制、带宽和吞吐量的理论极限以及兼容性问题。通过实战数据分析,评估PCI Express
CMW100 WLAN指令手册深度解析:基础使用指南揭秘
# 摘要
CMW100 WLAN指令是业界广泛使用的无线网络测试和分析工具,为研究者和工程师提供了强大的网络诊断和性能评估能力。本文旨在详细介绍CMW100 WLAN指令的基础理论、操作指南以及在不同领域的应用实例。首先,文章从工作原理和系统架构两个层面探讨了CMW100 WLAN指令的基本理论,并解释了相关网络协议。随后,提供了详细的操作指南,包括配置、调试、优化及故障排除方法。接着,本文探讨了CMW100 WLAN指令在网络安全、网络优化和物联网等领域的实际应用。最后,对CMW100 WLAN指令的进阶应用和未来技术趋势进行了展望,探讨了自动化测试和大数据分析中的潜在应用。本文为读者提供了
三菱FX3U PLC与HMI交互:打造直觉操作界面的秘籍

# 摘要
本论文详细介绍了三菱FX3U PLC与HMI的基本概念、工作原理及高级功能,并深入探讨了HMI操作界面的设计原则和高级交互功能。通过对三菱FX3U PLC的编程基础与高级功能的分析,本文提供了一系列软件集成、硬件配置和系统测试的实践案例,以及相应的故障排除方法。此外,本文还分享了在不同行业应用中的案例研究,并对可能出现的常见问题提出了具体的解决策略。最后,展望了新兴技术对PLC和HMI
【透明度问题不再难】:揭秘Canvas转Base64时透明度保持的关键技术

# 摘要
本文旨在全面介绍Canvas转Base64编码技术,从基础概念到实际应用,再到优化策略和未来趋势。首先,我们探讨了Canvas的基本概念、应用场景及其重要性,紧接着解析了Base64编码原理,并重点讨论了透明度在Canvas转Base64过程中的关键作用。实践方法章节通过标准流程和技术细节的讲解,提供了透明度保持的有效编码技巧和案例分析。高级技术部分则着重于性能优化、浏览器兼容性问题以及Ca
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )