HTTP请求全解析:urllib.parse模块的深度使用技巧
发布时间: 2024-10-11 19:13:47 阅读量: 24 订阅数: 22 

利用python爬虫(part2)–urllib.parse模块

# 1. HTTP协议基础与 urllib.parse模块概览
## 简介
在当今数字化的网络时代,HTTP协议作为互联网的通信基础,其重要性不言而喻。开发者在进行网络请求处理时,经常会用到Python的`urllib.parse`模块,它提供了一种便捷的方式来解析和构造URL。本章将从HTTP协议的基本知识讲起,逐渐深入到`urllib.parse`模块的核心功能和使用方法,旨在为读者提供一个坚实的基础,以便在后续章节中处理更复杂的HTTP请求和响应。
## HTTP协议基础
超文本传输协议(HTTP)是一种用于分布式、协作式和超媒体信息系统的应用层协议。它是一个请求和响应协议,运行在TCP/IP协议之上。HTTP协议的主要特点是无状态性,意味着服务器不会保存任何关于客户端请求的状态信息。每当你浏览网页时,你的浏览器都会与服务器建立一个连接,发送一个请求,服务器响应后连接就会关闭。
## urllib.parse模块概览
Python的标准库中的`urllib.parse`模块,承担着将URL拆分为多个组件,并能够将这些组件重新组合成一个完整URL的任务。举一个简单的例子,如果你要解析一个URL `***`,`urllib.parse`可以帮助你轻松地提取协议、主机名、端口、路径、查询字符串以及片段标识符等信息。这一模块是处理网络请求的基石,因为几乎所有的网络请求都需要对URL进行操作。
在后续章节中,我们将详细探讨如何使用`urllib.parse`模块中的各种功能,来解析和操作URL,这对于理解和执行HTTP请求至关重要。
# 2. 解析URL结构与编码
在本章中,我们将深入探讨URL的内部结构及其编码过程。URL(统一资源定位符)是互联网上用来定位资源的字符串。理解URL的组成、如何对其进行编码和解码是进行网络编程和网络数据处理的基础。
## 2.1 URL的组成部分
### 2.1.1 协议部分
URL的第一部分指定了用来访问资源的协议,如`http`或`https`。这种协议定义了客户端和服务器之间交换数据的方式。
```markdown
示例:`***`
```
### 2.1.2 域名和端口
紧随协议之后的是域名,它指向网络中存放资源的服务器地址,而端口则指定了服务器上的一个网络端点。默认情况下,HTTP使用端口80,HTTPS使用端口443。
```markdown
示例:`***`
```
### 2.1.3 路径和查询字符串
路径部分指定了服务器上资源的具体位置,而查询字符串包含了一组参数,这些参数以键值对的形式传递给服务器。
```markdown
示例:`***`
```
## 2.2 URL编码与解码
### 2.2.1 编码的必要性
URL中某些字符如空格、特殊符号等不能直接传输,需要进行编码。编码的目的是为了安全传输数据,防止数据在网络中被篡改,并且确保数据能够被服务器正确解析。
### 2.2.2 urllib.parse模块中的编码函数
Python的`urllib.parse`模块提供了`quote`函数,用于对URL中的特殊字符进行编码。
```python
from urllib.parse import quote
encoded_url = quote('空格使用%20替换')
print(encoded_url) # 输出:%E7%A9%BA%E6%A0%BC%E4%BD%BF%E7%94%A8%20%E6%9B%BF%E6%8D%A2
```
### 2.2.3 urllib.parse模块中的解码函数
解码则使用`unquote`函数,将编码后的URL转换回原始格式。
```python
from urllib.parse import unquote
decoded_url = unquote('%E7%A9%BA%E6%A0%BC%E4%BD%BF%E7%94%A8%20%E6%9B%BF%E6%8D%A2')
print(decoded_url) # 输出:空格使用 替换
```
## 2.3 构造和操作URL
### 2.3.1 使用urlparse进行URL解析
`urlparse`函数可以将URL分解为其组成部分。
```python
from urllib.parse import urlparse
parsed_url = urlparse('***')
print(parsed_url) # 输出:ParseResult(scheme='https', netloc='***', path='/path/to/resource', params='', query='query=value', fragment='')
```
### 2.3.2 使用urlunparse重构URL
使用`urlunparse`函数可以根据已有的URL组件来重构一个URL。
```python
from urllib.parse import urlunparse
url = urlunparse(parsed_url)
print(url) # 输出:***
```
### 2.3.3 使用urljoin处理相对URL
`urljoin`函数可以用来合并基URL和一个相对URL,生成绝对URL。
```python
from urllib.parse import urljoin
base_url = '***'
relative_url = '/new/resource'
absolute_url = urljoin(base_url, relative_url)
print(absolute_url) # 输出:***
```
以上就是本章节的详细介绍。在下一章节中,我们将继续探讨构建复杂的HTTP请求的内容。
# 3. 构建复杂的HTTP请求
构建复杂的HTTP请求是现代Web开发和数据抓取的重要部分。了解如何正确设置请求头信息、处理Cookies,以及创建和管理查询字符串对于确保请求成功、数据准确性和用户隐私保护至关重要。在本章节中,我们将详细探讨这些主题,并提供具体的代码示例来说明如何使用Python的urllib.request模块来实现这些任务。
## 3.1 设置请求头部信息
在发送HTTP请求时,设置适当的请求头部信息是模拟真实浏览器行为的关键。这些头部信息可以包含用户代理(User-Agent)、接受的语言、内容类型等多种参数。通过自定义请求头部信息,我们可以控制服务器如何响应我们的请求,并且可以用来处理特定于浏览器的请求条件。
### 3.1.1 使用urllib.request模块的HeaderProcessor
urllib.request模块提供了一个HeaderProcessor类,允许用户在发送请求之前添加或修改HTTP头部信息。例如,我们可以通过修改User-Agent来模拟不同的浏览器。
```python
from urllib import request
# 创建一个带有自定义头部信息的HeaderProcessor
headers = {
'User-Agent': 'Mozilla/5.0 (compatible; MyCrawler/1.0; +***'
}
handler = request.HTTPHeaderProcessor(headers)
# 创建一个 opener,它会使用我们自定义的头部信息
opener = request.build_opener(handler)
# 使用 opener 发送请求
response = opener.open('***')
# 读取响应内容
html_content = response.read()
```
### 3.1.2 用户代理(User-Agent)和其他常用头部设置
用户代理(User-Agent)是标识请求来源的一个重要头部信息。它告诉服务器我们正在使用哪个浏览器和操作系统,这对于网站显示正确的页面布局和提供兼容性支持至关重要。除了用户代理,我们还可以设置其他常见的头部,如“Accept”、“Accept-Language”和“Content-Type”等。
```python
import urllib.parse
# 构造请求的URL
url = "***"
# 创建一个请求对象
req = urllib.request.Request(url)
# 添加其他头部信息
req.add_header('Accept', 'text/html,application/xhtml+xml,application/xml')
req.add_header('Accept-Language', 'en-US,en;q=0.5')
req.add_header('Content-Type', 'application/x-www-form-urlencoded')
# 使用 urllib 的函数打开请求
response = urllib.request.urlopen(req)
# 打印响应状态码
print("Status Code:", response.status)
```
## 3.2 处理Cookies
Cookies是服务器发送到用户浏览器并保存在本地的一小块数据,它在后续的请求中会被自动发送到服务器。管理Cookies是维护用户会话状态、保存登录信息和跟踪用户行为的重要手段。urllib库中的http.cookiejar模块提供了对Cookies的全面支持。
### 3.2.1 Cookie的存储和传输
在发送请求时,可以通过Cookie处理器自动处理Cookies的存储和传输。这在需要登录并维持会话状态时尤其有用。
```python
import urllib.parse
import urllib.request
import http.cookiejar
# 设置URL和Cookies处理器
url = '***'
cookie Jar = http.cookiejar.CookieJar()
# 创建 Cookie 处理器
handler = urllib.request.HTTPCookieProcessor(Jar)
# 创建 opener
opener = urllib.request.build_opener(handler)
# 发送请求并打开响应
response = opener.open(url)
# 读取响应内容
html_content = response.read()
```
### 3.2.2 使用http.cookiejar管理Cookies
urllib库的http.cookiejar模块提供了一个CookieJar类,用于存储从服务器接收到的Cookie。当进行多个请求到同一个域名时,CookieJar会自动处理Cookies的存储和传输。
```python
# 创建一个请求
req = urllib.request.Request(
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Python 中强大的 urllib.parse 库,为网络请求、数据抓取和网络编程提供全面指南。从 URL 解析的入门知识到高级自定义方案解析器的构建,该专栏涵盖了 urllib.parse 的各个方面。它提供了 10 大高级技巧,5 分钟快速入门指南,查询字符串解析术,实战全解析,与 urllib.request 的完美搭档,深入解析与最佳实践,自定义 URL 方案解析器构建秘籍,从基础到高级应用,深度使用技巧,编码与安全性深度剖析,应用技巧,百分比编码处理之道,灵活的 URL 解析与构建流程,错误处理与调试秘籍,以及完整的使用指南。本专栏旨在帮助 Python 开发者掌握 urllib.parse 的精髓,提升网络请求和网络编程技能。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【调试与诊断】:cl.exe高级调试技巧,让代码问题无所遁形
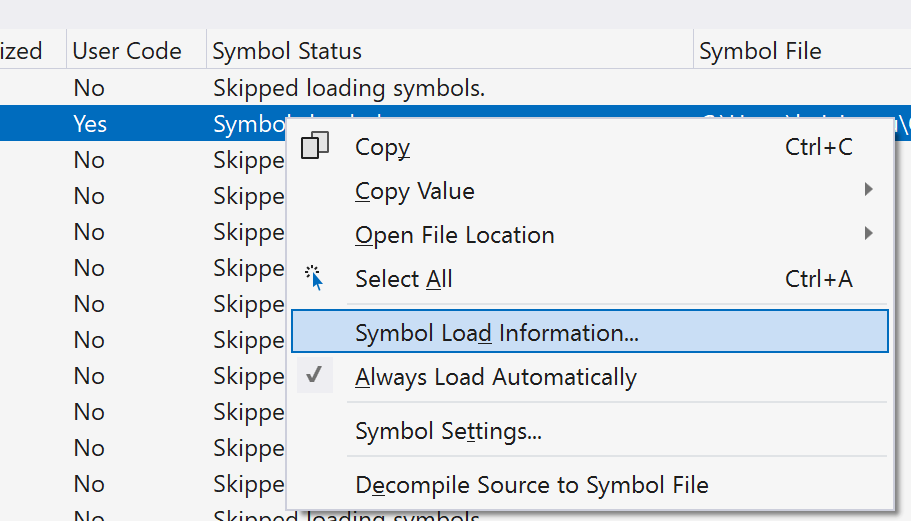
# 摘要
本文围绕软件开发的调试与诊断技术进行了深入探讨,特别是聚焦于Microsoft Visual Studio环境中的cl.exe编译器。文章首先介绍了调试与诊断的基础知识,随后详细解析了cl.exe编译器的使用、优化及调试符号管理。高级
【多核系统中Xilinx Tri-Mode MAC的高效应用】:架构设计与通信机制

# 摘要
本文深入探讨了多核系统环境下网络通信的优化与维护问题,特别关注了Xilinx Tri-Mode MAC架构的关键特性和高效应用。通过对核心硬件设计、网络通信协议、多核处理器集成以及理论模型的分析,文章阐述了如何在多核环境中实现高速数据传输与任务调度。本文还提供了故障诊断技术、系统维护与升级策略,并通过案例研究,探讨了Tri-Mode MAC在高性能计算与数据中心的应用
【APQC五级设计框架深度解析】:企业流程框架入门到精通

# 摘要
APQC五级设计框架是一个综合性的企业流程管理工具,旨在通过结构化的方法提升企业的流程管理能力和效率。本文首先概述了APQC框架的核心原则和结构,强调了企业流程框架的重要性,并详细描述了框架的五大级别和流程分类方法。接着,文章深入探讨了设计和实施APQC框架的方法论,包括如何识别关键流程、确定流程的输入输出、进行现状评估、制定和执行实施计划。此外,本文还讨论了APQC
ARINC653标准深度解析:航空电子实时操作系统的设计与应用(权威教程)

# 摘要
ARINC653作为一种航空航天领域内应用广泛的标准化接口,为实时操作系统提供了一套全面的架构规范。本文首先概述了ARINC653标准,然后详细分析了其操作系统架构及实时内核的关键特性,包括任务管理和时间管理调度、实时系统的理论基础与性能评估,以及内核级通信机制。接着,文章探讨了ARINC653的应用接口(
【软件仿真工具】:MATLAB_Simulink在倒立摆设计中的应用技巧
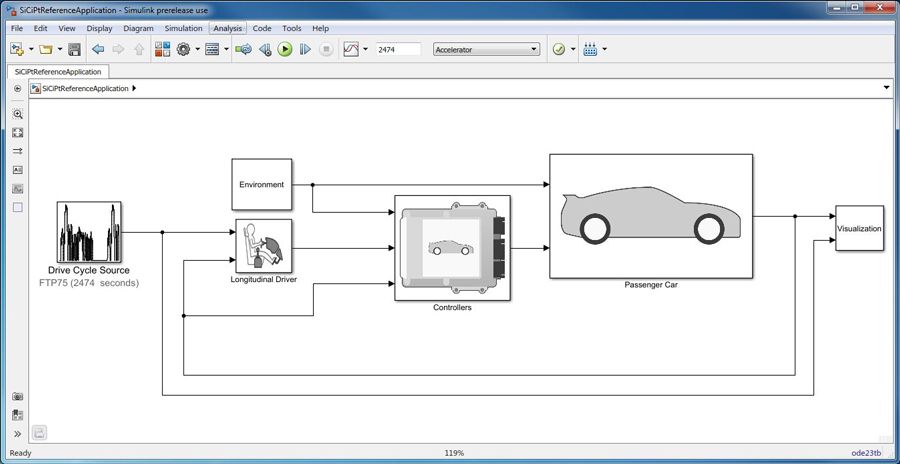
# 摘要
本文系统地介绍了MATLAB与Simulink在倒立摆系统设计与控制中的应用。文章首先概述
自动化测试与验证指南:高通QXDM工具提高研发效率策略

# 摘要
随着移动通信技术的快速发展,高通QXDM工具已成为自动化测试和验证领域不可或缺的组件。本文首先概述了自动化测试与验证的基本概念,随后对高通QXDM工具的功能、特点、安装和配置进行了详细介绍。文章重点探讨了QXDM工具在自动化测试与验证中的实际应用,包括脚本编写、测试执行、结果分析、验证流程设计及优化策略。此外,本文还分析了QXDM工具如何提高研发效率,并探讨了其技术发展趋势以及
C语言内存管理:C Primer Plus第六版指针习题解析与技巧

# 摘要
本论文深入探讨了C语言内存管理和指针应用的理论与实践。第一章为C语言内存管理的基础介绍,第二章系统阐述了指针与内存分配的基本概念,包括动态与静态内存、堆栈管理,以及指针类型与内存地址的关系。第三章对《C Primer Plus》第六版中的指针习题进行了详细解析,涵盖基础、函数传递和复杂数据结构的应用。第四章则集中于指针的高级技巧和最佳实践,重点讨论了内存操作、防止内存泄漏及指针错
【PDF元数据管理艺术】:轻松读取与编辑PDF属性的秘诀

# 摘要
本文详细介绍了PDF元数据的概念、理论基础、读取工具与方法、编辑技巧以及在实际应用中的案例研究。PDF元数据作为电子文档的重要组成部分,不仅对文件管理与检索具有关键作用,还能增强文档的信息结构和互操作性。文章首先解析了PDF文件结构,阐述了元数据的位置和作用,并探讨了不同标准和规范下元数据的特点。随后,本文评述了多种读取PDF元数据的工具和方法,包括命令行和图形用户
中兴交换机QoS配置教程:网络性能与用户体验双优化指南
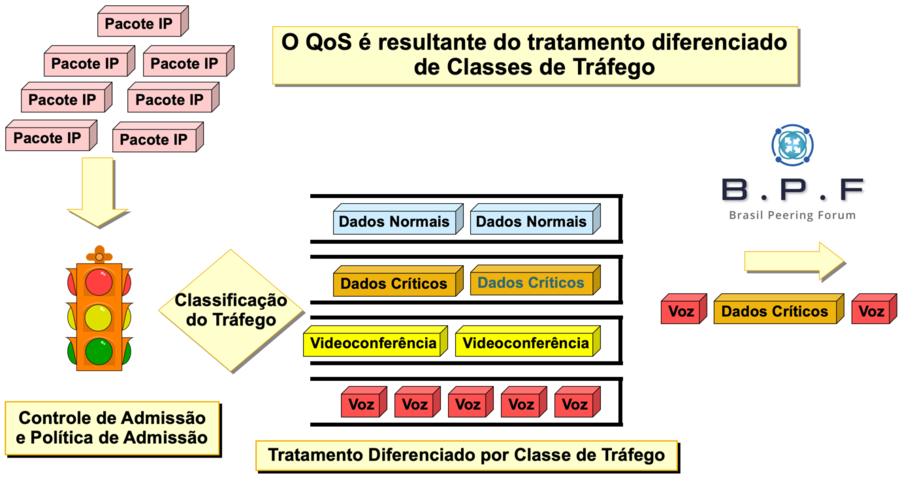
# 摘要
随着网络技术的快速发展,服务质量(QoS)成为交换机配置中的关键考量因素,直接影响用户体验和网络资源的有效管理。本文详细阐述了QoS的基础概念、核心原则及其在交换机中的重要性,并深入探讨了流量分类、标记、队列调度、拥塞控制和流量整形等关键技术。通过中兴交换机的配置实践和案例研究,本文展示了如何在不同网络环境中有效地应用QoS策略,以及故障排查
工程方法概览:使用MICROSAR进行E2E集成的详细流程
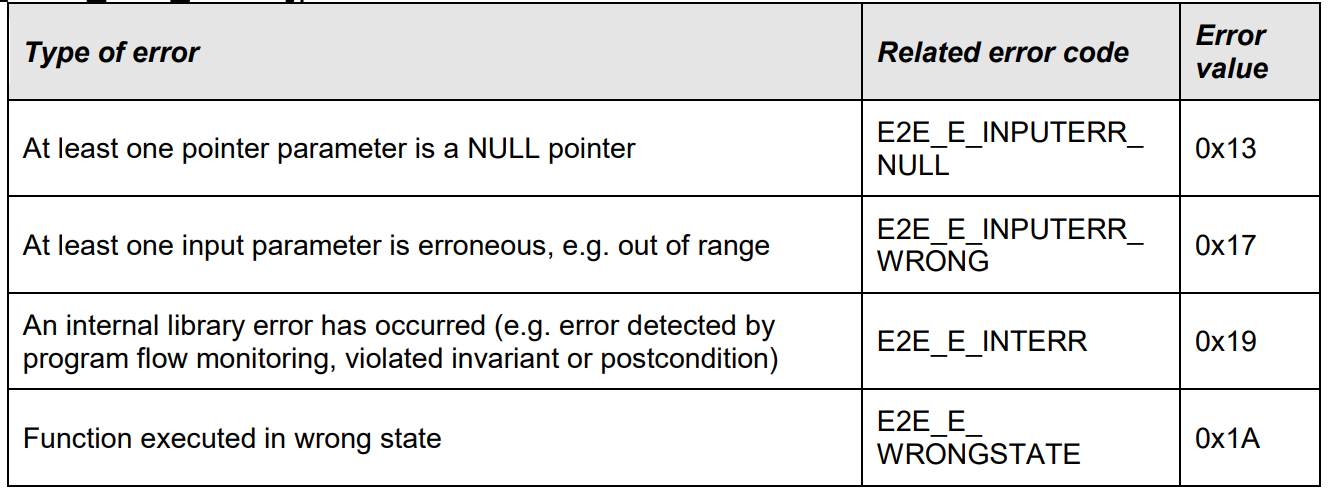
# 摘要
本文全面阐述了MICROSAR基础和其端到端(E2E)集成概念,详细介绍了MICROSAR E2E集成环境的建立过程,包括软件组件的安装配置和集成开发工具的使用。通过实践应用章节,分析了E2E集成在通信机制和诊断机制的实现方法。此外,文章还探讨了E2E集成的安全机制和性能优化策略,以及通过项目案例分析展示了E2E集成在实际项目中的应用,讨论了遇到的问题和解决方案,
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )