【Keras模型持久化指南】:模型保存与加载的最佳实践(确保项目稳定性)
发布时间: 2024-09-30 10:33:31 阅读量: 73 订阅数: 47 

基于遗传算法的动态优化物流配送中心选址问题研究(Matlab源码+详细注释),遗传算法与免疫算法在物流配送中心选址问题的应用详解(源码+详细注释,Matlab编写,含动态优化与迭代,结果图展示),遗传
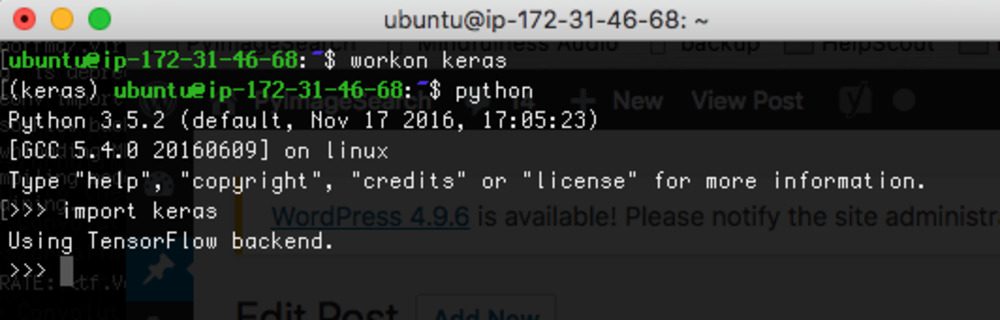
# 1. Keras模型持久化概念解析
Keras模型持久化是深度学习中一个重要环节,它涉及到模型的保存与加载,确保模型训练的成果能够被长期存储,并在需要时能够准确无误地恢复模型状态。本章将介绍模型持久化的基础概念,以及保存和加载模型的必要性,从而为读者提供一个清晰的理论基础。模型持久化不仅涉及技术层面的文件操作,更关系到数据科学的实践经验和最佳实践,是Keras应用中的核心组成部分。
## 模型持久化的必要性
在开发和部署深度学习模型时,持久化模型是保证模型复用性和稳定性的关键步骤。它允许我们在以下场景中高效利用模型资源:
- **训练中断恢复**:在模型训练过程中,若遇到意外中断,持久化的模型可以从中断处继续训练,避免从头开始。
- **模型部署**:训练完成的模型需要被部署到生产环境,持久化是确保模型能够被正确加载和执行的必要步骤。
- **版本控制与协作**:在团队合作环境中,模型的持久化版本可以帮助团队成员共享、比较不同阶段的模型状态。
理解模型持久化的概念和重要性,是每个深度学习从业者应该具备的基本技能。接下来的章节将深入探讨如何使用Keras实现模型的保存与加载。
# 2. Keras模型保存技术详解
在现代的深度学习实践中,模型保存是必不可少的环节。模型保存不仅能够让我们在进行模型训练时能够随时备份,还可以将训练好的模型部署到不同的环境中去。Keras作为一款高效的深度学习库,提供了多种模型保存的方式和策略。本章将从基本的模型保存技术到高级的自定义保存技术,再到解决模型保存中常见问题的方法,为读者提供一个全面的模型保存解决方案。
## 2.1 Keras模型保存基础
### 2.1.1 保存整个模型的方法
在Keras中保存整个模型的方法非常直接,你可以使用`model.save()`方法将整个模型结构、权重以及训练配置一次性保存到文件中。这个文件通常包含了模型的所有必要信息,包括模型的结构定义、权重值以及训练配置等。
```python
import keras
# 假设我们已经有了一个训练好的模型model
model = keras.models.Sequential([
keras.layers.Dense(64, activation='relu', input_shape=(10,)),
keras.layers.Dense(10, activation='softmax')
])
# 编译模型
***pile(optimizer='adam', loss='sparse_categorical_crossentropy')
# 进行模型训练
model.fit(x_train, y_train, epochs=10, validation_data=(x_val, y_val))
# 保存整个模型到文件
model.save('my_model.h5')
```
保存的`.h5`文件可以用于之后的模型加载,只需使用`keras.models.load_model()`方法。
### 2.1.2 权重保存与加载的策略
如果只需要保存或加载模型的权重,可以使用`model.save_weights()`和`model.load_weights()`方法。这种策略非常适合当你已经有模型结构,只需要更新模型权重的情况。另外,这种方法也有助于节省存储空间,因为权重数据通常比整个模型小得多。
```python
# 保存权重到文件
model.save_weights('weights.h5')
# 在另一个模型或者新的训练中加载权重
model.load_weights('weights.h5')
```
保存权重时,推荐使用`weights.h5`或`.hdf5`格式,因为这种格式支持更大规模的权重保存,并且能够更好地处理大数据集。
## 2.2 高级模型保存技术
### 2.2.1 使用回调函数进行周期性保存
Keras的回调函数机制允许我们更灵活地控制训练过程。通过使用`ModelCheckpoint`回调,可以设置在训练过程中周期性地保存模型到指定路径,以此来减少因训练过程意外中断而导致的损失。
```python
from keras.callbacks import ModelCheckpoint
# 创建ModelCheckpoint实例,设置保存路径和模式
checkpoint = ModelCheckpoint('model-{epoch:03d}.h5', period=1)
# 将ModelCheckpoint添加到模型的回调列表中
model.fit(x_train, y_train, epochs=10, validation_data=(x_val, y_val), callbacks=[checkpoint])
```
在上面的例子中,`period=1`表示每轮训练后都会触发保存操作,`model-{epoch:03d}.h5`表示保存的文件名将包含当前轮次的信息。
### 2.2.2 模型保存的自定义与优化
除了上述的保存策略外,我们还可以根据实际需要自定义模型保存的逻辑。自定义保存可以帮助我们在特定条件下执行保存操作,例如,只有当模型的验证准确率超过某一阈值时才保存模型。
```python
# 自定义回调函数
class CustomCheckpoint(keras.callbacks.Callback):
def __init__(self, filepath, threshold):
super(CustomCheckpoint, self).__init__()
self.filepath = filepath
self.threshold = threshold
def on_epoch_end(self, epoch, logs=None):
if logs.get('val_accuracy') > self.threshold:
self.model.save(self.filepath.format(epoch=epoch))
# 使用自定义回调
checkpoint = CustomCheckpoint('model-{epoch:03d}.h5', threshold=0.9)
model.fit(x_train, y_train, epochs=10, validation_data=(x_val, y_val), callbacks=[checkpoint])
```
通过自定义回调,可以更精确地控制模型保存的时机和条件,从而优化训练过程和资源使用。
## 2.3 模型保存的常见问题与解决方案
### 2.3.1 模型保存的兼容性问题
随着深度学习框架的不断升级,模型保存和加载的兼容性问题逐渐凸显。Keras提供了版本兼容性选项来解决这个问题。通过指定`options`参数,可以兼容不同版本的模型保存格式。
```python
model.save('my_model.h5', save_format='h5', options={'compress': 'gzip'})
```
### 2.3.2 模型保存时的内存管理
模型保存时可能会涉及到大文件的写入操作,可能会消耗大量内存资源。为了避免这种情况,可以考虑在保存模型时关闭其他不必要的程序,或者将保存操作放置在内存较大的服务器上执行。
此外,也可以考虑使用分布式文件系统,将模型分片保存,进一步降低单次保存操作对内存的压力。
```python
# 分片保存模型权重
num_slices = 10
for i in range(num_slices):
weights = model.get_weights()[i*num_slices:(i+1)*num_slices]
# 将分片权重保存到文件中
with open(f'weights_part_{i}.h5', 'wb') as f:
pickle.dump(weights, f)
```
通过分片保存模型权重,可以有效管理内存使用,特别是在权重特别大的模型中。
以上章节内容涵盖了Keras模型保存的基础知识、高级技术、常见问题以及解决方案。在下一章节中,我们将探讨如何加载这些已保存的模型,以及加载过程中可能遇到的挑战和解决策略。
# 3. Keras模型加载技术详解
## 3.1 模型加载的基本步骤
### 3.1.1 加载整个模型的流程
加载整个Keras模型是将之前保存的模型结构和权重重新加载到内存中,以便进行预测、评估或进一步的训练。这个过程主要包括两个步骤:首先加载模型架构,然后加载模型权重。使用Keras提供的`load_model`函数可以非常方便地实现这一过程。以下是加载整个模型的基本流程:
1. **导入必要的模块**:首先需要导入`keras`模块,这通常可以通过`from tensorflow import keras`来实现。
2. **指定模型文件**:指定已经保存好的模型文件的路径。通常模型保存为一个`.h5`文件。
3. **加载模型**:使用`keras.models.load_model()`函数加载整个模型。这个函数会读取`.h5`文件,恢复模型的结构和权重,

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到 Keras 进阶学习专栏!本专栏旨在深入探索 Keras 库,为高级深度学习从业者提供全面且实用的指导。从模型编译和训练的高级策略到后端优化和性能提升的独家指南,再到构建复杂神经网络的必备技巧和超参数调整的深度解析,本专栏涵盖了 Keras 的方方面面。此外,还提供了精通训练过程控制的回调函数高级教程,以及预训练模型和优化器的无缝接入指南。通过清晰高效的代码优化技巧、多 GPU 训练技巧和构建 REST API 的实战指导,本专栏将帮助您充分利用 Keras 的强大功能。最后,还提供了调试和故障排除秘籍、性能监控和分析技巧,以及计算机视觉实战案例,让您成为一名全面且熟练的 Keras 开发人员。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
HC-06蓝牙模块构建无线通信系统指南:从零开始到专家
# 摘要
HC-06蓝牙模块作为一种低成本、易配置的无线通信解决方案,在物联网和移动设备应用中得到了广泛使用。本文首先介绍了HC-06模块的基本概念和硬件连接配置方法,包括其硬件接口的连接方式和基本通信参数的设置。随后,文章探讨了HC-06的编程基础,包括蓝牙通信协议的工作原理以及如何通过AT命令和串口编程控制模块。在实践应用案例部分,本文阐述了如何构建基于HC-06的无线数据传输系统以及如何开发手机应
虚拟化技术深入解析
# 摘要
虚拟化技术是当代信息科技领域的重要进步,它通过抽象化硬件资源,允许多个操作系统和应用程序共享同一物理资源,从而提高了资源利用率和系统的灵活性。本文详细介绍了虚拟化技术的分类,包括硬件、操作系统级以及应用程序虚拟化,并比较了各自的优缺点,如资源利用率的提升、系统兼容性和隔离性的优势以及潜在的性能损耗与开销。文章进一步探讨了虚拟化环境的构建和管理方法,以及在企业中的实际应用案例,包括在云计算和数据中心的应用以及在灾难恢复中的作用。
Sew Movifit FC实战案例:解决实际问题的黄金法则
# 摘要
本文全面介绍了Sew Movifit FC的基础知识、理论基础、应用场景、实战案例分析以及高级应用技巧,并对其未来发展趋势进行了展望。Sew Movifit FC作为一种先进的技术设备,其硬件结构和软件组成共同构成了其工作原理的核心。文章详细探讨了Sew Movifit FC在工业自动化、智能家居控制以及能源管理系统等多个领域
软件测试:自动化测试框架搭建与管理的终极指南

# 摘要
自动化测试框架是软件开发中提高测试效率和质量的关键技术之一。本文首先概述了自动化测试框架的基本概念和重要性,探讨了不同类型的框架及其选择原则,并强调了测试流程优化的重要性。随后,文章提供了搭建自动化测试框架的详细实践指导,包括环境准备、代码结构设计和测试脚本编写。进一步,本文深入分析了自动化测试框架的高级应用,如模块化、持续集成以及案
透镜系统中的均匀照明秘诀:高斯光束光束整形技术终极指南

# 摘要
高斯光束作为激光技术中的基础概念,在光学研究和应用中占据重要地位。本文首先介绍了高斯光束的基本知识,包括其数学模型、空间分布以及时间和频率特性。随后,文章深入分析了高斯光束的光束整形技术,阐述了不同光束整形方法的原理、技术及实例应用。此外,本文探讨了均匀照明技术在显微成像、激光加工和光存储领域的实践应用,展示了光束整形技术的实用价值。最后,文章展望了高斯光束整
风险管理在IT项目中的应用:策略与案例研究指南

# 摘要
IT项目风险管理对于确保项目目标的实现至关重要。本文对IT项目风险管理进行了全面概述,详细介绍了项目风险的识别和评估过程,包括使用工具、技术、专家访谈以及团队共识来识别风险,并通过定性和定量的方法进行风险评估。文章还探讨了建立风险模型的分析方法,如敏感性分析和预测分析,并详细阐述了风险应对规划、缓解措施以及监控和报告的重要性。通过
负载均衡从入门到精通:静态和动态请求的高效路由
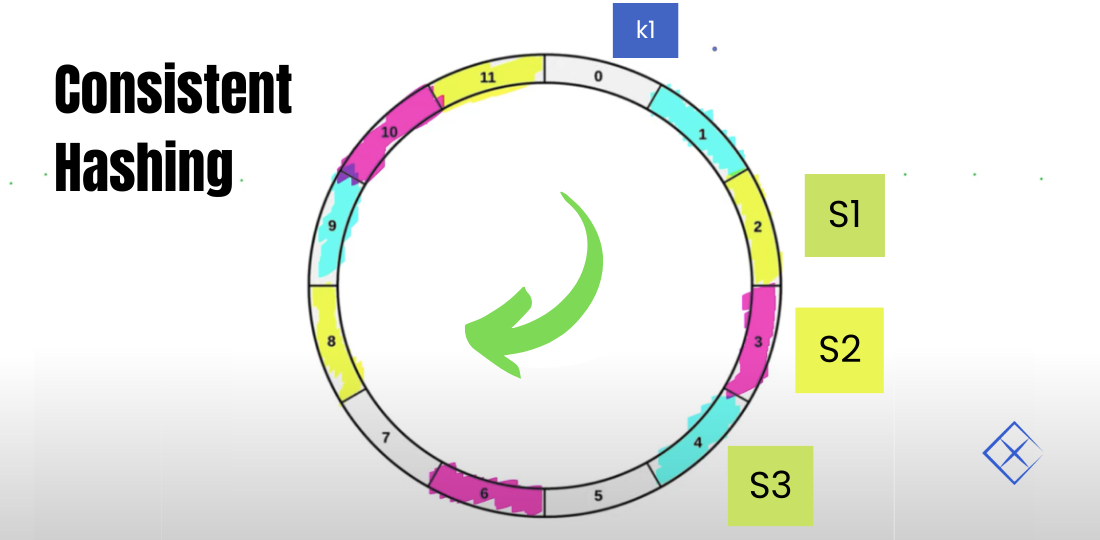
# 摘要
负载均衡是优化数据中心性能和可靠性的关键技术,本文全面探讨了负载均衡的基础原理、实现方法、高级应用以及挑战与未来趋势。首先介绍了负载均衡的基本概念和静态请求负载均衡的策略与实践,随后探讨了动态请求的负载均衡需求及其实现,并深入到高级负载均衡技术和性能调优。文章还分析了负载均衡器的选择与搭建、测试方法和案例研究,并对云计算环境、容器化架构下负载均衡的新特点进行了展望。最后,本文审视了负载均衡在多数据中心
CCS5.5代码编写:提升开发效率的顶级技巧(专家级别的实践方法)

# 摘要
CCS5.5是德州仪器公司推出的高性能集成开发环境,广泛应用于嵌入式系统的开发。本文全面介绍了CCS5.5的快速上手指南、代码编写基础、代码优化与性能提升、高级编译技术及工具链、系统级编程与硬件接口控制,以及专家级别的项目管理和团队协
【Ansys后处理器操作指南】:解决常见问题并优化您的工作流程
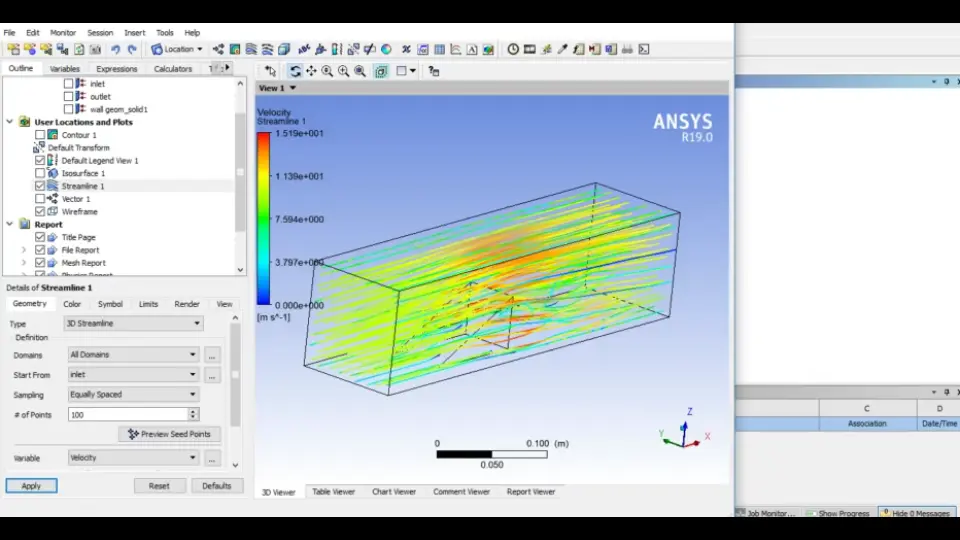
# 摘要
本文详细介绍了Ansys后处理器的功能和操作,从基础使用到高级技巧,再到定制化需求和最佳实践,为用户提供了全面的学习指南。首先,文章介绍了后处理器的界面布局和数据可视化技术,为用户提供直观的数据分析和结果展示能力。接着,文章探讨了提高后处理效率的高级技巧,包括批量处理和参数化分析。此外,文章还讨论了解决常见问题的策略,如性
MATLAB机器视觉应用:工件缺陷检测案例深度分析

# 摘要
本论文深入探讨了MATLAB在机器视觉和工件缺陷检测领域的应用。文章首先介绍了机器视觉的基础知识,随后详细阐述了工件缺陷检测的理论基础,包括其在工业生产中的重要性和发展趋势,以及图像处理和缺陷检测常用算法。第三章通过MATLAB图像处理工具箱的介绍和案例分析,展示了如何在实际中应用这些理论。第四章则探索了深度学习技术在缺陷检测中的作用,并对比分析了不同方法的性能。最后,第五章展望了机器视觉与人
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )