【Keras代码优化宝典】:编写清晰、高效的深度学习代码(专业编程必读)
发布时间: 2024-09-30 10:27:59 阅读量: 36 订阅数: 37 

# 1. 深度学习与Keras简介
## 1.1 深度学习的崛起
近年来,深度学习已成为推动人工智能发展的核心力量。它模拟人脑神经网络处理信息,通过多层非线性变换对高复杂性数据进行学习和预测。从图像识别到自然语言处理,深度学习的应用几乎涵盖了所有领域。
## 1.2 Keras的兴起
Keras作为最受欢迎的深度学习框架之一,因其简洁、易用和模块化而受到开发者的青睐。Keras提供了一种高层神经网络API,能够在TensorFlow、Microsoft Cognitive Toolkit或Theano等后端上运行。
## 1.3 Keras的定位与优势
Keras致力于实现快速实验,让深度学习更加人性化。其最大的优势在于易用性,同时允许用户以最小的代价从想法过渡到结果。它提供了一套完整的工具,以便开发者专注于创新,而不必担心底层复杂性。这使得Keras非常适合初学者和进行研究的专家。
# 2. 理解Keras的核心组件
## 2.1 Keras模型的基本构建
### 2.1.1 序列模型与函数式API
Keras提供了两种模型构建方式:序列模型(Sequential)和函数式API(Functional API)。序列模型是层的线性堆叠,而函数式API允许构建更复杂的模型,比如具有多个输入和输出的模型,或者共享层的模型。
#### 序列模型
序列模型是最简单的模型构建方法。每个层直接添加到前一层之上,构建过程直观易懂。
```python
from keras.models import Sequential
from keras.layers import Dense
model = Sequential()
model.add(Dense(64, activation='relu', input_shape=(100,)))
model.add(Dense(10, activation='softmax'))
***pile(loss='categorical_crossentropy',
optimizer='sgd',
metrics=['accuracy'])
```
在上述代码中,我们构建了一个简单的多层感知器(MLP),输入层的大小为100,输出层的大小为10,对应于10个分类问题。激活函数在Dense层中定义为'relu'和'softmax'。
#### 函数式API
函数式API提供了更大的灵活性。它允许构建任意的深度学习模型,包括多输入多输出模型,或者层之间有共享的模型。
```python
from keras.layers import Input, Dense
from keras.models import Model
input_tensor = Input(shape=(100,))
x = Dense(64, activation='relu')(input_tensor)
output_tensor = Dense(10, activation='softmax')(x)
model = Model(inputs=input_tensor, outputs=output_tensor)
***pile(loss='categorical_crossentropy',
optimizer='sgd',
metrics=['accuracy'])
```
在这个例子中,我们创建了一个与序列模型等效的模型,但使用了函数式API。该方法首先定义了输入,然后将输入传递给一系列层,最后定义了输出。
### 2.1.2 模型的编译与训练
模型构建后,下一步是编译模型。编译是设置模型学习过程的参数,包括损失函数、优化器和评估指标。
```***
***pile(loss='categorical_crossentropy',
optimizer='sgd',
metrics=['accuracy'])
```
损失函数(在这个例子中是"categorical_crossentropy")用于计算标签与预测概率之间的差异。优化器("sgd"即随机梯度下降)用于调整模型权重以最小化损失函数。指标(在这个例子中是"accuracy")用于监控训练和评估过程。
接下来是训练模型,通常使用`model.fit()`方法。
```python
model.fit(x_train, y_train, epochs=5, batch_size=32)
```
`model.fit()`方法接受训练数据`x_train`和`y_train`,以及可选的参数如训练轮数(epochs)和批量大小(batch_size)。训练完成后,可以使用`model.evaluate()`对模型进行评估。
## 2.2 Keras中的层与激活函数
### 2.2.1 常用层的使用方法
在Keras中,层是构建神经网络的基本单元。以下是一些常用层的使用示例:
#### 全连接层(Dense)
```python
from keras.layers import Dense
model.add(Dense(64, activation='relu'))
```
这是使用最多的一种层,它将输入向量通过矩阵乘法和一个偏置向量转换为另一个向量。激活函数(如'relu')将该层的输出转换为非线性特征。
#### 卷积层(Conv2D)
```python
from keras.layers import Conv2D
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)))
```
卷积层是卷积神经网络的基础,用于提取图像的特征。它通过滤波器在输入数据上滑动来工作,并执行卷积操作。
#### 循环层(LSTM)
```python
from keras.layers import LSTM
model.add(LSTM(128, return_sequences=True))
```
LSTM层是一种特殊的循环神经网络层,适用于序列数据。它能够学习序列之间的长期依赖关系。`return_sequences=True`参数表示返回整个序列而非仅返回序列的最后一个输出。
### 2.2.2 激活函数的选择与应用
激活函数为神经网络提供了非线性变换能力,它是神经网络模型复杂性的关键。以下是一些常用的激活函数:
#### ReLU
```python
model.add(Dense(64, activation='relu'))
```
ReLU(Rectified Linear Unit)是目前最受欢迎的激活函数之一。它的数学表达式为`f(x) = max(0, x)`。ReLU函数在正区间内是线性的,且在负区间内输出为零,这有助于缓解梯度消失问题。
#### Softmax
```python
model.add(Dense(10, activation='softmax'))
```
Softmax函数通常用作神经网络的最后一层,用于多分类问题。它将输出向量转换为概率分布。其公式为`f(x)_i = exp(x_i) / sum(exp(x))`,其中`x`是未经Softmax变换的输出向量。
#### Sigmoid
```python
model.add(Dense(1, activation='sigmoid'))
```
Sigmoid函数用于二分类问题,它的输出范围在0到1之间。Sigmoid函数的数学表达式为`f(x) = 1 / (1 + exp(-x))`。尽管Sigmoid在二分类中很受欢迎,但由于梯度消失问题,它在深层网络中很少使用。
## 2.3 Keras的损失函数与优化器
### 2.3.1 常见损失函数的原理与选择
损失函数是衡量模型预测值与真实值之间差异的指标。在Keras中,你可以根据不同的任务选择不同的损失函数。
#### Categorical Crossentropy
```***
***pile(loss='categorical_crossentropy', ...)
```
当输出层使用softmax激活函数且目标是进行多分类时,categorical_crossentropy是最佳选择。它衡量了两个概率分布之间的差异。
#### Mean Squared Error
```***
***pile(loss='mean_squared_error', ...)
```
Mean Squared Error(MSE)是回归问题中最常用的损失函数。它通过计算预测值和真实值差的平方的平均值来工作。
#### Binary Crossentropy
```***
***pile(loss='binary_crossentropy', ...)
```
对于二分类问题,binary_crossentropy是合适的选择。它同样衡量了预测概率分布与真实分布之间的差异,但适用于单个概率输出而非概率向量。
### 2.3.2 优化器的配置与效果对比
优化器用于更新网络权重以最小化损失函数。选择正确的优化器对模型的性能有显著影响。
#### SGD (Stochastic Gradient Descent)
```***
***pile(optimizer='sgd', ...)
```
SGD是最简单的优化器之一,它按照确定的学习率对权重进行更新。虽然速度可能较慢且可能陷入局部最小值,但SGD通常会得到相对较好的解。
#### Adam
```***
***pile(optimizer='adam', ...)
```
Adam结合了RMSprop和Momentum的优点,对学习率自适应调整。它是目前在大多数问题上默认且效果较好的优化器之一。
#### RMSprop
```***
***pile(optimizer=RMSprop(), ...)
```
RMSprop是为了解决Adagrad优化器在训练深度神经网络时学习率过早衰减的问题而设计的。它通过调整学习率以保持梯度的大小稳定。
优化器和损失函数的选择对模型的收敛速度和最终性能有直接影响。在实际应用中,建议根据具体问题对这些参数进行微调,并通过验证集进行验证。
至此,第二章的前半部分已经详述了Keras模型构建的基础知识,接下来将继续探讨模型的核心组件,包括激活函数、损失函数和优化器的深入理解和应用。
# 3. Keras代码优化实践
## 3.1 代码清晰性的优化
### 3.1.1 使用命名规范提高代码可读性
在编写Keras代码时,合理使用命名规范对于提高代码的可读性和维护性至关重要。命名规范不仅包括变量、函数、类的命名,还包括模型的命名、层的命名以及文件的组织结构。
- **变量命名**:变量名应简洁明了,表达其用途和含义,一般使用小写字母和下划线来命名。例如,使用`input_data`代替`a`来表示输入数据。
- **函数命名**:函数名通常为动词短语,清晰表达该函数的功能。例如,使用`create_model`代替`m`来表示创建模型的函数。
- **类命名**:类名通常使用驼峰命名法,首字母大写。例如,使用`SequentialModel`代替`seq`来表示序列模型类。
- **模型和层的命名**:在构建模型和层时,应当为它们指定清晰的名称,便于理解模型结构。例如,使用`conv_layer_1`代替`c1`来命名卷积层。
- **文件命名和组织**:合理组织项目文件,按照功能或模块来划分,文件和文件夹的名称应当能够反映出它们的内容。例如,使用`data_preparation.py`代替`dp.py`来命名数据预处理的脚本。
```python
# 示例代码:使用命名规范的函数和变量
def load_dataset(file_path):
"""
加载数据集
"""
data = # 加载数据的逻辑
return data
model = SequentialModel()
model.add(conv_layer_1(input_shape=(28, 28, 1)))
```
### 3.1.2 代码重构的技巧与原则
代码重构是提高代码效率和质量的重要手段。在使用Keras进行深度学习项目开发时,应该定期审视和重构代码,以提升其清晰度和性能。
- **重复代码的消除**:识别并合并重复的代码片段,使用函数或类来封装通用逻辑。
- **函数和类的划分**:过长的函数或类应该进行拆分,每个函数和类都应该有一个清晰定义的职责。
- **逻辑的简化**:重构复杂逻辑,降低代码的复杂度,使代码更易于理解和维护。
- **代码注释和文档**:增加必要的注释和文档说明,帮助他人(或未来的自己)理解代码的设计意图和实现细节。
- **遵循PEP 8风格指南**:Python社区广泛认可的代码编写风格指南,对于保持代码风格的一致性非常有帮助。
```python
# 示例代码:重构重复代码片段为函数
def preprocess_data(data):
"""
预处理数据
"""
# 数据预处理逻辑
processed_data = data # 假设处理逻辑为空
return processed_data
# 使用重构后的函数处理数据
processed_input = preprocess_data(input_data)
```
## 3.2 代码效率的优化
### 3.2.1 批量处理与向量化操作
在深度学习中,数据的批量处理和向量化操作对于提高代码效率至关重要。Keras支持批量处理,我们可以利用这一点来加速数据加载和处理过程。
- **使用fit_generator或ImageDataGenerator**:在训练模型时使用批量生成器,可以提高数据加载和预处理的效率。
- **使用Numpy进行向量化操作**:Numpy库支持高效的数组运算,能够减少Python循环的使用,提升计算速度。
```py
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到 Keras 进阶学习专栏!本专栏旨在深入探索 Keras 库,为高级深度学习从业者提供全面且实用的指导。从模型编译和训练的高级策略到后端优化和性能提升的独家指南,再到构建复杂神经网络的必备技巧和超参数调整的深度解析,本专栏涵盖了 Keras 的方方面面。此外,还提供了精通训练过程控制的回调函数高级教程,以及预训练模型和优化器的无缝接入指南。通过清晰高效的代码优化技巧、多 GPU 训练技巧和构建 REST API 的实战指导,本专栏将帮助您充分利用 Keras 的强大功能。最后,还提供了调试和故障排除秘籍、性能监控和分析技巧,以及计算机视觉实战案例,让您成为一名全面且熟练的 Keras 开发人员。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
PyroSiM中文版模拟效率革命:8个实用技巧助你提升精确度与效率
# 摘要
PyroSiM是一款强大的模拟软件,广泛应用于多个领域以解决复杂问题。本文从PyroSiM中文版的基础入门讲起,逐渐深入至模拟理论、技巧、实践应用以及高级技巧与进阶应用。通过对模拟理论与效率提升、模拟模型精确度分析以及实践案例的探讨,本文旨在为用户提供一套完整的PyroSiM使用指南。文章还关注了提高模拟效率的实践操作,包括优化技巧和模拟工作流的集成。高级
QT框架下的网络编程:从基础到高级,技术提升必读
# 摘要
QT框架下的网络编程技术为开发者提供了强大的网络通信能力,使得在网络应用开发过程中,可以灵活地实现各种网络协议和数据交换功能。本文介绍了QT网络编程的基础知识,包括QTcpSocket和QUdpSocket类的基本使用,以及QNetworkAccessManager在不同场景下的网络访问管理。进一步地,本文探讨了QT网络编程中的信号与槽
优化信号处理流程:【高效傅里叶变换实现】的算法与代码实践

# 摘要
傅里叶变换是现代信号处理中的基础理论,其高效的实现——快速傅里叶变换(FFT)算法,极大地推动了数字信号处理技术的发展。本文首先介绍了傅里叶变换的基础理论和离散傅里叶变换(DFT)的基本概念及其计算复杂度。随后,详细阐述了FFT算法的发展历程,特别是Coo
MTK-ATA核心算法深度揭秘:全面解析ATA协议运作机制

# 摘要
本文深入探讨了MTK-ATA核心算法的理论基础、实践应用、高级特性以及问题诊断与解决方法。首先,本文介绍了ATA协议和MTK芯片架构之间的关系,并解析了ATA协议的核心概念,包括其命令集和数据传输机制。其次,文章阐述了MTK-ATA算法的工作原理、实现框架、调试与优化以及扩展与改进措施。此外,本文还分析了MTK-ATA算法在多
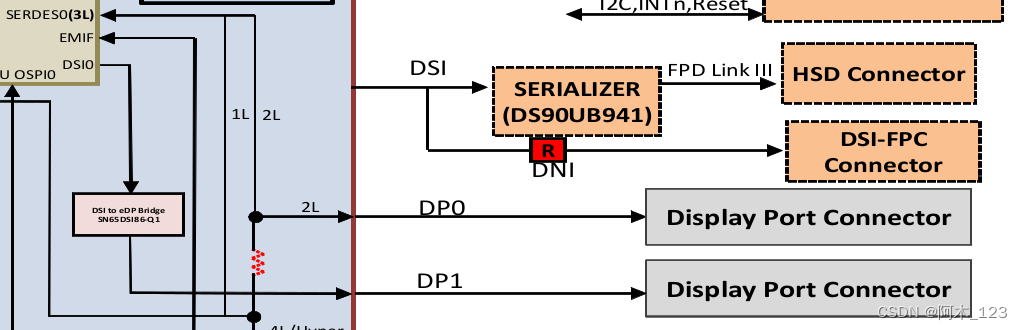
【MIPI摄像头与显示优化】:掌握CSI与DSI技术应用的关键
# 摘要
本文全面介绍了MIPI摄像头与显示技术,从基本概念到实际应用进行了详细阐述。首先,文章概览了MIPI摄像头与显示技术的基础知识,并对比分析了CSI与DSI标准的架构、技术要求及适用场景。接着,文章探讨了MIPI摄像头接口的配置、控制、图像处理与压缩技术,并提供了高级应用案例。对于MIPI显示接口部分,文章聚焦于配置、性能调优、视频输出与图形加速技术以及应用案例。第五章对性能测试工具与
揭秘PCtoLCD2002:如何利用其独特算法优化LCD显示性能

# 摘要
PCtoLCD2002作为一种高性能显示优化工具,在现代显示技术中占据重要地位。本文首先概述了PCtoLCD2002的基本概念及其显示性能的重要性,随后深入解析了其核心算法,包括理论基础、数据处理机制及性能分析。通过对算法的全面解析,探讨了算法如何在不同的显示设备上实现性能优化,并通过实验与案例研究展示了算法优化的实际效果。文章最后探讨了PCtoLCD2002算法的进阶应用和面临
DSP系统设计实战:TI 28X系列在嵌入式系统中的应用(系统优化全攻略)
# 摘要
TI 28X系列DSP系统作为一种高性能数字信号处理平台,广泛应用于音频、图像和通信等领域。本文旨在提供TI 28X系列DSP的系统概述、核心架构和性能分析,探讨软件开发基础、优化技术和实战应用案例。通过深入解析DSP系统的设计特点、性能指标、软件开发环境以及优化策略,本文旨在指导工程师有效地利用DSP系统的
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )