【高可用Hadoop集群部署指南】:DFSZKFailoverController实战技巧
发布时间: 2024-10-26 17:04:36 阅读量: 51 订阅数: 34 

9、hadoop高可用HA集群部署及三种方式验证
# 1. 高可用Hadoop集群部署概述
在构建大数据处理平台时,高可用性是核心需求之一。Hadoop作为业界广泛采用的大数据处理框架,其集群的稳定运行对于业务连续性至关重要。本章节将从宏观角度介绍高可用Hadoop集群部署的基本概念、目标和流程,为读者提供Hadoop集群部署的全景视角。
部署高可用的Hadoop集群,不仅仅是技术上的挑战,也是对业务需求和数据管理策略的深入理解。它涉及到集群架构设计、组件选择、故障转移机制、系统容错与恢复策略等关键因素,确保在出现硬件故障、软件错误或网络问题时,整个系统能够持续稳定运行,保证数据的可用性、完整性和一致性。
通过本章的阅读,读者将获得对高可用Hadoop集群部署的认识,了解其核心价值和部署前的准备工作,为后续的组件解析和具体部署步骤奠定基础。
# 2. Hadoop集群核心组件解析
## 2.1 Hadoop核心组件介绍
### 2.1.1 HDFS的架构与工作原理
Hadoop分布式文件系统(HDFS)是Hadoop的一个核心组件,它被设计用来存储和处理大规模数据集。HDFS的架构由以下几个关键组件组成:
- NameNode:负责管理文件系统的命名空间以及客户端对文件的访问。NameNode存储了所有的文件和目录信息,包括每个文件由哪些块组成,每个块存放在哪些DataNode上。
- DataNode:负责存储实际的数据,并处理数据的读写请求。DataNode通常部署在集群的每个工作节点上。
- Secondary NameNode:它不是NameNode的热备份,主要用于合并编辑日志和文件系统状态。
HDFS工作原理可以用以下几个步骤概括:
1. 客户端通过NameNode发起文件的读写请求。
2. NameNode接收到请求后,进行检查和授权。
3. 如果是读请求,NameNode返回相关文件的DataNode信息给客户端。客户端直接与DataNode交互读取数据。
4. 如果是写请求,客户端将数据分块并直接发送给DataNode,然后通知NameNode更新文件系统的命名空间。
5. NameNode将文件系统更新信息记录到编辑日志,并定期执行文件系统的“检查点”操作。
6. DataNode负责数据的持久化存储,对数据块进行备份,以提高数据的可靠性和容错性。
接下来是HDFS的一个简单代码示例,用于理解HDFS API的基本使用:
```java
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create("hdfs://namenode:8020"), conf, "user");
Path path = new Path("/user/hadoop/file.txt");
// 写文件
FSDataOutputStream out = fs.create(path);
out.writeUTF("Hello, HDFS!");
out.close();
// 读文件
FSDataInputStream in = fs.open(path);
in.read();
in.close();
```
在此示例中,我们首先创建了一个HDFS的配置对象,然后使用该配置对象和URI创建了一个FileSystem对象。之后我们使用该FileSystem对象来创建和读取HDFS中的文件。
### 2.1.2 MapReduce的作业流程分析
MapReduce是Hadoop的核心编程模型,用于处理大量数据集的并行运算。一个MapReduce作业大致可以分为以下几个阶段:
- 输入分割:MapReduce作业会根据输入数据进行分割,每个分割成为输入分片(Input Split)。
- Map阶段:系统将每个分片的记录作为输入传递给Map函数,Map函数处理后输出键值对(key-value pairs)。
- Shuffle阶段:MapReduce框架会自动完成Shuffle过程,它包括对Map输出的键值对进行排序、分组,然后将相同键的所有值传输到Reduce任务。
- Reduce阶段:Reduce函数迭代处理这些键值对,并产生最终输出。
- 输出:最终结果通常写入到HDFS中。
下面是一个MapReduce作业的简单示例,演示如何在Java中实现一个MapReduce程序:
```java
public static class MyMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] words = value.toString().split(" ");
for (String str : words) {
word.set(str);
context.write(word, one);
}
}
}
public static class MyReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
context.write(key, new IntWritable(sum));
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(MyMapper.class);
job.setCombinerClass(MyReducer.class);
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
```
在这个示例中,我们定义了一个Mapper类和一个Reducer类。Mapper读取输入数据,将每行文本分割成单词并输出它们,Reducer则将相同的单词出现次数进行累加。最后我们配置了作业属性,并指定了输入输出路径。
## 2.2 ZooKeeper在Hadoop中的作用
### 2.2.1 ZooKeeper的基本概念
ZooKeeper是一个开源的分布式协调服务,它为分布式应用提供了高性能、高可用性和易于使用的协调机制。在Hadoop生态系统中,ZooKeeper主要用于协调和管理集群中的节点。
ZooKeeper的数据模型可以看作是一个树状结构,其中每个节点称为znode,它不仅可以存储数据,还能维持子节点。ZooKeeper的特性包括:
- 顺序一致性:操作的执行顺序与客户端请求的顺序一致。
- 原子性:更新操作要么完全执行,要么完全不执行。
- 单一系统映像:客户端无论连接到哪个服务器,都能看到相同的系统视图。
- 可靠性:一旦对znode的更改被提交,就会持久化,直到被另一个更改覆盖。
- 实时性:客户端在一定时间范围内可以获取最新的更新。
### 2.2.2 ZooKeeper在集群管理中的应用
在Hadoop集群管理中,ZooKeeper主要用作以下场景:
- NameNode高可用性:在Hadoop 2.x版本中,ZooKeeper用于管理HDFS NameNode的主备切换,确保在主节点失败时可以迅速切换到备用节点。
- YARN资源管理器选举:在YARN集群中,ZooKeeper负责协调不同资源管理器节点,确保集群中只有一个资源管理器处于活跃状态。
- 服务发现与配置管理:ZooKeeper可以为集群中的服务提供发现机制,帮助服务节点找到集群中的其他服务。
- 分布式锁:在需要同步处理的场景中,ZooKeeper提供分布式锁服务。
在实际应用中,ZooKeeper集群通常由奇数个节点构成,这样即使在部分节点失效的情况下,仍然可以提供服务。
## 2.3 高可用性设计原理
### 2.3.1 故障转移机制
高可用性(High Availability,HA)是Hadoop集群设计中的一项重要指标,它确保集群在部分组件失败的情况下仍然能够提供服务。在Hadoop的高可用设计中,故障转移机制扮演着关键角色。
故障转移机制主要通过以下步骤实现:
1. 监测:使用Heartbeat机制持续检测集群中各个组件的健康状态。
2. 切换:当检测到主节点(例如NameNode或ResourceManager)出现故障时,备用节点接管服务,成为新的主节点。
3. 一致性:确保在切换过程中数据的一致性和完整性。
故障转移的实现依赖于多个组件的协同工作,比如ZooKeeper、HDFS以及YARN的高可用特性。
### 2.3.2 系统容错与恢复策略
高可用Hadoop集群中的容错设计意味着即使发生故障,集群也应该能够快速恢复到正常状态,继续提供服务。恢复策略包含以下几个方面:
- 数据副本:通过在多个DataNode上存储数据块的副本来保证数据的可靠性。
- 自动故障检测与恢复:集群组件需要能够自动检测到故障并触发恢复程序。
- 快速重启:失败的节点或服务需要能够快速重启,并重新加入集群。
- 事务日志:关键操作都会记录到事务日志中,以便在发生故障时能够恢复到最近的稳定状态。
通过上述容错和恢复策略,Hadoop集群能够处理各种类型的故障,从而提供持续稳定的服务。
下表展示了高可用性设计中的不同策略以及它们的作用:
| 策略 | 作用 |
| --- | --- |
| 故障检测 | 及时发现系统中的异常节点 |
| 快速切换 | 在主节点失效时迅速切换到备用节点 |
| 数据冗余 | 保证数据不丢失,可恢复 |
| 自动恢复 | 通过预设脚本自动修复故障节点 |
| 人工干预 | 当系统自动恢复失败时,允许管理员介入处理 |
通过这样的策略组合,Hadoop集群能够实现真正意义上的高可用性,极大地增强了系统的稳定性和可靠性。
# 3. 配置和部署Hadoop集群
## 3.1 环境准备与集群规划
### 3.1.1 硬件与软件要求
构建一个高效、稳定的Hadoop集群,硬件与软件的选择至关重要。硬件方面,我们需要为集群中的每个节点分配足够的CPU核心、内存和存储空间。一般来说,每个节点应具备至少4个CPU核心和8GB内存,而存储空间则根据实际需求进行分配,通常需要使用多块硬盘通过RAID技术来保证数据的安全性和读写速度。
软件方面,需要安装操作系统、JDK以及Hadoop集群软件包。操作系统推荐使用Linux发行版,如CentOS,这是因为大多数Hadoop组件都是在Linux环境下开发和运行的。JDK的版本要与Hadoop版本兼容,一般来说,Hadoop 3.x版本需要JDK 1.8或更高版本。
### 3.1.2 集群角色分配与规划
在一个Hadoop集群中,主要有三种角色:NameNode、DataNode和ResourceManager。NameNode负责管理文件系统的命名空间,维护文件系统树及整个文件系统的元数据;DataNode则负责存储实际的数据;ResourceManager负责管理集群中的资源,并根据应用程序的资源需求进行调度。
在集群规划时,通常会设置一个或多个备用NameNode来提高系统的高可用性。此外,针对大规模集群,也可以考虑设置多个ResourceManager,以及多个NameNode和DataNode组成的Hadoop高可用集群架构。
## 3.2 Hadoop集群的安装步骤
### 3.2.1 基本安装流程
安装Hadoop集群的基本流程可以分为以下几个步骤:
1. 准备工作:在所有机器上配置好主机名和IP地址,设置好SSH无密码登录,确保所有节点间网络畅通。
2. 安装JDK:根据规划安装对应版本的JDK,并设置环境变量。
3. 安装Hadoop:下载Hadoop软件包,并解压到指定目录。
4. 配置环境变量:设置`HADOOP_HOME`,并将`$HADOOP_HOME/bin`添加到系统的`PATH`变量中。
5. 格式化文件系统:使用`hdfs namenode -format`命令格式化NameNode。
```bash
# 示例:格式化NameNode
ssh root@namenode "hdfs namenode -format"
```
6. 启动集群:使用`start-all.sh`脚本来启动集群的各个服务。
### 3.2.2 集群配置详解
Hadoop的配置主要涉及`core-site.xml`、`hdfs-site.xml`、`yarn-site.xml`等配置文件。以下是一些关键参数的设置:
- `fs.defaultFS`:设置HDFS的默认文件系统。
- `dfs.replication`:设置HDFS文件的默认复制因子。
- `yarn.resourcemanager.address`:设置ResourceManager的地址。
- `yarn.nodemanager.aux-services`:指定NodeManager使用的辅助服务,比如MapReduce。
```xml
<!-- core-site.xml 示例配置 -->
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://namenode:8020</value>
</property>
</configuration>
```
## 3.3 配置Hadoop高可用集群
### 3.3.1 设置ZooKeeper集群
ZooKeeper在Hadoop集群中扮演着关键的角色,主要负责维护配置信息、提供分布式锁等服务,对于实现高可用集群至关重要。要设置ZooKeeper集群,首先需要安装并配置ZooKeeper服务。
安装ZooKeeper时需要在多个节点上执行,并配置其`zoo.cfg`文件,指定其他ZooKeeper节点的地址。
```xml
<!-- zoo.cfg 示例配置 -->
server.1=zoo1:2888:3888
server.2=zoo2:2888:3888
server.3=zoo3:2888:3888
```
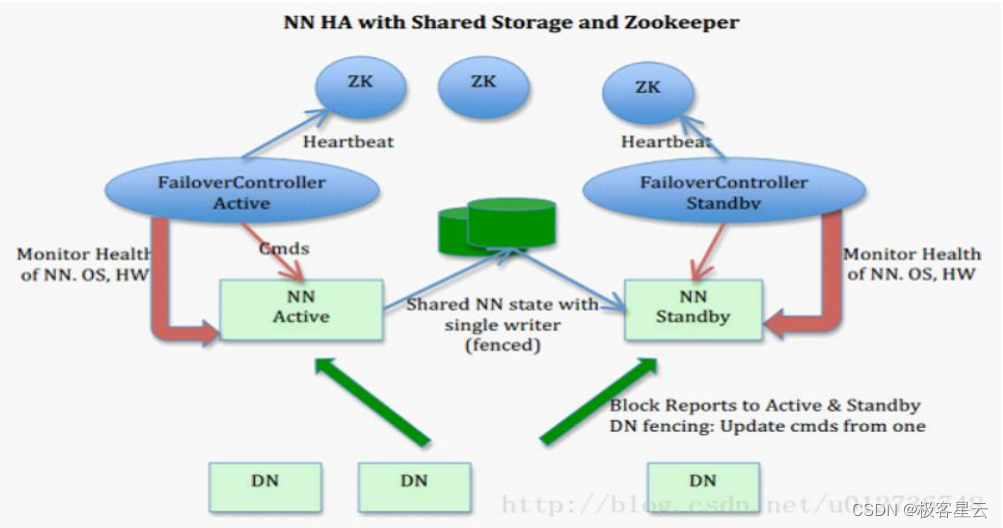
### 3.3.2 配置故障转移控制器(DFSZKFailoverController)
故障转移控制器(DFSZKFailoverController)是Hadoop中的一个组件,用于监控NameNode的健康状态,并在主NameNode故障时自动触发故障转移,提升备用NameNode为新的主NameNode。
配置DFSZKFailoverController时,需要在`hdfs-site.xml`中添加相关配置,指定ZooKeeper集群的连接信息,并设置故障转移时的超时时间。
```xml
<!-- hdfs-site.xml 示例配置 -->
<configuration>
<property>
<name>ha.zookeeper.quorum</name>
<value>zoo1:2181,zoo2:2181,zoo3:2181</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
</configuration>
```
通过上述配置,Hadoop集群能够实现更加稳定和可靠的服务,确保在面对节点故障时能够迅速响应并恢复正常服务。
# 4. Hadoop集群的优化与监控
随着企业数据量的不断增长,对于Hadoop集群的性能要求也在逐渐提高。为了确保集群能够提供稳定的高性能服务,优化和监控工作显得尤为重要。本章将深入探讨Hadoop集群的优化策略、监控工具以及日常维护和故障排除的实践方法。
## 4.1 集群性能调优
在面对复杂的计算任务时,合理的参数调优能够显著提升Hadoop集群的运行效率。下面将详细介绍调优技巧和性能优化的策略。
### 4.1.1 Hadoop参数调优技巧
Hadoop集群的性能直接受到各种配置参数的影响。要进行有效的性能调优,首先需要理解以下几个核心的配置参数:
- `fs.inmemory.size.mb`:此参数控制DFS使用的内存大小,可以提高小文件读取的性能。
- `io.sort.factor`:定义了Map输出时,内存中能够同时处理的流的数量,适当增加这个值可以提高排序速度。
- `mapreduce.jobhistory.address`:配置JobHistory服务器的地址和端口,便于跟踪和管理MapReduce作业的历史信息。
调优步骤可以分为以下几个阶段:
1. **基准测试**:运行基准测试来获得集群的原始性能数据。
2. **参数分析**:分析参数对集群性能的影响,这可能需要通过多次试验来确定最佳值。
3. **负载测试**:在模拟的生产负载下测试调整后的配置。
4. **监控与调整**:持续监控集群的表现,根据实时数据调整参数。
### 4.1.2 网络与IO性能优化
网络和IO性能是影响Hadoop集群性能的关键因素。以下是一些具体的优化建议:
- **网络优化**:
- 使用高性能网络硬件,如10G以太网卡,以减少网络延迟。
- 配置网络参数如`dfs.namenode.handler.count`,以提高NameNode的处理能力。
- **IO性能优化**:
- 调整HDFS块大小(`dfs.block.size`)以更好地适应数据存取模式。
- 使用SSD作为HDFS的存储介质,以提升IO性能。
## 4.2 集群监控工具与实践
监控是确保集群稳定运行的重要环节。有效的监控不仅可以帮助管理员发现潜在问题,还能在发生故障时快速响应。
### 4.2.1 常用监控工具介绍
- **Ambari**:提供了一个直观的Web界面,能够方便地监控集群状态,安装和管理服务,并且支持告警。
- **Ganglia**:一个高性能、可扩展的分布式监控系统,用于收集和监控集群的性能数据。
- **Nagios**:一个开源的系统和网络监控应用,它可以监视集群中的主机和服务。
### 4.2.2 集群监控设置与告警机制
一个典型的监控设置流程如下:
1. **安装监控工具**:根据选择的工具进行安装和配置。
2. **配置数据收集器**:设置代理或数据收集器以收集性能指标数据。
3. **设置阈值和告警规则**:定义阈值来触发告警,比如CPU使用率过高或磁盘空间不足。
4. **告警通知**:配置告警通知方式,如邮件、短信或即时消息通知。
下面是一个基于Ambari的监控设置示例代码块:
```json
// Ambari monitor configuration snippet
{
"type": "metric",
"definition": [
{
"name": "CPU.Utilization (%)",
"metric": "system.cpu.utilization",
"condition": {
"max": 90
},
"tags": {
"cluster": "default"
},
"period": 60
}
]
}
```
在上述示例中,我们定义了一个监控规则,当集群的CPU使用率达到90%时,触发告警。
## 4.3 集群的日常维护和故障排除
即使在做了充分的优化和监控之后,集群仍然可能遇到各种各样的问题。因此,了解日常维护和故障排除的技巧是每个管理员必备的技能。
### 4.3.1 常见问题及解决方法
- **NameNode故障**:当NameNode发生故障时,可以使用Secondary NameNode来恢复系统,或者配置高可用性的NameNode。
- **数据不平衡**:使用`hdfs balancer`命令对数据进行重新分布,解决数据不平衡的问题。
### 4.3.2 集群升级与扩展策略
随着业务的增长,集群可能需要进行升级或扩展。升级和扩展的基本步骤包括:
1. **规划升级**:评估集群的使用情况,制定详细的升级计划。
2. **分批次升级**:将集群分成多个部分,逐步进行组件的升级,以减少风险。
3. **测试新版本**:在升级前先在一个小的测试集群上安装和测试新版本的Hadoop。
4. **数据备份**:在升级之前对集群中的数据进行备份,以防万一。
下面是一个集群升级前的检查表表格:
| 检查项 | 是否完成 | 备注 |
|--------------------------|---------|------|
| 系统备份 | 是 | |
| Hadoop版本兼容性检查 | 是 | |
| 硬件资源评估 | 是 | |
| 集群测试升级计划 | 是 | |
| 集群性能测试 | 否 | 待完成 |
| 业务连续性计划测试 | 是 | |
| 文档更新与培训计划 | 否 | 待完成 |
通过上述章节的介绍,我们可以了解到Hadoop集群优化与监控的重要性以及具体的实施方法。了解这些信息对于保障集群的稳定性、提升集群的运行效率至关重要。
# 5. 实战技巧与案例分析
## 5.1 DFSZKFailoverController深入解析
### 5.1.1 内部工作机制
DFSZKFailoverController(DFSZKFC)是Hadoop高可用集群中用于故障转移的关键组件。它通过与ZooKeeper进行交互,实时监控Active和Standby NameNode的状态,并在需要时执行故障切换。
要深入理解DFSZKFC的工作原理,首先需要了解其与ZooKeeper之间的通信机制。DFSZKFC会创建一个持久节点在ZooKeeper集群中,该节点用于跟踪当前Active NameNode的状态。若Active NameNode发生故障,DFSZKFC将通过ZooKeeper的顺序节点创建能力选举新的Active NameNode。这一过程涉及以下几个关键步骤:
1. **状态检查**:DFSZKFC定期检查本地NameNode的状态。
2. **状态发布**:将当前Active NameNode的状态信息写入ZooKeeper。
3. **故障检测**:DFSZKFC通过监听ZooKeeper中的状态信息,发现故障节点。
4. **故障处理**:一旦检测到Active NameNode故障,启动故障转移流程,选举新的Active NameNode。
### 5.1.2 配置技巧与最佳实践
配置DFSZKFC时,需要确保几项关键的参数设置正确:
- **dfs.ha.fencing.methods**:定义了故障转移期间的隔离方法,确保旧的Active NameNode不再接受请求。
- **dfs.ha.fencing.ssh.user**:指定用于SSH隔离的用户名。
- **dfs.ha.fencing.ssh.private-key-files**:指定SSH访问时使用的私钥文件。
最佳实践包括:
- **持久化ZooKeeper节点配置**:确保在集群重启后,DFSZKFC能够迅速恢复故障转移机制。
- **资源隔离**:合理配置隔离方法,例如使用SSH或shell命令来隔离故障节点。
- **监控和日志**:保持对DFSZKFC相关日志和监控的持续关注,以便于快速发现并处理异常情况。
## 5.2 Hadoop集群实战案例
### 5.2.1 企业级部署案例
在企业级部署中,我们通常会面临资源限制、数据安全、高并发访问等挑战。Hadoop的高可用集群部署是解决这些问题的关键。
部署案例中我们关注:
- **资源规划**:如何根据业务需求合理分配硬件资源。
- **数据安全**:实现NameNode的高可用,并采取数据备份和冗余策略。
- **高并发优化**:使用QJM(Quorum Journal Manager)等组件确保数据一致性。
### 5.2.2 高可用集群故障排查实例
在高可用集群部署过程中,故障排查是不可避免的。以下是一个常见的故障排查实例:
- **故障现象**:集群在运行过程中,突然失去一个NameNode的服务能力。
- **排查步骤**:
1. 检查NameNode的日志文件,寻找可能的错误信息。
2. 查看ZooKeeper集群状态,确认DFSZKFC是否执行了故障转移。
3. 使用Hadoop提供的诊断工具,如`hdfsadmin`和`yarnadmin`,进行问题诊断。
4. 分析故障期间集群网络流量,检查是否有异常流量导致资源争用。
- **解决方案**:
- 如果NameNode故障由硬件问题引起,替换损坏的硬件。
- 如果是软件问题,考虑升级Hadoop版本或应用补丁。
- 如果ZooKeeper集群故障,检查集群健康状况并进行必要的维护。
## 5.3 未来发展趋势与展望
### 5.3.1 Hadoop生态系统的新技术
随着大数据技术的发展,Hadoop生态系统也在不断创新。未来趋势可能包括:
- **新一代Hadoop发行版**:拥抱云原生架构,提高资源利用率。
- **更高效的存储技术**:利用NFSv4、云存储等技术提升数据存储的效率和可靠性。
- **增强的数据处理能力**:通过集成Spark、Flink等大数据处理框架,优化处理流程。
### 5.3.2 高可用架构的演进
高可用架构将向着更加智能和自适应的方向演进,其中包括:
- **自动故障恢复机制**:减少人工干预,实现故障后快速自动恢复。
- **资源动态调度**:根据实际负载情况动态调整资源分配,以优化集群性能。
- **预测性维护**:通过机器学习技术预测潜在故障,提前进行预防性维护。
通过以上章节内容的展开,我们可以看到Hadoop集群的部署和优化不仅仅是一项技术实践,更是一种深度探索和持续创新的过程。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
该专栏深入探讨了 Hadoop 分布式文件系统 (DFS) 中的 DFSZKFailoverController,这是实现高可用性的关键组件。它涵盖了 10 个角色和机制,5 个设计原理,实战技巧,故障恢复流程,数据零丢失策略,参数调优,自动化恢复,ZooKeeper 依赖,网络分区应对,维护技巧,成功案例,扩展性优化,社区动态和架构对比。通过深入分析和实际案例,该专栏为读者提供了全面了解 DFSZKFailoverController 的工作原理、最佳实践和优化策略,帮助他们构建和维护高度可用的 Hadoop 集群,确保数据安全和业务连续性。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
CDD版本控制实战:最佳实践助你事半功倍

# 摘要
本文详细探讨了CDD(Configuration-Driven Development)版本控制的理论与实践操作,强调了版本控制在软件开发生命周期中的核心作用。文章首先介绍了版本控制的基础知识,包括其基本原理、优势以及应用场景,并对比了不同版本控制工具的特点和选择标准。随后,以Git为例,深入阐述了版本控制工具的安装配置、基础使用方法以及高
Nginx与CDN的完美结合:图片快速加载的10大技巧
# 摘要
本文详细探讨了Nginx和CDN在图片处理和加速中的应用。首先介绍了Nginx的基础概念和图片处理技巧,如反向代理优化、模块增强、日志分析和性能监控。接着,阐述了CDN的工作原理、优势及配置,重点在于图片加
高速数据处理关键:HMC7043LP7FE技术深度剖析
# 摘要
HMC7043LP7FE是一款集成了先进硬件架构和丰富软件支持的高精度频率合成器。本文全面介绍了HMC7043LP7FE的技术特性,从硬件架构的时钟管理单元和数字信号处理单元,到信号传输技术中的高速串行接口与低速并行接口,以及性能参数如数据吞吐率和功耗管理。此外,详细阐述了其软件支持与开发环境,包括驱动与固件开发、
安全通信基石:IEC103协议安全特性解析
# 摘要
IEC 103协议是电力自动化领域内广泛应用于远动通信的一个重要标准。本文首先介绍了IEC 103协议的背景和简介,然后详细阐述了其数据传输机制,包括帧结构定义、数据封装过程以及数据交换模式。接下来,本文深
EB工具错误不重演:诊断与解决观察角问题的黄金法则

# 摘要
EB工具在错误诊断领域发挥着重要作用,特别是在观察角问题的识别和分析中。本文从EB工具的基础知识开始,深入探讨观察角问题的理论与实践,涵盖了理论基础、诊断方法和预防策略。文章接着介绍了EB工具的高级诊断技术,如问题定位、根因分析以及修复策略,旨在提高问题解决的效率和准确性。通过实践案例的分析,本文展示了EB工具的应用效果,并从失败案例中总结了宝贵经验。最后,文章展望了EB工具未来的发展趋势和挑战,并提出了全方位优化EB工具的综合应用指南,以
深入STM32F767IGT6:架构详解与外设扩展实战指南
# 摘要
本文详细介绍了STM32F767IGT6微控制器的核心架构、内核功能以及与之相关的外设接口与扩展模块。首先概览了该芯片的基本架构和特性,进一步深入探讨了其核心组件,特别是Cortex-M7内核的架构与性能,以及存储器管理和系统性能优化技巧。在第三章中,具体介绍了各种通信接口、多媒体和显示外设的应用与扩展。随后,第四章阐述了开发环境的搭建,包括STM32CubeMX配置工具的应用、集成开发环境的选择与设置,以及调试与性能测试的方法。最后,第五章通过项目案例与实战演练,展示了STM32F767IGT6在嵌入式系统中的实际应用,如操作系统移植、综合应用项目构建,以及性能优化与故障排除的技巧
以太网技术革新纪元:深度解读802.3BS-2017标准及其演进
# 摘要
以太网技术作为局域网通讯的核心,其起源与发展见证了计算技术的进步。本文回顾了以太网技术的起源,深入分析了802.3BS-2017标准的理论基础,包括数据链路层的协议功能、帧结构与传输机制,以及该标准的技术特点和对网络架构的长远影响。实践中,802.3BS-2017标准的部署对网络硬件的适配与升级提出了新要求,其案例分析展示了数据中心和企业级应用中的性能提升。文章还探讨
日鼎伺服驱动器DHE:从入门到精通,功能、案例与高级应用
# 摘要
日鼎伺服驱动器DHE作为一种高效能的机电控制设备,广泛应用于各种工业自动化场景中。本文首先概述了DHE的理论基础、基本原理及其在市场中的定位和应用领域。接着,深入解析了其基础操作,包括硬件连接、标准操作和程序设置等。进一步地,文章详细探讨了DHE的功能,特别是高级控制技术、通讯网络功能以及安全特性。通过工业自动化和精密定位的应用案例,本文展示了DHE在实际应用中的性能和效果。最后,讨论了DHE的高级应用技巧,如自定义功能开发、系统集成与兼容性,以及智能控制技术的未来趋势。
# 关键字
伺服驱动器;控制技术;通讯网络;安全特性;自动化应用;智能控制
参考资源链接:[日鼎DHE伺服驱
YC1026案例分析:揭秘技术数据表背后的秘密武器

# 摘要
YC1026案例分析深入探讨了数据表的结构和技术原理,强调了数据预处理、数据分析和数据可视化在实际应用中的重要性。本研究详细分析了数据表的设计哲学、技术支撑、以及读写操作的优化策略,并应用数据挖掘技术于YC1026案例,包括数据预处理、高级分析方法和可视化报表生成。实践操作章节具体阐述了案例环境的搭建、数据操作案例及结果分析,同时提供了宝贵的经验总结和对技术趋势的展望。此
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )