【大数据异常挖掘】:在海量数据中发现异常的策略与工具
发布时间: 2024-09-07 17:08:23 阅读量: 78 订阅数: 49 

混合四策略改进SSA优化算法:MISSA的实证研究与应用展望 经过融合spm映射、自适应-正余弦算法、levy机制、步长因子动态调整四种策略的改进,MISSA算法测试结果惊艳,麻雀飞天变凤凰 目前相
# 1. 大数据异常挖掘概述
大数据异常挖掘是数据分析领域的一个关键分支,它关注于识别数据集中的不规则或异常模式。这种技术对于检测欺诈行为、系统故障、网络安全威胁等方面至关重要。随着数据量的急剧增长,异常挖掘技术也迅速发展,逐渐成为IT和数据分析专家的核心技能之一。
异常挖掘不仅是简单地找到数据中的异常点,而是通过深层次的数据分析,揭示潜在的问题和风险。其应用范围广泛,不仅限于IT行业,还涉及金融、医疗、制造等多个领域。本章旨在为读者提供异常挖掘的基本概念和重要性,为后续深入探讨异常挖掘的理论、工具和实践案例奠定基础。
# 2. 异常挖掘的理论基础
## 2.1 异常值的定义和特征
### 2.1.1 统计学中的异常值概念
在统计学中,异常值(Outlier)是指一个数据点在给定数据集中与其它数据相比显得异常,它可能表明了测量错误、数据污染或自然变异的一种不寻常形式。异常值的存在可以显著影响数据的统计特性,如均值和方差,因此在数据分析和挖掘过程中,正确识别并处理异常值是非常重要的。
例如,在一组正态分布的体重数据中,一个体重远高于或远低于平均值的个体可能是一个异常值,这可能是个别测量错误,也可能是由于特殊的生活习惯或生理条件造成的。
### 2.1.2 异常值的分类及识别方法
异常值可以根据其发生的原因进行分类,大致可以分为三类:
1. **全局异常(Global Outliers)**:在一个数据集中全局地表现出异常的点。例如,一个国家的平均收入数据中异常高的个人收入。
2. **上下文异常(Contextual Outliers)**:在特定上下文或条件中表现为异常的点。例如,在特定季节或地区内的异常气候条件。
3. **集体异常(Collective Outliers)**:一组数据点共同表现出异常,但单独每个数据点看起来并不异常。例如,一组传感器数据可能在特定时间点集体报告异常,表明某种未预料的系统状态。
识别异常值的方法多种多样,常见的有:
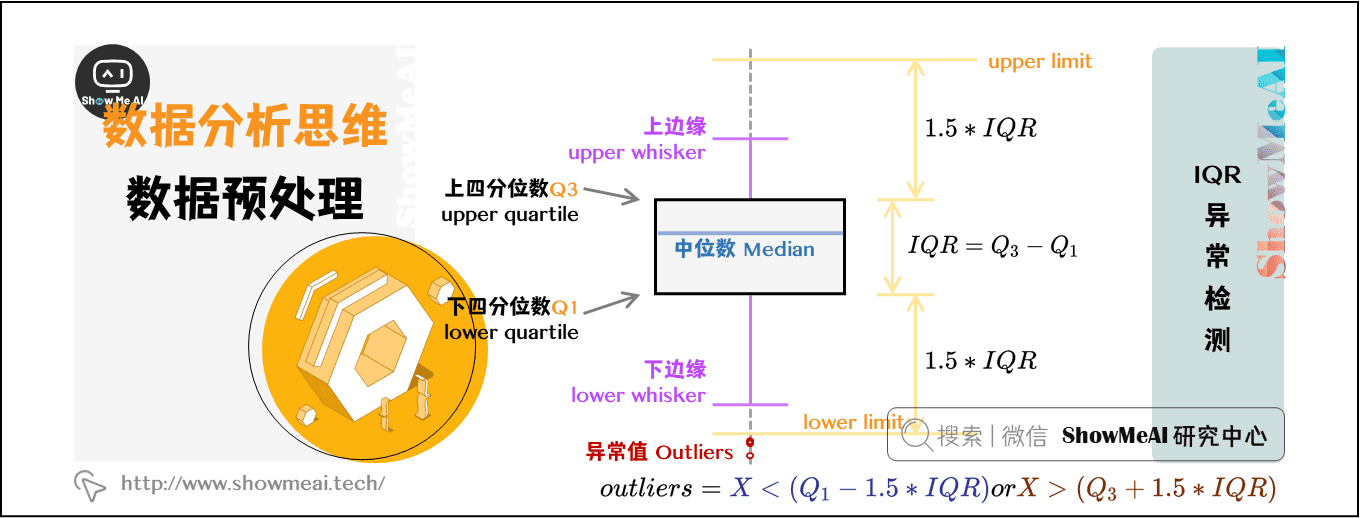
- **标准差法**:基于数据的均值和标准差,设定一个阈值(如均值±3倍标准差),数据点若超出此范围,则认为是异常值。
- **四分位距法(IQR)**:利用四分位数来定义异常值。超出1.5倍IQR(第一四分位数到第三四分位数的距离)范围的数据点被认为是异常的。
### 2.1.3 识别过程中的注意事项
识别异常值时,还需要注意以下几点:
- **数据的分布特性**:在非正态分布数据中,使用标准差法可能会导致错误的异常值判断。
- **数据的领域知识**:在某些情况下,需要结合领域知识来判断数据点是否为异常值。
- **异常值的处理**:在发现异常值后,应考虑是否需要进行处理。处理方法包括删除异常值、用中位数替代等。
## 2.2 异常检测的算法原理
### 2.2.1 统计学方法
统计学方法是异常检测中最早使用的方法之一。这类方法通常基于数据的统计特性,如均值、方差等来识别异常值。常见的统计学方法包括:
- **箱型图(Boxplot)**:利用四分位数和四分位距来识别异常值。
- **Grubbs' Test**:一种用于检测单变量数据集中是否含有单一全局异常值的假设检验方法。
### 2.2.2 机器学习方法
随着机器学习技术的发展,越来越多的异常检测算法基于机器学习方法。这些方法通常需要一个训练数据集来学习数据的正常行为模式,并根据这些模式来检测异常。常见的机器学习方法包括:
- **One-Class SVM**:适合于未标记数据的异常检测,通过学习数据的主要分布,对偏离这一分布的数据点进行标记。
- **Isolation Forest**:一种集成学习方法,通过随机选择特征和随机切分值来“孤立”观察值,异常点由于特征少且值偏离典型特征值而更容易被孤立出来。
### 2.2.3 深度学习方法
深度学习在异常检测领域表现出色,特别是对高维数据和复杂数据模式的异常检测。基于深度学习的异常检测方法包括:
- **自编码器(Autoencoders)**:一种用于无监督学习的神经网络,通过训练一个神经网络学习输入数据的有效表示(编码),再通过网络重建输入数据,使得网络能够重建正常数据,而对异常数据重建效果不佳。
- **生成对抗网络(GANs)**:利用两个网络,一个生成网络(Generator)生成数据,一个判别网络(Discriminator)判断数据的真伪。通过训练,可以使得生成网络生成正常数据分布,异常数据将被两个网络识别为假。
## 2.3 异常检测的评估指标
### 2.3.1 精确度、召回率和F1分数
在机器学习模型中,精确度(Precision)、召回率(Recall)和F1分数是常用的评估指标。
- **精确度**:在所有被模型判定为异常的数据点中,真正是异常的所占的比例。
- **召回率**:在所有实际异常的数据点中,被模型正确识别出的比例。
- **F1分数**:精确度和召回率的调和平均,是二者的综合指标。高F1分数意味着模型的性能均衡。
### 2.3.2 ROC曲线和AUC值
受试者工作特征曲线(ROC)和曲线下面积(AUC)是评估分类器性能的另一种方法。
- **ROC曲线**:在不同的分类阈值下绘制出的真正例率(True Positive Rate, TPR)与假正例率(False Positive Rate, FPR)的关系图。
- **AUC值**:ROC曲线下的面积,值范围从0到1。AUC值越接近1,表示模型的分类效果越好。
### 2.3.3 进一步的评估指标
除了上述指标外,还有其他的指标来评估异常检测模型的性能:
- **检测率**:异常点被检测出的概率。
- **误报率**:正常数据被错误地识别为异常的比例。
- **正常数据检测率**:正常数据未被错误识别为异常的比例。
这些指标可以帮助我们从不同角度评估异常检测模型的有效性,并选择最适合特定应用场景的模型。
通过对异常挖掘理论基础的学习,我们能更好地理解异常值的概念、分类和识别方法,以及异常检测的各种算法原理和评估指标。这些基础知识是开展异常挖掘实践和深入研究的重要基础。在下一章中,我们将深入探讨大数据异常挖掘实践工具的使用和构建实时异常检测系统的方法。
# 3. 大数据异常挖掘实践工具
## 3.1 开源数据分析平台
### 3.1.1 Apache Hadoop与HDFS
Apache Hadoop是一个开源框架,用于存储和处理大规模数据集的软件平台。Hadoop的核心是HDFS(Hadoop Distributed File System)和MapReduce编程模型。HDFS是一个高度容错的系统,设计用于部署在廉价的硬件上。它提供高吞吐量的数据访问,非常适合大规模数据集的应用。
HDFS使用主从架构,由一个NameNode和多个DataNodes组成。NameNode负责管理文件系统的命名空间和客户端对文件的访问。DataNodes负责存储实际的数据。在处理大数据时,HDFS能够将数据分割成多个块(block),并分布式存储在集群的多

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨异常检测方法,涵盖了广泛的技术和实践。从算法和工具的全面解析到异常检测原理和实践的深入分析,再到数据预处理、模型构建和实时监控策略的详细指南,本专栏提供了全面的知识,帮助读者打造无懈可击的检测系统。此外,还探讨了异常检测对企业决策的影响,以及整合多源数据进行异常检测的策略和实践。通过阅读本专栏,读者将获得在各种场景中有效检测和响应异常情况所需的技能和知识。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【微信小程序架构深度解析】:SSM框架与小程序整合的终极指南
# 摘要
随着移动互联网技术的快速发展,微信小程序作为一种新型的应用形式,其架构和开发实践已成为业界关注的热点。本文首先概述了微信小程序的架构,然后深入探讨了SSM(Spring, SpringMVC, MyBatis)框架与小程序的整合方式,接着从前端和后端两个方面详细阐述了小程序的开发实践,
PJ80高级特性详解:精通依赖注入与事件驱动架构
# 摘要
本文综合探讨了PJ80框架的高级特性和现代软件架构设计中的核心概念,重点分析了依赖注入原理及其在PJ80中的应用,并深入阐述了事件驱动架构的基本理论与实践。文章首先概述了依赖注入的核心原理及其优势,包括不同注入类型的实现方式与高级模式,随后探讨了事件驱动架构的基础知识、组件设计以及如何高效实现事件驱动系统。在PJ80框架的语境下,本文详细讨论了依赖注入和事件驱动架构的整合方法,
【HART设备调试秘籍】:现场调试不再难

# 摘要
本文全面介绍了HART通信协议,包括其基本理论、设备特性、调试工具、实操技巧和应用案例分析。首先概述了HART协议的概念和工作原理,然后详细解读了HART设备的理论基础,涵盖协议架构、命令集、功能码以及信号传输与解析。文章进一步探讨了调试HART设备所需的工具和软件,并提供了实用的配置、初始化、故障诊断和维护技巧。通过分析具体的应用案例,本文展示了HART在过程控制中的集成和应用,以及系统扩展的相关考虑。最
【vSAN存储策略定制】:高级配置与精细化管理技巧揭秘
# 摘要
本文详细探讨了vSAN存储策略的理论基础、定制与应用、高级管理技巧以及未来展望和最佳实践。首先介绍了vSAN的存储架构和理论基础,包括架构组件和数据管理,以及存储策略的关键概念和性能关系。接着,深入分析了如何定制存储策略、实时应用与管理的细节,并通过应用案例进一步阐释策略定制的实际操作。文章还涉及了高级管理技巧,包括故障排查、优化、变更管理以及自动化与API集成的策略
【电商新纪元】:5个关键步骤使用Spring Boot 323打造高并发美妆购物平台
-min.png?width=544&auto=webp&format=pjpg&disable=upscale&quality=100&dpr=2)
# 摘要
随着电商行业的快速发展,构建高并发、高性能的购物平台已成为
Aruba无线控制器深度解析:专家教你如何处理死锁问题

# 摘要
本文对Aruba无线控制器的死锁现象进行了系统性研究。首先概述了死锁的基本概念和产生的条件,然后介绍了Aruba无线控制器死锁时的常见症状及诊断方法。接下来,从理论视角探讨了死锁的预防与避免策略,包括资源分配策略和死锁预防算法,如银行家算法的介绍和比较。文章还详细讨论了在Aruba无线控制器中实践死锁解决的策略,包括系统配置优化和故障排除案例。最后,本文提出
MPE720软件故障排除:20个常见问题及绝妙解决方案

# 摘要
MPE720软件故障排除是一项关键任务,它确保系统的稳定性和性能。本文旨在概述故障排除的基本原则,并深入分析常见的软件故障类型及其诊断方法。我们从
SSO实战攻略:如何高效设计并实现跨平台单点登录系统
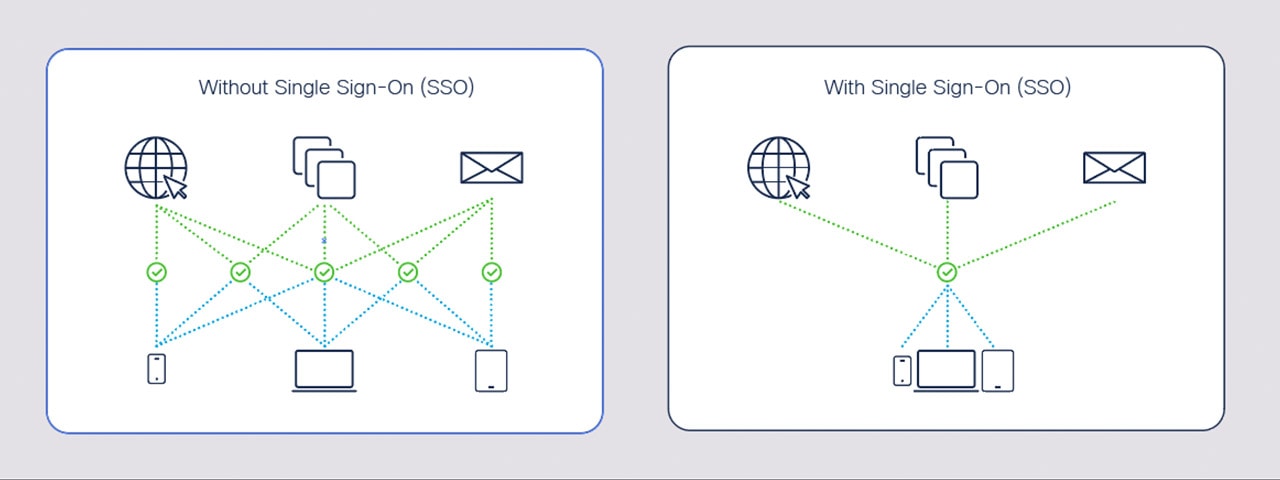
# 摘要
单点登录(SSO)系统是现代企业级应用中不可或缺的安全技术,它允许用户使用单一账号访问多个应用系统。本文首先介绍了SSO的基本概念和核心理论,包括认证授权机制、
【权威指南】Windows环境下的PostgreSQL安装全攻略:一步步带你安装最新版12.2
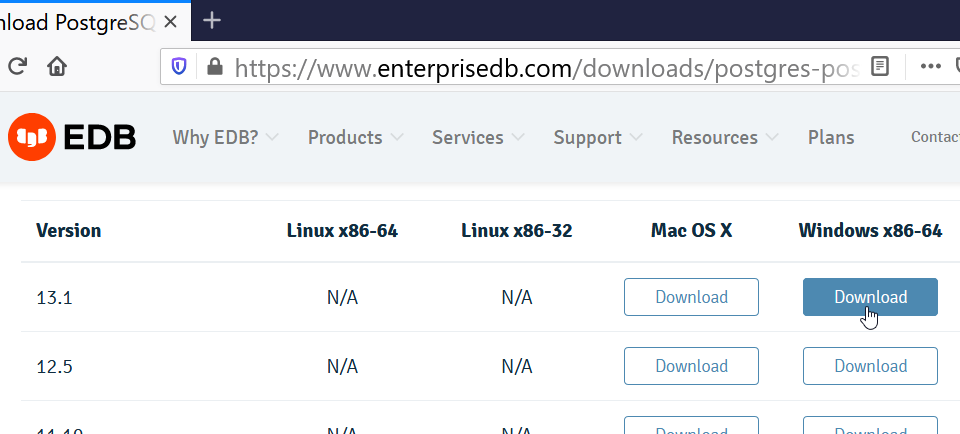
# 摘要
本文旨在为数据库管理员和系统工程师提供一份详尽的PostgreSQL在Windows环境下的安装、配置与管理指南。首先介绍了PostgreSQL的基础知识和安装前的准备工作,然后深入讲解了在Windows环境下安装PostgreSQL的
VSS版本控制最佳实践:如何有效管理项目代码的7大技巧
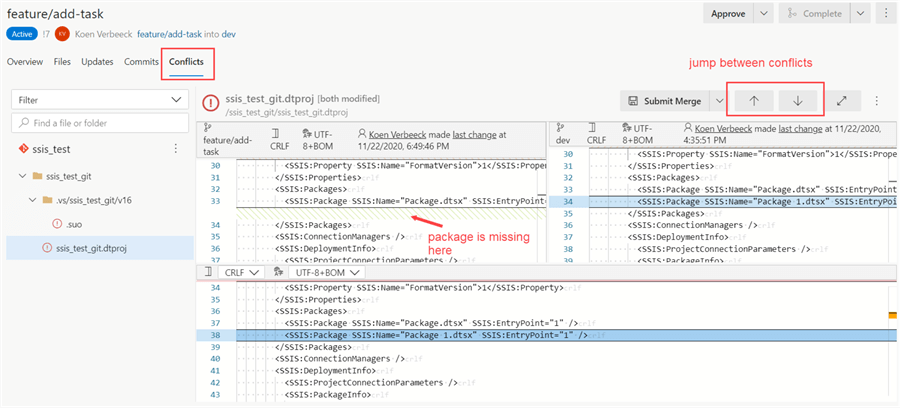
# 摘要
本文系统介绍了VSS版本控制系统的基本概念、配置流程、基础操作、高级技巧以及权限与安全策略。首先,文中对VSS的环境搭建、用户权限配置和项目初始化进行了详尽说明,确保用户能够顺利设置项目空间和管理工作区。随后,通过对文件检入检出、冲突解决和版本合并等基本操作的介绍,为读者提供了日常版本控制的实用指南。进阶章节深入探讨了分支管理、标签应用、外
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )