Python算法设计模式:掌握实战技巧,提升源码理解能力
发布时间: 2024-09-12 12:20:48 阅读量: 213 订阅数: 47 
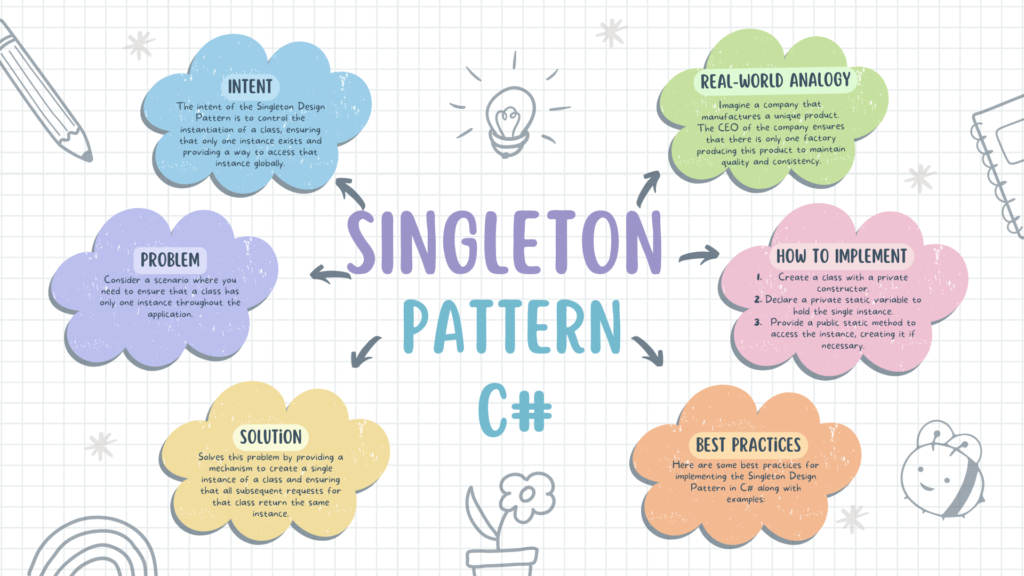
# 1. Python算法设计模式概述
在当今的软件开发领域,算法和设计模式是构建高效、可维护代码的两个关键要素。算法确保了程序的效率和性能,而设计模式则为实现这些算法提供了结构化和可复用的框架。Python作为一个动态、高级、解释型语言,在算法设计中呈现出独特的灵活性和表达力。本章节旨在为读者提供一个全面的Python算法设计模式概览,从设计模式的基本概念入手,阐述如何通过这些模式优化算法,并将其应用于解决实际问题。
在本章中,我们将探索以下主题:
- Python算法设计的重要性,以及设计模式在其中的作用。
- 设计模式的分类,包括创建型、结构型和行为型模式。
- 如何将设计模式理论知识应用到实际开发工作中,从而提高代码质量和性能。
通过深入理解设计模式与Python算法的结合,开发者可以更有效地构建复杂系统,实现代码的优雅和功能的强大。让我们揭开Python算法设计模式的神秘面纱,探索它们如何塑造现代软件开发的最佳实践。
# 2. ```
# 第二章:算法设计基础
## 2.1 Python数据结构与算法
### 2.1.1 常见的数据结构介绍
在Python中,数据结构是组织和存储数据的一种方式,它允许我们高效地访问和修改数据。了解和掌握这些数据结构对于任何想深入理解算法和提高编程技能的开发者来说都是基础。Python支持多种数据结构,其中最常见的是列表(List)、元组(Tuple)、字典(Dictionary)、集合(Set)和数组(Array)。
- **列表(List)**:列表是Python中最基本的数据结构,它是可变的,这意味着列表中的元素可以被修改。列表可以通过方括号或者list()函数创建,且支持任意类型的数据。
- **元组(Tuple)**:元组类似于列表,但是它是不可变的。创建元组使用圆括号,一旦创建,不能修改。元组通常用于保护数据不被修改。
- **字典(Dictionary)**:字典是存储键值对的数据结构,通过键来访问对应的值。字典是可变的,可以通过花括号或者dict()函数创建。
- **集合(Set)**:集合是一个无序的不重复元素集。基本功能包括关系运算和添加/删除元素。集合的创建通常使用大括号或者set()函数。
- **数组(Array)**:数组不同于列表,它只能包含相同类型的数据,且存储的是指向相同类型数据的指针。在Python中,数组可以通过array模块来实现。
了解这些基本数据结构后,对算法的理解和实现将更加容易。例如,理解如何使用字典来实现快速查找,或者如何通过列表的排序来快速定位数据。
### 2.1.2 算法复杂度基础
算法复杂度是衡量算法效率的重要指标,主要分为时间复杂度和空间复杂度。它们用于描述算法执行所需的时间和空间与问题规模之间的关系。
- **时间复杂度**:描述了算法执行的时间与输入数据规模之间的关系,常用大O符号表示。例如,O(n)表示算法的执行时间与输入数据的大小成线性关系。
- **空间复杂度**:描述了算法执行过程中所需的存储空间与输入数据规模之间的关系。同样使用大O符号表示。例如,O(1)表示算法所需的空间与输入数据大小无关,是一个常数。
理解这些复杂度概念对于评估算法的实际性能至关重要。在设计算法时,我们通常试图找到复杂度尽可能低的方法,以确保算法可以处理大规模数据。
在Python中,内置数据结构和标准库函数往往都经过了优化,能够提供较低的复杂度。然而,在设计自己的算法时,正确评估和优化算法复杂度是必不可少的。
## 2.2 设计模式的基本概念
### 2.2.1 设计模式的定义与重要性
设计模式是软件工程领域中针对特定问题的通用解决方案,它们是软件开发过程中形成的一套被广泛认可的最佳实践。设计模式不是特定的代码片段,而是一些模板或框架,用于解决特定的设计问题,使得软件设计更加灵活、可扩展和可重用。
设计模式的重要性体现在以下几个方面:
- **重用性**:设计模式提供了一种通用的语言和模板,让开发者能够重用他人的经验,并且可以在不同的项目之间重用相同的解决方案。
- **可维护性**:采用设计模式可以提高软件的可维护性。模式通常以一种易于理解的方式组织代码,使得其他人更容易理解和修改。
- **可扩展性**:设计模式有助于构建可扩展的系统。它们考虑到了未来的增长和变化,使得系统能够适应新的需求。
- **可测试性**:许多设计模式有助于进行单元测试和集成测试,因为它们鼓励使用松耦合和高内聚的设计。
### 2.2.2 设计模式的分类和选择
设计模式通常被分为三类:创建型模式、结构型模式和行为型模式。了解这些分类有助于我们选择最合适的模式来解决特定的设计问题。
- **创建型模式**:用于创建对象,同时隐藏创建逻辑,而不是使用new直接实例化对象。常见的创建型模式包括单例模式、工厂模式、抽象工厂模式、建造者模式和原型模式。
- **结构型模式**:涉及如何组合类和对象以获得更大的结构。常见的结构型模式包括适配器模式、桥接模式、组合模式、装饰器模式、外观模式、享元模式和代理模式。
- **行为型模式**:涉及对象之间的通信模式。常见的行为型模式包括解释器模式、迭代器模式、中介者模式、备忘录模式、观察者模式、状态模式、策略模式、模板方法模式、访问者模式等。
选择合适的设计模式需要了解项目的需求和上下文。对于不同的设计问题,某些模式可能比其他模式更合适。例如,如果需要控制对象的创建,单例模式可能是一个很好的选择。如果需要在不同的类之间共享接口,适配器模式可能更加合适。理解这些模式之间的差异和适用场景对于做出正确的设计决策至关重要。
## 2.3 理论到实践的桥梁
### 2.3.1 设计模式在算法中的应用
设计模式不仅仅在软件架构层面有用,它们同样可以被应用到算法设计中。通过理解模式提供的抽象和解决方案,开发者可以将这些模式融入到算法的设计和实现中。
例如,当我们设计一个搜索算法时,我们可以利用策略模式来允许算法在运行时选择不同的搜索策略。另外,如果需要根据不同的数据类型动态地调整数据结构,工厂模式可以帮助我们创建适当的对象。
下面是一个使用工厂模式来创建不同搜索算法的简单示例:
```python
class SearchAlgorithm:
def search(self, data):
raise NotImplementedError
class LinearSearch(SearchAlgorithm):
def search(self, data):
return 'Linear search result'
class BinarySearch(SearchAlgorithm):
def search(self, data):
return 'Binary search result'
class AlgorithmFactory:
@staticmethod
def get_algorithm(name):
if name == 'linear':
return LinearSearch()
elif name == 'binary':
return BinarySearch()
else:
raise ValueError('Algorithm not supported')
# 使用工厂模式创建算法实例
algorithm = AlgorithmFactory.get_algorithm('linear')
result = algorithm.search('some_data')
print(result)
```
在此示例中,`AlgorithmFactory` 类根据提供的名称参数返回不同的搜索算法实例。这样,算法的具体实现细节被隐藏在工厂背后,允许客户端代码简单地调用搜索方法而不必关心实际的算法。
### 2.3.2 设计模式与算法性能优化
设计模式不仅有助于提高代码的可读性和可维护性,还可以用来优化算法的性能。通过合理使用设计模式,可以减少不必要的计算,减少资源消耗,并提高代码的执行效率。
在某些情况下,设计模式可以帮助我们更有效地利用缓存,或者通过减少对象创建的次数来降低性能开销。例如,使用享元模式可以减少创建大量相似对象的需要,因为它们可以共享相同的数据或状态。
再比如,代理模式可以用来控制对资源的访问,从而避免不必要的操作,减少数据库查询次数,或者限制资源的使用。以下是一个使用代理模式来减少数据库查询次数的示例:
```python
class Database:
def fetch_data(self):
print("Database fetching data.")
return "data"
class ProxyDatabase:
def __init__(self):
self._db = Database()
self._cached_data = None
def fetch_data(self):
if self._cached_data is None:
print("Proxy fetching data from database.")
self._cached_data = self._db.fetch_data()
return self._cached_data
# 创建代理对象
proxy_db = ProxyDatabase()
# 第一次调用会实际从数据库获取数据
print(proxy_db.fetch_data())
# 第二次调用将直接返回缓存的数据
print(proxy_db.fetch_data())
```
在此示例中,`ProxyDatabase` 类作为 `Database` 的代理,只有在缓存为空时才会从数据库中获取数据。如果数据已经被缓存,则直接返回缓存的数据,从而避免了重复的数据库访问。
通过这些方式,设计模式可以成为提升算法性能的重要工具。正确地使用设计模式可以帮助我们编写更加高效和优化的代码。
# 3. Python实战设计模式
## 3.1 创建型模式
创建型模式主要处理对象的创建问题,它们将对象的创建与使用分离,以提高代码的模块性和可维护性。在Python中,创建型模式尤其有用,因为Python的动态特性和简洁语法允许我们以更灵活的方式实现这些设计模式。
### 3.1.1 单例模式
单例模式是一种常见的创建型模式,它确保一个类只有一个实例,并提供一个全局访问点。在Python中实现单例模式可以通过多种方式,包括使用模块级别的变量、继承`__new__()`方法,或者利用元类(metaclass)。
下面是一个通过继承`__new__()`方法实现单例模式的例子:
```python
class Singleton:
_instance = None
def __new__(cls, *args, **kwargs):
if not cls._instance:
cls._instance = super(Singleton, cls).__new__(cls, *args, **kwargs)
return cls._instance
# 私有化构造函数以防止外部通过init方法创建对象
def __init__(self):
raise RuntimeError('Call instance method instead')
@classmethod
def instance(cls):
return cls._instance
# 使用单例类创建实例
singleton1 = Singleton()
singleton2 = Singleton()
print(singleton1) # 输出: <__main__.Singleton object at 0x7f4c43c5c4e0>
print(singleton2) # 输出: <__main__.Singleton object at 0x7f4c43c5c4e0>
# 验证两个实例是否相同
print(singleton1 is singleton2) # 输出: True
```
### 3.1.2 工厂方法和抽象工厂
工厂方法模式通过定义一个用于创建对象的接口,但让子类决定实例化哪一个类。抽象工厂模式则提供了一个接口用于创建相关或依赖对象的家族,而不需要明确指定具体类。
工厂方法模式的实现相对简单。在Python中,我们可以定义一个基类,该基类定义了一个方法,用于创建对象。然后,不同的子类可以实现这个方法,以创建具体的对象。
```python
class Product:
def operation(self):
pass
class ConcreteProductA(Product):
def operation(self):
return "ConcreteProductA"
class ConcreteProductB(Product):
def operation(self):
return "ConcreteProductB"
class Creator:
def factory_method(self):
raise NotImplementedError
def operation(self):
product = self.factory_method()
return f"Creator: The same creator's code works with {product.operation()}"
class ConcreteCreatorA(Creator):
def factory_method(self):
return ConcreteProductA()
class ConcreteCreatorB(Creator):
def factory_method(self):
return ConcreteProductB()
# 使用工厂方法
creator_a = ConcreteCreatorA()
print(creator_a.operation()) # 输出: Creator: The same creator's code works with ConcreteProductA
creator_b = ConcreteCreatorB()
print(creator_b.operation()) # 输出: Creator: The same creator's code works with ConcreteProductB
```
### 3.1.3 建造者模式
建造者模式(Builder pattern)是一种创建型设计模式,它将一个复杂对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示。它主要适用于创建那些结构复杂的对象,而且用户不需要知道内部的具体构造细节。
建造者模式通常包含以下几个角色:
- **产品(Product)**:最终要创建的复杂对象。
- **建造者(Builder)**:定义创建产品对象的接口,一般由一系列方法构成,每个方法对应产品的一个组成部分。
- **具体建造者(Concrete Builder)**:实现Builder接口,构造和装配各个部件。
- **指挥者(Director)**:负责安排已有模块的顺序,然后告诉Builder开始建造。
- **客户端(Client)**:创建Director对象,并用它来安排建造过程。
```python
class Product:
pass
class Builder:
def __init__(self):
self.product = Product()
def build_part_a(self):
pass
def build_part_b(self):
pass
def get_result(self):
return self.product
class ConcreteBuilder(Builder):
def build_part_a(self):
# 构建产品的一部分
pass
def build_part_b(self):
# 构建产品的一部分
pass
class Director:
def __init__(self, builder):
self.builder = builder
def construct(self):
self.builder.build_part_a()
self.builder.build_part_b()
return self.builder.get_result()
# 使用建造者模式
builder = ConcreteBuilder()
director = Director(builder)
product = director.construct()
```
## 3.2 结构型模式
结构型模式涉及到如何组合类和对象以获得更大的结构。Python中的结构型模式包括适配器模式、装饰器模式、代理模式等。
### 3.2.1 适配器模式
适配器模式允许将一个类的接口转换成客户期望的另一个接口,使得原本由于接口不兼容而不能一起工作的那些类可以一起工作。
适配器模式主要包含以下角色:
- **目标(Target)**:定义客户所期待的接口,可以是一个抽象类或接口。
- **待适配的类(Adaptee)**:定义一个已经存在的接口,这个接口需要适配。
- **适配器(Adapter)**:对Adaptee的接口与Target接口进行适配。
下面是一个使用类适配器模式的例子:
```python
class Target:
def request(self):
pass
class Adaptee:
def specific_request(self):
pass
# 类适配器
class Adapter(Target, Adaptee):
def request(self):
return self.specific_request()
# 使用适配器
adapter = Adapter()
adapter.request() # 返回Adaptee的specific_request方法的结果
```
### 3.2.2 装饰器模式
装饰器模式允许向一个现有的对象添加新的功能,同时又不改变其结构。装饰器模式提供了一个透明的包装类,使得可以给单个对象添加更多的责任。
装饰器模式主要包含以下角色:
- **组件(Component)**:定义一个对象接口,可以给这些对象动态地添加职责。
- **具体组件(Concrete Component)**:定义了一个具体的对象,也可以给这个对象添加一些职责。
- **装饰器(Decorator)**:维持一个指向组件对象的指针,并定义一个与组件接口一致的接口。
- **具体装饰器(Concrete Decorator)**:向组件添加职责。
下面是一个使用装饰器模式的例子:
```python
class Component:
def operation(self):
pass
class ConcreteComponent(Component):
def operation(self):
return "ConcreteComponent operation"
class Decorator(Component):
def __init__(self, component):
***ponent = component
def operation(self):
***ponent.operation()
class ConcreteDecoratorA(Decorator):
def operation(self):
return f"ConcreteDecoratorA({***ponent.operation()})"
class ConcreteDecoratorB(Decorator):
def operation(self):
return f"ConcreteDecoratorB({***ponent.operation()})"
# 使用装饰器模式
component = ConcreteComponent()
decorated_a = ConcreteDecoratorA(component)
decorated_b = ConcreteDecoratorB(decorated_a)
print(decorated_b.operation()) # 输出: ConcreteDecoratorB(ConcreteDecoratorA(ConcreteComponent operation))
```
### 3.2.3 代理模式
代理模式为其他对象提供一种代理以控制对这个对象的访问。它适用于控制对具有特殊访问要求的对象的访问,或需要延迟初始化的对象。
代理模式主要包含以下角色:
- **主题(Subject)**:定义了代理和真实主题的共同接口,这样就可以在任何使用真实主题的地方使用代理主题。
- **真实主题(Real Subject)**:定义了代理所代表的真实对象。
- **代理(Proxy)**:包含对真实主题的引用,同时也实现了Subject接口。
```python
class Subject:
def request(self):
pass
class RealSubject(Subject):
def request(self):
return "RealSubject request"
class Proxy(Subject):
def __init__(self):
self._real_subject = RealSubject()
def request(self):
return f"Proxy: Calling RealSubject's request with {self._real_subject.request()}"
# 使用代理模式
subject = Proxy()
print(subject.request()) # 输出: Proxy: Calling RealSubject's request with RealSubject request
```
## 3.3 行为型模式
行为型模式关注对象间的通信,Python中的行为型模式包括观察者模式、策略模式、命令模式等。
### 3.3.1 观察者模式
观察者模式定义了对象之间的一对多依赖关系,当一个对象改变状态时,所有依赖者都会收到通知,并自动更新。
观察者模式主要包含以下角色:
- **主题(Subject)**:定义了注册、移除和通知观察者的方法。
- **观察者(Observer)**:提供更新的接口。
- **具体主题(Concrete Subject)**:维护观察者列表,并在状态改变时,通知所有观察者。
- **具体观察者(Concrete Observer)**:实现更新接口以完成具体的更新工作。
```python
class Subject:
def __init__(self):
self._observers = []
def attach(self, observer):
self._observers.append(observer)
def detach(self, observer):
self._observers.remove(observer)
def notify(self):
for observer in self._observers:
observer.update()
class Observer:
def update(self):
pass
class ConcreteObserver(Observer):
def update(self):
print("ConcreteObserver update")
# 使用观察者模式
subject = Subject()
observer1 = ConcreteObserver()
observer2 = ConcreteObserver()
subject.attach(observer1)
subject.attach(observer2)
subject.notify() # 输出: ConcreteObserver update ConcreteObserver update
subject.detach(observer1)
subject.notify() # 输出: ConcreteObserver update
```
### 3.3.2 策略模式
策略模式定义了一系列算法,并将每一个算法封装起来,使它们可以互相替换,且算法的变化不会影响到使用算法的客户。
策略模式主要包含以下角色:
- **上下文(Context)**:使用算法的接口。
- **策略(Strategy)**:定义所有支持的算法的公共接口。上下文使用这个接口来调用具体策略定义的算法。
- **具体策略(Concrete Strategies)**:实现了策略定义的算法。
```python
class Strategy:
def execute(self, data):
pass
class ConcreteStrategyA(Strategy):
def execute(self, data):
return data
class ConcreteStrategyB(Strategy):
def execute(self, data):
return f"ConcreteStrategyB({data})"
class Context:
def __init__(self, strategy):
self._strategy = strategy
def execute_strategy(self, data):
return self._strategy.execute(data)
# 使用策略模式
context = Context(ConcreteStrategyA())
print(context.execute_strategy("Strategy A applied")) # 输出: Strategy A applied
context = Context(ConcreteStrategyB())
print(context.execute_strategy("Strategy B applied")) # 输出: ConcreteStrategyB(Strategy B applied)
```
### 3.3.3 命令模式
命令模式将请求封装为具有统一接口的对象,这样就可以使用不同的请求对客户进行参数化。它支持可撤销的操作。
命令模式主要包含以下角色:
- **调用者(Invoker)**:请求发送者,它通过命令对象来执行请求。
- **命令(Command)**:定义一个执行操作的接口。
- **具体命令(Concrete Command)**:将一个接收者对象绑定于一个动作;调用接收者相应的操作,以实现Execute。
- **接收者(Receiver)**:知道如何实施与执行一个请求相关的操作。
```python
class Command:
def execute(self):
pass
class ConcreteCommand(Command):
def __init__(self, receiver):
self._receiver = receiver
def execute(self):
return self._receiver.action()
class Receiver:
def action(self):
return "Receiver action"
class Invoker:
def __init__(self):
self._command = None
def set_command(self, command):
self._command = command
def execute_command(self):
return self._command.execute()
# 使用命令模式
receiver = Receiver()
command = ConcreteCommand(receiver)
invoker = Invoker()
invoker.set_command(command)
print(invoker.execute_command()) # 输出: Receiver action
```
以上就是Python实战设计模式的详细内容。每个设计模式在Python中的实现都展示了不同的结构和用法,这些模式不仅能够帮助我们更好地组织和管理代码,还能够提高代码的可维护性和可扩展性。在实际开发过程中,我们可以根据具体需求选择合适的设计模式,以达到代码优化和业务需求的目的。
# 4. 深入算法与源码分析
## 4.1 算法背后的Python源码
### 4.1.1 Python内置数据结构的源码分析
Python的内置数据结构如列表(list)、字典(dict)、集合(set)等是构建更复杂算法和数据处理应用的基础。了解这些数据结构的源码实现有助于我们更好地利用这些结构,甚至可以在此基础上开发出更加高级的自定义数据结构。
以列表为例,列表在Python中是通过动态数组的方式实现的。列表对象实际上是一个封装了数组操作的容器类,这些操作包括添加、删除、访问元素等。列表的底层使用`_PyListObject`结构体实现,其中包含了指向数组的指针以及数组的当前长度等信息。
下面是一个简化的Python列表结构体示例代码:
```c
typedef struct {
PyObject **ob_item;
Py_ssize_t allocated;
} PyListObject;
```
这里,`ob_item`是一个指向指针数组的指针,每个指针指向列表中的一个元素。`allocated`表示当前分配的数组大小,这允许列表在元素数量增加时动态地重新分配内存。
**代码逻辑解读:**
- `ob_item`用于动态地引用元素的地址。
- `allocated`字段表明内部数组目前能够存储多少元素,通过这个值可以判断是否需要扩容。
通过观察`list`对象的创建过程,我们可以看到一个Python对象的创建过程是如何进行的,包括内存分配、类型绑定等。源码分析也帮助我们理解了列表是如何高效实现快速索引访问的,以及在列表末尾添加元素时,为什么可以达到近似O(1)的时间复杂度。
### 4.1.2 标准库算法实现的源码探究
Python标准库提供了一系列实用的算法实现,例如排序、搜索等。通过研究这些算法的源码,我们可以学习到优秀算法设计的精髓,并且可以在此基础上进一步优化和定制算法。
Python内置的排序算法在Python 3中是Timsort,这是一种结合了归并排序和插入排序的混合排序算法。Timsort根据数据的实际排列情况,动态地选择最合适的排序方法,对于部分有序的数据集具有很好的性能。
Timsort的源码实现较为复杂,但其核心部分是对输入数据进行“归并操作”。归并操作是一种将两个或多个有序序列合并成一个有序序列的算法。
```python
def merge(left, right):
result = []
i = j = 0
while i < len(left) and j < len(right):
if left[i] <= right[j]:
result.append(left[i])
i += 1
else:
result.append(right[j])
j += 1
result.extend(left[i:])
result.extend(right[j:])
return result
```
**代码逻辑解读:**
- `merge`函数通过创建一个空结果列表`result`,用于存放归并后的元素。
- 使用两个指针`i`和`j`分别跟踪`left`和`right`两个列表的元素位置。
- 在归并过程中,选择`left`和`right`列表中较小的元素放入`result`中,直到一个列表的所有元素都处理完毕。
- 将剩余未处理的元素直接追加到`result`的末尾。
这个过程保证了`result`列表是有序的,因为每次只从两个列表中取出最小的元素加入到`result`中。对于Python的Timsort来说,通过寻找输入列表中的有序序列(称为“runs”),并采用类似分治法的策略来完成排序。
通过分析标准库中的算法实现,我们可以发现许多优化算法性能的技巧和方法。这些技巧和方法是算法设计和实现中不可多得的财富,而源码就是它们最直接的体现。
## 4.2 高级算法的实战技巧
### 4.2.1 动态规划和分治法在实际中的应用
动态规划(Dynamic Programming,DP)是一种解决多阶段决策问题的方法。它将复杂的问题分解为简单子问题,并存储子问题的解,避免了重复计算。分治法(Divide and Conquer)是另一种算法设计策略,它将大问题分解成小问题来解决,通常是将问题分成两个或多个子问题,并递归地解决它们。
在实际应用中,动态规划和分治法常用于优化递归算法,减少计算复杂度。例如,Fibonacci数列可以通过递归简单实现,但其时间复杂度是指数级的。采用动态规划后,可以通过将已经计算出的Fibonacci数存储在数组中,以O(n)的时间复杂度计算第n个Fibonacci数。
```python
def fibonacci(n):
if n <= 1:
return n
fibs = [0, 1] + [0] * (n-1)
for i in range(2, n+1):
fibs[i] = fibs[i-1] + fibs[i-2]
return fibs[n]
```
**代码逻辑解读:**
- 定义了一个`fibs`数组用于存储从0到n的Fibonacci数列。
- 初始化`fibs`数组的前两个值为0和1,因为Fibonacci数列的前两个数是0和1。
- 使用for循环迭代计算从第三个数开始的Fibonacci数,并将其存入`fibs`数组。
- 最后返回第n个Fibonacci数。
通过使用动态规划和分治法,我们可以高效地解决许多复杂问题,如最短路径、背包问题等。在实际项目中合理应用这些策略,不仅可以优化算法性能,还可以提高程序的可读性和可维护性。
## 4.3 源码中的设计模式
### 4.3.1 设计模式在Python标准库的应用
Python标准库中广泛使用了设计模式。例如,在`itertools`模块中,我们可以发现迭代器模式的应用。迭代器模式提供了一种方法,使得可以通过连续调用`next()`方法来逐个访问容器中的元素,而不必暴露容器的内部表示。
例如,`itertools.count`返回一个无限的迭代器,它按顺序生成自然数。迭代器模式允许无限序列的实现,同时隐藏了序列的内部状态。
```python
import itertools
counter = itertools.count(1)
for _ in range(5):
print(next(counter)) # 输出1到5
```
**代码逻辑解读:**
- 导入`itertools`模块。
- 使用`itertools.count`创建一个从1开始的无限计数器。
- 通过for循环和`next()`函数,逐个打印出计数器的值。
在`logging`模块中,装饰器模式用来动态地为对象添加日志记录功能,通过`logging`模块提供的装饰器,可以很容易地为函数或方法添加日志记录功能,而无需修改原有函数代码。
```python
import logging
def log(func):
def wrapper(*args, **kwargs):
logging.basicConfig(level=***)
***(f"Running {func.__name__}")
return func(*args, **kwargs)
return wrapper
@log
def run():
print("Running")
run()
```
**代码逻辑解读:**
- 定义了一个`log`装饰器函数`wrapper`,用于包装目标函数。
- 在`wrapper`函数中,使用`logging`模块记录被调用函数的名称。
- 在函数调用前,使用`logging.basicConfig`设置日志级别和格式。
- 使用`@log`装饰器修饰`run`函数,调用`run`函数时会先记录日志信息。
通过分析Python标准库中设计模式的应用,我们可以发现设计模式不仅在理论上有指导意义,在实际应用中同样能够极大地提升代码的质量和开发效率。了解这些模式的应用,对于提升自身的设计能力有着重要意义。
### 4.3.2 设计模式在开源项目中的应用实例
在开源项目中,设计模式的应用案例比比皆是,它们帮助维护和扩展代码库,并且使代码更加灵活和易于理解。一个经典的例子是在Django Web框架中广泛使用的设计模式。
Django在其ORM(对象关系映射)层广泛使用了工厂方法模式。工厂方法模式提供了一种创建对象的最佳方式,工厂方法模式让创建对象和使用对象分离,通过工厂方法创建对象可以让子类决定实例化哪一个类。
```python
class Article(models.Model):
title = models.CharField(max_length=100)
content = models.TextField()
# other fields...
class ArticleFactory:
def create_article(self, title, content):
return Article.objects.create(title=title, content=content)
factory = ArticleFactory()
article = factory.create_article('My new article', 'Content of article...')
```
**代码逻辑解读:**
- 定义了一个`Article`模型类,它是一个Django模型,用于映射到数据库中的一个表。
- 创建了一个`ArticleFactory`类,其中包含一个`create_article`方法,用于创建`Article`类的实例。
- 实例化`ArticleFactory`并调用`create_article`方法创建一个新的文章对象。
在Django框架中,工厂模式的使用有助于减轻开发者的负担,他们不必每次都直接操作模型来创建对象,同时也使得代码更加模块化,便于单元测试和扩展。
另一个例子是在Flask微框架中,装饰器模式的应用非常广泛。Flask使用装饰器来装饰视图函数,使得视图函数能够处理Web请求并返回响应。
```python
from flask import Flask
app = Flask(__name__)
@app.route('/')
def hello_world():
return 'Hello, World!'
if __name__ == '__main__':
app.run()
```
**代码逻辑解读:**
- 导入Flask类并创建Flask应用实例。
- 使用`@app.route`装饰器指定视图函数处理的URL模式。
- 定义了一个`hello_world`视图函数,用于处理到达根URL的请求并返回响应。
- 在脚本被直接运行时,启动Flask应用。
Flask中的装饰器模式不仅简化了路由的处理,而且使得Web应用的扩展和维护变得更加简单。了解和分析这些开源项目中设计模式的应用,能够帮助我们深刻理解设计模式的实用价值。
通过本章节的介绍,我们深入探究了Python源码中算法和设计模式的应用。在下一章中,我们将讨论如何利用设计模式来重构代码,提高其可维护性和性能。
# 5. 设计模式与代码重构
## 5.1 重构的原则与技巧
### 5.1.1 代码重构的基本原则
代码重构是改善现有代码结构而不影响其外部行为的过程。其目的是提高可读性、简化设计、降低复杂度,以及增加系统的可维护性。重构的基本原则包括:
- **小步快跑**:每次重构只做小的修改,频繁地进行提交,这样可以减少错误的风险,并简化问题定位。
- **保持代码简洁**:移除不必要的复杂性,使代码更加易于理解。
- **测试驱动**:在进行重构之前,确保有充分的测试覆盖。重构后立即运行测试,以确保修改未破坏任何现有功能。
- **解耦**:减少模块之间的依赖,使系统的各部分可以独立开发和测试。
- **单一职责**:确保每个类或方法都有一个明确的职责,避免“大泥球”类的产生。
### 5.1.2 代码重构的常用方法
重构方法涵盖了从变量、方法到类和模块的各级别。以下是一些常见的重构技术:
- **提取方法**:将一段代码封装到一个新的方法中,并给予它一个清晰的名称。
- **合并方法**:如果两个方法的功能非常相似,可以考虑将它们合并。
- **引入参数对象**:当多个方法需要相同的参数时,可以创建一个新的类或结构体来封装这些参数。
- **使用多态**:在对象的行为依赖于其类型时,使用继承和多态可以减少条件判断语句。
- **内联方法**:如果一个方法只是简单地调用另一个方法,可以直接将方法内联。
## 5.2 设计模式在重构中的作用
### 5.2.1 利用设计模式简化代码结构
设计模式提供了经过验证的解决方案来处理软件设计中的常见问题。在重构过程中,它们可以帮助简化代码结构:
- **单例模式**:确保类只有一个实例,并提供全局访问点。这对于减少全局状态非常有用。
- **工厂模式**:创建对象而不暴露创建逻辑到客户端,并且通过使用接口来指向创建的对象类型。
- **观察者模式**:定义对象间的一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都会得到通知并自动更新。
### 5.2.2 设计模式在提高代码可维护性中的应用
维护性是软件质量的关键指标。设计模式可以帮助我们:
- **降低耦合度**:通过依赖注入、工厂模式等手段减少类之间的耦合。
- **易于扩展**:遵循开闭原则,使系统易于扩展而无需修改现有代码。
- **提供清晰的接口**:使用适配器模式、策略模式等提供统一的接口给客户端。
## 5.3 实战:重构一个Python项目
### 5.3.1 识别代码中的问题
在实际项目中识别代码的问题是重构的第一步。问题可能包括但不限于:
- **重复代码**:同一个逻辑出现在了不同的地方。
- **过长的方法或函数**:方法内部执行了多个任务,难以理解和测试。
- **过度耦合**:类或模块间存在不必要的紧密联系。
- **缺乏抽象**:重要的概念没有在代码中得到清晰的体现。
### 5.3.2 应用设计模式进行重构
为了重构代码,我们可以:
- **使用工厂模式替代直接实例化对象**,当创建逻辑比较复杂或需要延迟初始化时。
- **使用策略模式重构条件判断**,尤其是当有多个条件分支需要处理类似问题时。
- **使用观察者模式替换事件广播的轮询逻辑**,以降低耦合度。
### 5.3.3 重构后的性能与可维护性对比
重构完成后,对系统的性能和可维护性进行对比分析:
- **性能评估**:包括时间复杂度和空间复杂度的测量。
- **可维护性评估**:通过团队成员的反馈,代码审查和错误率的减少等方面进行评估。
- **长期效益**:良好的重构能够带来长期的维护成本下降和技术债务的减少。
在重构的实际操作中,一定要注意以下几点:
1. **持续集成**:在重构过程中,应该持续集成测试,确保重构没有破坏现有功能。
2. **代码审查**:在重构后,通过代码审查来获取其他人的反馈。
3. **文档更新**:重构后更新相关文档,确保团队其他成员可以理解新的代码结构。
4. **逐步迭代**:重构不是一蹴而就的工作,需要分步进行,逐步提升代码质量。
以上就是第五章《设计模式与代码重构》的主要内容。通过掌握这些知识,可以帮助我们更好地理解如何在实际项目中应用设计模式,进行有效的代码重构,提高代码质量和可维护性。
# 6. 提升算法设计的综合案例
## 6.1 算法设计模式的综合应用
在实际开发中,算法设计模式并非孤立存在,它们常常需要协同工作,以解决更为复杂的问题。分步解决策略是指将复杂问题分解成一系列小问题,然后逐一解决,这与设计模式的应用是相辅相成的。
### 6.1.1 复杂问题的分步解决策略
复杂问题的解决往往需要我们首先将问题分解,然后在各个子问题上应用合适的算法和设计模式。例如,当我们面对一个需要快速检索和更新数据的场景时,我们可以采用组合模式与哈希表结合的方式。
以一个在线零售网站为例,我们需要根据不同的分类和条件对商品进行快速检索。这里就可以使用组合模式来表示商品的层级结构,同时通过哈希表来快速定位各个分类。
```python
class Product:
def __init__(self, name, category):
self.name = name
self.category = category
class Category:
def __init__(self, name):
self.name = name
self.children = []
self.products = []
def add(self, product):
self.products.append(product)
def add_category(self, category):
self.children.append(category)
def get_all_products(self):
result = []
result.extend(self.products)
for child in self.children:
result.extend(child.get_all_products())
return result
# 创建类别结构
home_appliances = Category('Home Appliances')
small_appliances = Category('Small Appliances')
heating = Category('Heating')
# 添加产品到类别中
electric_kettle = Product('Electric Kettle', small_appliances.name)
heating_pad = Product('Heating Pad', heating.name)
small_appliances.add(electric_kettle)
heating.add(heating_pad)
# 构建完整的类别树
home_appliances.add(small_appliances)
home_appliances.add(heating)
# 检索所有商品
all_products = home_appliances.get_all_products()
print([product.name for product in all_products])
```
### 6.1.2 设计模式在解决复杂算法问题中的综合应用
在实际应用中,我们会遇到各种复杂的问题,这时就需要根据问题的具体情况选择合适的设计模式,甚至需要组合多个设计模式。
例如,在一个社交网络应用中,用户可以发布消息,这些消息可以是普通文本,也可以是图片或者视频。我们可以使用策略模式来处理不同类型的消息发布,同时使用观察者模式来通知关注者新的消息发布。
```python
from abc import ABC, abstractmethod
class MessageStrategy(ABC):
@abstractmethod
def send_message(self, message):
pass
class TextMessageStrategy(MessageStrategy):
def send_message(self, message):
print(f"Sending text message: {message}")
class MultimediaMessageStrategy(MessageStrategy):
def send_message(self, message):
print(f"Sending multimedia message with content: {message}")
class MessagePublisher:
def __init__(self):
self.strategy = None
self.subscribers = []
def set_strategy(self, strategy):
self.strategy = strategy
def add_subscriber(self, subscriber):
self.subscribers.append(subscriber)
def publish_message(self, message):
self.strategy.send_message(message)
for subscriber in self.subscribers:
subscriber.notify(message)
class Subscriber:
def notify(self, message):
pass
# 具体策略和订阅者的实现省略
# 使用示例
publisher = MessagePublisher()
publisher.set_strategy(TextMessageStrategy())
publisher.add_subscriber(Subscriber())
publisher.publish_message("Hello, world!")
```
## 6.2 实战案例分析
在真实项目中,算法设计模式的应用需要结合具体的业务场景进行。以下将分析一个实际项目中的案例,以及如何对项目中的算法进行分析与优化。
### 6.2.1 实际项目中的算法设计模式应用
假设我们正在处理一个股票交易系统,该系统需要实时处理大量的交易订单,并且要求高性能和高可用性。
在这个系统中,我们可以使用工厂模式来创建不同类型的交易订单对象,使用代理模式来控制对交易系统的访问,确保系统的安全性。同时,可以使用单例模式来保证交易引擎的唯一性。
### 6.2.2 分析与优化现有项目中的算法
对于已有的项目,我们可能需要对其进行性能分析,找出瓶颈所在,并应用合适的设计模式进行优化。比如,如果发现数据查询性能不佳,我们可以考虑使用缓存机制,使用策略模式根据不同的查询条件选择不同的缓存策略。
```python
class CacheStrategy(ABC):
@abstractmethod
def fetch(self, query):
pass
class NoCacheStrategy(CacheStrategy):
def fetch(self, query):
# 直接从数据库查询数据
return self.query_database(query)
class MemoryCacheStrategy(CacheStrategy):
def fetch(self, query):
# 首先尝试从内存中获取数据
data = self.get_from_memory_cache(query)
if data:
return data
# 如果内存中没有,从数据库获取,并更新到内存中
data = self.query_database(query)
self.update_memory_cache(query, data)
return data
def query_database(query):
# 模拟数据库查询
print(f"Querying database for '{query}'")
return "data for " + query
def get_from_memory_cache(query):
# 模拟从内存缓存中获取数据
pass
def update_memory_cache(query, data):
# 模拟更新内存缓存
pass
# 使用示例
cache_strategy = MemoryCacheStrategy()
data = cache_strategy.fetch("stock prices")
```
## 6.3 设计模式与技术创新
设计模式不仅在解决传统问题上发挥作用,在推动技术创新方面同样具有重要意义。随着新技术的不断涌现,设计模式可以帮助我们更好地理解和应用这些技术。
### 6.3.1 如何在技术创新中运用设计模式
在微服务架构中,容器化和编排技术(如Kubernetes)使得服务的部署和管理变得更加灵活。我们可以运用代理模式来管理服务之间的通信,使用单例模式来保证某些关键服务的全局唯一性。
### 6.3.2 设计模式在未来技术趋势中的潜在角色
随着AI和机器学习技术的发展,设计模式也会在这些领域发挥重要作用。例如,在AI模型训练过程中,可以利用建造者模式来构建不同的模型架构,在模型部署时,策略模式可以用来选择最优的服务部署策略。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入剖析 Python 数据结构和算法的源码,为读者提供全面的理解和应用指南。涵盖核心数据结构(链表、堆、队列、树、图)和算法(排序、搜索、动态规划、回溯、启发式),从源码解析到实际应用,循序渐进地提升读者的编程技能。通过案例驱动、源码解读和性能优化技巧,读者将掌握算法设计模式,优化算法性能,解决 LeetCode 算法难题,并深入理解数据结构的内部机制。本专栏旨在为 Python 开发者提供全面的数据结构和算法知识,提升他们的编程能力和解决复杂问题的效率。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
PCM测试进阶必读:深度剖析写入放大和功耗分析的实战策略
# 摘要
相变存储(PCM)技术作为一种前沿的非易失性存储解决方案,近年来受到广泛关注。本文全面概述了PCM存储技术,并深入分析了其写入放大现象,探讨了影响写入放大的关键因素以及对应的优化策略。此外,文章着重研究了PCM的功耗特性,提出了多种节能技术,并通过实际案例分析评估了这些技术的有效性。在综合测试方法方面,本文提出了系统的测试框架和策略,并针对测试结果给出了优化建议。最后,文章通过进阶案例研究,探索了PCM在特定应用场景中的表现,并探讨了
网络负载均衡与压力测试全解:NetIQ Chariot 5.4应用专家指南
# 摘要
本文详细介绍了网络负载均衡的基础知识和NetIQ Chariot 5.4的部署与配置方法。通过对NetIQ Chariot工具的安装、初始化设置、测试场景构建、执行监控以及结果分析的深入讨论,展示了如何有效地进行性能和压力测试。此外,本文还探讨了网络负载均衡的高级应用,包括不同负载均衡策略、多协议支持下的性能测试,以及网络优化与故障排除技巧。通过案例分析,本文为网络管理员和技术人员提供了一套完整的网络性能提升和问
ETA6884移动电源效率大揭秘:充电与放电速率的效率分析

# 摘要
移动电源作为便携式电子设备的能源,其效率对用户体验至关重要。本文系统地概述了移动电源效率的概念,并分析了充电与放电速率的理论基础。通过对理论影响因素的深入探讨以及测量技术的介绍,本文进一步评估了ETA6884移动电源在实际应用中的效率表现,并基于案例研究提出了优化充电技术和改
深入浅出:收音机测试进阶指南与优化实战

# 摘要
本论文详细探讨了收音机测试的基础知识、进阶理论与实践,以及自动化测试流程和工具的应用。文章首先介绍了收音机的工作原理和测试指标,然后深入分析了手动测试与自动测试的差异、测试设备的使用和数据分析方法。在进阶应用部分,文中探讨了频率和信号测试、音质评价以及收音机功能测试的标准和方法。通过案例分析,本文还讨论了测试中常见的问题、解决策略以及自动化测试的优势和实施。最后,文章展望了收音机测试技术的未来发展趋势,包括新技术的应用和智能化测试的前
微波毫米波集成电路制造与封装:揭秘先进工艺
# 摘要
本文综述了微波毫米波集成电路的基础知识、先进制造技术和封装技术。首先介绍了微波毫米波集成电路的基本概念和制造技术的理论基础,然后详细分析了各种先进制造工艺及其在质量控制中的作用。接着,本文探讨了集成电路封装技术的创新应用和测试评估方法。在应用案例分析章节,本文讨论了微波毫米波集成电路在通信、感测与成像系统中的应用,并展望了物联网和人工智能对集成电路设计的新要求。最后,文章对行业的未来展望进
Z变换新手入门指南:第三版习题与应用技巧大揭秘

# 摘要
Z变换是数字信号处理中的核心工具,它将离散时间信号从时域转换到复频域,为分析和设计线性时不变系统提供强有力的数学手段。本文首先介绍了Z变换的基
Passthru函数的高级用法:PHP与Linux系统直接交互指南

# 摘要
本文详细探讨了PHP中Passthru函数的使用场景、工作原理及其进阶应用技巧。首先介绍了Passthru函数的基本概念和在基础交
【Sentaurus仿真调优秘籍】:参数优化的6个关键步骤

# 摘要
本文系统地探讨了Sentaurus仿真技术的基础知识、参数优化的理论基础以及实际操作技巧。首先介绍了Sentaurus仿真参数设置的基础,随后分析了优化过程中涉及的目标、原则、搜索算法、模型简化
【技术文档编写艺术】:提升技术信息传达效率的12个秘诀

# 摘要
本文旨在探讨技术文档编写的全过程,从重要性与目的出发,深入到结构设计、内容撰写技巧,以及用户测试与反馈的循环。文章强调,一个结构合理、内容丰富、易于理解的技术文档对于产品的成功至关重要。通过合理设计文档框架,逻辑性布局内容,以及应用视觉辅助元素,可以显著提升文档的可读性和可用性。此外,撰写技术文档时的语言准确性、规范化流程和读者意识的培养也是不可或缺的要
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )