【R语言数据重塑终极指南】:掌握reshape2包的7种高效技巧
发布时间: 2024-11-02 21:40:20 阅读量: 75 订阅数: 38 

R语言数据重塑,20种高效函数操作数据格式与管理
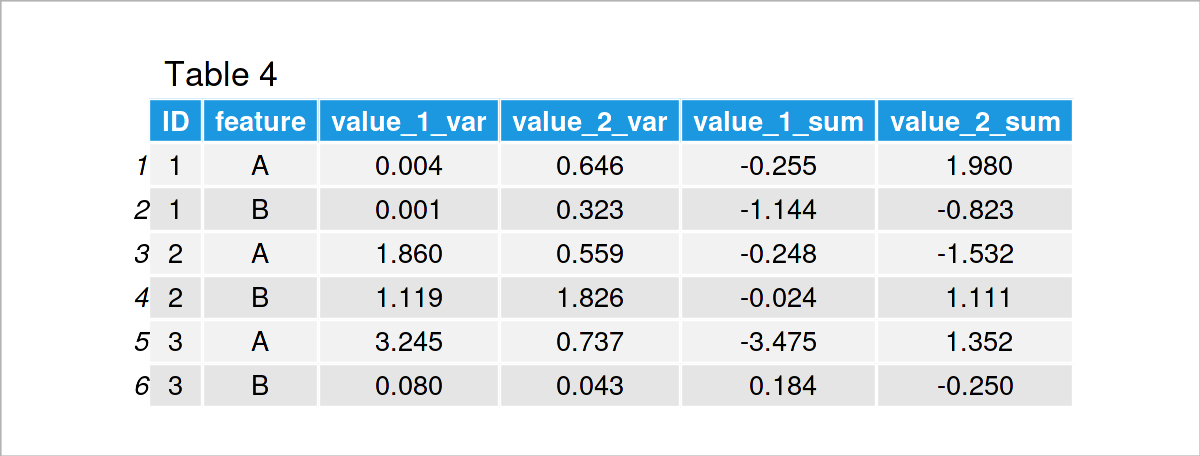
# 1. 数据重塑的概念和重要性
数据重塑是数据处理过程中的一个重要环节,涉及将数据从一种结构转换为另一种结构,以满足不同的分析或展示需求。随着数据量的增长和复杂性的提升,数据重塑的重要性愈发凸显。它不仅能够提高数据处理的效率,而且在数据分析、机器学习、数据可视化等领域中发挥着关键作用。理解数据重塑的概念,掌握其方法和技巧,对于任何需要处理和分析数据的专业人士来说都至关重要。
在本章中,我们将探讨数据重塑的定义,它在数据科学工作流程中的位置,以及为什么我们需要对数据进行重塑。我们将介绍数据重塑的一些常见场景,以及在没有适当工具的情况下进行数据重塑的挑战。通过对数据重塑的初步了解,我们为深入学习后续章节中提到的reshape2包打下坚实的基础。
# 2. 理解reshape2包的基础
## 2.1 R语言的数据类型和结构
### 2.1.1 常见数据类型:向量、矩阵、列表和数据框
在R语言中,数据的基本结构包括向量(vector)、矩阵(matrix)、列表(list)和数据框(data frame)。这些数据结构构成了R语言处理数据的基础。
- **向量**是R语言中的一维数组,由相同类型的元素组成,可以是数值型、字符型或逻辑型等。
- **矩阵**是二维数组,所有元素的数据类型相同,可以看作是向量的扩展。
- **列表**可以包含多种类型的数据结构,可以认为是向量的泛化形式。
- **数据框**是R中最常用的数据结构,类似于数据库中的表格,每列可以是不同的数据类型。
数据框(DataFrame)在数据重塑过程中扮演着核心角色,因为它们可以容纳来自不同数据结构的数据,并且易于操作和分析。
### 2.1.2 理解数据框(DataFrame)的核心作用
数据框(DataFrame)是由多个等长的向量组成的二维结构,这些向量形成了数据框的列。数据框是R语言中最接近于传统意义上“表格”的数据结构,因此在数据处理和分析中尤为重要。
数据框的特点如下:
- 可以存储不同类型的数据。
- 每列有一个名称,方便引用。
- 提供了强大的数据操作功能,例如子集选择、数据合并等。
- 与R的其他函数和包兼容性良好,特别是在进行数据重塑、数据可视化和统计分析时。
数据框作为R中操作数据的基础单位,是进行数据探索、数据准备和预处理的关键环节。
## 2.2 reshape2包的基本功能和安装
### 2.2.1 安装reshape2包的步骤和验证
要安装reshape2包,可以使用以下R语言的包管理命令:
```R
install.packages("reshape2")
```
安装完成后,可以通过以下命令来加载reshape2包:
```R
library(reshape2)
```
安装和加载包之后,可以通过`help()`函数获取关于reshape2的帮助文档,确保包已经正确安装并且可用:
```R
help(package = "reshape2")
```
### 2.2.2 掌握melt()和dcast()函数的基本用法
`melt()`函数和`dcast()`函数是reshape2包中进行数据重塑的核心函数。`melt()`函数用于将数据框从宽格式转换为长格式,而`dcast()`函数则用于将长格式数据转换为宽格式。
- 使用`melt()`函数:
```R
long_data <- melt(data, id.vars, measure.vars, variable.name, value.name)
```
其中,`data`是要处理的数据框,`id.vars`是作为标识符的变量,`measure.vars`是要融化(melt)的变量,`variable.name`和`value.name`是长格式数据中变量名和值的列名。
- 使用`dcast()`函数:
```R
wide_data <- dcast(long_data, formula, fun.aggregate = ..., value.var = ...)
```
在这里,`long_data`是已经转换为长格式的数据,`formula`是一个公式,用于指定如何将数据转换为宽格式,`fun.aggregate`是应用于聚合的函数(如sum, mean等),`value.var`指定了需要被聚合的变量名。
`melt()`和`dcast()`函数的灵活使用是掌握reshape2包的关键,通过这两个函数,可以实现数据的不同维度转换,满足数据分析和可视化的需求。
## 2.3 从基础到进阶:reshape2的参数解读
### 2.3.1 探索melt()的参数设置
`melt()`函数在R中常用于将宽格式数据框转换为长格式,它具有多个参数以适应不同的数据处理需求:
- `id.vars`参数用于指定哪些列作为标识符变量,即在转换过程中保持不变的列。
- `measure.vars`参数用于指定需要被转换的变量,即那些将从宽格式的列转换为长格式的值的列。
- `variable.name`参数用于指定在结果中,由`measure.vars`参数指定的列名转换成的新列名。
- `value.name`参数用于指定在结果中,由`measure.vars`参数指定的列的值转换成的新列名。
下面的代码展示了如何使用`melt()`函数:
```R
# 假设df1是原始数据框,包含id, time1, time2列
long_df <- melt(df1, id.vars = "id", measure.vars = c("time1", "time2"))
```
该代码将`df1`中的`time1`和`time2`列融化为两列,一列是变量名(由`time1`, `time2`转换而来的),一列是对应的值。
### 2.3.2 详细解析dcast()的参数使用
`dcast()`函数则用于将长格式数据框转换回宽格式,它同样具备一系列参数以实现灵活的数据重塑:
- `formula`参数定义了重塑的规则,形式为`rowvar ~ colvar`,表示行和列的变量。
- `fun.aggregate`参数用于指定在重塑过程中需要执行的聚合操作,如`sum`, `mean`, `length`等。
- `value.var`参数指定了需要应用聚合函数的变量列。
例如,下面的代码将`long_df`转换回宽格式,使用`sum`作为聚合函数:
```R
# 假设long_df是已经由melt()函数处理后的长格式数据框
wide_df <- dcast(long_df, id ~ variable, fun.aggregate = sum, value.var = "value")
```
在这个例子中,我们以`id`作为行标识,将`variable`中的不同值转换为列名,并对`value`列进行求和聚合。结果`wide_df`是一个宽格式的数据框。
`melt()`和`dcast()`函数不仅提供了基础的数据转换能力,通过不同参数的组合,还能实现复杂的数据重塑任务,如多变量的处理、缺失值的填充、自定义聚合逻辑等。熟练掌握这些参数,能够大幅提高数据处理的灵活性和效率。
# 3. R语言数据重塑的实践技巧
## 3.1 使用melt()函数进行数据融化
melt()函数是reshape2包中的一个关键函数,它可以将数据从宽格式(宽表)转换为长格式(长表)。在数据科学中,这种转换常常是数据预处理的重要环节,特别是在准备进行时间序列分析或面板数据分析时。
### 3.1.1 案例分析:从宽格式到长格式的转换
为了理解melt()函数的具体作用,我们来看一个简单的例子。假设我们有一个名为`sales_data`的宽格式数据框,其中包含了不同地区的销售数据:
```r
library(reshape2)
# 假设的宽格式数据框
sales_data <- data.frame(
Year = c(2019, 2020, 2021),
North = c(1000, 1200, 1300),
South = c(800, 900, 1100),
East = c(1100, 1250, 1500),
West = c(1300, 1400, 1600)
)
```
要将这个数据框从宽格式转换为长格式,我们可以使用以下代码:
```r
# 使用melt()转换数据格式
long_sales_data <- melt(sales_data, id.vars = "Year")
```
转换后的`long_sales_data`数据框会包含三列:`Year`、`variable`(表示地区)和`value`(表示销售额)。这样,每个地区每年的销售数据都在单独的行中表示,方便进行进一步分析。
### 3.1.2 处理多变量和标识符的情况
在实际应用中,宽格式数据常常包含多个变量和标识符。melt()函数的`measure.vars`参数允许我们指定哪些列是需要被融化的变量,而`variable.name`和`value.name`参数则允许我们自定义长格式数据框中对应的变量和值列的名称。
```r
# 多变量和标识符的情况
more_sales_data <- data.frame(
Year = rep(c(2019, 2020, 2021), 2),
Region = rep(c("North", "South"), each = 3),
Sales = c(1000, 1200, 1300, 800, 900, 1100),
Profit = c(250, 260, 270, 200, 210, 220)
)
# 使用melt()处理多变量
long_more_sales_data <- melt(more_sales_data,
id.vars = c("Year", "Region"),
measure.vars = c("Sales", "Profit"),
variable.name = "Metric",
value.name = "Amount")
```
在这个例子中,`long_more_sales_data`将包含四列:`Year`、`Region`、`Metric`(表示度量指标,如销售额或利润)和`Amount`(表示具体的数值)。通过这种方式,我们可以轻松地将具有多个度量指标的宽格式数据框转换为长格式。
## 3.2 使用dcast()函数进行数据重塑
在将数据从宽格式转换为长格式后,我们可能需要根据某些分类变量重新组织数据。dcast()函数允许我们将长格式数据框重塑为宽格式,这是数据分析中常见的需求,比如制作交叉表或进行多变量分析。
### 3.2.1 将长格式数据转换为宽格式的案例
假设我们有一个使用melt()函数处理过的销售数据,现在我们想要将它转换回宽格式,以方便比较不同地区和年度的销售情况。
```r
# 重新构造长格式数据框
set.seed(123)
long_data <- data.frame(
Year = sample(2018:2021, 100, replace = TRUE),
Region = sample(c("North", "South", "East", "West"), 100, replace = TRUE),
Sales = runif(100, 500, 2000)
)
# 使用melt()将数据融化为长格式
long_data <- melt(long_data, id.vars = c("Year", "Region"))
# 使用dcast()重塑数据为宽格式
wide_data <- dcast(long_data, Year ~ Region, value.var = "Sales")
```
在上述代码中,`dcast()`函数根据`Year`列将数据重塑为宽格式,并且`Region`列的不同值成为了新的列标题,`Sales`列的值填充在相应的单元格中。
### 3.2.2 掌握公式语法及其在数据重塑中的应用
dcast()函数的强大之处在于其公式语法,它允许我们灵活地指定数据的结构。公式的一般形式为`row_variable ~ column_variable`。我们可以将此语法用于复杂的分组和聚合任务。
```r
# 使用公式语法和聚合函数进行复杂重塑
complex_wide_data <- dcast(long_data, Year ~ Region,
value.var = "Sales",
fun.aggregate = mean)
```
在这个例子中,我们不仅转换了数据格式,还应用了`mean`函数来计算每个地区每年的平均销售额。这样的操作在数据分析和报表生成中非常常见。
## 3.3 高级技巧:结合多个数据框进行重塑
在数据分析过程中,我们经常会处理多个数据框,它们可能有不同的结构,但包含共同的标识符。reshape2包提供了处理多个数据框的高级功能,允许我们合并和重塑这些数据框。
### 3.3.1 多数据框的整合与合并
在R中,我们可以使用`merge()`函数或`plyr`包的`join()`函数来合并数据框,但reshape2也提供了一个简单的函数`melt()`来进行合并。这对于只需要按某些共同的标识符进行连接的情况特别有用。
```r
# 假设我们有两个数据框,一个包含销售额,另一个包含利润
sales <- data.frame(
Year = c(2019, 2020, 2021),
North = c(1000, 1200, 1300),
South = c(800, 900, 1100)
)
profit <- data.frame(
Year = c(2019, 2020, 2021),
North = c(250, 260, 270),
South = c(200, 210, 220)
)
# 使用merge()函数合并数据框
combined_data <- merge(sales, profit, by = "Year")
```
在这个例子中,我们得到了一个包含销售额和利润数据的合并数据框,它可以直接用于进一步的分析或重塑操作。
### 3.3.2 使用reshape2处理复杂的分组和聚合任务
在某些情况下,我们可能需要在合并数据框的同时进行分组和聚合操作。虽然`dcast()`函数本身不支持在重塑过程中直接进行聚合,但我们可以先使用`melt()`函数进行合并,然后使用`dcast()`或其他聚合函数进行处理。
```r
# 使用melt()和dcast()进行合并和重塑
melted_data <- melt(sales, id.vars = "Year")
dcasted_data <- dcast(melted_data, Year ~ variable, value.var = "value", sum)
```
在这个例子中,我们首先将`sales`数据框融化,然后使用`dcast()`对`variable`变量进行分组,并对`value`进行求和聚合。这样,我们就得到了每个年度所有地区的总销售额。
## 3.4 小结
通过本章节的介绍,我们深入探讨了R语言中数据重塑的实用技巧。首先,我们了解了melt()函数的基本用法,并通过案例分析展示了如何将宽格式数据转换为长格式。接着,我们学习了dcast()函数,并展示了如何将长格式数据转换回宽格式,同时掌握其公式语法的应用。最后,我们探讨了如何结合多个数据框进行高级的重塑操作。这些技巧对于处理实际数据集,特别是在需要数据准备和预处理时,将证明是极其有价值的。
# 4. 深入学习reshape2包的高效应用
在数据处理过程中,数据重塑(Reshaping)是常见的需求之一。它涉及到将数据从一种结构转换到另一种结构,以便于进行分析、可视化和报告。R语言中的reshape2包是一个强大的工具,它提供了一系列函数来简化数据重塑的过程。在这一章节中,我们将深入探索reshape2包的高级功能,学习如何处理可能出现的错误,并通过实战案例分析来掌握其高效应用。
## 4.1 reshape2的高级功能探索
### 4.1.1 掌握cast()函数的高级用法
cast()函数是reshape2包中的一个高级函数,它允许用户根据指定的公式和数据框进行复杂的重塑操作。与dcast()不同,cast()更加灵活,可以自定义输出数据框的结构。
```r
# 用cast()函数将数据从长格式转换为宽格式的示例
library(reshape2)
# 假设有一个数据框df,其中包含日期、名称和值
df <- data.frame(date = rep(c("2021-01-01", "2021-01-02"), 3),
name = rep(c("Alice", "Bob", "Charlie"), each = 2),
value = c(1, 2, 3, 4, 5, 6))
# 使用cast()函数将数据重塑为以日期为行,以name为列的宽格式数据框
reshaped_df <- cast(df, date ~ name, value.var = "value")
reshaped_df
```
cast()函数的第一个参数是一个公式,指定如何将数据重塑。在这个例子中,`date ~ name`表示将date作为行,name作为列。value.var参数指定了要填充到新数据框的值的变量名。通过这种方式,可以灵活地调整数据框的行和列结构。
### 4.1.2 了解其他辅助函数如acast()和recast()
除了dcast()和cast(),reshape2包还包括acast()和recast()这样的辅助函数,它们为不同类型的数据输出提供了支持。acast()返回一个数组,而recast()允许用户将重塑后的数据存储在一个新的数据框中。
```r
# 使用acast()函数将数据转换为一个矩阵
matrix_data <- acast(df, date ~ name, value.var = "value")
# 使用recast()函数将数据重塑为一个新的数据框,但结构不同
recasted_df <- recast(df, date + name ~ .)
matrix_data
recasted_df
```
acast()函数返回的数据结构更加紧凑,适合进行数值计算,而recast()函数则是在不改变原始数据框结构的情况下,添加新的数据结构或对现有数据结构进行修改。
## 4.2 错误处理和调试技巧
### 4.2.1 常见错误及解决方案
在使用reshape2包进行数据重塑时,可能会遇到一些常见的错误,例如:
- 参数名或参数值错误
- 输入数据框的结构与预期不符
- 公式语法错误
针对这些错误,通常需要仔细检查函数调用和输入数据。使用R语言的调试工具,如traceback()函数,可以帮助定位错误发生的位置。
```r
# 一个错误示例,错误的公式语法
tryCatch({
wrong_reshaped_df <- dcast(df, name ~ date, value.var = "value")
}, error = function(e) {
print(e)
})
# 通过traceback()定位错误
try({
wrong_reshaped_df <- dcast(df, name ~ date, value.var = "value")
}, silent = TRUE)
traceback()
```
### 4.2.2 提升reshape2操作的性能和效率
为了提升reshape2操作的性能和效率,可以考虑以下策略:
- 确保输入数据框已经是最优的数据结构,避免重复的数据转换。
- 使用向量化操作和R的内置函数,如rowSums()、colMeans(),这些函数通常比循环快。
- 在处理大型数据集时,考虑使用data.table包代替reshape2,因为data.table在性能上有优势。
```r
# 使用data.table代替reshape2的示例
library(data.table)
setDT(df) # 将data.frame转换为data.table
dcast.data.table(df, date ~ name, value.var = "value")
```
## 4.3 实战案例分析
### 4.3.1 复杂数据集的重塑实战
在处理复杂数据集时,我们可以利用reshape2包中的高级功能来简化操作。例如,我们有一个包含多个时间点的销售数据集,每个时间点都有多个产品的销量。我们希望将这些数据重塑为每个产品在不同时间点的销量汇总。
```r
# 假设有一个复杂的数据集sales_data
sales_data <- data.frame(
product = c("Product1", "Product1", "Product2", "Product2", "Product3", "Product3"),
date = rep(c("2021-01-01", "2021-01-02"), 3),
sales = c(100, 150, 200, 250, 300, 350)
)
# 使用dcast()函数进行重塑
reshaped_sales <- dcast(sales_data, product ~ date, value.var = "sales")
reshaped_sales
```
通过这样的操作,我们可以轻松地获取每个产品在不同日期的销售数据汇总。
### 4.3.2 利用reshape2优化数据处理流程
在实际的数据处理流程中,可以利用reshape2包提供的函数来简化和优化整个流程。例如,结合ggplot2包进行数据可视化时,可以先使用reshape2对数据进行必要的重塑,然后直接使用ggplot2进行绘图。
```r
library(ggplot2)
library(reshape2)
# 将数据从长格式转换为宽格式,以便进行绘图
wide_data <- dcast(sales_data, product ~ date, value.var = "sales")
# 使用ggplot2绘制柱状图
ggplot(wide_data, aes(x = date, y = product)) +
geom_bar(stat = "identity", aes(fill = product))
```
在这个流程中,我们不仅简化了数据处理步骤,还提高了数据可视化的效率。通过将数据重塑为适合绘图的格式,我们可以直接利用ggplot2强大的绘图功能,生成美观的图表。
# 5. R语言数据重塑与相关技术的融合
## 与ggplot2结合进行数据可视化
当我们处理好数据后,接下来的步骤往往涉及到数据可视化。ggplot2是一个非常流行的R语言图形包,它使用了一种分层的语法系统,使得用户可以自由地构建各种复杂图形。我们先来看一个例子,展示如何将数据通过reshape2处理后用于ggplot2绘图。
```R
# 安装并加载所需的包
if (!require("ggplot2")) install.packages("ggplot2")
library(ggplot2)
if (!require("reshape2")) install.packages("reshape2")
library(reshape2)
# 生成示例数据
set.seed(123)
data <- data.frame(
year = rep(2017:2020, each = 4),
quarter = rep(c("Q1", "Q2", "Q3", "Q4"), times = 4),
sales = rnorm(16, mean = 100, sd = 15),
profit = rnorm(16, mean = 40, sd = 10)
)
# 使用melt()转换数据格式
long_data <- melt(data, id.vars = c("year", "quarter"))
# 利用ggplot2绘图
ggplot(long_data, aes(x = quarter, y = value, fill = variable)) +
geom_bar(stat = "identity", position = "dodge") +
facet_grid(year ~ .) +
labs(x = "Quarter", y = "Value", fill = "Variable") +
ggtitle("Sales and Profit by Year and Quarter")
```
这个例子中,我们首先创建了一个包含年份、季度、销售额和利润的宽格式数据框。然后,使用`melt()`函数将其转换为长格式,这样每个变量(销售和利润)的值都包含在一个单独的行中。最后,我们使用ggplot2函数创建了一个分组柱状图,分别按年份和季度展示销售和利润数据。
## 与dplyr包协同处理数据
另一个重要的R语言包是dplyr,它提供了许多方便的函数用于数据操作。我们可以利用reshape2和dplyr的结合,实现更加复杂的数据处理和重塑流程。
```R
# 安装并加载所需的包
if (!require("dplyr")) install.packages("dplyr")
library(dplyr)
# 使用dplyr对原始数据进行处理
processed_data <- data %>%
group_by(quarter) %>%
summarize(mean_sales = mean(sales), mean_profit = mean(profit))
# 再次使用melt()转换数据格式
final_data <- melt(processed_data, id.vars = "quarter")
# 查看最终数据框
print(final_data)
```
在此例中,我们使用了dplyr的管道操作符(`%>%`),这样可以更加直观地组合多个操作。我们首先对原始数据按季度分组,并计算每个季度的平均销售额和利润。然后,我们用`melt()`函数将数据框从宽格式转换为长格式,方便进一步的分析或可视化。
## 数据重塑的最佳实践和案例分享
为了更加深入地理解数据重塑的应用,下面我们将分享一个实际案例,探讨如何在统计分析中应用数据重塑技巧。
### 案例:数据重塑在统计分析中的应用
假设我们有一个包含多个部门和它们相应员工的销售数据,我们希望进行一些部门间的比较分析。
```R
# 创建示例数据
department_data <- data.frame(
department = rep(c("Sales", "Marketing", "HR"), each = 10),
employee_id = 1:30,
sales = runif(30, min = 1000, max = 5000),
marketing_expense = runif(30, min = 500, max = 2000),
hr_expense = runif(30, min = 300, max = 1500)
)
# 使用dcast()重塑数据为部门级别的汇总
summary_data <- dcast(department_data, department ~ employee_id, sum)
# 使用reshape2包中的colsplit()处理多列数据
split_data <- colsplit(summary_data$sales, " ", names = c("min_sales", "max_sales"))
split_data$min_expense <- colsplit(summary_data$marketing_expense, " ", names = c("min_expense", "max_expense"))[,1]
split_data$max_expense <- colsplit(summary_data$marketing_expense, " ", names = c("min_expense", "max_expense"))[,2]
split_data$min_hr_expense <- colsplit(summary_data$hr_expense, " ", names = c("min_hr_expense", "max_hr_expense"))[,1]
split_data$max_hr_expense <- colsplit(summary_data$hr_expense, " ", names = c("min_hr_expense", "max_hr_expense"))[,2]
# 查看处理后数据
print(split_data)
```
在这个案例中,我们首先创建了一个数据框,其中包含不同部门的员工销售数据和相关费用。然后,我们使用`dcast()`函数将数据重塑为部门级别的汇总视图。通过`colsplit()`函数,我们将这些汇总数据拆分成了最小值和最大值两列,从而进行了更详细的统计分析。
### 总结:数据重塑技巧的实用建议和提示
通过上面的章节,我们了解了数据重塑的基础知识和实践技巧,学习了如何结合其他包进行更复杂的操作。在实际应用中,数据重塑技术是数据分析流程中不可或缺的一环。掌握好这些技能可以大大提升工作效率和数据洞察力。下面几点建议可以帮助你在数据重塑的过程中做得更好:
- 在开始数据重塑前,一定要理解数据的基本结构和你想要达到的目标。
- 使用reshape2进行数据转换时,注意数据类型和层级结构,确保转换结果符合预期。
- 与ggplot2和dplyr等包结合使用时,先构建一个清晰的管道操作流程,然后逐步实现。
- 优化代码性能,避免在大数据集上使用效率低下的操作,适时考虑使用更高效的数据操作包。
- 利用R社区和文档资源,学习其他人的实践经验和方法,持续提升自己。
通过这些步骤和技巧的应用,你可以更有效地利用R语言进行数据重塑,并在数据分析的各个阶段都能保持高效和准确。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨 R 语言中强大的 reshape2 数据包,提供全面的教程和实践案例,指导读者掌握数据重塑的艺术与科学。通过七种高效技巧、实战案例分析、性能优化技巧以及与 dplyr 包的协同作用,专栏揭示了 reshape2 包在解决数据重塑难题、优化数据结构、创建数据透视表和提升数据可视化方面的强大功能。无论是数据分析新手还是经验丰富的专家,本专栏都将帮助读者提升数据处理技能,解锁 reshape2 包的全部潜力,并为数据重塑任务提供高效且实用的解决方案。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
并行编程多线程指南:精通线程同步与通信技术(权威性)

# 摘要
随着现代计算机系统的发展,多线程编程已成为实现并行计算和提高程序性能的关键技术。本文首先介绍了并行编程和多线程的基础概念,随后深入探讨了线程同步机制,包括同步的必要性、锁机制、其他同步原语等。第三章详细描述了线程间通信的技术实践,强调了消息队列和事件/信号机制的应用。第四章着重讨论并行算法设计和数据竞争问题,提出了有效的避免策略及锁无关同步技术。第五章分析了多线程编程的高级主题,包括线程池、异步编程模型以及调试与性能分析。最后一章回
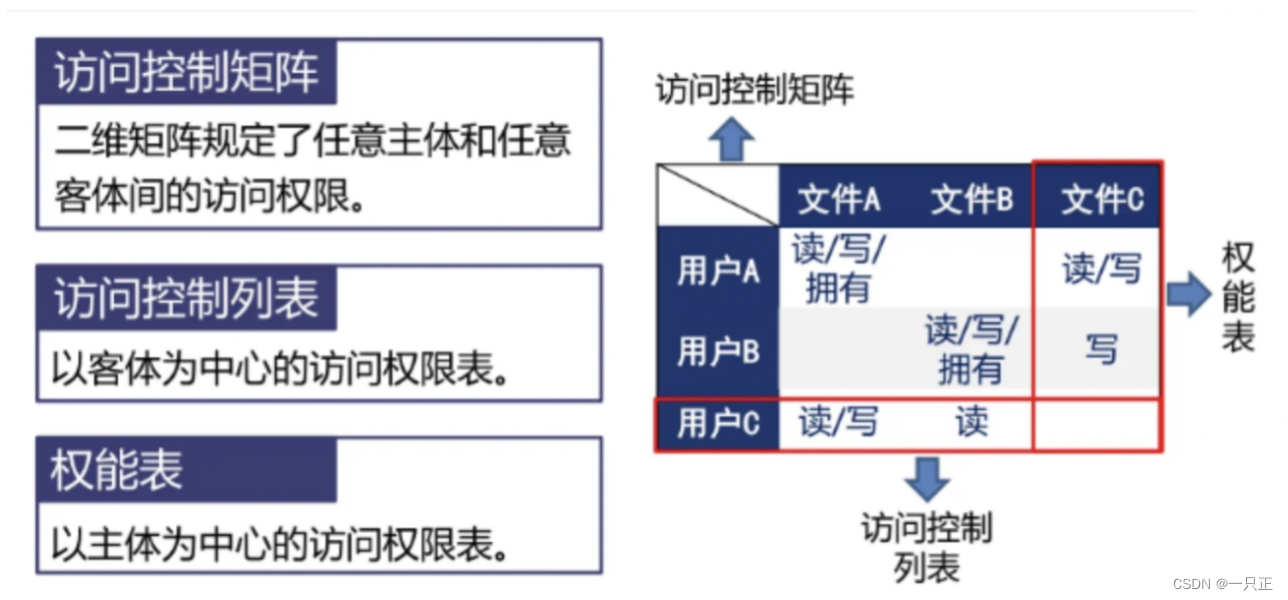
【Groops安全加固】:保障数据安全与访问控制的最佳实践
# 摘要
本文全面探讨了Groovy编程语言在不同环境下的安全实践和安全加固策略。从Groovy基础和安全性概述开始,深入分析了Groovy中的安全实践措施,包括脚本执行环境的安全配置、输入验证、数据清洗、认证与授权机制,以及代码审计和静态分析工具的应用。接着,文章探讨了Groovy与Java集成的安全实践,重点关注Java安全API在Groovy中的应用、JVM安全模型以及安全框架集成。此外,本
CMOS数据结构与管理:软件高效操作的终极指南

# 摘要
本文系统地探讨了CMOS数据结构的理论基础、管理技巧、高级应用、在软件中的高效操作,以及未来的发展趋势和挑战。首先,定义了CMOS数据结构并分析了其分类与应用场景。随后,介绍了CMOS数据的获取、存储、处理和分析的实践技巧,强调了精确操作的重要性。深入分析了CMOS数据结构在数据挖掘和机器学习等高级应用中的实例,展示了其在现代软件开发和测试中的
【服务器性能调优】:深度解析,让服务器性能飞跃提升的10大技巧
# 摘要
服务器性能调优是确保高效稳定服务运行的关键环节。本文介绍了服务器性能调优的基础概念、硬件优化策略、操作系统级别的性能调整、应用层面的性能优化以及监控和故障排除的实践方法。文章强调了硬件组件、网络设施、电源管理、操作系统参数以及应用程序代码和数据库性能的调优重要性。同时,还探讨了如何利用虚拟化、容器技术和自动化工具来实现前瞻性优化和管理。通过这些策略的实施
【逆变器测试自动化】:PIC单片机实现高效性能测试的秘诀
# 摘要
逆变器测试自动化是一个复杂过程,涉及对逆变器功能、性能参数的全面评估和监控。本文首先介绍了逆变器测试自动化与PIC单片机之间的关系,然后深入探讨了逆变器测试的原理、自动化基础以及PIC单片机的编程和应用。在第三章中,着重讲述了PIC单片机编程基础和逆变器性能测试的具体实现。第四章通过实践案例分析,展示了测试自动化系统的构建过程、软件设计、硬件组成以及测试结果的分
分布式数据库扩展性策略:构建可扩展系统的必备知识
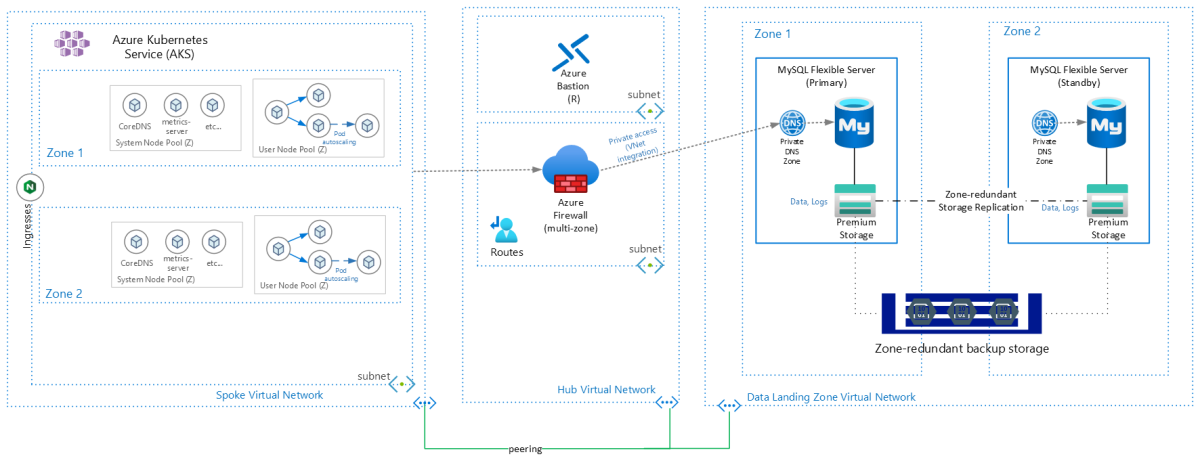
# 摘要
分布式数据库作为支持大规模数据存储和高并发处理的关键技术,其扩展性、性能优化、安全性和隐私保护等方面对于现代信息系统至关重要。本文全面探讨了分布式数据库的基本概念和架构,分析了扩展性理论及其在实际应用中的挑战与解决方案,同时深入研究了性能优化策略和安全隐私保护措施。通过对理论与实践案例的综合分析,本文展望了未
【IAR嵌入式软件开发必备指南】:从安装到项目创建的全面流程解析

# 摘要
本文全面介绍IAR嵌入式开发环境的安装、配置、项目管理及代码编写与调试方法。文章首先概述了IAR Embedded Workbench的优势和安装系统要求,然后详述了项目创建、源文件管理以及版本控制等关键步骤。接下来,探讨了嵌入式代码编写、调试技巧以及性能分析与优化工具,特别强调了内
【冠林AH1000系统安装快速指南】:新手必看的工程安装基础知识
# 摘要
本文全面介绍了冠林AH1000系统的安装流程,包括安装前的准备工作、系统安装过程、安装后的配置与优化以及系统维护等关键步骤。首先,我们分析了系统的硬件需求、环境搭建、安装介质与工具的准备,确保用户能够顺利完成系统安装前的各项准备工作。随后,文章详细阐述了冠林AH1000系统的安装向导、分区与格式化、配置与启动等关键步骤,以保证系统能够正确安装并顺利启动。接着,文章探讨了安装后的网络与安全设置、性能调
【MS建模工具全面解读】:深入探索MS建模工具的10大功能与优势

# 摘要
本文全面介绍了MS建模工具的各个方面,包括其核心功能、高级特性以及在不同领域的应用实践。首先,概述了MS建模工具的基
电力系统创新应用揭秘:对称分量法如何在现代电网中大显身手
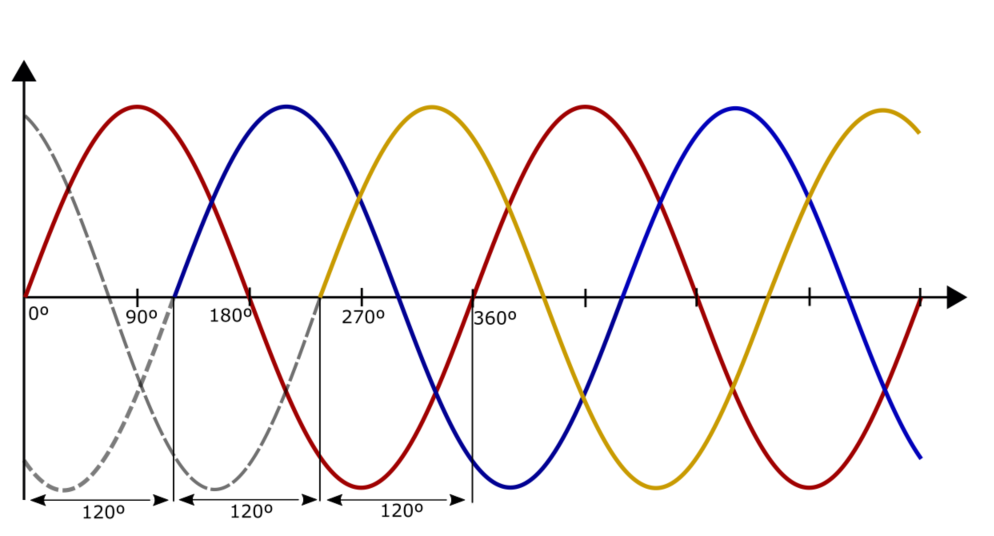
# 摘要
对称分量法是电力系统分析中的一种基本工具,它提供了处理三相电路非对称故障的有效手段。本文系统地回顾了对称分量法的理论基础和历史沿革,并详述了其在现代电力系统分析、稳定性评估及故障定位等领域的应用。随着现代电力系统复杂性的增加,特别是可再生能源与电力电子设备的广泛应用,对称分量法面临着新的挑战和创新应用。文章还探讨了对称分量法在智能电网中的潜在应用前景,及其与自动化、智能化技术的融合,
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )