Map Join与传统Join算法的比较
发布时间: 2024-10-31 06:15:26 阅读量: 3 订阅数: 6 
# 1. 数据库连接算法概述
在当今的IT领域,数据库连接算法是数据库管理系统(DBMS)中不可或缺的一部分,尤其对于数据分析师和数据库管理员来说。连接操作允许我们从多个表中获取数据,并将它们整合成有用的信息。算法的效率直接影响查询处理的速度和系统资源的使用。在本章中,我们将探究不同类型的连接算法,理解它们的工作原理、性能特点以及在实际应用中的影响。
数据库连接算法通常分为两大类:传统的Join算法和优化后的Join算法。前者包括嵌套循环连接、排序合并连接、索引连接等,后者中最引人注目的是Map Join算法。这些算法在处理能力、内存和磁盘I/O的使用方面各有千秋。接下来的章节将深入探讨这些连接算法的具体实现和优化方式。我们将通过分析算法核心概念、执行流程和性能分析来揭示它们如何有效地处理数据连接任务。
# 2. 传统Join算法详解
在数据库管理系统中,Join操作是通过匹配两个或多个表中的字段来组合这些表的数据。对于传统Join算法而言,常见的有嵌套循环连接、排序合并连接和索引连接三种方式。这些算法在性能上各有千秋,适用于不同的使用场景。接下来,我们将详细探讨每种算法的基本原理与实现,以及它们的性能分析与优化方法。
## 2.1 嵌套循环连接算法
### 2.1.1 基本原理与实现
嵌套循环连接算法是Join操作中最直观的一种算法。它涉及到双重循环,外循环遍历一个表的每一行,内循环遍历另一个表中的每一行,检查这两个表中的相关字段是否满足连接条件。
以两个表A和B为例,A表有a和b两个字段,B表有c和d两个字段,我们要找出字段a和c相等的记录,嵌套循环连接算法的伪代码如下:
```sql
FOR each row a IN table A DO
FOR each row b IN table B DO
IF a.b = b.d THEN
OUTPUT (a, b)
END IF
END FOR
END FOR
```
### 2.1.2 性能分析与优化
嵌套循环连接算法在小表和大表的连接操作中效率较高,尤其是当连接条件可以在小表中创建索引时。然而,如果两个表都很大,这种算法的效率就会大大降低,因为其时间复杂度达到O(n*m),其中n和m分别是两个表的大小。
优化嵌套循环连接的方法有:
- 对于小表建立索引,减少查找时间。
- 采用合适的连接顺序,先连接过滤条件较多的表。
- 使用启发式方法预先过滤数据,减少循环迭代的次数。
## 2.2 排序合并连接算法
### 2.2.1 基本原理与实现
排序合并连接算法通过排序来优化数据访问,主要分为三个步骤:
1. 对两个表进行排序,排序依据是连接键。
2. 指针分别指向两个表的开始位置。
3. 逐个比较两个表中当前指针所指的记录,当连接键相等时将它们输出,否则移动指针到下一个可能匹配的位置。
排序合并连接的伪代码如下:
```sql
MERGE_SORT(tableA, joinKey)
MERGE_SORT(tableB, joinKey)
pointerA = pointerB = 1
WHILE pointerA <= length(tableA) AND pointerB <= length(tableB) DO
IF tableA[pointerA].joinKey == tableB[pointerB].joinKey THEN
OUTPUT (tableA[pointerA], tableB[pointerB])
pointerA += 1
pointerB += 1
ELSE IF tableA[pointerA].joinKey < tableB[pointerB].joinKey THEN
pointerA += 1
ELSE
pointerB += 1
END IF
END WHILE
```
### 2.2.2 性能分析与优化
排序合并连接适用于处理大数据量的表连接操作,但前提是两个表都必须能够完全载入内存。其主要开销在于排序操作,需要O(nlogn + mlogm)的时间复杂度。
为了优化这一算法:
- 可以采用外部排序,将表分块载入内存进行排序。
- 利用多路归并排序合并多个数据块。
## 2.

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【MapReduce数据处理】:掌握Reduce阶段的缓存机制与内存管理技巧

# 1. MapReduce数据处理概述
MapReduce是一种编程模型,旨在简化大规模数据集的并行运算。其核心思想是将复杂的数据处理过程分解为两个阶段:Map(映射)阶段和Reduce(归约)阶段。Map阶段负责处理输入数据,生成键值对集合;Reduce阶段则对这些键值对进行合并处理。这一模型在处理大量数据时,通过分布式计算,极大地提
【数据仓库Join优化】:构建高效数据处理流程的策略

# 1. 数据仓库Join操作的基础理解
## 数据库中的Join操作简介
在数据仓库中,Join操作是连接不同表之间数据的核心机制。它允许我们根据特定的字段,合并两个或多个表中的数据,为数据分析和决策支持提供整合后的视图。Join的类型决定了数据如何组合,常用的SQL Join类型包括INNER JOIN、LEFT JOIN、RIGHT JOIN、FULL JOIN等。
## SQL Joi
跨集群数据Shuffle:MapReduce Shuffle实现高效数据流动

# 1. MapReduce Shuffle基础概念解析
## 1.1 Shuffle的定义与目的
MapReduce Shuffle是Hadoop框架中的关键过程,用于在Map和Reduce任务之间传递数据。它确保每个Reduce任务可以收到其处理所需的正确数据片段。Shuffle过程主要涉及数据的排序、分组和转移,目的是保证数据的有序性和局部性,以便于后续处理。
【MapReduce内存管理策略】:优化Reduce端内存使用以提升数据拉取速度
# 1. MapReduce内存管理概述
在大数据处理领域中,MapReduce作为一种流行的编程模型,已被广泛应用于各种场景,其中内存管理是影响性能的关键因素之一。MapReduce内存管理涉及到内存的分配、使用和回收,需要精心设计以保证系统高效稳定运行。
## 1.1 内存管理的重要性
内存管理在MapReduce
MapReduce与大数据:挑战PB级别数据的处理策略
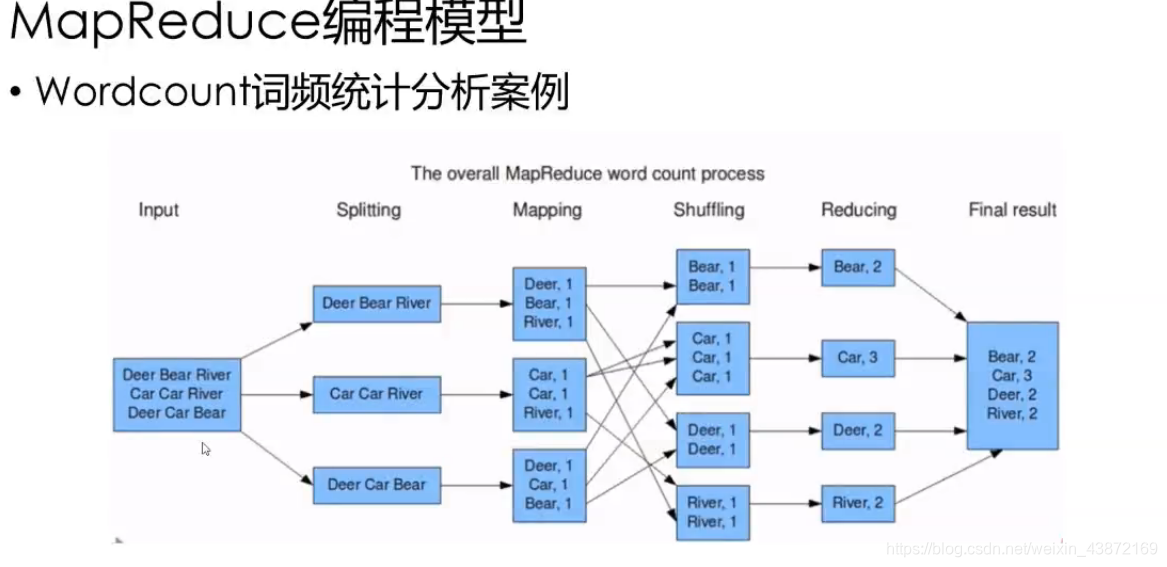
# 1. MapReduce简介与大数据背景
## 1.1 大数据的定义与特性
大数据(Big Data)是指传统数据处理应用软件难以处
MapReduce中的Combiner与Reducer选择策略:如何判断何时使用Combiner

# 1. MapReduce框架基础
MapReduce 是一种编程模型,用于处理大规模数据集
MapReduce Shuffle数据加密指南:确保数据安全的高级实践
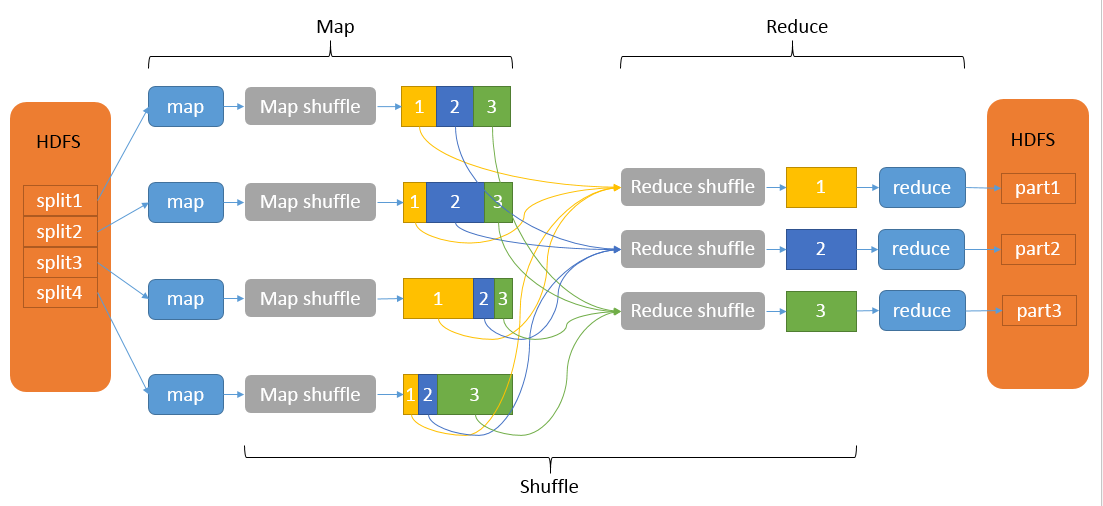
# 1. MapReduce Shuffle的内部机制与挑战
MapReduce框架的核心优势之一是能够处理大量数据,而Shuffle阶段作为这个过程的关键部分,其性能直接关系到整个作业的效率。本章我们将深入探究MapReduce Shuffle的内部机制,揭露其背后的工作原理,并讨论在此过程中遇到的挑战。
## 1.1 Shuffle的执行流程
Shuffle阶段大致可以分为三个部分:Map端Shuffle、Shuffle传输和Reduce端S
MapReduce小文件处理:数据预处理与批处理的最佳实践

# 1. MapReduce小文件处理概述
## 1.1 MapReduce小文件问题的普遍性
在大规模数据处理领域,MapReduce小文件问题普遍存在,严重影响
项目中的Map Join策略选择

# 1. Map Join策略概述
Map Join策略是现代大数据处理和数据仓库设计中经常使用的一种技术,用于提高Join操作的效率。它主要依赖于MapReduce模型,特别是当一个较小的数据集需要与一个较大的数据集进行Join时。本章将介绍Map Join策略的基本概念,以及它在数据处理中的重要性。
Map Join背后的核心思想是预先将小数据集加载到每个Map任
MapReduce自定义分区:理论与实践的深入探讨

# 1. MapReduce自定义分区概述
MapReduce是大数据处理领域中的一种分布式编程模型,广泛应用于大规模数据集的并行运算。在MapReduce中,自定义分区是优化数据处理流程、提高作业效率的重要手段。通过对数据进行特定的分区处理,我们可以更加精细地控制MapReduce作业中Map和Reduce阶段的数据流动,进而提升整体的处理性能。本章将概述自定义分区的概念、目的及其在实际应
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )