【问题解决宝典】:BaseHTTPServer常见错误处理与调试技巧
发布时间: 2024-09-30 13:51:29 阅读量: 30 订阅数: 20 
# 1. BaseHTTPServer简介与基础使用
## 1.1 BaseHTTPServer介绍
BaseHTTPServer是Python标准库的一部分,它提供了一个简单易用的HTTP服务器框架。虽然其功能相对基础,但对于小型项目或快速原型开发来说却十分方便。它主要通过继承`BaseHTTPRequestHandler`类和创建`HTTPServer`实例来运行一个Web服务器。
## 1.2 基础使用步骤
要在Python程序中使用BaseHTTPServer,你需要做以下几步:
- 导入`BaseHTTPServer`模块中的`HTTPServer`和`BaseHTTPRequestHandler`类。
- 定义一个请求处理器类,继承自`BaseHTTPRequestHandler`,并实现必要的请求处理方法。
- 创建`HTTPServer`实例,指定监听的地址和端口。
- 启动服务器的主循环。
例如,下面是一个简单的Web服务器代码示例:
```python
from BaseHTTPServer import HTTPServer, BaseHTTPRequestHandler
class SimpleHTTPRequestHandler(BaseHTTPRequestHandler):
def do_GET(self):
self.send_response(200)
self.send_header('Content-type', 'text/html')
self.end_headers()
self.wfile.write(b"Hello, World!")
if __name__ == "__main__":
server_address = ('', 8000) # 监听8000端口
httpd = HTTPServer(server_address, SimpleHTTPRequestHandler)
httpd.serve_forever() # 启动服务器主循环
```
运行上述代码,即可启动一个在本地8000端口监听的Web服务器,通过访问*** ,可以看到返回的"Hello, World!"。
## 1.3 注意事项
虽然BaseHTTPServer功能简单,但它并不是用于生产环境的最佳选择。因为它缺乏很多生产级别的功能,比如多线程支持、安全性和性能优化等。对于任何需要长期运行并处理高负载的Web应用,推荐使用更成熟的服务器软件,如Apache或Nginx,或框架如Flask或Django自带的服务器。
# 2. BaseHTTPServer的错误类型及诊断
## 2.1 常见错误代码分析
### 2.1.1 404错误处理
404错误,也被称为“未找到”错误,通常发生在服务器无法找到客户端请求的资源时。在BaseHTTPServer中,这种错误可能由多种因素导致,例如请求的URL路径错误、服务器配置问题等。
要处理404错误,首先需要确保服务器配置正确,所有请求的路径都应有对应的处理逻辑。下面是一个简单的404错误处理示例:
```python
from BaseHTTPServer import BaseHTTPRequestHandler, HTTPServer
class RequestHandler(BaseHTTPRequestHandler):
def do_GET(self):
try:
# 模拟处理请求
if self.path == '/':
self.handle_root()
else:
self.handle_custom()
except Exception as e:
self.handle_not_found()
def handle_root(self):
self.send_response(200)
self.send_header('Content-type', 'text/html')
self.end_headers()
self.wfile.write(b"Welcome to the BaseHTTPServer!")
def handle_custom(self):
self.send_response(200)
self.send_header('Content-type', 'text/html')
self.end_headers()
self.wfile.write(b"Custom page content")
def handle_not_found(self):
self.send_response(404)
self.send_header('Content-type', 'text/html')
self.end_headers()
self.wfile.write(b"Not Found")
def run(server_class=HTTPServer, handler_class=RequestHandler, port=8080):
server_address = ('', port)
httpd = server_class(server_address, handler_class)
print(f'Server running on port {port}...')
httpd.serve_forever()
if __name__ == '__main__':
run()
```
在此代码中,`handle_not_found` 函数负责处理404错误,并返回一个简单的“Not Found”页面。为了测试404错误,你可以尝试访问一个不存在的路径,如 `***`。
### 2.1.2 500内部服务器错误
500错误表示服务器遇到了意外情况,导致它无法完成对请求的处理。这可能是由于服务器端代码中的错误,比如脚本错误或请求被拒绝。当发生500错误时,通常需要检查服务器日志,以确定导致错误的具体原因。
处理500错误通常涉及到错误日志的分析。对于BaseHTTPServer来说,可以通过实现自定义的错误处理方法来记录和响应500错误:
```python
class RequestHandler(BaseHTTPRequestHandler):
# ... (省略其他方法)
def do_GET(self):
try:
# ... (省略其他处理)
except Exception as e:
self.handle_error(500, str(e))
def handle_error(self, status_code, message):
self.send_response(status_code)
self.send_header('Content-type', 'text/html')
self.end_headers()
error_page = f"<html><body><h1>Error {status_code}: {message}</h1></body></html>"
self.wfile.write(error_page.encode('utf-8'))
# ... (省略其他代码)
```
当发生异常时,`handle_error` 方法会被调用,并生成一个包含错误信息的HTML页面。为了更好地进行错误诊断,可以将错误信息写入日志文件,以便事后分析。
## 2.2 错误日志与日志管理
### 2.2.1 配置日志记录
良好的日志记录对于故障诊断至关重要。Python的logging模块可以用于BaseHTTPServer的日志记录,确保你能够捕获所有的错误信息和服务器行为。
以下是如何在BaseHTTPServer中配置日志记录:
```python
import logging
from BaseHTTPServer import BaseHTTPRequestHandler, HTTPServer
# 配置日志记录
logger = logging.getLogger('BaseHTTPServer')
logger.setLevel(logging.DEBUG)
fh = logging.FileHandler('server.log')
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
fh.setFormatter(formatter)
logger.addHandler(fh)
# ... (省略RequestHandler和run函数)
if __name__ == '__main__':
run()
```
上面的代码示例中,我们创建了一个日志记录器、一个文件处理器,并将其格式化为包含时间戳、记录器名称、日志级别和消息的格式。之后,将文件处理器添加到日志记录器中,以便将日志输出到`server.log`文件。
### 2.2.2 日志分析技巧
日志文件中包含了服务器的许多运行信息,分析日志文件可以帮助识别错误模式和性能瓶颈。以下是分析日志文件的一些基本技巧:
- **查找重复出现的错误代码**:通过查找重复的404或500错误代码,可以快速定位问题。
- **监控异常堆栈跟踪**:在日志中,仔细检查任何异常堆栈跟踪,它们提供了错误发生的精确位置和原因。
- **评估请求的响应时间**:比较不同请求的响应时间可以帮助识别性能问题。
- **使用日志级别过滤**:根据日志的严重性级别(INFO、WARNING、ERROR等)过滤日志,专注于最紧急的问题。
在分析过程中,使用文本编辑器或日志分析工具可以帮助更有效地处理日志数据。例如,可以使用`grep`命令在日志文件中快速定位特定的日志条目:
```bash
grep "ERROR" server.log
```
这条命令会列出所有包含"ERROR"的日志条目,便于你快速找到错误信息。
## 2.3 常见运行时错误的排查
### 2.3.1 端口冲突问题
当尝试启动一个服务时,可能会遇到端口冲突的问题,因为端口已经被其他进程占用。例如,尝试在80端口启动服务器时,如果该端口已被其他服务占用,就会遇到错误。
解决端口冲突问题,首先需要找出哪个进程正在使用该端口。在Unix系统中,可以使用`netstat`命令和`grep`来查找:
```bash
sudo netstat -tulpn | grep :80
```
如果发现80端口被某个进程占用,你可以停止该进程或选择一个不同的端口来启动你的服务器。在Python中,可以在创建HTTPServer实例时指定端口号:
```python
httpd = HTTPServer(('localhost', 8080), RequestHandler)
```
在这个例子中,服务器将在8080端口上运行,而不是默认的80端口。
### 2.3.2 资源不足问题
资源不足错误通常是由于系统资源限制导致的,如内存不足(Out of memory, OOM)或进程数量达到系统上限。当资源不足时,操作系统可能会杀死进程,导致服务不正常退出。
排查资源不足问题需要使用系统监控工具,如`top`、`htop`或`dstat`。这些工具可以帮助你实时监控系统的资源使用情况。当发现资源使用达到峰值时,应考虑优化程序或增加资源配额。
例如,使用`top`命令可以查看当前系统的资源使用状态:
```bash
top
```
如果发现内存或CPU使用率过高,可以考虑优化代码或增加服务器的物理资源。在BaseHTTPServer中,可以通过限制并发连接数、优化请求处理逻辑等方法来减少资源消耗。
以上是BaseHTTPServer错误类型及诊断方法的第二章内容,本章重点介绍了常见

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Python 库文件学习之 BaseHTTPServer》专栏深入剖析了 BaseHTTPServer 的内部工作原理,阐述了其在 Python Web 开发中的核心作用,并揭示了其封装和优化的秘密。专栏还提供了优化 BaseHTTPServer 性能的策略,介绍了如何使用它实现高效的异步 Web 服务。此外,专栏还提供了 BaseHTTPServer 在小型项目中的应用案例,探讨了它与现代 Web 框架的集成,以及如何使用它进行服务健康和性能监控。最后,专栏还介绍了为 BaseHTTPServer 设计负载均衡策略,以及它在微服务架构中的应用案例。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
从Python脚本到交互式图表:Matplotlib的应用案例,让数据生动起来

# 1. Matplotlib的安装与基础配置
在这一章中,我们将首先讨论如何安装Matplotlib,这是一个广泛使用的Python绘图库,它是数据可视化项目中的一个核心工具。我们将介绍适用于各种操作系统的安装方法,并确保读者可以无痛地开始使用Matplotlib
【数据集加载与分析】:Scikit-learn内置数据集探索指南

# 1. Scikit-learn数据集简介
数据科学的核心是数据,而高效地处理和分析数据离不开合适的工具和数据集。Scikit-learn,一个广泛应用于Python语言的开源机器学习库,不仅提供了一整套机器学习算法,还内置了多种数据集,为数据科学家进行数据探索和模型验证提供了极大的便利。本章将首先介绍Scikit-learn数据集的基础知识,包括它的起源、
【循环神经网络】:TensorFlow中RNN、LSTM和GRU的实现

# 1. 循环神经网络(RNN)基础
在当今的人工智能领域,循环神经网络(RNN)是处理序列数据的核心技术之一。与传统的全连接网络和卷积网络不同,RNN通过其独特的循环结构,能够处理并记忆序列化信息,这使得它在时间序列分析、语音识别、自然语言处理等多
Keras注意力机制:构建理解复杂数据的强大模型

# 1. 注意力机制在深度学习中的作用
## 1.1 理解深度学习中的注意力
深度学习通过模仿人脑的信息处理机制,已经取得了巨大的成功。然而,传统深度学习模型在处理长序列数据时常常遇到挑战,如长距离依赖问题和计算资源消耗。注意力机制的提出为解决这些问题提供了一种创新的方法。通过模仿人类的注意力集中过程,这种机制允许模型在处理信息时,更加聚焦于相关数据,从而提高学习效率和准确性。
## 1.2
硬件加速在目标检测中的应用:FPGA vs. GPU的性能对比
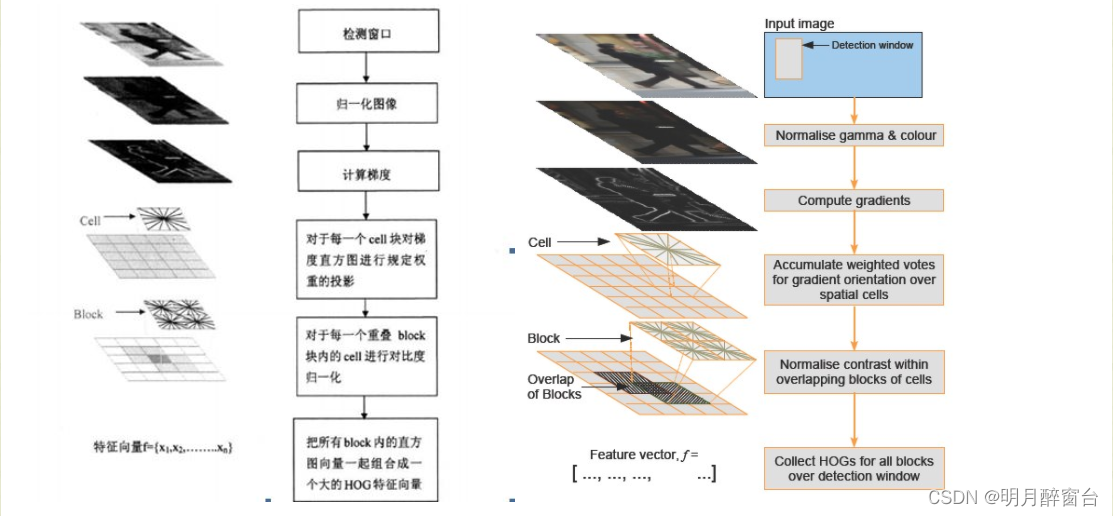
# 1. 目标检测技术与硬件加速概述
目标检测技术是计算机视觉领域的一项核心技术,它能够识别图像中的感兴趣物体,并对其进行分类与定位。这一过程通常涉及到复杂的算法和大量的计算资源,因此硬件加速成为了提升目标检测性能的关键技术手段。本章将深入探讨目标检测的基本原理,以及硬件加速,特别是FPGA和GPU在目标检测中的作用与优势。
## 1.1 目标检测技术的演进与重要性
目标检测技术的发展与深度学习的兴起紧密相关
【提高图表信息密度】:Seaborn自定义图例与标签技巧
# 1. Seaborn图表的简介和基础应用
Seaborn 是一个基于 Matplotlib 的 Python 数据可视化库,它提供了一套高级接口,用于绘制吸引人、信息丰富的统计图形。Seaborn 的设计目的是使其易于探索和理解数据集的结构,特别是对于大型数据集。它特别擅长于展示和分析多变量数据集。
## 1.1 Seaborn
数据分析中的概率分布应用:概率分布的现实应用指南

# 1. 概率分布基础概述
## 1.1 概率分布的意义与应用
概率分布是统计学和概率论中的核心概念,它描述了随机变量取各种可能值的概率。在数据分析、机器学习、金融分析等领域中,概率分布帮助我们理解数据的生成机制和特征。例如,在质量控制中,通
Pandas数据转换:重塑、融合与数据转换技巧秘籍

# 1. Pandas数据转换基础
在这一章节中,我们将介绍Pandas库中数据转换的基础知识,为读者搭建理解后续章节内容的基础。首先,我们将快速回顾Pandas库的重要性以及它在数据分析中的核心地位。接下来,我们将探讨数据转换的基本概念,包括数据的筛选、清洗、聚合等操作。然后,逐步深入到不同数据转换场景,对每种操作的实际意义进行详细解读,以及它们如何影响数
PyTorch超参数调优:专家的5步调优指南

# 1. PyTorch超参数调优基础概念
## 1.1 什么是超参数?
在深度学习中,超参数是模型训练前需要设定的参数,它们控制学习过程并影响模型的性能。与模型参数(如权重和偏置)不同,超参数不会在训练过程中自动更新,而是需要我们根据经验或者通过调优来确定它们的最优值。
## 1.2 为什么要进行超参数调优?
超参数的选择直接影响模型的学习效率和最终的性能。在没有经过优化的默认值下训练模型可能会导致以下问题:
- **过拟合**:模型在
NumPy在金融数据分析中的应用:风险模型与预测技术的6大秘籍

# 1. NumPy基础与金融数据处理
金融数据处理是金融分析的核心,而NumPy作为一个强大的科学计算库,在金融数据处理中扮演着不可或缺的角色。本章首先介绍NumPy的基础知识,然后探讨其在金融数据处理中的应用。
## 1.1 NumPy基础
NumPy(N
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )