Oracle跨数据库查询实战指南:掌握分布式查询的奥秘,从入门到精通
发布时间: 2024-08-03 14:00:22 阅读量: 18 订阅数: 27 

# 1. 跨数据库查询概述**
跨数据库查询是指在不同的数据库系统之间执行查询,从而访问和整合来自多个数据源的数据。它允许组织打破数据孤岛,并从分布式数据环境中获得更全面的见解。
跨数据库查询的优势包括:
- **数据整合:**将来自不同数据库的数据整合到一个视图中,提供对组织数据的全面了解。
- **数据共享:**允许不同的应用程序和用户访问和使用分布在不同数据库中的数据。
- **增强决策制定:**通过访问更全面的数据,组织可以做出更明智的决策。
# 2. 跨数据库查询的基础
### 2.1 分布式数据库架构
#### 2.1.1 分布式数据库的概念和优势
分布式数据库是一种将数据分布在多个物理位置的数据库系统。它允许用户访问和管理位于不同服务器或网络上的数据,就像它们位于同一台计算机上一样。
分布式数据库的优势包括:
- **可扩展性:**可以轻松地添加或删除节点以满足不断变化的性能需求。
- **高可用性:**如果一个节点发生故障,其他节点可以继续提供服务,确保数据的高可用性。
- **数据局部性:**数据可以存储在离用户最近的位置,从而提高查询性能。
- **弹性:**分布式数据库可以自动处理节点故障和网络中断,确保数据的完整性和一致性。
#### 2.1.2 分布式数据库的实现方式
分布式数据库的实现方式有多种,包括:
- **分片:**将数据表水平划分为多个分片,每个分片存储特定范围的数据。
- **复制:**将数据复制到多个节点,以提高可用性和性能。
- **共享磁盘:**使用共享存储设备将数据存储在所有节点上,确保数据的一致性。
### 2.2 跨数据库查询协议
跨数据库查询协议允许用户从不同的数据库系统中查询数据。常用的协议包括:
#### 2.2.1 SQL Server Distributed Queries
SQL Server Distributed Queries允许用户从SQL Server数据库查询其他数据库系统,例如Oracle和MySQL。它使用四部分命名法来指定远程数据库对象,如下所示:
```
[Linked Server Name].[Database Name].[Schema Name].[Object Name]
```
#### 2.2.2 Oracle Database Link
Oracle Database Link允许用户从Oracle数据库查询其他数据库系统,例如SQL Server和MySQL。它使用别名来引用远程数据库对象,如下所示:
```
SELECT * FROM [Remote Database Alias].[Table Name]
```
#### 2.2.3 MySQL Federated Tables
MySQL Federated Tables允许用户从MySQL数据库查询其他数据库系统,例如SQL Server和Oracle。它使用别名来引用远程数据库表,如下所示:
```
SELECT * FROM [Remote Database Alias].[Table Name]
```
# 3.1 使用 SQL Server Distributed Queries
**3.1.1 创建 Linked Server**
为了在 SQL Server 中执行跨数据库查询,需要先创建一个 Linked Server,它充当对远程数据库的连接。创建 Linked Server 的步骤如下:
1. 在 SQL Server Management Studio 中,右键单击“服务器对象”节点,然后选择“新建”>“Linked Server”。
2. 在“新建链接服务器”对话框中,输入远程服务器的名称或 IP 地址。
3. 选择远程服务器的类型(例如,SQL Server、Oracle)。
4. 提供必要的连接信息,例如用户名、密码和数据库名称。
5. 单击“确定”创建 Linked Server。
**3.1.2 执行跨数据库查询**
创建 Linked Server 后,可以使用 OPENQUERY 语句执行跨数据库查询。该语句的语法如下:
```sql
SELECT *
FROM OPENQUERY(LinkedServerName, 'SELECT * FROM RemoteTable')
```
其中:
* LinkedServerName 是创建的 Linked Server 的名称。
* RemoteTable 是远程数据库中要查询的表。
例如,要从名为 "RemoteServer" 的 Linked Server 中查询 "Customers" 表,可以使用以下查询:
```sql
SELECT *
FROM OPENQUERY(RemoteServer, 'SELECT * FROM Customers')
```
### 3.2 使用 Oracle Database Link**
**3.2.1 创建 Database Link**
在 Oracle 数据库中,使用 Database Link 来连接到远程数据库。创建 Database Link 的步骤如下:
1. 在 Oracle SQL Developer 中,右键单击“连接”节点,然后选择“新建”>“Database Link”。
2. 在“新建数据库链接”对话框中,输入远程数据库的名称或 IP 地址。
3. 选择远程数据库的类型(例如,Oracle、SQL Server)。
4. 提供必要的连接信息,例如用户名、密码和数据库名称。
5. 单击“确定”创建 Database Link。
**3.2.2 执行跨数据库查询**
创建 Database Link 后,可以使用 dblink 语法执行跨数据库查询。该语法的语法如下:
```sql
SELECT *
FROM dblink(RemoteDatabase, 'SELECT * FROM RemoteTable')
```
其中:
* RemoteDatabase 是创建的 Database Link 的名称。
* RemoteTable 是远程数据库中要查询的表。
例如,要从名为 "RemoteDB" 的 Database Link 中查询 "Employees" 表,可以使用以下查询:
```sql
SELECT *
FROM dblink(RemoteDB, 'SELECT * FROM Employees')
```
### 3.3 使用 MySQL Federated Tables**
**3.3.1 创建 Federated Table**
在 MySQL 中,使用 Federated Tables 来连接到远程数据库。创建 Federated Table 的步骤如下:
1. 在 MySQL Workbench 中,右键单击“模式”节点,然后选择“新建”>“Federated Table”。
2. 在“新建联合表”对话框中,输入远程数据库的名称或 IP 地址。
3. 选择远程数据库的类型(例如,MySQL、Oracle)。
4. 提供必要的连接信息,例如用户名、密码和数据库名称。
5. 选择要联合的远程表。
6. 单击“确定”创建 Federated Table。
**3.3.2 执行跨数据库查询**
创建 Federated Table 后,可以使用它就像本地表一样执行跨数据库查询。例如,要从名为 "RemoteTable" 的 Federated Table 中查询数据,可以使用以下查询:
```sql
SELECT *
FROM RemoteTable
```
# 4. 跨数据库查询优化
### 4.1 查询计划优化
#### 4.1.1 理解查询计划
查询计划是数据库优化器为执行查询而生成的执行步骤。它指定了查询中各个操作的顺序和方式。理解查询计划对于优化查询性能至关重要。
**查询计划的组成部分:**
- **操作符:**表示查询中执行的特定操作,如表扫描、索引查找、连接等。
- **估计行数:**估计每个操作符处理的行数。
- **成本:**估计每个操作符执行的成本,通常以 CPU 时间或 I/O 操作衡量。
- **访问类型:**指定操作符如何访问数据,如索引扫描、表扫描、哈希连接等。
#### 4.1.2 优化查询计划
优化查询计划涉及识别和解决导致低性能的瓶颈。以下是优化查询计划的一些常见技术:
- **使用索引:**索引可以显着提高数据访问速度。确保为经常查询的列创建索引。
- **避免全表扫描:**全表扫描需要扫描整个表,这可能非常耗时。使用索引或谓词来缩小要扫描的数据量。
- **优化连接顺序:**连接顺序会影响查询性能。考虑使用嵌套连接或哈希连接来优化连接顺序。
- **使用参数化查询:**参数化查询可以防止 SQL 注入攻击,并可以提高查询性能。
- **减少子查询:**子查询会增加查询复杂性,并可能导致性能问题。尝试将子查询转换为连接或使用视图。
### 4.2 数据分区优化
#### 4.2.1 分区概念和优势
分区是一种将大型表划分为更小、更易于管理的部分的技术。分区可以显著提高查询性能,特别是对于经常查询特定数据范围的情况。
**分区的好处:**
- **提高查询性能:**分区允许数据库仅扫描与查询相关的分区,从而减少 I/O 操作和提高查询速度。
- **简化数据管理:**分区可以简化数据管理任务,如备份、恢复和删除。
- **提高并发性:**分区可以提高并发性,因为多个用户可以同时访问不同的分区。
#### 4.2.2 创建和管理分区
创建和管理分区涉及以下步骤:
- **确定分区键:**分区键是用于将数据划分为分区的列。
- **创建分区表:**使用 `CREATE TABLE` 语句创建分区表,并指定分区键和分区策略。
- **添加分区:**使用 `ALTER TABLE` 语句添加新分区。
- **管理分区:**可以使用 `ALTER TABLE` 语句重新分配数据、合并分区或删除分区。
### 4.3 索引优化
#### 4.3.1 索引类型和选择
索引是一种数据结构,它可以加快对数据库表的访问速度。有不同类型的索引,每种类型都有自己的优点和缺点。
**索引类型:**
- **B 树索引:**一种平衡树结构,用于快速查找数据。
- **哈希索引:**一种基于哈希表的索引,用于快速查找基于哈希值的数据。
- **位图索引:**一种用于快速查找特定值集合的数据结构。
**索引选择:**
选择正确的索引对于优化查询性能至关重要。考虑以下因素:
- **查询模式:**确定查询通常如何访问数据。
- **索引大小:**索引大小会影响插入和更新操作的性能。
- **数据分布:**考虑数据分布以选择最有效的索引类型。
#### 4.3.2 创建和管理索引
创建和管理索引涉及以下步骤:
- **创建索引:**使用 `CREATE INDEX` 语句创建索引。
- **管理索引:**可以使用 `ALTER INDEX` 语句重建、删除或禁用索引。
- **监控索引:**定期监控索引的使用情况和碎片情况,以确保其有效性。
# 5. 跨数据库查询高级应用
### 5.1 异构数据库查询
**5.1.1 异构数据库的概念和挑战**
异构数据库是指不同厂商、不同平台或不同数据模型的数据库系统。跨异构数据库查询允许用户从多个异构数据库中检索数据,但由于异构数据库的异质性,带来了以下挑战:
* **数据类型差异:**不同数据库系统使用不同的数据类型,需要进行类型转换。
* **SQL 语法差异:**不同数据库系统使用不同的 SQL 方言,需要进行语法转换。
* **连接协议差异:**不同数据库系统使用不同的连接协议,需要使用异构数据库连接器。
### 5.1.2 使用异构数据库连接器
异构数据库连接器是一种中间件,它允许应用程序连接到异构数据库并执行查询。常见的异构数据库连接器包括:
* **JDBC:**Java 数据库连接器,支持多种数据库系统。
* **ODBC:**开放数据库连接,支持多种数据库系统。
* **ADO.NET:**微软的异构数据库连接器,支持多种数据库系统。
使用异构数据库连接器时,需要遵循以下步骤:
1. 安装异构数据库连接器。
2. 配置异构数据库连接器,包括数据库连接信息、数据类型映射和 SQL 语法转换规则。
3. 使用异构数据库连接器连接到异构数据库。
4. 执行跨异构数据库查询。
**代码示例:**
```java
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class HeterogeneousDatabaseQuery {
public static void main(String[] args) throws Exception {
// 加载异构数据库连接器驱动
Class.forName("com.example.jdbc.HeterogeneousDatabaseDriver");
// 连接到异构数据库
Connection connection = DriverManager.getConnection("jdbc:heterogeneous://host:port/database", "username", "password");
// 执行跨异构数据库查询
Statement statement = connection.createStatement();
ResultSet resultSet = statement.executeQuery("SELECT * FROM table1@database1 UNION SELECT * FROM table2@database2");
// 遍历查询结果
while (resultSet.next()) {
// 获取查询结果
}
// 关闭连接
resultSet.close();
statement.close();
connection.close();
}
}
```
### 5.2 分布式事务处理
**5.2.1 分布式事务的概念和要求**
分布式事务是指跨越多个数据库系统的事务。与本地事务不同,分布式事务需要考虑以下要求:
* **原子性:**所有参与分布式事务的操作要么全部成功,要么全部失败。
* **一致性:**所有参与分布式事务的数据库系统必须保持一致的状态。
* **隔离性:**分布式事务与其他并发事务隔离,不会相互影响。
* **持久性:**分布式事务一旦提交,其结果必须持久化到所有参与的数据库系统中。
**5.2.2 实现分布式事务**
实现分布式事务可以使用以下方法:
* **两阶段提交(2PC):**一种协调分布式事务提交的协议,确保所有参与的数据库系统要么全部提交,要么全部回滚。
* **XA:**一种分布式事务标准,定义了分布式事务的接口和协议。
* **分布式数据库:**一种专门设计用于处理分布式事务的数据库系统,提供内置的事务协调机制。
**代码示例:**
```java
import javax.transaction.xa.XAConnection;
import javax.transaction.xa.XAResource;
import javax.transaction.xa.Xid;
public class DistributedTransaction {
public static void main(String[] args) throws Exception {
// 获取两个数据库系统的 XA 连接
XAConnection connection1 = ...;
XAConnection connection2 = ...;
// 创建分布式事务
Xid xid = ...;
// 获取两个数据库系统的 XAResource
XAResource resource1 = connection1.getXAResource();
XAResource resource2 = connection2.getXAResource();
// 启动分布式事务
resource1.start(xid, XAResource.TMNOFLAGS);
resource2.start(xid, XAResource.TMNOFLAGS);
// 执行分布式事务操作
// ...
// 准备分布式事务
int prepare1 = resource1.prepare(xid);
int prepare2 = resource2.prepare(xid);
// 提交分布式事务
if (prepare1 == XAResource.XA_OK && prepare2 == XAResource.XA_OK) {
resource1.commit(xid, false);
resource2.commit(xid, false);
} else {
resource1.rollback(xid);
resource2.rollback(xid);
}
// 关闭连接
connection1.close();
connection2.close();
}
}
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
Oracle跨数据库查询专栏深入探讨了分布式查询技术,从入门到精通,全面解析其内部机制、应用场景、优缺点、最佳实践、常见陷阱、性能调优、安全考虑、性能基准测试、监控和管理策略,以及在大数据分析中的应用。通过一系列文章,专栏提供了全面的指南,帮助读者掌握跨数据库查询的奥秘,提升查询性能和可靠性,避免常见错误,并充分利用其在大数据分析中的潜力。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
掌握tm包的文本分词与词频统计方法:文本挖掘的核心技能

# 1. 文本挖掘与文本分词的基础知识
文本挖掘是从大量文本数据中提取有用信息和知识的过程。它涉及自然语言
【Tau包在生物信息学中的应用】:基因数据分析的革新工具
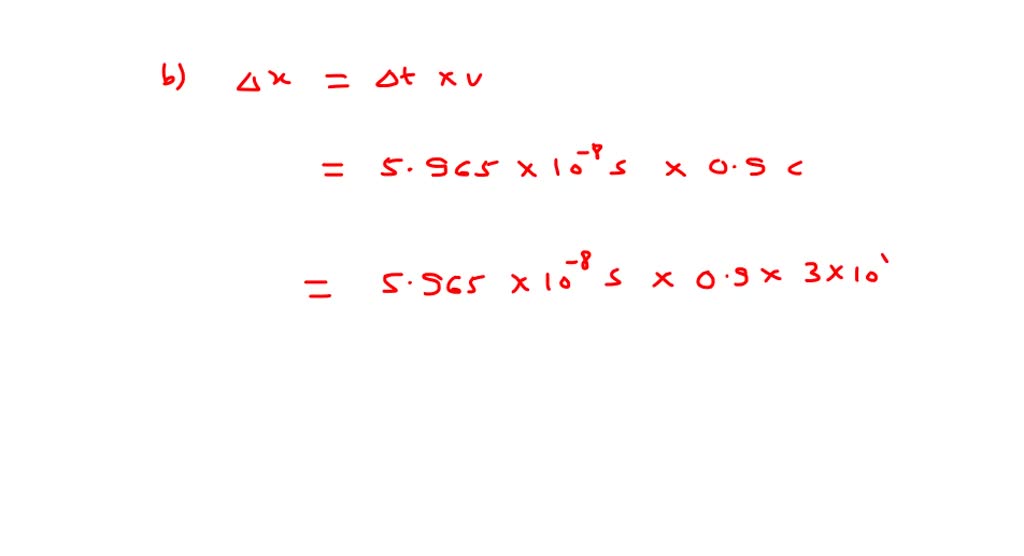
# 1. Tau包概述及其在生物信息学中的地位
生物信息学是一个多学科交叉领域,它汇集了生物学、计算机科学、数学等多个领域的知识,用以解析生物数据。Tau包作为该领域内的一套综合工具集,提供了从数据预处理到高级分析的广泛功能,致力于简化复杂的生物信息学工作流程。由于其强大的数据处理能力、友好的用户界面以及在基因表达和调控网络分析中的卓越表现,Tau包在专业研究者和生物技术公司中占据了举足轻重的地位。它不仅提高了分析
R语言数据包多语言集成指南:与其他编程语言的数据交互(语言桥)

# 1. R语言数据包的基本概念与集成需求
## R语言数据包简介
R语言作为统计分析领域的佼佼者,其数据包(也称作包或库)是其强大功能的核心所在。每个数据包包含特定的函数集合、数据集、编译代码等,专门用于解决特定问题。在进行数据分析工作之前,了解如何选择合适的数据包,并集成到R的
R语言与SQL数据库交互秘籍:数据查询与分析的高级技巧
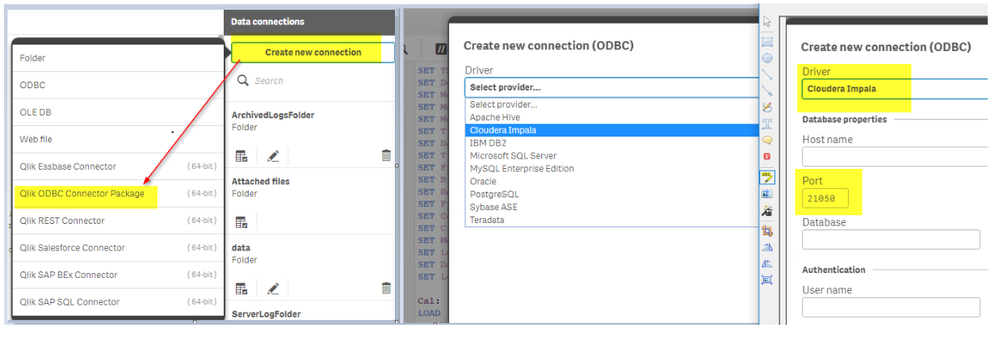
# 1. R语言与SQL数据库交互概述
在数据分析和数据科学领域,R语言与SQL数据库的交互是获取、处理和分析数据的重要环节。R语言擅长于统计分析、图形表示和数据处理,而SQL数据库则擅长存储和快速检索大量结构化数据。本章将概览R语言与SQL数据库交互的基础知识和应用场景,为读者搭建理解后续章节的框架。
## 1.
【R语言地理信息数据分析】:chinesemisc包的高级应用与技巧
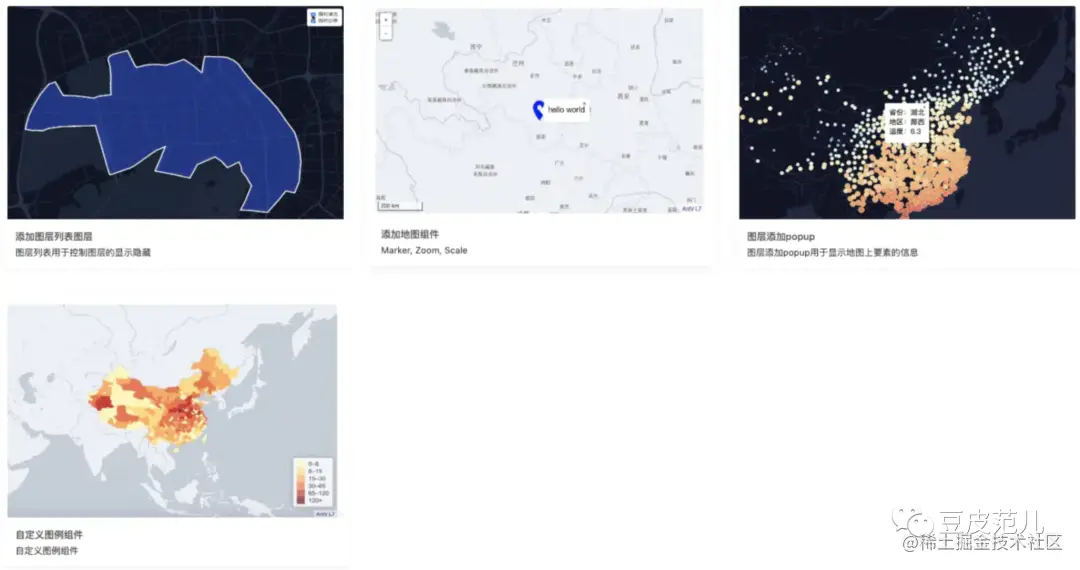
# 1. R语言与地理信息数据分析概述
R语言作为一种功能强大的编程语言和开源软件,非常适合于统计分析、数据挖掘、可视化以及地理信息数据的处理。它集成了众多的统计包和图形工具,为用户提供了一个灵活的工作环境以进行数据分析。地理信息数据分析是一个特定领域
R语言数据包安全使用指南:规避潜在风险的策略
# 1. R语言数据包基础知识
在R语言的世界里,数据包是构成整个生态系统的基本单元。它们为用户提供了一系列功能强大的工具和函数,用以执行统计分析、数据可视化、机器学习等复杂任务。理解数据包的基础知识是每个数据科学家和分析师的重要起点。本章旨在简明扼要地介绍R语言数据包的核心概念和基础知识,为
动态规划的R语言实现:solnp包的实用指南
# 1. 动态规划简介
## 1.1 动态规划的历史和概念
动态规划(Dynamic Programming,简称DP)是一种数学规划方法,由美国数学家理查德·贝尔曼(Richard Bellman)于20世纪50年代初提出。它用于求解多阶段决策过程问题,将复杂问题分解为一系列简单的子问题,通过解决子问题并存储其结果来避免重复计算,从而显著提高算法效率。DP适用于具有重叠子问题和最优子
【数据挖掘应用案例】:alabama包在挖掘中的关键角色

# 1. 数据挖掘简介与alabama包概述
## 1.1 数据挖掘的定义和重要性
数据挖掘是一个从大量数据中提取或“挖掘”知识的过程。它使用统计、模式识别、机器学习和逻辑编程等技术,以发现数据中的有意义的信息和模式。在当今信息丰富的世界中,数据挖掘已成为各种业务决策的关键支撑技术。有效地挖掘数据可以帮助企业发现未知的关系,预测未来趋势,优化
模型验证的艺术:使用R语言SolveLP包进行模型评估
# 1. 线性规划与模型验证简介
## 1.1 线性规划的定义和重要性
线性规划是一种数学方法,用于在一系列线性不等式约束条件下,找到线性目标函数的最大值或最小值。它在资源分配、生产调度、物流和投资组合优化等众多领域中发挥着关键作用。
```mermaid
flowchart LR
A[问题定义] --> B[建立目标函数]
B --> C[确定约束条件]
C --> D[
质量控制中的Rsolnp应用:流程分析与改进的策略

# 1. 质量控制的基本概念
## 1.1 质量控制的定义与重要性
质量控制(Quality Control, QC)是确保产品或服务质量
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )