揭秘Oracle跨数据库查询的内部机制:分布式查询的底层原理
发布时间: 2024-08-03 14:04:22 阅读量: 23 订阅数: 36 

Oracle 跨库 查询 复制表数据 分布式查询介绍
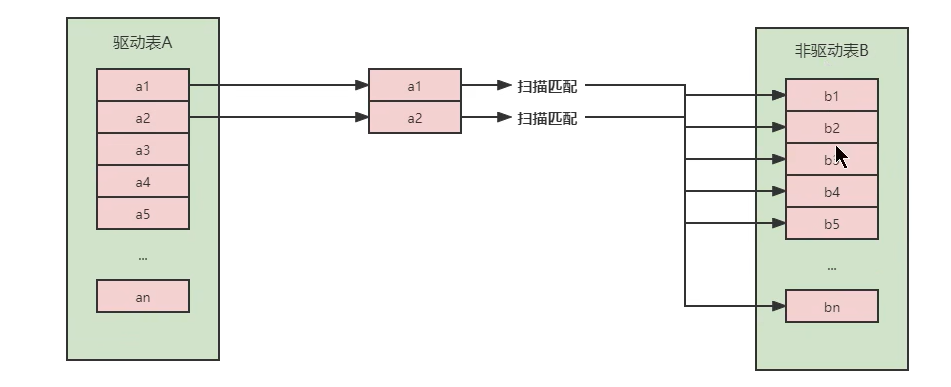
# 1. Oracle分布式查询概述**
Oracle分布式查询是一种跨越多个数据库实例的查询技术,允许用户访问和操作分布在不同数据库中的数据。它通过分布式链接和数据库网关实现,为用户提供了跨数据库查询和更新的能力。
分布式查询的优势包括:
* **数据整合:**允许用户访问和查询分布在不同数据库中的数据,消除数据孤岛问题。
* **数据共享:**促进不同数据库之间的数据共享,提高数据利用率。
* **灵活性和可扩展性:**支持在不断变化的IT环境中添加或删除数据库实例,提高系统的灵活性和可扩展性。
# 2. 分布式查询的理论基础
### 2.1 分布式数据库的概念和架构
**2.1.1 分布式数据库的定义和特点**
分布式数据库是一种数据库管理系统,它将数据分布在多个物理位置,并允许用户透明地访问这些数据。与集中式数据库不同,分布式数据库具有以下特点:
* **数据分布:** 数据存储在多个物理位置,可以是不同的服务器、存储设备或云平台。
* **透明性:** 用户可以无感知地访问分布式数据库中的数据,就像访问集中式数据库一样。
* **可扩展性:** 分布式数据库可以通过添加或删除节点来轻松扩展,以满足不断增长的数据需求。
* **高可用性:** 分布式数据库通常具有冗余和故障转移机制,以确保数据的可用性,即使发生故障。
**2.1.2 分布式数据库的架构和组件**
分布式数据库通常采用以下架构:
* **客户端:** 发出查询并接收结果的应用程序或用户。
* **数据库服务器:** 存储和管理数据的物理节点。
* **协调器:** 协调查询执行和结果合并的中央组件。
* **数据字典:** 存储有关数据库架构和数据分布的信息。
* **网络:** 连接不同组件并传输查询和数据的通信基础设施。
### 2.2 分布式查询的处理流程
**2.2.1 查询解析和优化**
当用户发出分布式查询时,协调器首先对其进行解析和优化。解析过程将查询转换为内部表示,而优化过程则确定最有效的查询执行计划。优化器考虑以下因素:
* **数据分布:** 确定查询涉及哪些数据节点。
* **网络延迟:** 估计不同节点之间的通信成本。
* **数据量:** 估计不同节点上数据的规模。
* **查询复杂度:** 分析查询的复杂性,例如连接、聚合和排序操作。
**2.2.2 查询执行和结果合并**
优化后,协调器将查询执行计划分发给相关的数据库服务器。每个服务器执行其部分查询,并将其结果返回给协调器。协调器负责合并这些结果并将其返回给客户端。
**代码块:**
```sql
SELECT * FROM customers@remote_db
WHERE state = 'CA';
```
**逻辑分析:**
此查询从名为 `remote_db` 的分布式数据库中检索 `customers` 表中位于加利福尼亚州 (`CA`) 的所有客户记录。
**参数说明:**
* `remote_db`:分布式数据库的名称。
* `customers`:要查询的表。
* `state`:要筛选的列。
* `CA`:要筛选的值。
**流程图:**
```mermaid
graph LR
subgraph 查询解析和优化
A[解析查询] --> B[优化查询]
end
subgraph 查询执行和结果合并
C[分发查询计划] --> D[执行查询] --> E[合并结果]
end
A --> C
E --> B
```
# 3. Oracle分布式查询的实现
### 3.1 分布式链接和数据库网关
#### 3.1.1 分布式链接的创建和管理
分布式链接是Oracle中用于连接远程数据库的对象。它允许用户访问和查询远程数据库中的数据,就好像它们是本地数据库的一部分。
**创建分布式链接**
```sql
CREATE DATABASE LINK link_name CONNECT TO remote_user IDENTIFIED BY remote_password USING 'remote_database_name';
```
**参数说明:**
- `link_name`: 分布式链接的名称。
- `remote_user`: 远程数据库的用户名。
- `remote_password`: 远程数据库的密码。
- `remote_database_name`: 远程数据库的名称。
**管理分布式链接**
- **查看分布式链接:**
```sql
SELECT * FROM dba_db_links;
```
- **修改分布式链接:**
```sql
ALTER DATABASE LINK link_name SET ATTRIBUTE = value;
```
- **删除分布式链接:**
```sql
DROP DATABASE LINK link_name;
```
#### 3.1.2 数据库网关的配置和使用
数据库网关是Oracle中的一个组件,它充当分布式查询的中间层。它管理与远程数据库的连接,并优化查询执行。
**配置数据库网关**
1. 创建一个网关服务:
```sql
CREATE SERVICE gateway_name TYPE SERVICE_TYPE;
```
2. 配置网关参数:
```sql
ALTER SERVICE gateway_name SET PARAMETER = value;
```
**使用数据库网关**
在查询中使用`@`符号指定网关:
```sql
SELECT * FROM remote_table@gateway_name;
```
**参数说明:**
- `remote_table`: 远程数据库中的表名。
- `gateway_name`: 用于连接远程数据库的网关名称。
### 3.2 查询优化和执行计划
#### 3.2.1 分布式查询的优化策略
Oracle使用以下策略来优化分布式查询:
- **查询重写:**将分布式查询转换为等效的本地查询,以减少对远程数据库的访问。
- **并行执行:**将查询分解为多个并行任务,在多个远程数据库上同时执行。
- **数据分区:**将数据分区存储在不同的远程数据库中,以优化对特定数据的访问。
#### 3.2.2 查询执行计划的生成和分析
Oracle生成一个执行计划来描述查询的执行方式。对于分布式查询,执行计划包括以下步骤:
1. **解析查询:**将查询解析成内部表示。
2. **优化查询:**应用优化策略来生成最优的执行计划。
3. **生成执行计划:**创建详细的执行计划,指定查询的执行步骤。
4. **执行查询:**根据执行计划执行查询。
**分析执行计划**
```sql
EXPLAIN PLAN FOR query;
```
**执行计划示例:**
```
# 4. 分布式查询的实践应用
### 4.1 跨数据库数据查询和更新
#### 4.1.1 跨数据库数据查询的语法和示例
跨数据库数据查询允许从多个分布式数据库中检索数据。Oracle提供了`REMOTE`关键字来实现跨数据库查询。语法如下:
```sql
SELECT * FROM REMOTE.schema_name.table_name@database_link;
```
其中:
* `REMOTE`关键字表示远程数据库
* `schema_name`是远程数据库中的模式名称
* `table_name`是远程数据库中的表名称
* `database_link`是连接到远程数据库的数据库链接名称
**示例:**
从`db1`数据库查询`db2`数据库中`sales`表的数据:
```sql
SELECT * FROM REMOTE.sales@db2_link;
```
#### 4.1.2 跨数据库数据更新的语法和注意事项
跨数据库数据更新允许在分布式数据库中更新数据。Oracle提供了`UPDATE`和`DELETE`语句的`REMOTE`版本来实现跨数据库更新。语法如下:
```sql
UPDATE REMOTE.schema_name.table_name@database_link
SET column_name = value
WHERE condition;
DELETE FROM REMOTE.schema_name.table_name@database_link
WHERE condition;
```
**注意事项:**
* 跨数据库更新需要在远程数据库中具有足够的权限。
* 远程数据库必须启用`Distributed Update`选项。
* 更新操作可能需要提交分布式事务。
### 4.2 分布式事务管理
#### 4.2.1 分布式事务的概念和特性
分布式事务是指跨越多个分布式数据库的单个逻辑操作。它具有以下特性:
* **原子性:**所有参与数据库要么全部提交,要么全部回滚。
* **一致性:**所有参与数据库中的数据保持一致。
* **隔离性:**分布式事务与其他事务隔离。
* **持久性:**一旦提交,分布式事务对所有参与数据库都是永久性的。
#### 4.2.2 Oracle分布式事务的实现和管理
Oracle使用`XA`(扩展架构)标准来实现分布式事务。XA事务管理器协调参与数据库中的事务。
**实现分布式事务的步骤:**
1. 创建分布式数据库链接。
2. 在参与数据库中启用`Distributed Update`选项。
3. 使用`BEGIN DISTRIBUTED TRANSACTION`语句开始分布式事务。
4. 在参与数据库中执行更新操作。
5. 使用`COMMIT DISTRIBUTED TRANSACTION`语句提交分布式事务。
**管理分布式事务:**
Oracle提供了`DBMS_TRANSACTION`包来管理分布式事务。它提供以下功能:
* 查询分布式事务的状态
* 提交或回滚分布式事务
* 获取参与分布式事务的数据库列表
# 5. 分布式查询的性能优化
### 5.1 分布式查询性能影响因素
分布式查询的性能受到多种因素的影响,主要包括:
- **网络延迟和带宽:**跨数据库查询涉及网络通信,网络延迟和带宽会直接影响查询性能。高延迟和低带宽会增加查询执行时间。
- **数据量和查询复杂度:**查询涉及的数据量和复杂度也会影响性能。大量数据和复杂的查询会增加查询处理时间。
### 5.2 分布式查询性能优化策略
为了优化分布式查询的性能,可以采取以下策略:
#### 5.2.1 优化查询语句和执行计划
- **使用索引:**在查询涉及的表上创建索引可以显著提高查询速度。
- **优化查询条件:**使用等值条件和范围条件代替通配符条件。
- **减少查询返回的数据量:**使用 `LIMIT` 子句限制查询返回的行数。
- **分析执行计划:**使用 `EXPLAIN PLAN` 语句分析查询的执行计划,并根据分析结果进行优化。
#### 5.2.2 优化网络连接和数据传输
- **使用高速网络连接:**确保跨数据库查询的网络连接速度足够快。
- **使用数据库网关:**使用数据库网关可以减少网络通信开销,提高查询性能。
- **压缩数据传输:**使用压缩算法压缩数据传输,减少网络带宽占用。
- **使用并行查询:**如果查询涉及大量数据,可以考虑使用并行查询来提高性能。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
Oracle跨数据库查询专栏深入探讨了分布式查询技术,从入门到精通,全面解析其内部机制、应用场景、优缺点、最佳实践、常见陷阱、性能调优、安全考虑、性能基准测试、监控和管理策略,以及在大数据分析中的应用。通过一系列文章,专栏提供了全面的指南,帮助读者掌握跨数据库查询的奥秘,提升查询性能和可靠性,避免常见错误,并充分利用其在大数据分析中的潜力。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Android应用中的MAX30100集成完全手册:一步步带你上手
# 摘要
本文综合介绍了MAX30100传感器的搭建和应用,涵盖了从基础硬件环境的搭建到高级应用和性能优化的全过程。首先概述了MAX30100的工作原理及其主要特性,然后详细阐述了如何集成到Arduino或Raspberry Pi等开发板,并搭建相应的硬件环境。文章进一步介绍了软件环境的配置,包括Arduino IDE的安装、依赖库的集成和MAX30100库的使用。接着,通过编程实践展示了MAX30100的基本操作和高级功能的开发,包括心率和血氧饱和度测量以及与Android设备的数据传输。最后,文章探讨了MAX30100在Android应用中的界面设计、功能拓展和性能优化,并通过实际案例分析
【AI高手】:掌握这些技巧,A*算法解决8数码问题游刃有余
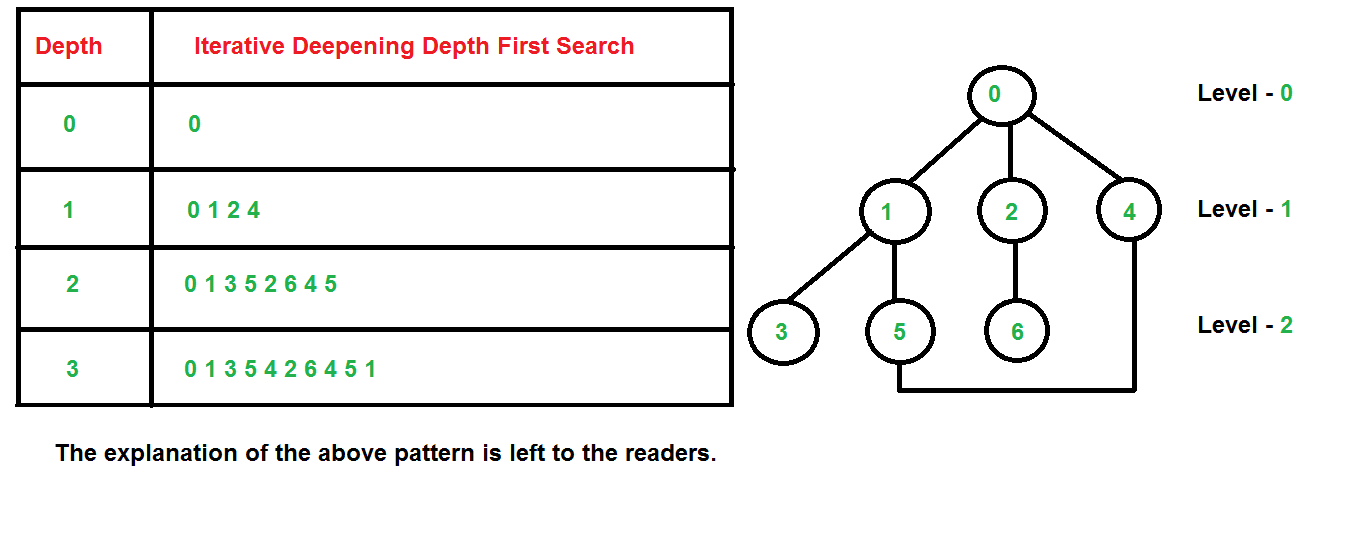
# 摘要
A*算法是计算机科学中广泛使用的一种启发式搜索算法,尤其在路径查找和问题求解领域表现出色。本文首先概述了A*算法的基本概念,随后深入探讨了其理论基础,包括搜索算法的分类和评价指标,启发式搜索的原理以及评估函数的设计。通过结合著名的8数码问题,文章详细介绍了A*算法的实际操作流程、编码前的准备、实现步骤以及优化策略。在应用实例部分,文章通过具体问题的实例化和算法的实现细节,提供了深入的案例分析和问题解决方法。最后,本文展望
【硬件软件接口艺术】:掌握提升系统协同效率的关键策略
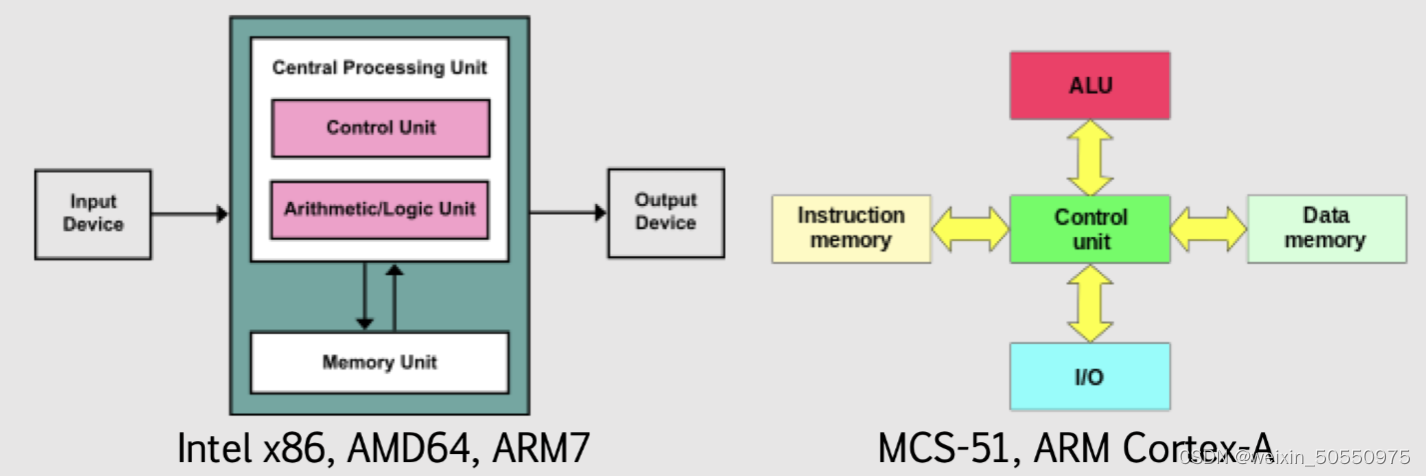
# 摘要
硬件与软件接口是现代计算系统的核心,它决定了系统各组件间的通信效率和协同工作能力。本文首先概述了硬件与软件接口的基本概念和通信机制,深入探讨了硬件通信接口标准的发展和主流技术的对比。接着,文章分析了软件接口的抽象层次,包括系统调用、API以及驱动程序的作用。此外,本文还详细介绍了同步与异步处理机制的原理和实践。在探讨提升系统协同效率的关键技术方面,文中阐述了缓存机制优化、多线程与并行处理,以及
PFC 5.0二次开发宝典:API接口使用与自定义扩展
# 摘要
本文深入探讨了PFC 5.0的技术细节、自定义扩展的指南以及二次开发的实践技巧。首先,概述了PFC 5.0的基础知识和标准API接口,接着详细分析了AP
【台达VFD-B变频器与PLC通信集成】:构建高效自动化系统的不二法门

# 摘要
本文综合介绍了台达VFD-B变频器与PLC通信的关键技术,涵盖了通信协议基础、变频器设置、PLC通信程序设计、实际应用调试以及高级功能集成等各个方面。通过深入探讨通信协议的基本理论,本文阐述了如何设置台达VFD-B变频器以实现与PLC的有效通信,并提出了多种调试技巧与参数优化策略,以解决实际应用中的常见问题。此外,本文
【ASM配置挑战全解析】:盈高经验分享与解决方案

# 摘要
自动存储管理(ASM)作为数据库管理员优化存储解决方案的核心技术,能够提供灵活性、扩展性和高可用性。本文深入介绍了ASM的架构、存储选项、配置要点、高级技术、实践操作以及自动化配置工具。通过探讨ASM的基础理论、常见配置问题、性能优化、故障排查以及与RAC环境的集成,本文旨在为数据库管理员提供全面的配置指导和操作建议。文章还分析了ASM在云环境中的应用前景、社区资源和
【自行车码表耐候性设计】:STM32硬件防护与环境适应性提升

# 摘要
本文详细探讨了自行车码表的设计原理、耐候性设计实践及软硬件防护机制。首先介绍自行车码表的基本工作原理和设计要求,随后深入分析STM32微控制器的硬件防护基础。接着,通过研究环境因素对自行车码表性能的影响,提出了相应的耐候性设计方案,并通过实验室测试和现场实验验证了设计的有效性。文章还着重讨论了软件防护机制,包括设计原则和实现方法,并探讨了软硬件协同防护
STM32的电源管理:打造高效节能系统设计秘籍
# 摘要
随着嵌入式系统在物联网和便携设备中的广泛应用,STM32微控制器的电源管理成为提高能效和延长电池寿命的关键技术。本文对STM32电源管理进行了全面的概述,从理论基础到实践技巧,再到高级应用的探讨。首先介绍了电源管理的基本需求和电源架构,接着深入分析了动态电压调节技术、电源模式和转换机制等管理策略,并探讨了低功耗模式的实现方法。进一步地,本文详细阐述了软件工具和编程技
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )