揭秘跨库查询难题:SQL多数据库查询,打破数据孤岛
发布时间: 2024-07-30 21:29:25 阅读量: 25 订阅数: 22 
# 1. 跨库查询概述**
跨库查询是指在多个独立的数据库系统中同时执行查询,以获取跨越这些数据库的数据。它是一种强大的技术,可以解决许多数据管理问题,例如:
* **数据整合:**将来自不同来源的数据组合到一个统一的视图中,以便进行分析和报告。
* **数据联邦:**允许用户访问和查询分布在不同位置和平台上的数据,而无需物理整合这些数据。
* **数据迁移:**在不同的数据库系统之间移动数据,以满足性能、可用性和成本要求。
# 2. 跨库查询的技术实现
跨库查询涉及多种技术,包括分布式数据库技术和数据库联合查询技术。
### 2.1 分布式数据库技术
分布式数据库是一种将数据存储在多个物理位置的数据库系统。它通过将数据分布在多个节点上,实现数据的弹性扩展、高可用性和容灾能力。
#### 2.1.1 分布式数据库的架构和原理
分布式数据库的架构通常采用主从复制或分片复制的方式。主从复制是指将数据复制到多个从节点,以提高读性能和容灾能力。分片复制是指将数据表水平划分为多个分片,并分布在不同的节点上,以实现数据的弹性扩展。
#### 2.1.2 分布式事务处理
分布式事务处理是分布式数据库中一个重要的挑战。为了保证事务的原子性、一致性、隔离性和持久性(ACID),分布式数据库通常采用两阶段提交(2PC)协议或三阶段提交(3PC)协议。
### 2.2 数据库联合查询技术
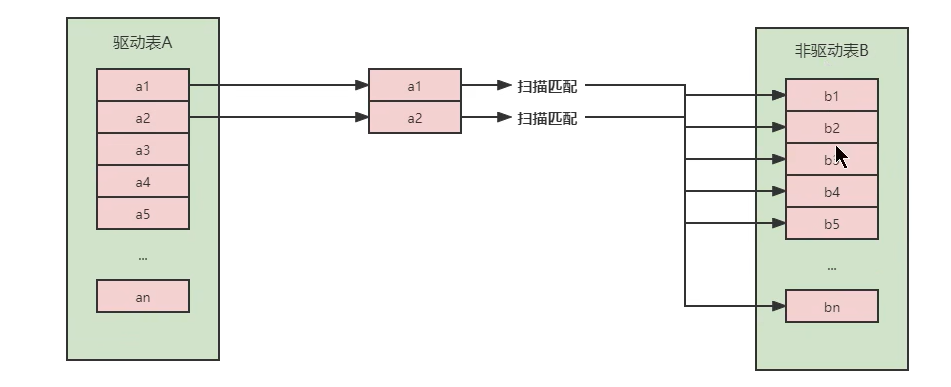
数据库联合查询技术允许从多个异构数据库中查询数据。它通过建立数据库之间的连接,将查询发送到不同的数据库,并整合查询结果。
#### 2.2.1 联合查询的原理和实现
联合查询的原理是将查询分解为多个子查询,并分别发送到不同的数据库执行。这些子查询的结果通过一个中间层进行整合,形成最终的查询结果。
#### 2.2.2 联合查询的优化策略
为了优化联合查询的性能,可以采用以下策略:
- **查询重写:**将联合查询重写为等价的子查询,以减少网络开销。
- **并行查询:**将子查询并行执行,以提高查询速度。
- **数据分区:**将数据表分区,并根据查询条件选择需要查询的分区,以减少数据传输量。
**代码块 1:联合查询示例**
```sql
SELECT *
FROM table1@db1
JOIN table2@db2
ON table1.id = table2.id;
```
**逻辑分析:**
此查询从数据库 db1 中的 table1 和数据库 db2 中的 table2 中查询数据。JOIN 语句将两个表根据 id 列连接起来。
**参数说明:**
- `table1@db1`:数据库 db1 中的 table1 表
- `table2@db2`:数据库 db2 中的 table2 表
- `id`:连接两个表的列名
# 3.1 异构数据库的跨库查询
#### 3.1.1 异构数据库的连接和数据转换
异构数据库的跨库查询涉及到不同数据库系统之间的连接和数据转换。连接异构数据库需要使用特定的连接器或中间件,如 ODBC、JDBC 或第三方工具。这些连接器负责建立数据库之间的通信通道,并提供统一的数据访问接口。
数据转换是异构数据库跨库查询的另一个重要方面。不同数据库系统使用不同的数据类型、编码和存储格式。为了实现跨库查询,需要将数据从一种格式转换到另一种格式。数据转换可以通过连接器或中间件自动完成,也可以通过编写自定义转换函数或使用转换工具手动完成。
#### 3.1.2 异构数据库的联合查询实例
下面是一个异构数据库联合查询的示例,其中查询来自两个不同的数据库系统:
```sql
SELECT *
FROM OracleDB.table1
INNER JOIN MySQLDB.table2
ON OracleDB.table1.id = MySQLDB.table2.id;
```
在这个示例中,`OracleDB` 和 `MySQLDB` 是两个不同的数据库系统。`table1` 和 `table2` 是这两个数据库中的两个表。连接条件是 `OracleDB.table1.id` 和 `MySQLDB.table2.id` 相等。
为了执行这个查询,需要使用一个连接器或中间件来连接两个数据库系统。连接器将负责建立通信通道,并提供统一的数据访问接口。连接器还将负责转换数据,以确保两个数据库系统之间的数据兼容。
### 3.2 云数据库的跨库查询
#### 3.2.1 云数据库的跨库查询服务
云数据库服务提供商通常提供跨库查询服务,允许用户在不同的云数据库之间进行查询。这些服务通常基于分布式数据库技术或数据库联合查询技术。
例如,AWS 提供了 Aurora Global Database 服务,它允许用户跨多个可用区和区域查询 Aurora 数据库集群。Azure 提供了 Cosmos DB 服务,它允许用户跨多个 Azure 区域查询 NoSQL 数据库。
#### 3.2.2 云数据库的跨库查询案例
下面是一个云数据库跨库查询的示例,其中查询来自两个不同的云数据库服务:
```sql
SELECT *
FROM AWS_Aurora.table1
INNER JOIN Azure_CosmosDB.table2
ON AWS_Aurora.table1.id = Azure_CosmosDB.table2.id;
```
在这个示例中,`AWS_Aurora` 和 `Azure_CosmosDB` 是两个不同的云数据库服务。`table1` 和 `table2` 是这两个服务中的两个表。连接条件是 `AWS_Aurora.table1.id` 和 `Azure_CosmosDB.table2.id` 相等。
为了执行这个查询,需要使用云数据库服务提供商提供的跨库查询服务。该服务将负责建立通信通道,并提供统一的数据访问接口。该服务还将负责转换数据,以确保两个云数据库服务之间的数据兼容。
# 4.1 查询计划优化
跨库查询的性能优化至关重要,查询计划优化是其中一个关键环节。查询计划优化是指分析和改进查询计划,以提高查询执行效率。
### 4.1.1 查询计划的分析和优化
查询计划分析和优化是一个复杂的过程,涉及以下步骤:
1. **获取查询计划:**使用 EXPLAIN 或类似命令获取查询的执行计划。
2. **分析计划:**检查计划中的操作符、连接类型和数据访问模式,找出性能瓶颈。
3. **优化计划:**根据分析结果,采用适当的优化策略,例如:
- **重写查询:**修改查询以使用更优化的语法或结构。
- **添加索引:**在适当的列上创建索引,以加快数据访问。
- **使用分区:**将数据按特定条件分区,以减少需要扫描的数据量。
- **优化连接:**选择最合适的连接类型,例如 INNER JOIN 或 LEFT JOIN。
- **利用缓存:**利用数据库缓存机制,减少重复查询的执行时间。
### 4.1.2 索引和分区的使用
索引和分区是提高跨库查询性能的有效技术。
**索引**通过在表列上创建附加结构,加快数据访问速度。索引可以根据特定列或列组合对数据进行排序,从而减少需要扫描的数据量。
**分区**将表中的数据按特定条件(例如日期范围或地理位置)划分为多个子集。分区可以缩小查询扫描的数据范围,从而提高性能。
### 代码示例
以下代码示例演示了如何使用索引优化跨库查询:
```sql
-- 创建索引
CREATE INDEX idx_name ON table_name (column_name);
-- 使用索引的查询
SELECT * FROM table_name WHERE column_name = 'value'
```
逻辑分析:
* 创建索引 idx_name,在 table_name 表的 column_name 列上创建索引。
* 使用 WHERE 子句过滤数据,并利用索引快速查找满足条件的行。
### 表格示例
下表总结了查询计划优化策略:
| 策略 | 描述 |
|---|---|
| 重写查询 | 修改查询以使用更优化的语法或结构。 |
| 添加索引 | 在适当的列上创建索引,以加快数据访问。 |
| 使用分区 | 将数据按特定条件分区,以减少需要扫描的数据量。 |
| 优化连接 | 选择最合适的连接类型,例如 INNER JOIN 或 LEFT JOIN。 |
| 利用缓存 | 利用数据库缓存机制,减少重复查询的执行时间。 |
# 5.1 新兴技术对跨库查询的影响
### 5.1.1 大数据和人工智能
大数据和人工智能的兴起对跨库查询带来了新的挑战和机遇。
**挑战:**
- **数据量激增:**大数据时代,数据量呈爆炸式增长,跨库查询需要处理海量数据,这给查询性能带来了极大的压力。
- **数据异构性:**大数据场景下,数据往往来自不同的来源,具有不同的格式和结构,跨库查询需要应对异构数据的兼容性问题。
- **复杂查询需求:**人工智能应用对数据分析提出了更高的要求,需要进行复杂的多表关联查询,这给跨库查询的优化带来了难度。
**机遇:**
- **大数据处理技术:**大数据处理技术,如 Hadoop 和 Spark,提供了分布式计算和数据存储能力,可以有效处理海量数据,为跨库查询提供基础设施支持。
- **人工智能算法:**人工智能算法,如机器学习和自然语言处理,可以帮助优化跨库查询计划,提高查询效率。
- **智能数据管理:**智能数据管理工具可以自动发现和管理数据,简化跨库查询的数据集成和转换过程。
### 5.1.2 无服务器架构
无服务器架构是一种云计算模型,它允许开发人员构建和部署应用程序,而无需管理底层服务器基础设施。无服务器架构对跨库查询的影响主要体现在以下方面:
**优势:**
- **弹性扩展:**无服务器架构可以根据实际负载自动扩展,满足跨库查询对资源的弹性需求。
- **成本优化:**无服务器架构按需计费,仅在应用程序运行时才产生费用,可以有效降低跨库查询的成本。
- **简化开发:**无服务器架构屏蔽了底层服务器管理的复杂性,简化了跨库查询应用程序的开发和部署。
**挑战:**
- **延迟问题:**无服务器架构中的冷启动问题可能会导致跨库查询的延迟,需要优化代码和使用预热机制来缓解。
- **数据安全性:**无服务器架构中的数据安全性需要额外关注,需要采用适当的加密和访问控制措施。
- **供应商锁定:**无服务器架构通常与特定的云平台绑定,可能会限制跨库查询应用程序的跨平台移植性。
 最低0.47元/天 解锁专栏
最低0.47元/天 解锁专栏 送3个月
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了多数据库管理的方方面面,提供了一系列实用秘诀和最佳实践,帮助您轻松驾驭不同数据库,提升数据管理效率。从跨库查询到性能优化,再到异构数据库集成,专栏涵盖了多数据库管理的各个方面。此外,还重点介绍了数据一致性、安全性和故障排除等关键主题,确保您能够安全有效地管理多数据库系统。通过遵循本专栏的指导,您可以打破数据孤岛,挖掘多数据库的性能潜力,并建立一个高可用、可扩展且安全的数据库环境。
专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Setting the Limits of Matlab Coordinate Axis Gridlines: Avoiding Too Many or Too Few, Optimizing Data Visualization
# 1. Basic Concepts of Matlab Coordinate Axis Gridlines
Coordinate axis gridlines are indispensable elements in Matlab plotting, aiding us in clearly understanding and interpreting data. Matlab offers a plethora of gridline settings, allowing us to customize the appearance and positioning of gridli
【Advanced】Using MATLAB to Implement Long Short-Term Memory (LSTM) Networks for Classification and Regression Problems
# 2.1 LSTM Network Architecture and Algorithm
### 2.1.1 Composition and Principle of LSTM Units
Long Short-Term Memory (LSTM) is a type of Recurrent Neural Network (RNN) designed specifically for handling sequential data. An LSTM unit consists of an input gate, a forget gate, an output gate, and a
MATLAB's strtok Function: Splitting Strings with Delimiters for More Precise Text Parsing
# Chapter 1: Overview of String Operations in MATLAB
MATLAB offers a rich set of functions for string manipulation, among which the `strtok` function stands out as a powerful tool for delimiter-driven string splitting. This chapter will introduce the basic syntax, usage, and return results of the `
【选择排序的高效实现】:顺序表排序的优化方案大公开
# 1. 选择排序算法基础
选择排序是一种简单直观的排序算法,它的工作原理是每次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,直到全部待排序的数据元素排完。选择排序是不稳定的排序方法,因为当存在相同数据值时,相对位置可能会发生变化。
## 1.1 算法描述
选择排序的基本思想是:
1. 首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置。
2. 然后,
【可扩展哈希表构建】:编程实战,构建一个适应未来需求的哈希表
# 1. 可扩展哈希表的基本概念和原理
在信息存储与检索领域,哈希表是最基本且广泛应用的数据结构之一。它通过哈希函数将键映射到表中的位置,以实现快速的数据访问。本章将概述可扩展哈希表的核心概念,包括其基本原理和如何高效地实现快速键值对的映射。
## 1.1 哈希表的定义及其优势
哈希表是一种通过哈希函数进行数据存储的数据结构,它能够实现平均情况下常数时间复杂度(O(1))的查找、插
MATLAB Reading Financial Data from TXT Files: Financial Data Processing Expert, Easily Read Financial Data
# Mastering Financial Data Handling in MATLAB: A Comprehensive Guide to Processing Financial Data
## 1. Overview of Financial Data
Financial data pertains to information related to financial markets and activities, encompassing stock prices, foreign exchange rates, economic indicators, and more. S
The Industry Impact of YOLOv10: Driving the Advancement of Object Detection Technology and Leading the New Revolution in Artificial Intelligence
# 1. Overview and Theoretical Foundation of YOLOv10
YOLOv10 is a groundbreaking algorithm in the field of object detection, released by Ultralytics in 2023. It integrates computer vision, deep learning, and machine learning technologies, achieving outstanding performance in object detection tasks.
Kafka Message Queue Hands-On: From Beginner to Expert
# Kafka Message Queue Practical: From Beginner to Expert
## 1. Overview of Kafka Message Queue
Kafka is a distributed streaming platform designed for building real-time data pipelines and applications. It offers a high-throughput, low-latency messaging queue capable of handling vast amounts of dat
堆排序与数据压缩:压缩算法中的数据结构应用,提升效率与性能

# 1. 堆排序原理与实现
## 1.1 堆排序的基本概念
堆排序是一种基于比较的排序算法,它利用堆这种数据结构的特性来进行排序。堆是一个近似完全二叉树的结
Application of Matrix Transposition in Bioinformatics: A Powerful Tool for Analyzing Gene Sequences and Protein Structures
# 1. Theoretical Foundations of Transposed Matrices
A transposed matrix is a special kind of matrix in which elements are symmetrically distributed along the main diagonal. It has extensive applications in mathematics and computer science, especially in the field of bioinformatics.
The mathematica
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )