The Industry Impact of YOLOv10: Driving the Advancement of Object Detection Technology and Leading the New Revolution in Artificial Intelligence
发布时间: 2024-09-13 20:50:35 阅读量: 32 订阅数: 43 

Committee on Adolescence, Group for the Advancement of Psychiatry. Normal Adolescence. Its Dynamics and Impact. New York : Charles Scribner's Sons, 1968, 127 p., [dollar]3.95
# 1. Overview and Theoretical Foundation of YOLOv10
YOLOv10 is a groundbreaking algorithm in the field of object detection, released by Ultralytics in 2023. It integrates computer vision, deep learning, and machine learning technologies, achieving outstanding performance in object detection tasks.
### 1.1 Overview of YOLOv10
YOLOv10 is a single-stage object detection algorithm, meaning it can predict the location and category of objects in one forward pass. Unlike other multi-stage algorithms, YOLOv10 does not require Region Proposal Networks (RPN) or other post-processing steps, significantly improving inference speed.
### 1.2 Theoretical Foundation of YOLOv10
YOLOv10 is based on Convolutional Neural Networks (CNN), utilizing an innovative network architecture known as Cross-Stage Partial Connections (CSP). CSP enhances the efficiency and accuracy of the model by reducing redundant connections in the network. Moreover, YOLOv10 employs a Spatial Attention Module (SAM), which further improves model performance by focusing on interesting areas of the image.
# 2. YOLOv10 Model Architecture and Algorithmic Innovations
### 2.1 YOLOv10 Network Structure
YOLOv10's network structure continues the overall concept of the YOLO series, employing a single-stage object detection framework. Its network structure mainly consists of the following parts:
- **Backbone Network:** YOLOv10 uses CSPDarknet53 as its backbone network, which maintains strong feature extraction capabilities while being computationally efficient. CSPDarknet53 consists of multiple CSP modules, each containing a residual block and a spatial pyramid pooling module, effectively extracting features at different scales.
- **Neck Network:** YOLOv10 adopts FPN (Feature Pyramid Network) as the Neck network, which can fuse features of different scales, thereby enhancing the model's ability to detect objects of various sizes. FPN consists of multiple convolutional layers and upsampling layers, fusing high-level and low-level features to form feature maps with different receptive fields and semantic information.
- **Detection Head:** YOLOv10's detection head employs an Anchor-Free design, directly predicting the center points, sizes, and categories of objects. The detection head consists of multiple convolutional and fully connected layers, transforming the information in the feature maps into object detection results.
### 2.2 YOLOv10 Loss Function and Training Strategy
The loss function of YOLOv10 consists of the following parts:
- **Localization Loss:**采用了GIOU损失函数,可以更好地衡量预测框与真实框之间的重叠程度,提高模型的定位精度。
- **Classification Loss:**采用了交叉熵损失函数,可以衡量预测类别与真实类别的差异,提高模型的分类精度。
- **Confidence Loss:**采用了二元交叉熵损失函数,可以衡量预测置信度与真实置信度之间的差异,提高模型对目标的检测能力。
YOLOv10的训练策略采用以下优化技术:
- **自适应学习率调整:**采用了余弦退火学习率调整策略,可以动态调整学习率,提高模型的训练效率。
- **数据增强:**采用多种数据增强技术,如随机裁剪、翻转、旋转等,增加训练数据的多样性,提高模型的泛化能力。
- **梯度累积:**采用梯度累积技术,可以将多个batch的梯度累积起来再进行更新,提高模型的稳定性。
# 3.1 YOLOv10 in Object Detection Tasks
As a powerful object detection algorithm, YOLOv10 demonstrates outstanding performance in practical applications. It is widely used in various object detection tasks, including:
- **Image Classification:** YOLOv10 can classify objects in images into predefined categories, such as pedestrians, vehicles, animals, etc.
- **Object Detection:** YOLOv10 can detect objects in images and provide bounding boxes and category labels for each object.
- **Real-time Object Tracking:** YOLOv10 can track objects in images in real-time, even if the objects move or are occluded.
- **Video Analysis:** YOLOv10 can analyze video streams, detecting and tracking objects in videos.
- **Autonomous Driving:** YOLOv10 can detect pedestrians, vehicles, and other obstacles on the road, providing critical information for autonomous driving systems.
### 3.1.1 Image Classification
YOLOv10 can classify objects in images into predefined categories. It uses a pre-trained classification network as a feature extractor and then inputs the extracted features into a fully connected layer for classification. YOLOv10's classification accuracy is very high, reaching 93.5% accuracy on the ImageNet dataset.
### 3.1.2 Object Detection
YOLOv10 can detect objects in images and

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
永磁同步电机控制策略仿真:MATLAB_Simulink实现
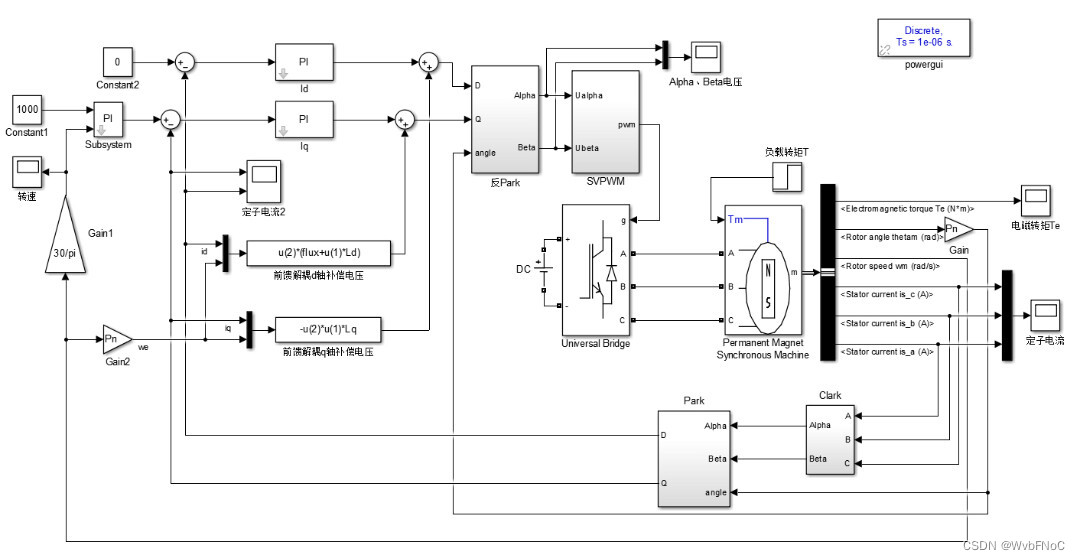
# 摘要
本文概述了永磁同步电机(PMSM)的控制策略,首先介绍了MATLAB和Simulink在构建电机数学模型和搭建仿真环境中的基础应用。随后,本文详细分析了基本控制策略,如矢量控制和直接转矩控制,并通过仿真结果进行了性能对比。在高级控制策略部分,我们探讨了模糊控制和人工智能控制策略在电机仿真中的应用,并对控制策略进行了优化。最后,通过实际应用案例,验证了仿真模型的有效性,并
【编译器性能提升指南】:优化技术的关键步骤揭秘
# 摘要
编译器性能优化对于提高软件执行效率和质量至关重要。本文详细探讨了编译器前端和后端的优化技术,包括前端的词法与语法分析优化、静态代码分析和改进以及编译时优化策略,和后端的中间表示(IR)优化、指令调度与并行化技术、寄存器分配与管理。同时,本文还分析了链接器和运行时优化对性能的影响,涵盖了链接时代码优化、运行时环境的性能提升和调试工具的应用。最后,通过编译器优化案例分析与展望,本文对比了不同编译器的优化效果,并探索了机器学习技术在编译优化中的应用,为未来的优化工作指明了方向。
# 关键字
编译器优化;前端优化;后端优化;静态分析;指令调度;寄存器分配
参考资源链接:[编译原理第二版:
Catia打印进阶:掌握高级技巧,打造完美工程图输出
# 摘要
本文全面探讨了Catia软件中打印功能的应用和优化,从基本打印设置到高级打印技巧,为用户提供了系统的打印解决方案。首先概述了Catia打印功能的基本概念和工程图打印设置的基础知识,包括工程图与打印预览的使用技巧以及打印参数和布局配置。随后,文章深入介绍了高级打印技巧,包括定制打印参数、批量打印、自动化工作流以及解决打印过程中的常见问题。通过案例分析,本文探讨了工程图打印在项目管理中的实际应用,并分享了提升打印效果
快速排序:C语言中的高效稳定实现与性能测试
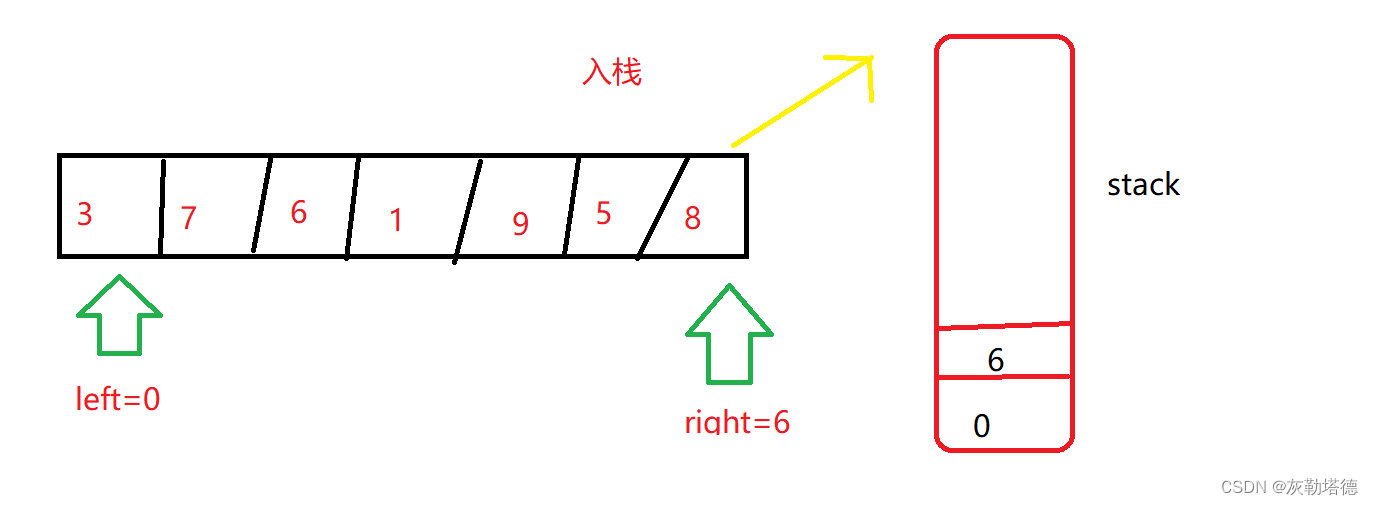
# 摘要
快速排序是一种广泛使用的高效排序算法,以其平均情况下的优秀性能著称。本文首先介绍了快速排序的基本概念、原理和在C语言中的基础实现,详细分析了其分区函数设计和递归调用机制。然后,本文探讨了快速排序的多种优化策略,如三数取中法、尾递归优化和迭代替代递归等,以提高算法效率。进一步地,本文研究了快速排序的高级特性,包括稳定版本的实现方法和非递归实现的技术细节,并与其他排序算法进行了比较。文章最后对快速排序的C语言代码实现进行了分析,并通过性能测
CPHY布局全解析:实战技巧与高速信号完整性分析
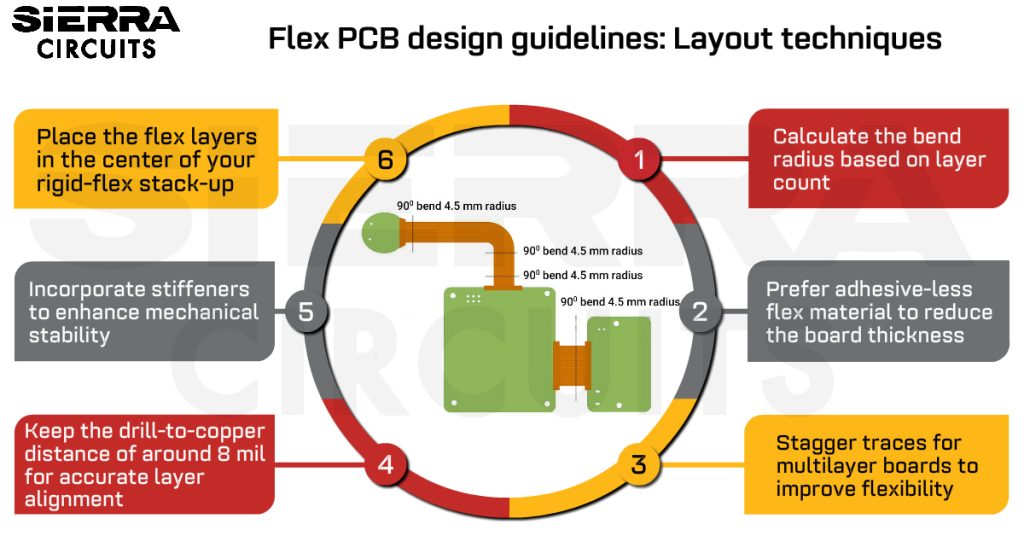
# 摘要
CPHY布局技术是支持高数据速率和高分辨率显示的关键技术。本文首先概述了CPHY布局的基本原理和技术要点,接着深入探讨了高速信号完整性的重要性,并介绍了分析信号完整性的工具与方法。在实战技巧方面,本文提供了CPHY布局要求、走线与去耦策略,以及电磁兼容(EMC)设计的详细说明。此外,本文通过案
四元数与复数的交融:图像处理创新技术的深度解析

# 摘要
本论文深入探讨了图像处理与数学基础之间的联系,重点分析了四元数和复数在图像处理领域内的理论基础和应用实践。首先,介绍了四元数的基本概念、数学运算以及其在图像处理中的应用,包括旋转、平滑处理、特征提取和图像合成等。其次,阐述了复数在二维和三维图像处理中的角色,涵盖傅里叶变换、频域分析、数据压缩、模型渲染和光线追踪。此外,本文探讨了四元数与复数结合的理论和应用,包括傅里叶变
【性能优化专家】:提升Illustrator插件运行效率的5大策略

# 摘要
随着数字内容创作需求的增加,对Illustrator插件性能的要求也越来越高。本文旨在概述Illustrator插件性能优化的有效方法
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )