A Comparative Analysis of YOLOv10 with Other Object Detection Models: Advantages and Disadvantages to Help You Make the Best Choice
发布时间: 2024-09-13 20:34:58 阅读量: 47 订阅数: 23 

An assessment of the mental health of teachers: A comparative analysis
# 1. Overview of Object Detection Models
Object detection models are a type of computer vision technology used to identify and locate objects within images or videos. They are widely used across various fields such as autonomous driving, video surveillance, and medical diagnostics.
An object detection model typically consists of two components: a feature extractor and an object detector. The feature extractor extracts relevant features from the input image or video, while the object detector uses these features to recognize and localize objects.
The performance of an object detection model is mainly determined by the following factors: accuracy, real-time capability, and robustness. Accuracy refers to the model's ability to correctly identify and localize objects, real-time capability refers to the model's inference speed, and robustness refers to the model's ability to maintain performance under various conditions, such as changes in lighting, occlusion, and cluttered backgrounds.
# 2. Theory and Practice of YOLOv10
### 2.1 Network Architecture and Algorithm Principles of YOLOv10
#### 2.1.1 Network Structure of YOLOv10
The network structure of YOLOv10 is based on the CSPDarknet53 backbone network, which consists of a series of convolutional layers, residual blocks, and spatial pyramid pooling (SPP) layers. The CSPDarknet53 backbone network has strong feature extraction capabilities and can effectively extract target features from images.
In YOLOv10, the CSPDarknet53 backbone network is modified to the CSPDarknet53-SPP network. The CSPDarknet53-SPP network adds SPP layers to the CSPDarknet53 backbone network, which can expand the receptive field and enhance the network's ability to detect targets of different scales.
#### 2.1.2 Algorithm Principles of YOLOv10
YOLOv10 adopts a new object detection algorithm, called the YOLOv10 algorithm. The YOLOv10 algorithm mainly includes the following steps:
1. **Image preprocessing:** Adjust the input image to the network input size and perform normalization.
2. **Feature extraction:** Input the preprocessed image into the CSPDarknet53-SPP backbone network for feature extraction, obtaining feature maps.
3. **Feature fusion:** Fuse feature maps of different scales to obtain fused feature maps.
4. **Object detection:** Perform object detection on the fused feature maps to obtain the bounding boxes and class predictions of the objects.
### 2.2 Training and Evaluation of YOLOv10
#### 2.2.1 Training Process of YOLOv10
The training process of YOLOv10 mainly includes the following steps:
1. **Prepare training data:** Collect and annotate target detection datasets and divide the datasets into training sets and validation sets.
2. **Initialize network:** Initialize the weights of the YOLOv10 network, which can use pre-trained weights or random initialization.
3. **Define loss function:** Define the loss function to measure the difference between the network's predictions and the true labels.
4. **Select optimizer:** Select an optimizer to update the network's weights.
5. **Train network:** Input the training set into the network and use the optimizer to update the network's weights to minimize the loss function.
6. **Validate network:** Evaluate the network's performance using the validation set and adjust the network's hyperparameters based on the validation results.
#### 2.2.2 Evaluation Metrics of YOLOv10
The evaluation metrics of YOLOv10 mainly inclu

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Java代码审计核心教程】:零基础快速入门与进阶策略
-Concept-in-Java.webp)
# 摘要
Java代码审计是保障软件安全性的重要手段。本文系统性地介绍了Java代码审计的基础概念、实践技巧、实战案例分析、进阶技能提升以及相关工具与资源。文中详细阐述了代码审计的各个阶段,包括准备、执行和报告撰写,并强调了审计工具的选择、环境搭建和结果整理的重要性。结合具体实战案例,文章
【Windows系统网络管理】:IT专家如何有效控制IP地址,3个实用技巧

# 摘要
本文主要探讨了Windows系统网络管理的关键组成部分,特别是IP地址管理的基础知识与高级策略。首先概述了Windows系统网络管理的基本概念,然后深入分析了IP地址的结构、分类、子网划分和地址分配机制。在实用技巧章节中,我们讨论了如何预防和解决IP地址冲突,以及IP地址池的管理方法和网络监控工具的使用。之后,文章转向了高级
【技术演进对比】:智能ODF架与传统ODF架性能大比拼

# 摘要
随着信息技术的快速发展,智能ODF架作为一种新型的光分配架,与传统ODF架相比,展现出诸多优势。本文首先概述了智能ODF架与传统ODF架的基本概念和技术架构,随后对比了两者在性能指标、实际应用案例、成本与效益以及市场趋势等方面的不同。智能ODF架通过集成智能管理系统,提高了数据传输的高效性和系统的可靠性,同时在安全性方面也有显著增强。通过对智能ODF架在不同部署场景中的优势展示和传统ODF架局限性的分析,本文还探讨
化工生产优化策略:工业催化原理的深入分析
# 摘要
本文综述了化工生产优化的关键要素,从工业催化的基本原理到优化策略,再到环境挑战的应对,以及未来发展趋势。首先,介绍了化工生产优化的基本概念和工业催化理论,包括催化剂的设计、选择、活性调控及其在工业应用中的重要性。其次,探讨了生产过程的模拟、流程调整控制、产品质量提升的策略和监控技术。接着,分析了环境法规对化工生产的影响,提出了能源管理和废物处理的环境友好型生产方法。通过案例分析,展示了优化策略在多相催化反应和精细化工产品生产中的实际应用。最后,本文展望了新型催化剂的开发、工业4.0与智能化技术的应用,以及可持续发展的未来方向,为化工生产优化提供了全面的视角和深入的见解。
# 关键字
MIPI D-PHY标准深度解析:掌握规范与应用的终极指南
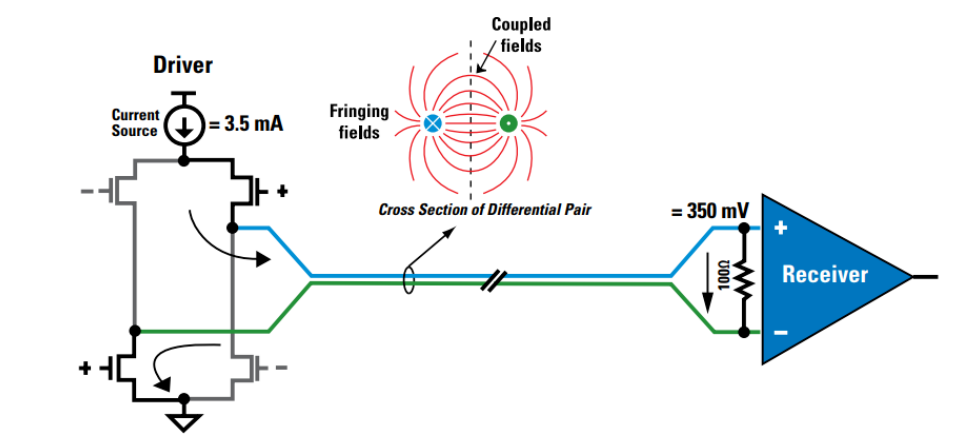
# 摘要
MIPI D-PHY作为一种高速、低功耗的物理层通信接口标准,广泛应用于移动和嵌入式系统。本文首先概述了MIPI D-PHY标准,并深入探讨了其物理层特性和协议基础,包括数据传输的速率、通道配置、差分信号设计以及传输模式和协议规范。接着,文章详细介绍了MIPI D-PHY在嵌入式系统中的硬件集成、软件驱动设计及实际应用案例,同时提出了性能测试与验
【SAP BASIS全面指南】:掌握基础知识与高级技能

# 摘要
SAP BASIS是企业资源规划(ERP)解决方案中重要的技术基础,涵盖了系统安装、配置、监控、备份、性能优化、安全管理以及自动化集成等多个方面。本文对SAP BASIS的基础配置进行了详细介绍,包括系统安装、用户管理、系统监控及备份策略。进一步探讨了高级管理技
【Talend新手必读】:5大组件深度解析,一步到位掌握数据集成
# 摘要
Talend是一款强大的数据集成工具,本文首先介绍了Talend的基本概念和安装配置方法。随后,详细解读了Talend的基础组件,包括Data Integration、Big Data和Cloud组件,并探讨了各自的核心功能和应用场景。进阶章节分析了Talend在实时数据集成、数据质量和合规性管理以及与其他工
网络安全新策略:Wireshark在抓包实践中的应用技巧

# 摘要
Wireshark作为一款强大的网络协议分析工具,广泛应用于网络安全、故障排除、网络性能优化等多个领域。本文首先介绍了Wireshark的基本概念和基础使用方法,然后深入探讨了其数据包捕获和分析技术,包括数据包结构解析和高级设置优化。文章重点分析了Wireshark在网络安全中的应用,包括网络协议分析、入侵检测与响应、网络取证与合规等。通过实
三角形问题边界测试用例的测试执行与监控:精确控制每一步

# 摘要
本文针对三角形问题的边界测试用例进行了深入研究,旨在提升测试用例的精确性和有效性。文章首先概述了三角形问题边界测试用例的基础理论,包括测试用例设计原则、边界值分析法及其应用和实践技巧。随后,文章详细探讨了三角形问题的定义、分类以及测试用例的创建、管理和执行过程。特别地,文章深入分析了如何控制测试环境与用例的精确性,并探讨了持续集成与边界测试整合的可能性。在测试结果分析与优化方面,本文提出了一系列故障分析方法和测试流程改进策略。最后,文章展望了边界
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )