YOLOv10 Code Analysis: In-depth Understanding of Its Implementation Principles and Mastery of Core Model Technologies
发布时间: 2024-09-13 20:37:54 阅读量: 29 订阅数: 42 

计算机网络英文课件:lecture-10-Principles of Transform Layer Protocol.ppt
# 1. Overview of YOLOv10
YOLOv10 is the latest iteration of the You Only Look Once (YOLO) object detection algorithm, released by Megvii Technology in 2023. It represents a significant advancement in the field of object detection, achieving notable improvements in both accuracy and speed.
YOLOv10 employs a new network architecture known as Cross-Stage Partial Connections (CSP), which enhances the model's efficiency and accuracy by optimizing the feature extraction process. Additionally, it introduces a Path Aggregation Network (PAN) module that strengthens the model's contextual information by fusing feature maps from different stages.
# 2. Theoretical Foundation of YOLOv10
### 2.1 Convolutional Neural Networks (CNN)
A Convolutional Neural Network (CNN) is a deep learning model designed to process grid-like data, such as images and videos. The core idea of CNNs is the use of convolutional operations to extract local features from the data.
Convolutional operations involve applying a filter, known as a convolutional kernel, to the input data. The kernel is a small matrix, typically 3x3 or 5x5, which performs element-wise multiplication with a local region of the input data, followed by summing the results.
By sliding the convolutional kernel over the input data, CNNs can extract various features such as edges, textures, and shapes. These features are organized into feature maps, with each map representing a particular type of feature present in the input data.
### 2.2 Object Detection Algorithms
Object detection algorithms aim to locate and identify objects within images or videos. These algorithms are generally divided into two categories: two-stage algorithms and one-stage algorithms.
**Two-stage algorithms** (such as R-CNN) first generate candidate regions and then classify each region and perform bounding box regression. While this method is accurate, it is computationally expensive.
**One-stage algorithms** (such as YOLO) directly predict bounding boxes and categories from the input image or video. This approach is faster but generally less accurate than two-stage algorithms.
### 2.3 Innovations in YOLOv10
YOLOv10, being the newest version of the YOLO series of object detection algorithms, introduces several innovative features:
***Cross-Stage Partial Connections (CSP)**: CSP is a network architecture that splits the feature maps into multiple branches and re-links them at different stages. This helps reduce computational costs while maintaining accuracy.
***Spatial Attention Module (SAM)**: SAM is an attention mechanism that focuses on areas of the image related to the target. This aids in improving localization accuracy.
***Path Aggregation Network (PAN)**: PAN is a feature fusion network that aggregates feature maps of different scales. This helps enhance feature representation and improve detection performance.
These innovations make YOLOv10 one of the most advanced algorithms in the field of object detection, excelling in both speed and accuracy.
# 3.1 Data Preprocessing and Augmentation
### Data Preprocessing
Data preprocessing is a critical step in object detection tasks, as it can enhance the model'***mon data preprocessing techniques in YOLOv10 include:
- **Image Scaling and Cropping**: Scale and crop images to a uniform size to meet the input requirements of the model.
- **Color Space Conversion**: Convert images from the RGB color space to other color spaces, such as HSV or LAB, to

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
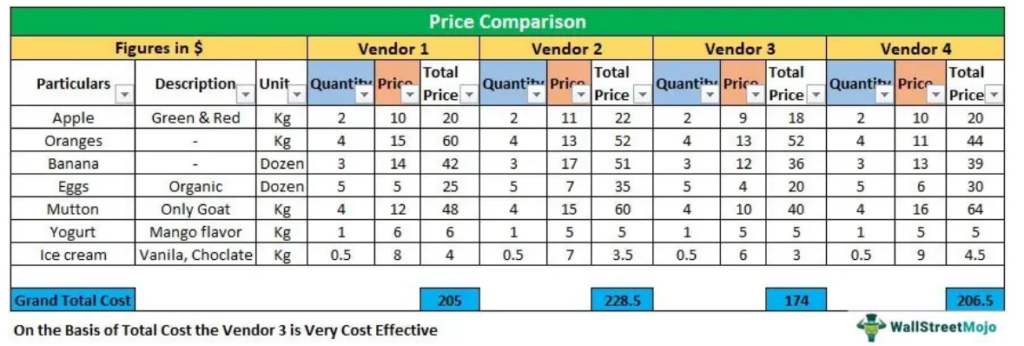
SAPSD定价策略深度剖析:成本加成与竞对分析,制胜关键解读
# 摘要
本文首先概述了SAPSD定价策略的基础概念,随后详细介绍了成本加成定价模型的理论和计算方法,包括成本构成分析、利润率设定及成本加成率的计算。文章进一步探讨了如何通过竞争对手分析来优化定价策略,并提出了基于市场定位的定价方法和应对竞争对手价格变化的策略。通过实战案例研究,本文分析了成本加成与市场适应性策略的实施效果,以及竞争对手分析在案例中的应用。最后,探
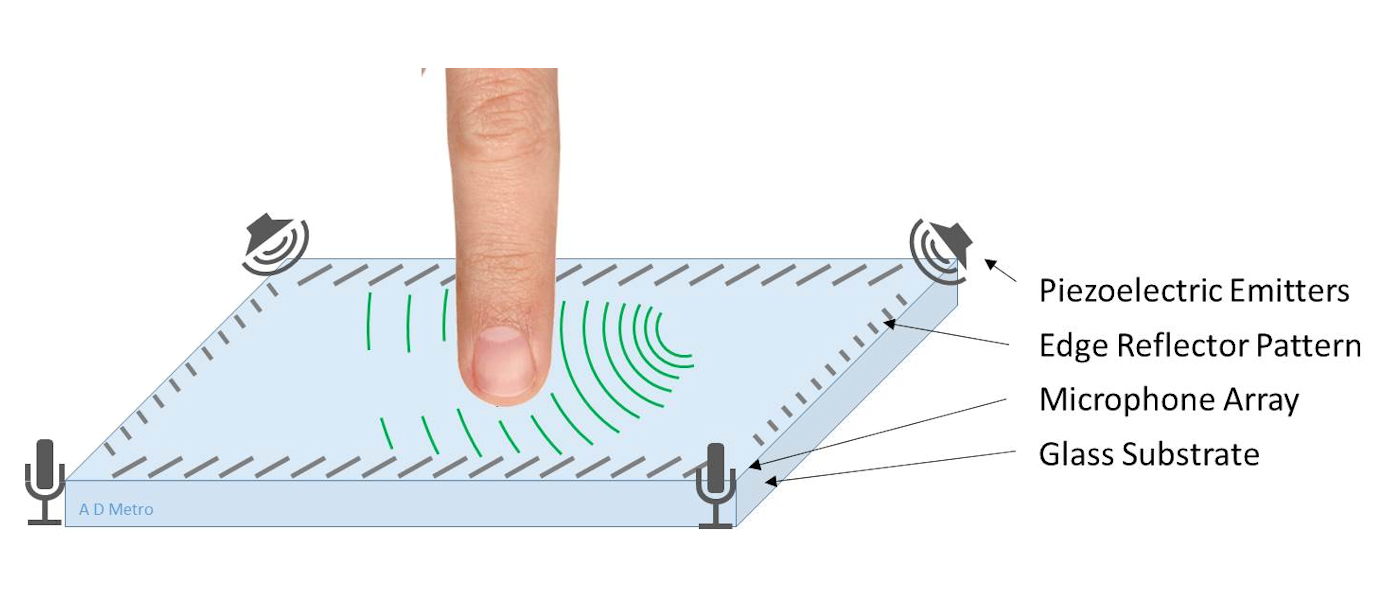
【指纹模组选型秘籍】:关键参数与性能指标深度解读
# 摘要
本文系统地介绍了指纹模组的基础知识、关键技术参数、性能测试评估方法,以及选型策略和市场趋势。首先,详细阐述了指纹模组的基本组成部分,如传感器技术参数、识别算法及其性能、电源与接口技术等。随后,文章深入探讨了指纹模组的性能测试流程、稳定性和耐用性测试方法,并对安全性标准和数据保护进行了评估。在选型实战指南部分,根据不同的应用场景和成本效益分析,提供了模组选择的实用指导。最后,
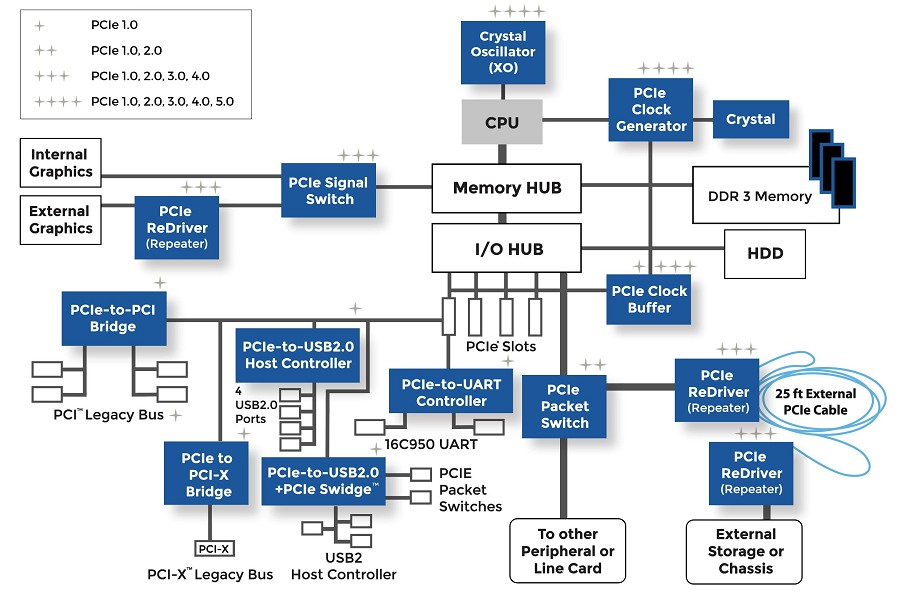
凌华PCI-Dask.dll全解析:掌握IO卡编程的核心秘籍(2023版)
# 摘要
凌华PCI-Dask.dll是一个专门用于数据采集与硬件控制的动态链接库,它为开发者提供了一套丰富的API接口,以便于用户开发出高效、稳定的IO卡控制程序。本文详细介绍了PCI-Dask.dll的架构和工作原理,包括其模块划分、数据流缓冲机制、硬件抽象层、用户交互数据流程、中断处理与同步机制以及错误处理机制。在实践篇中,本文阐述了如何利用PCI-Dask.dll进行IO卡编程,包括AP
案例分析:MIPI RFFE在实际项目中的高效应用攻略

# 摘要
本文全面介绍了MIPI RFFE技术的概况、应用场景、深入协议解析以及在硬件设计、软件优化与实际项目中的应用。首先概述了MIPI RFFE技术及其应用场景,接着详细解析了协议的基本概念、通信架构以及数据包格式和传输机制。随后,本文探讨了硬件接口设计要点、驱动程序开发及芯片与传感器的集成应用,以及软件层面的协议栈优化、系统集成测试和性能监控。最后,文章通过多个项目案例,分析了MIPI RF
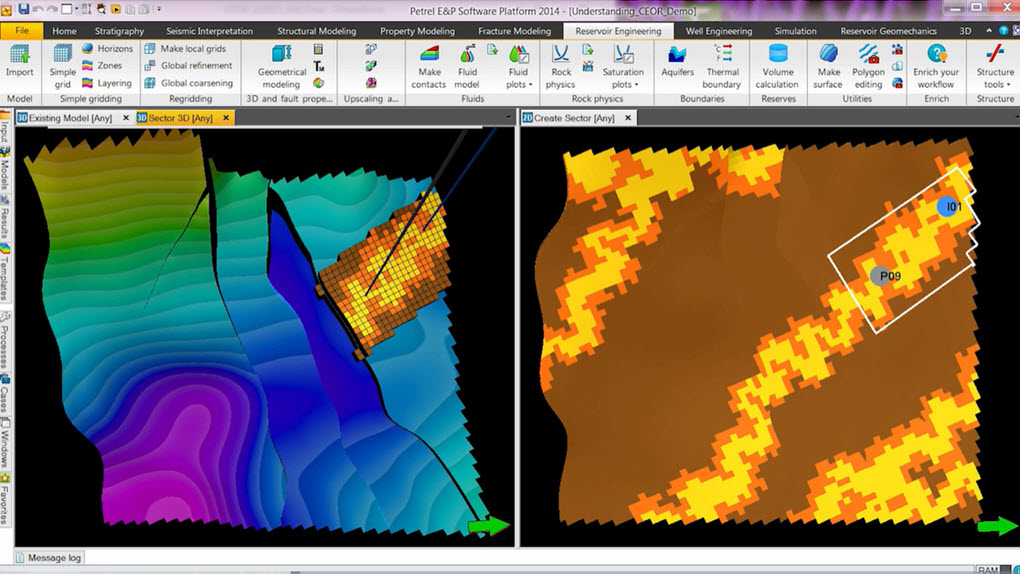
Geolog 6.7.1高级日志处理:专家级功能优化与案例研究
# 摘要
本文全面介绍了Geolog 6.7.1版本,首先提供了该软件的概览,接着深入探讨了其高级日志处理、专家级功能以及案例研究,强调了数据过滤、索引、搜索和数据分析等关键功能。文中分析了如何通过优化日志处理流程,解决日志管理问题,以及提升日志数据分析的价值。此外,还探讨了性能调优的策略和维护方法。最后,本文对Geolog的未来发展趋势进行了展望,包括新版本
ADS模型精确校准:掌握电感与变压器仿真技术的10个关键步骤

# 摘要
本文全面介绍了ADS模型精确校准的理论基础与实践应用。首先概述了ADS模型的概念及其校准的重要性,随后深入探讨了其与电感器和变压器仿真原理的基础理论,详细解释了相关仿真模型的构建方法。文章进一步阐述了ADS仿真软件的使用技巧,包括界面操作和仿真模型配置。通过对电感器和变压器模型参数校准的具体实践案例分析,本文展示了高级仿真技术在提高仿真准确性中的应用,并验证了仿真结果的准确性。最后
深入解析华为LTE功率控制:掌握理论与实践的完美融合

# 摘要
本文对LTE功率控制的技术基础、理论框架及华为在该领域的技术应用进行了全面的阐述和深入分析。首先介绍了LTE功率控制的基本概念及其重要性,随后详细探
【Linux故障处理攻略】:从新手到专家的Linux设备打开失败故障解决全攻略
# 摘要
本文系统介绍了Linux故障处理的基本概念,详细分析了Linux系统的启动过程,包括BIOS/UEFI的启动机制、内核加载、初始化进程、运行级和
PLC编程新手福音:入门到精通的10大实践指南

# 摘要
本文旨在为读者提供一份关于PLC(可编程逻辑控制器)编程的全面概览,从基础理论到进阶应用,涵盖了PLC的工作原理、编程语言、输入输出模块配置、编程环境和工具使用、项目实践以及未来趋势与挑战。通过详细介绍PLC的硬件结构、常用编程语言和指令集,文章为工程技术人员提供了理解和应用PLC编程的基础知识。此外,通过对PLC在自动化控制项目中的实践案例分析,本文
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )