Time Series Autoregressive Models: In-depth Exploration and Practical Techniques
发布时间: 2024-09-15 07:03:37 阅读量: 94 订阅数: 29 

orange3-timeseries::tangerine:橙色附加组件,用于分析,可视化,操纵和预测时间序列数据
# Machine Learning Methods in Time Series Prediction
When analyzing and predicting time series data, autoregressive models (Autoregressive, AR) are powerful tools. These models assume that the current value can be predicted using observations from previous time points. Understanding the basics of autoregressive models is crucial for mastering subsequent theoretical constructs and practical techniques.
Autoregressive models are a type of linear time series model that describes the linear relationship between the current value of the time series and its historical values. When building the model, the order of the model is usually selected based on autocorrelation. The simple form of the AR model is AR(1), indicating a linear relationship between the current value and the value at the previous time point.
Mathematically, an AR(1) model can be expressed as:
```
Y_t = c + φ_1 * Y_(t-1) + ε_t
```
Where, `Y_t` is the value at time point t, `c` is the constant term, `φ_1` is the autoregressive coefficient, and `ε_t` is the error term. Understanding this basic formula is the first step to mastering autoregressive models, laying the foundation for constructing more complex models.
# 2. Theoretical Construction of Autoregressive Models
### 2.1 Basic Concepts of Autoregressive Models
#### 2.1.1 Definition and Mathematical Expression of Autoregressive Models
An autoregressive model (Autoregressive model, AR model for short) is a basic statistical model in time series analysis, used to describe the relationship between a time series and its own past values. Its idea originates from linear regression, but linear regression deals with data from different individuals at different time points, while the autoregressive model deals with data from the same time series at different time points.
Mathematically, a p-th order autoregressive model can be expressed as:
\[ X_t = c + \phi_1X_{t-1} + \phi_2X_{t-2} + ... + \phi_pX_{t-p} + \varepsilon_t \]
Where:
- \( X_t \) is the observed value at the current time point.
- \( \phi_1, \phi_2, ..., \phi_p \) are the parameters of the autoregressive model, representing the coefficients of the past values of the time series.
- \( p \) is the order of the model, indicating how many past values we consider to predict the current value.
- \( c \) is the constant term.
- \( \varepsilon_t \) is the error term (residual), usually assumed to be white noise.
In autoregressive models, it is assumed that the error term \( \varepsilon_t \) has a constant variance and is not correlated with all past values and error terms.
#### 2.1.2 Importance of Model Parameters and Estimation Methods
The estimation of autoregressive model parameters is a key step in model establishment. Parameter estimation is usually achieved by minimizing the sum of squared residuals, a method known as Ordinary Least Squares (OLS). Specifically, the goal of OLS is to find a set of parameters that minimize the difference between the observed values and the model predicted values.
Parameter estimation methods mainly include:
- **Maximum Likelihood Estimation (MLE)**: This method is based on probability theory and estimates parameters by maximizing the probability of observed data occurring.
- **Yule-Walker Equations**: This is a set of linear equations that estimate autoregressive parameters through the first and second moments (i.e., mean and autocovariance) of the time series.
- **Burg Algorithm**: This is a recursive method for calculating autoregressive parameters while minimizing the variance of forward and backward prediction errors.
Correct parameter estimation is crucial for the predictive power of the model. If the parameter estimation is inaccurate, the model may produce misleading predictions about future trends.
### 2.2 Statistical Foundation of the Model and Hypothesis Testing
#### 2.2.1 Stationarity Test and Difference Processing
Time series data usually contains seasonal components and trend components, which can affect the predictive accuracy of autoregressive models. To make time series data suitable for autoregressive models, ***
***mon methods for stationarity tests include:
- **Augmented Dickey-Fuller (ADF) Test**: This test is used to determine whether a series has a unit root, i.e., whether the series is non-stationary.
- **KPSS Test**: Kwiatkowski-Phillips-Schmidt-Shin test, its null hypothesis is that the series is stationary.
If the time series data is non-stationary, difference processing is one of the commonly used solutions. Difference is to calculate the difference between each pair of consecutive observations in the series, forming a new series. Differencing can eliminate trends and seasonal components, making the series stationary.
#### 2.2.2 Residual Diagnosis and Hypothesis Testing of the Model
The purpose of residual diagnosis is to test whether the residuals conform to the basic assumptions of OLS. Residuals are the differences between the actual values and the predicted values of the model and can be considered as the unexplained error part after the model is established.
Residual hypothesis testing mainly includes:
- **Independence of Residuals**: Ljung-Box Q test can be used.
- **Normality of Residuals**: Shapiro-Wilk test or Q-Q plot can be used.
- **Homoscedasticity of Residuals**: ARCH-LM test can be used.
If problems are found during residual diagnosis, it may be necessary to reconsider the form of the model or further transform the data.
### 2.3 Model Order Selection and Validation
#### 2.3.1 Application of Information Criteria in Model Selection
In autoregressive models, ***rmation criteria provide a standard for selecting the model order, common information criteria include:
- **Akaike Information Criterion (AIC)**
- **Bayesian Information Criterion (BIC)**
- **Schwarz Criterion (SC)**
Information criteria balance the complexity of the model and goodness of fit, aiming to avoid overfitting of the model while selecting the model that best describes the data. Generally, the model with the smallest information criterion value is chosen as the final model.
#### 2.3.2 Cross-Validation of the Model and Evaluation of Predictive Performance
Cross-validation is a technique for evaluating a model's generalization ability. The process involves dividing the dataset into several parts, one part is used for training the model, and the remaining parts are used for testing the model's predictive ability. In autoregressive models, time series cross-validation is usually used.
Predictive performance evaluation requires the use of some indicators, commonly used indicators include:
- **Mean Squared Error (MSE)**
- **Root Mean Squared Error (RMSE)**
- **Mean Absolute Error (MAE)**
The smaller these indicators are, the better the model's predictive performance. In addition, the model's predictive effect can be visually assessed by plotting the predicted values against the actual values.
# 3. Practical Techniques for Autoregressive Models
### 3.1 Data Preparation and Preprocessing
#### 3.1.1 Data Cleaning and Formatting
When conducting time series analysis, data cleaning and formatting are crucial steps. The raw data may contain missing values, outliers, or inconsistent formats, which, if not addressed, will negatively affect the accuracy and reliability of the model. The purpose of data cleaning is to ensure data quality for subsequent analysis.
Data cleaning includes handling missing values, deleting or correcting outliers, ***mon methods for handling missing values include interpolation, deleting records with missing values, or using averages as substitutes. The handling of outliers requires judgment based on specific situations, which may involve further data analysis, and even the application of domain knowledge.
Below is a simple example of data cleaning code:
```python
import pandas as pd
# Assuming there is a DataFrame containing time series data
data = pd.DataFrame({
'date': pd.date_range('2020-01-01', periods=100, freq='D'),
'value': range(100)
})
# Assuming the data for the 95th day is missing
data.iloc[94, 1] = None
# Check for missing values
print(data.isnull().sum())
# Fill missing values using the previous day's value
data['value'].fillna(method='ffill', inplace=True)
# Delete or correct outliers, here we take deletion as an example
data.dropna(inplace=True)
# The final data should have no missing values or outliers
print(data.isnull().sum())
```
#### 3.1.2 Application of Feature Engineering in Autoregression
In time series analysis, feature engineering is an important means to improve model predictive performance. By creating and selecting appropriate time series features, the model's predictive ability can be effectively improved. Feature engineering mainly includes the creation of lag features, the extraction of time-related features, and the extraction of seasonal components.
Lag features are commonly used in time series analysis. They refer to the values of the time series at different time points and can be used as a basis for predicting future values. For example, if we want to predict tomorrow's temperature, we can use today's, yesterday's, or even the previous few days' temperatures as predictive variables.
Below is a Python code example for creating lag features:
```python
from statsmodels.tsa.tsatools import lagmat
# Assuming data is time series data that has been cleaned
data['lag_1'] = lagmat(data['value'].values, maxlag=1, use_pandas=True)[0]
# You can continue to add other lag features, such as lag_2, lag_3, etc.
# ...
```
With the above code, we have added a lag feature for the previous period. Depending on the characteristics of the time series and the requirements of the autoregressive model, we can add more lag features. In actual operations, the appropriate lag order should be determined based on the data characteristics and the requirements of the autoregressive model.
### 3.2 Establishment and Training of Autoregressive Models
#### 3.2.1 Building Models Using Statistical Software Packages
The construction of autoregressive models can usually be achieved with the help of statistical software packages, such as the `stats` package in R language and the `statsmodels` package in Python. These packages provide convenient functions and tools for fitting autoregressive models, as well as parameter estimation and model diagnostics.
Below is an example of how to use the `statsmodels` library in Python to build a simple autoregressive model. First, you need to install the `statsmodels` package, and if it is not installed, you can use the pip command to install it:
```bash
pip install statsmodels
```
Next is the code example for model building:
```python
import numpy as np
import pandas as pd
from statsmodels.tsa.ar_model import AutoReg
# Assuming data is time series data that has been cleaned
data = pd.read_csv('time_series_data.csv') # Assuming the CSV file contains time series data
# Fit the autoregressive model
# Here we assume we are using a model with a lag of 1 period, i.e., AR(1)
model = AutoReg(data['value'], lags=1)
model_fit = model.fit()
# View detailed statistical information about the model
print(model_fit.summary())
```
When the model summary is output, the `summary()` function will display the results of model parameter estimation, including the estimated values of the parameters, standard errors, t-statistics, and corresponding p-values. These statistics can help us determine the significance of the model parameter

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
潮流分析的艺术:PSD-BPA软件高级功能深度介绍

# 摘要
电力系统分析在保证电网安全稳定运行中起着至关重要的作用。本文首先介绍了潮流分析的基础知识以及PSD-BPA软件的概况。接着详细阐述了PSD-BPA的潮流计算功能,包括电力系统的基本模型、潮流计算的数学原理以及如何设置潮流计算参数。本文还深入探讨了PSD-BPA的高级功
RTC4版本迭代秘籍:平滑升级与维护的最佳实践

# 摘要
本文重点讨论了RTC4版本迭代的平滑升级过程,包括理论基础、实践中的迭代与维护,以及维护与技术支持。文章首先概述了RTC4的版本迭代概览,然后详细分析了平滑升级的理论基础,包括架构与组件分析、升级策略与计划制定、技术要点。在实践章节中,本文探讨了版本控制与代码审查、单元测试
嵌入式系统中的BMP应用挑战:格式适配与性能优化
# 摘要
本文综合探讨了BMP格式在嵌入式系统中的应用,以及如何优化相关图像处理与系统性能。文章首先概述了嵌入式系统与BMP格式的基本概念,并深入分析了BMP格式在嵌入式系统中的应用细节,包括结构解析、适配问题以及优化存储资源的策略。接着,本文着重介绍了BMP图像的处理方法,如压缩技术、渲染技术以及资源和性能优化措施。最后,通过具体应用案例和实践,展示了如何在嵌入式设备中有效利用BMP图像,并探讨了开发工具链的重要性。文章展望了高级图像处理技术和新兴格式的兼容性,以及未来嵌入式系统与人工智能结合的可能方向。
# 关键字
嵌入式系统;BMP格式;图像处理;性能优化;资源适配;人工智能
参考资
SSD1306在智能穿戴设备中的应用:设计与实现终极指南
# 摘要
SSD1306是一款广泛应用于智能穿戴设备的OLED显示屏,具有独特的技术参数和功能优势。本文首先介绍了SSD1306的技术概览及其在智能穿戴设备中的应用,然后深入探讨了其编程与控制技术,包括基本编程、动画与图形显示以及高级交互功能的实现。接着,本文着重分析了SSD1306在智能穿戴应用中的设计原则和能效管理策略,以及实际应用中的案例分析。最后,文章对SSD1306未来的发展方向进行了展望,包括新型显示技术的对比、市场分析以及持续开发的可能性。
# 关键字
SSD1306;OLED显示;智能穿戴;编程与控制;用户界面设计;能效管理;市场分析
参考资源链接:[SSD1306 OLE
ECOTALK数据科学应用:机器学习模型在预测分析中的真实案例

# 摘要
本文对机器学习模型的基础理论与技术进行了综合概述,并详细探讨了数据准备、预处理技巧、模型构建与优化方法,以及预测分析案例研究。文章首先回顾了机器学习的基本概念和技术要点,然后重点介绍了数据清洗、特征工程、数据集划分以及交叉验证等关键环节。接
PM813S内存管理优化技巧:提升系统性能的关键步骤,专家分享!
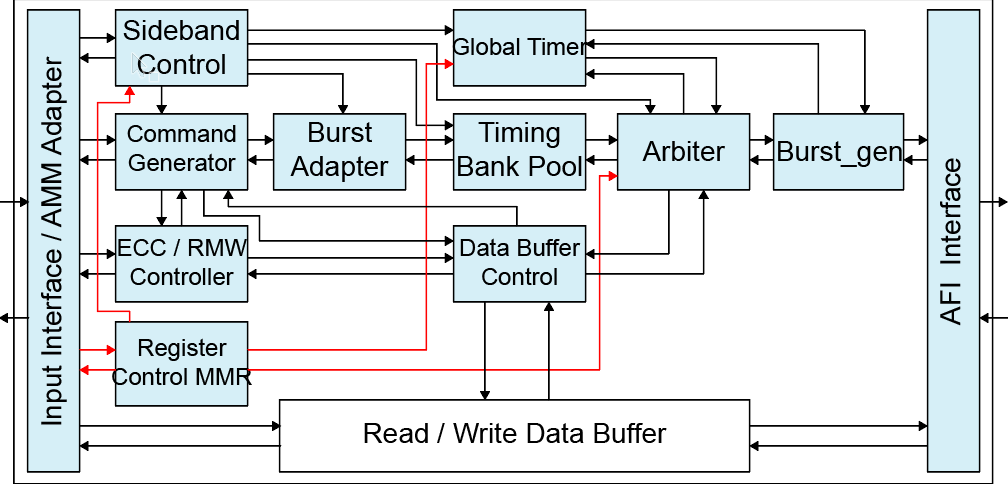
# 摘要
PM813S作为一款具有先进内存管理功能的系统,其内存管理机制对于系统性能和稳定性至关重要。本文首先概述了PM813S内存管理的基础架构,然后分析了内存分配与回收机制、内存碎片化问题以及物理与虚拟内存的概念。特别关注了多级页表机制以及内存优化实践技巧,如缓存优化和内存压缩技术的应用。通过性能评估指标和调优实践的探讨,本文还为系统监控和内存性能提
CC-LINK远程IO模块AJ65SBTB1现场应用指南:常见问题快速解决
# 摘要
CC-LINK远程IO模块作为一种工业通信技术,为自动化和控制系统提供了高效的数据交换和设备管理能力。本文首先概述了CC-LINK远程IO模块的基础知识,接着详细介绍了其安装与配置流程,包括硬件的物理连接和系统集成要求,以及软件的参数设置与优化。为应对潜在的故障问题,本文还提供了故障诊断与排除的方法,并探讨了故障解决的实践案例。在高级应用方面,文中讲述了如何进行编程与控制,以及如何实现系统扩展与集成。最后,本文强调了CC-LINK远程IO模块的维护与管理的重要性,并对未来技术发展趋势进行了展望。
# 关键字
CC-LINK远程IO模块;系统集成;故障诊断;性能优化;编程与控制;维护
【光辐射测量教育】:IT专业人员的培训课程与教育指南

# 摘要
光辐射测量是现代科技中应用广泛的领域,涉及到基础理论、测量设备、技术应用、教育课程设计等多个方面。本文首先介绍了光辐射测量的基础知识,然后详细探讨了不同类型的光辐射测量设备及其工作原理和分类选择。接着,本文分析了光辐射测量技术及其在环境监测、农业和医疗等不同领域的应用实例。教育课程设计章节则着重于如何构建理论与实践相结合的教育内容,并提出了评估与反馈机制。最后,本文展望了光辐射测量教育的未来趋势,讨论了技术发展对教育内容和教
【Ubuntu 16.04系统更新与维护】:保持系统最新状态的策略
# 摘要
本文针对Ubuntu 16.04系统更新与维护进行了全面的概述,探讨了系统更新的基础理论、实践技巧以及在更新过程中可能遇到的常见问题。文章详细介绍了安全加固与维护的策略,包括安全更新与补丁管理、系统加固实践技巧及监控与日志分析。在备份与灾难恢复方面,本文阐述了
分析准确性提升之道:谢菲尔德工具箱参数优化攻略

# 摘要
本文介绍了谢菲尔德工具箱的基本概念及其在各种应用领域的重要性。文章首先阐述了参数优化的基础理论,包括定义、目标、方法论以及常见算法,并对确定性与随机性方法、单目标与多目标优化进行了讨论。接着,本文详细说明了谢菲尔德工具箱的安装与配置过程,包括环境选择、参数配置、优化流程设置以及调试与问题排查。此外,通过实战演练章节,文章分析了案例应用,并对参数调优的实验过程与结果评估给出了具体指
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )