"Random Forest Time Series Forecasting": Theoretical Depth and Practical Guide
发布时间: 2024-09-15 06:48:42 阅读量: 62 订阅数: 29 
# Random Forest Time Series Forecasting: Theoretical Depth and Practical Guide
## 1. Overview of Random Forest Algorithm
The Random Forest algorithm is an ensemble learning technique composed of multiple decision trees, designed to improve predictive accuracy and prevent overfitting. In this chapter, we will explore the origins of Random Forest, its status in machine learning, and how it handles classification and regression tasks.
### 1.1 Core Concepts of Random Forest
Random Forest enhances a model's generalization capabilities by introducing randomness. The core idea is to create a forest of multiple decision trees, each trained on only a subset of the data. This diversity helps the model exhibit greater robustness when facing new data.
### 1.2 Brief Explanation of Random Forest's Mechanism
Each tree independently learns the relationship between data features and labels, ultimately determining the prediction result through a voting mechanism. This ensemble method not only improves model performance but also simplifies model tuning and interpretation.
### 1.3 Application Domains and Advantages
Random Forest is widely used in financial analysis, bioinformatics, natural language processing, and other fields due to its efficiency and flexibility. It shows unique advantages in dealing with high-dimensional data and interactions between features, making it a powerful tool for data scientists.
The following chapters will delve into the Random Forest algorithm and its applications and optimization strategies in time series forecasting.
## 2. Fundamentals of Time Series Forecasting
Time series analysis is one of the key techniques for understanding and forecasting future events, with widespread applications in economics, finance, meteorology, and technology. This chapter first discusses the basic theory of time series analysis, then introduces how to preprocess time series data, and finally compares different time series forecasting methods.
### 2.1 Theories of Time Series Analysis
#### 2.1.1 Components of a Time Series
A time series is a sequence of data points arranged in chronological order, usually used to represent changes in a variable at different points in time. Time series analysis focuses on the temporal characteristics of the data, which are crucial for forecasting future data points. A time series typically includes the following elements:
- **Trend**: The long-term direction of change in the time series data over time. Trends can be rising, falling, or stable.
- **Seasonality**: Periodic fluctuations that occur within fixed time intervals (such as seasons, months, weeks, etc.).
- **Cyclical**: Fluctuations that do not have a fixed period but typically have a cycle of more than a year.
- **Irregular/Random**: The remaining fluctuations, caused by unexpected events or random disturbances, which are difficult to predict.
Understanding these elements is a prerequisite for time series analysis. For instance, when forecasting a company's quarterly sales, one would consider past sales trends, seasonality (such as increased sales during the holiday season), and potential cyclical changes (such as the impact of economic cycles on sales).
#### 2.1.2 Common Time Series Models
In time series analysis, there are various models that can be used to describe and predict data. These models include:
- **Autoregressive Model (AR)**: Predicts future values using lagged values of the time series itself.
- **Moving Average Model (MA)**: Uses historical disturbances or residuals of the time series to predict future values.
- **Autoregressive Moving Average Model (ARMA)**: Combines the advantages of AR and MA models by considering both the lagged values and historical disturbances of the time series.
- **Autoregressive Integrated Moving Average Model (ARIMA)**: When the time series is non-stationary, it is first transformed into a stationary series, and then the ARMA model is applied.
- **Seasonal Autoregressive Integrated Moving Average Model (SARIMA)**: Adds seasonal component analysis on the basis of ARIMA.
- **Exponential Smoothing Model**: Assigns different weights to historical data, with more recent data being given higher weight.
Each model has its own scenarios and limitations, and choosing the appropriate model is crucial for the accuracy of the forecasts.
### 2.2 Preprocessing Time Series Data
Before conducting time series analysis, it is essential to thoroughly preprocess the data to ensure the accuracy and reliability of the analysis results.
#### 2.2.1 Data Cleaning
Data cleaning involves identifying and addressing inconsistencies, missing values, and outliers within the time series data. Effective data cleaning can improve the accuracy of the model'***mon steps include:
- **Filling Missing Values**: If the amount of missing data is small, methods such as forward-filling, backward-filling, or interpolation can be used to fill in the gaps.
- **Outlier Handling**: Identify outliers in the data and decide whether to remove, correct, or retain these values.
- **Smoothing**: Use moving averages or other methods to smooth data and reduce the impact of random fluctuations.
#### 2.2.2 Data Transformation and Smoothing
To eliminate trends and seasonality or to make the time series平稳, data transformation and smoothing are often necessary. These methods include:
- **Log Transformation**: Reduces the heteroscedasticity of data, making fluctuations more stable.
- **Differencing**: Eliminates trends by calculating the difference between data points and their previous values.
- **Seasonal Differencing**: Conducts differencing over the seasonal period to remove seasonal effects.
- **Moving Average Smoothing**: Calculates the moving average over a window to reduce random fluctuations.
### 2.3 Comparison of Time Series Forecasting Methods
When selecting a time series forecasting method, several factors such as the characteristics of the data, the accuracy of the forecasts, and the complexity of the computations need to be considered.
#### 2.3.1 Statistical Methods vs. Machine Learning Methods
- **Statistical Methods**: Traditional statistical models like ARIMA and exponential smoothing are widely used due to their strong interpretability and relatively low computational complexity. These models perform well on small to medium-sized datasets, especially when the time series data is linear or can be linearized.
- **Machine Learning Methods**: With the development of machine learning technology, models like Random Forest, Support Vector Machines (SVM), and neural networks are also used for time series forecasting. These models excel in capturing non-linear and complex patterns, but they typically require more data and computational resources and have poorer model interpretability.
#### 2.3.2 Factors to Consider in Model Selection
- **Data Scale and Complexity**: Large-scale, non-linear time series data is more suitable for machine learning methods.
- **Forecasting Accuracy**: Machine learning methods usually outperform statistical methods in terms of accuracy, but overfitting risks need to be monitored.
- **Computational Resources and Time**: Statistical methods are computationally more efficient and suitable for environments with limited resources.
- **Model Interpretability**: If the forecast results need to be explained, statistical models may be more appropriate.
The above are some fundamental points of time series forecasting. In the following chapters, we will delve deeper into the Random Forest algorithm and its application in time series forecasting.
# 3. Detailed Explanation of Random Forest Algorithm
As a powerful machine learning method, the Random Forest algorithm has shown excellent performance in handling classification and regression problems. In the field of time series forecasting, it has gradually become a research hotspot. This chapter will delve into the

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
HL7数据映射与转换秘籍:MR-eGateway高级应用指南(数据处理专家)
# 摘要
HL7数据映射与转换是医疗信息系统集成的核心技术,涉及数据结构的理解、消息解析、数据验证和映射策略的制定等多个方面。本文从HL7数据模型基础出发,探讨了数据映射理论、实践案例以及转换技术,分析了MR-eGateway在数据映射和转换中的应用,并展望了HL7在未来医疗信息交换中的趋势。文章旨在为医疗信息处理的专业人员提供深入的理论指导和实际应用参考,同时促进了医疗数据交换技术的持续发展和行业标准化进程。
# 关键字
HL7数据模型;数据映射;数据转换;MR-eGateway;医疗信息交换;行业标准化
参考资源链接:[迈瑞eGateway HL7参考手册:数据转换与安全操作指南](h
留住人才的艺术:2024-2025年度人力资源关键指标最佳实践
# 摘要
人力资源管理是组织成功的关键因素之一,涵盖了招聘、绩效管理、员工发展、满意度与工作环境优化等多个维度。本文全面探讨了人力资源管理的核心要素,着重分析了招聘与人才获取的最新最佳实践,包括流程优化和数据分析在其中的作用。同时,本文还强调了员工绩效管理体系的重要性,探讨如何通过绩效反馈激励员工,并推动其职业成长。此外,员工满意度、工
【网上花店架构设计与部署指南】:组件图与部署图的构建技巧

# 摘要
本文旨在讨论网上花店的架构设计与部署,涵盖架构设计的理论基础、部署图的构建与应用以及实际架构设计实践。首先,我们分析了高可用性与可伸缩性原则以及微服务架构在现代网络应用中的应用,并探讨了负载均衡与服务发现机制。接着,深入构建与应用部署图,包括其基本元素、组件图绘制技巧和实践应用案例分析。第四章着重于网上花店的前后端架构设计、性能优化、安全性和隐私保护。最后,介绍了自动化部署流程、性能测试与
【欧姆龙高级编程技巧】:数据类型管理的深层探索

# 摘要
数据类型管理是编程和软件开发的核心组成部分,对程序的效率、稳定性和可维护性具有重要影响。本文首先介绍了数据类型管理的基本概念和理论基础,详细探讨了基
Sysmac Gateway故障排除秘籍:快速诊断与解决方案

# 摘要
本文全面介绍了Sysmac Gateway的故障诊断与维护技术。首先概述了Sysmac Gateway的基本概念及其在故障诊断中的基础作用。随后,深入分析了硬件故障诊断技术,涵盖了硬件连接检查、性能指标检测及诊断报告解读等方面。第三章转向软件故障诊断,详细讨论了软件更新、系统资源配置错误、服务故障和网络通信问题的排查方法。第四章通过实际案例,展示故障场
STC89C52单片机时钟电路设计:原理图要点快速掌握
# 摘要
本文针对STC89C52单片机的时钟电路设计进行了深入探讨。首先概述了时钟电路设计的基本概念和重要性,接着详细介绍了时钟信号的基础理论,包括频率、周期定义以及晶振和负载电容的作用。第三章通过实例分析,阐述了设计前的准备工作、电路图绘制要点以及电路调试与测试过程中的关键步骤。第四章着重于时钟电路的高级应用,提出了提高时钟电路稳定性的方法和时钟电路功能的扩展技术。最后,第五章通过案例分析展示了时钟电路在实际项目中的应用,并对优化设计策略和未来展望进行了讨论。本文旨在为工程师提供一个系统化的时钟电路设计指南,并推动该领域技术的进步。
# 关键字
STC89C52单片机;时钟电路设计;频率与
【天清IPS性能与安全双提升】:高效配置技巧,提升效能不再难
# 摘要
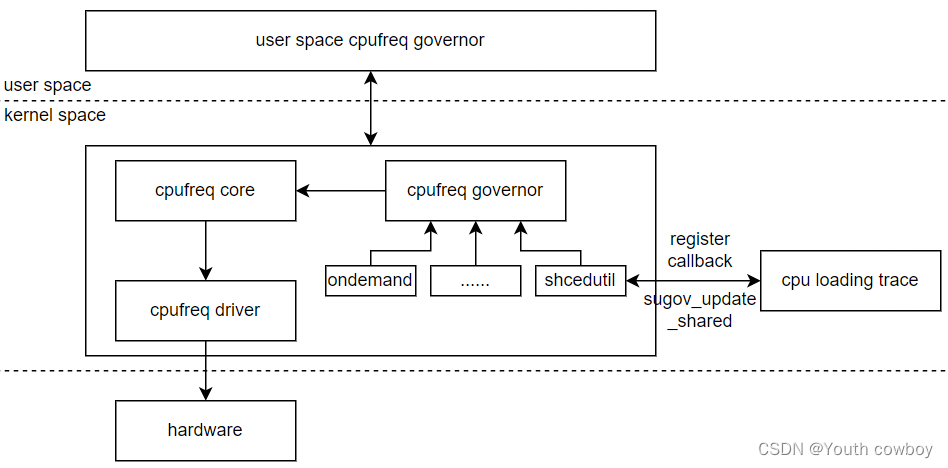
随着网络安全威胁的不断演变,入侵防御系统(IPS)扮演着越来越关键的角色。本文从技术概述和性能提升需求入手,详细介绍天清IPS系统的配置、安全策略优化和性能优化实战。文中阐述了天清IPS的基础配置,包括安装部署、基本设置以及性能参数调整,同时强调了安全策略定制化和优化,以及签名库更新与异常检测的重要性。通过硬件优化、软件性能调优及实战场景下的性能测试,本文展示了如何系统地
揭秘QEMU-Q35芯片组:新一代虚拟化平台的全面剖析和性能提升秘籍
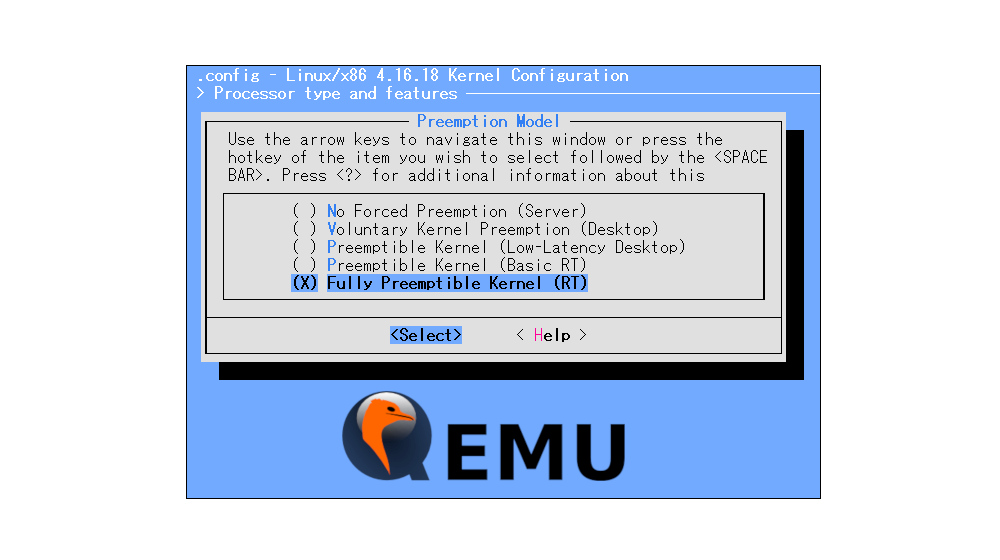
# 摘要
本文旨在全面介绍QEMU-Q35芯片组及其在虚拟化技术中的应用。首先概述了QEMU-Q35芯片组的基础架构及其工作原理,重点分析了虚拟化技术的分类和原理。接着,详细探讨了QEMU-Q35芯片组的性能优势,包括硬件虚拟化的支持和虚拟机管理的增强特性。此外,本文对QEMU-Q35芯片组的内存管理和I/O虚拟化技术进行了理论深度剖析,并提供了实战应用案例,包括部署
【高级网络管理策略】:C++与SNMPv3在Cisco设备中捕获显示值的高效方法

# 摘要
随着网络技术的快速发展,网络管理成为确保网络稳定运行的关键。SNMP(简单网络管理协议)作为网络管理的核心技术之一,其版本的演进不断满足网络管理的需求。本文首先介绍了网络管理的基础知识及其重要性,随后深入探讨了C++编程语言,作为实现高效网络管理工具的基础。文章重点介绍了SNMPv3协议的工作原理和安全机制,以
深入解构MULTIPROG软件架构:掌握软件设计五大核心原则的终极指南
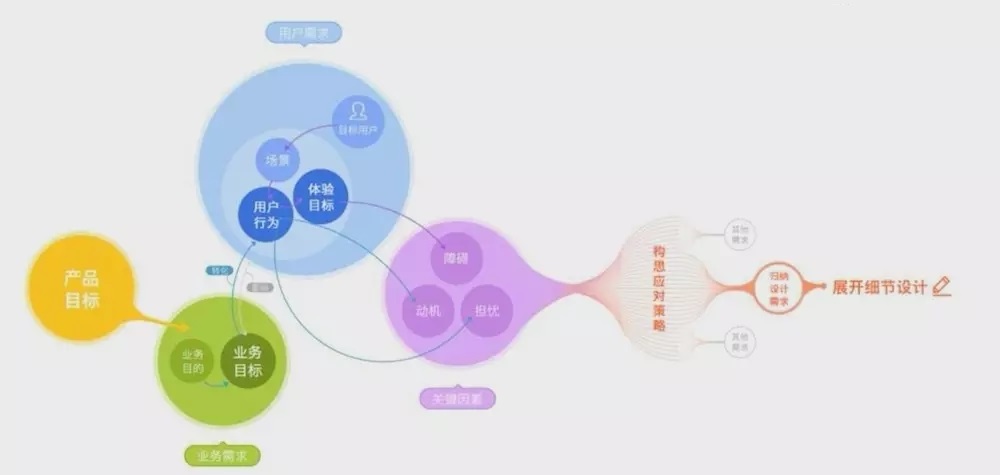
# 摘要
本文旨在探讨MULTIPROG软件架构的设计原则和模式应用,并通过实践案例分析,评估其在实际开发中的表现和优化策略。文章首先介绍了软件设计的五大核心原则——单一职责原则(SRP)、开闭原则(OCP)、里氏替换原则(LSP)、接口隔离原则(ISP)、依赖倒置原则(DIP)——以及它们在MULTIPROG架构中的具体应用。随后,本文深入分析了创建型、结构型和行为型设计模式在
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )