【Essentials of Deep Learning for Time Series Forecasting】: Tips and Advanced Applications of RNN
发布时间: 2024-09-15 06:28:57 阅读量: 84 订阅数: 33 
# Deep Learning Time Series Forecasting Essentials: Tips and Advanced Applications of RNN
## 1. Overview of Deep Learning and Time Series Forecasting
### 1.1 Introduction to Deep Learning Techniques
Deep learning, as a branch of the machine learning field, has become a core technology for handling complex data and pattern recognition. By simulating the working principles of the human brain's neural network, deep learning algorithms can automatically learn data representations and features without the need for manual feature design. This adaptive feature extraction capability has led to breakthroughs in deep learning in areas such as image recognition, speech processing, and natural language processing.
### 1.2 The Importance of Time Series Forecasting
Time series forecasting involves predicting future data points or trends based on historical data. This technology is widely applied in many fields, including finance, meteorology, economics, and energy. The purpose of time series forecasting is to learn patterns from past and present data to make reasonable predictions about future data within a certain period. Accurate time series forecasting is crucial for resource optimization, risk management, and decision-making.
### 1.3 Combining Deep Learning and Time Series Forecasting
Deep learning applications in time series forecasting, particularly through recurrent neural networks (RNNs) and their variants (such as LSTMs and GRUs), ***pared to traditional statistical methods, deep learning methods have unique advantages in nonlinear pattern recognition, thus providing more accurate predictions when dealing with complex, high-dimensional time series data.
## 2. Basic Principles and Structure of RNN Networks
### 2.1 Basics of Recurrent Neural Networks (RNN)
#### 2.1.1 How RNNs Work
Recurrent Neural Networks (RNNs) are a type of neural network designed for processing sequential data. In traditional feedforward neural networks, information flows in one direction, from the input layer to the hidden layer, and then to the output layer. The core feature of RNNs is their ability to use their memory to process sequential data, endowing the network with dynamic characteristics over time.
RNNs introduce a hidden state that allows the network to retain previous information and use it to influence subsequent outputs. This makes RNNs particularly suitable for tasks related to sequences, such as time series data, natural language, and speech.
At each time step, RNNs receive input data and the hidden state from the previous time step, then compute the current time step's hidden state and output. The output can be the classification result of the time step or a comprehensive representation of the entire sequence. The mathematical expression is as follows:
$$ h_t = f(h_{t-1}, x_t) $$
Here, $h_t$ is the hidden state of the current time step, $h_{t-1}$ is the hidden state of the previous time step, $x_t$ is the input of the current time step, and $f$ is a nonlinear activation function.
The hidden state maintains a "state" that can be understood as an encoding of the historical information of the sequence. This state update, i.e., the computation of the hidden layer, is achieved through recurrent connections, hence the name recurrent neural network.
#### 2.1.2 Comparison of RNNs with Other Neural Networks
Compared to traditional feedforward neural networks, the most significant difference with RNNs is their ability to process sequential data, ***
***pared to convolutional neural networks (CNNs), although CNNs can also process sequential data, their focus is on capturing local patterns through local receptive fields, while RNNs emphasize information transfer over time.
In addition to standard RNNs, there are several special recurrent network structures, such as Long Short-Term Memory (LSTM) networks and Gated Recurrent Units (GRUs), designed to solve the inherent problems of gradient vanishing and explosion in RNNs and to improve modeling capabilities for long-term dependencies. These improved RNN variants are more commonly used in practical applications due to their ability to more effectively train long sequence data.
### 2.2 RNN Mathematical Models and Computational Graphs
#### 2.2.1 Time Step Unfolding and the Vanishing Gradient Problem
In RNNs, due to the recurrent connections between hidden layers, RNNs can be viewed as multiple identical neural network layers connected in series over time. This structural feature leads to RNNs being unfolded into a very deep network during training, causing gradients to be propagated through many time steps during backpropagation. When the time steps are too long, it can result in the vanishing or exploding gradient problem.
The vanishing gradient problem refers to the phenomenon where gradients exponentially decrease in magnitude during backpropagation as the distance of propagation increases, causing the learning process to become very slow. The exploding gradient is the opposite, where gradients exponentially increase, causing unstable weight updates and even numerical overflow.
To address these issues, researchers have proposed various methods, such as using gradient clipping techniques to limit gradient size or using more complex, specially designed RNN variants like LSTMs and GRUs.
#### 2.2.2 Forward Propagation and Backpropagation
Forward propagation refers to the process in RNNs where, at each time step, input data is received and the hidden state is updated. This process continues until the sequence ends. During this process, the network generates output and passes the hidden state to the next time step.
Backpropagation is the process through time (Backpropagation Through Time, BPTT). In traditional backpropagation, error gradients are propagated downward through the network's layers. However, in RNNs, due to the network's unique structure, gradients must be propagated not only through the layers but also across the time dimension. When calculating the gradient for each time step, the gradient from the previous time step is accumulated. This step needs to be recursively repeated until the end of the entire sequence.
This process involves the chain rule, requiring the computation of the local gradient for each time step and combining it with the gradient from the previous time step to update the weights. This is achieved by solving partial derivatives and applying the chain rule, ultimately obtaining the gradient to be updated at each time step.
#### 2.2.3 RNN Variants: LSTMs and GRUs
Due to the gradient vanishing and exploding problems in standard RNNs, researchers have designed two special RNN structures, LSTMs and GRUs, to more effectively handle long-term dependencies.
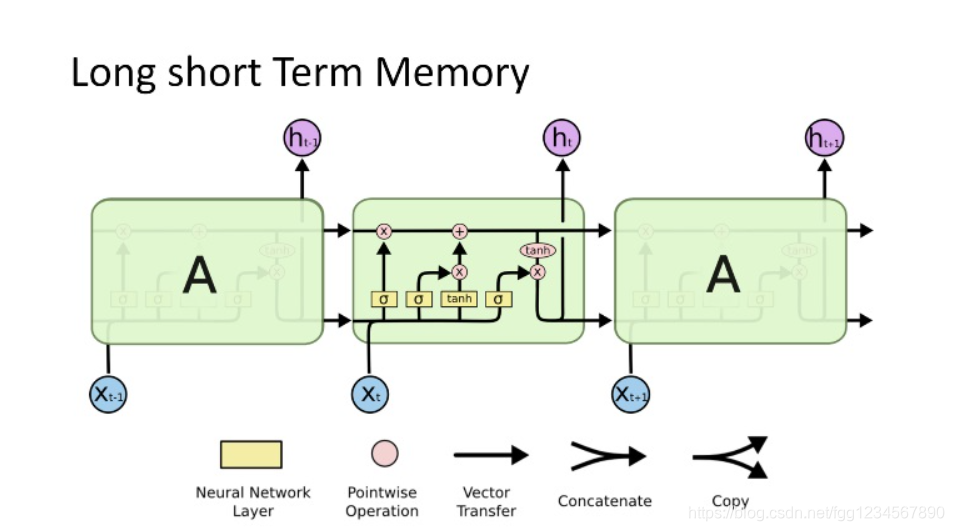
- **LSTM (Long Short-Term Memory):** The design concept of LSTMs is to introduce a gating mechanism at each time step that can decide what information to retain or forget. LSTMs have three gates: the forget gate (decides which information to discard), the input gate (decides which new information is saved into the state), and the output gate (decides the output of the next hidden state). With this design, LSTMs can preserve long-term dependency information in sequences while avoiding the vanishing gradient problem.
- **GRU (Gated Recurrent Unit):** GRUs can be seen as a simplified version of LSTMs. GRUs only use two gates: the reset gate (decides the extent to which new input is combined with old memory), and the update gate (decides how much old memory to retain). GRUs have a simpler structure than LSTMs but can still effectively handle long-term dependency issues.
These variants effectively solve the gradient problem through gating mechanisms and demonstrate outstanding performance in various sequence prediction tasks.
### Code Block Example: Forward Propagation of an RNN Model
Assuming we use the Keras library in Python to define a simple RNN model, here is a simplified code example:
```python
from keras.models import Sequential
from keras.layers import SimpleRNN, Activation
# Create a model
model = Sequential()
# Add an RNN layer, assuming the input sequence length is 10 and the feature dimension is 50
model.add(SimpleRNN(64, input_shape=(10, 50), return_sequences=False))
# Add an activation layer
model.add(Activation('relu'))
# Compile the model
***pile(loss='mean_squared_error', optimizer='adam')
# Print model summary
model.summary()
```
#### Parameter Explanation:
- `Sequential()`: Creates a sequential model.
- `SimpleRNN(64, input_shape=(10, 50), return_sequences=False)`: Adds an RNN layer. Here, 64 neurons are used, and `input_shape` defines the shape of the input data (time step length of 10, feature dimension of 50). `return_sequences=False` indicates that only the last output of each time step is returned.
- `Activation('relu')`: Adds an activation layer using the ReLU activation function.
- `***pile(loss='mean_squared_error', optimizer='adam')`: Compiles the model, using mean squared error as the loss function and the Adam optimizer.
#### Logical Analysis:
In this simple RNN model, we define an input sequence with a length of 10 and a feature dimension of 50. The RNN layer generates output based on this data, and since `return_sequences=False`, we obtain the last output of each time step. The activation layer then applies the ReLU function to increase the model's nonlinear capability. Finally, we specify the loss function and optimizer by compiling the model.
In practical applications, LSTMs or GRUs are often used to build models because they perform better in many tasks, especially when seq

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【SketchUp设计自动化】

# 摘要
本文系统地探讨了SketchUp设计自动化在现代设计行业中的概念与重要性,着重介绍了SketchUp的基础操作、脚本语言特性及其在自动化任务中的应用。通过详细阐述如何通过脚本实现基础及复杂设计任务的自动化
【科大讯飞语音识别:二次开发的6大技巧】:打造个性化交互体验
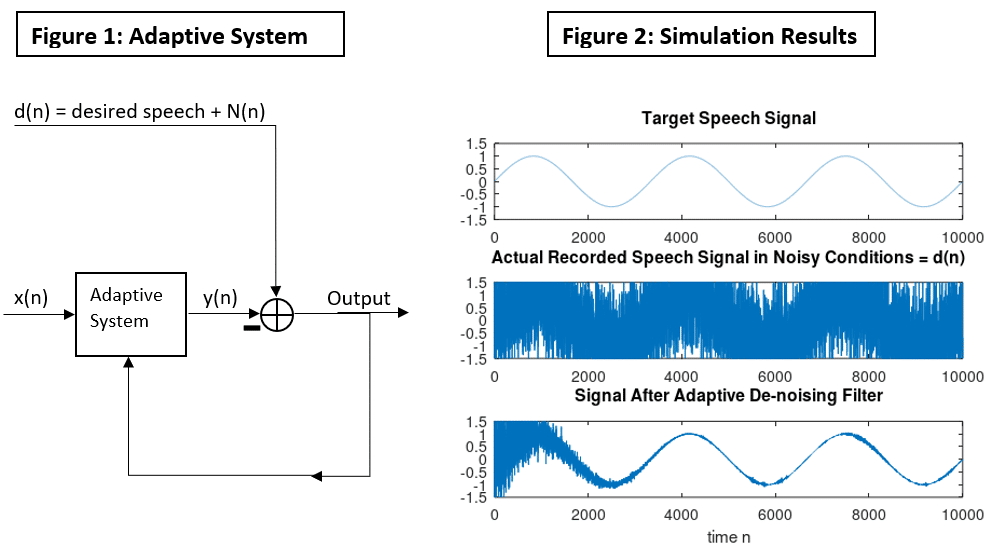
# 摘要
科大讯飞作为领先的语音识别技术提供商,其技术概述与二次开发基础是本篇论文关注的焦点。本文首先概述了科大讯飞语音识别技术的基本原理和API接口,随后深入探讨了二次开发过程中参数优化、场景化应用及后处理技术的实践技巧。进阶应用开发部分着重讨论了语音识别与自然语言处理的结合、智能家居中的应用以及移动应用中的语音识别集成。最后,论文分析了性能调优策略、常见问题解决方法,并展望了语音识别技术的未来趋势,特别是人工
【电机工程独家技术】:揭秘如何通过磁链计算优化电机设计

# 摘要
电机工程的基础知识与磁链概念是理解和分析电机性能的关键。本文首先介绍了电机工程的基本概念和磁链的定义。接着,通过深入探讨电机电磁学的基本原理,包括电磁感应定律和磁场理论基础,建立了电机磁链的理论分析框架。在此基础上,详细阐述了磁链计算的基本方法和高级模型,重点包括线圈与磁通的关系以及考虑非线性和饱和效应的模型。本文还探讨了磁链计算在电机设计中的实际应
【用户体验(UX)在软件管理中的重要性】:设计原则与实践

# 摘要
用户体验(UX)是衡量软件产品质量和用户满意度的关键指标。本文深入探讨了UX的概念、设计原则及其在软件管理中的实践方法。首先解析了用户体验的基本概念,并介绍了用户中心设计(UCD)和设计思维的重要性。接着,文章详细讨论了在软件开发生命周期中整合用户体验的重要性,包括敏捷开发环境下的UX设计方法以及如何进行用户体验度量和评估。最后,本文针对技术与用户需求平
【MySQL性能诊断】:如何快速定位和解决数据库性能问题

# 摘要
MySQL作为广泛应用的开源数据库系统,其性能问题一直是数据库管理员和技术人员关注的焦点。本文首先对MySQL性能诊断进行了概述,随后介绍了性能诊断的基础理论,包括性能指标、监控工具和分析方法论。在实践技巧章节,文章提供了SQL优化策略、数据库配置调整和硬件资源优化建议。通过分析性能问题解决的案例,例如慢
【硬盘管理进阶】:西数硬盘检测工具的企业级应用策略(企业硬盘管理的新策略)

# 摘要
硬盘作为企业级数据存储的核心设备,其管理与优化对企业信息系统的稳定运行至关重要。本文探讨了硬盘管理的重要性与面临的挑战,并概述了西数硬盘检测工具的功能与原理。通过深入分析硬盘性能优化策略,包括性能检测方法论与评估指标,本文旨在为企业提供硬盘维护和故障预防的最佳实践。此外,本文还详细介绍了数据恢复与备份的高级方法,并探讨了企业硬盘管理的未来趋势,包括云存储和分布式存储的融合,以及智能化管理工具的发展
【sCMOS相机驱动电路调试实战技巧】:故障排除的高手经验
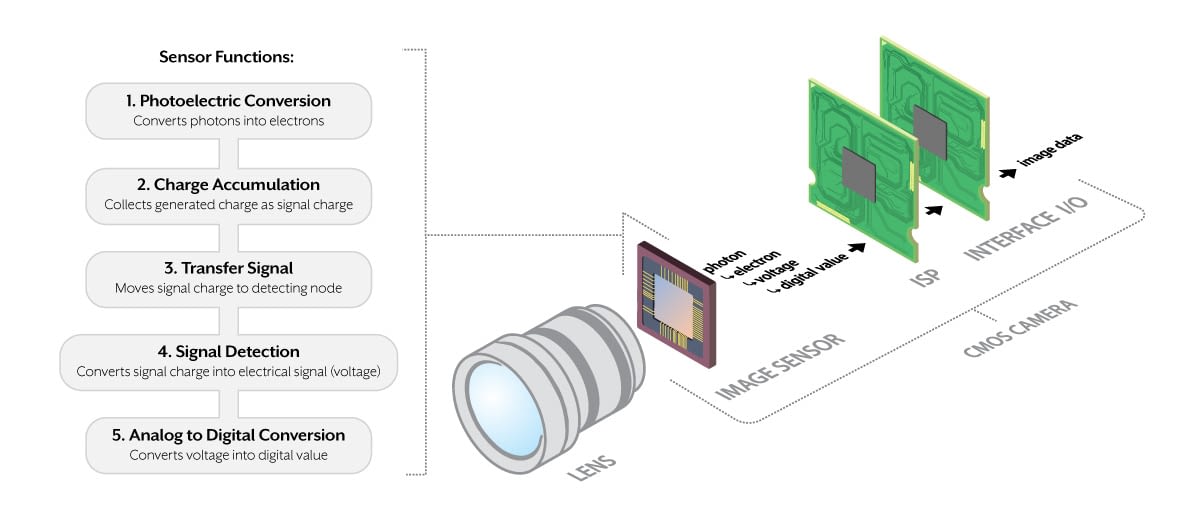
# 摘要
sCMOS相机驱动电路是成像设备的重要组成部分,其性能直接关系到成像质量与系统稳定性。本文首先介绍了sCMOS相机驱动电路的基本概念和理论基础,包括其工作原理、技术特点以及驱动电路在相机中的关键作用。其次,探讨了驱动电路设计的关键要素,
【LSTM双色球预测实战】:从零开始,一步步构建赢率系统
# 摘要
本文旨在通过LSTM(长短期记忆网络)技术预测双色球开奖结果。首先介绍了LSTM网络及其在双色球预测中的应用背景。其次,详细阐述了理
EMC VNX5100控制器SP更换后性能调优:专家的最优实践

# 摘要
本文全面介绍了EMC VNX5100存储控制器的基本概念、SP更换流程、性能调优理论与实践以及故障排除技巧。首先概述了VNX5100控制器的特点以及更换服务处理器(SP)前的准备工作。接着,深入探讨了性能调优的基础理论,包括性能监控工具的使用和关键性能参数的调整。此外,本文还提供了系统级性能调优的实际操作指导
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )