Time Series Forecasting with Ensemble Learning: Expert Guide to Enhancing Accuracy
发布时间: 2024-09-15 06:51:45 阅读量: 57 订阅数: 27 
# 1. Overview of Time Series Forecasting
In this chapter, we will begin by exploring the basics of time series forecasting and lay the foundation for a deeper dive into ensemble learning and its applications in time series forecasting in subsequent chapters. Firstly, we will define time series forecasting and explain its importance in a wide range of fields. Time series forecasting is the process of predicting future values or states at certain points in time based on historical data sequences and is widely applied in economic forecasting, weather prediction, stock market analysis, and more. We will then briefly discuss the basic steps in the time series forecasting process, including data collection, cleaning, modeling, and prediction, as well as the common issues that may arise at each step. By the end of this chapter, readers will have a comprehensive fundamental understanding of time series forecasting and will have laid a solid foundation for in-depth understanding of the application of ensemble learning in this field.
# 2. Theoretical Foundations of Ensemble Learning
In this chapter, we will delve into the theoretical foundations of ensemble learning, understanding its definition, advantages, and core algorithms, and discussing the characteristics of different ensemble strategies and how to make choices in practical applications.
## 2.1 Definition and Advantages of Ensemble Learning
### 2.1.1 Conceptual Analysis of Ensemble Learning
Ensemble Learning is a technique that involves constructing and combining multiple learners to perform a learning task, with the core idea of combining the strengths of multiple models to achieve better predictive performance than a single model. In machine learning, a single model can often be limited by its structural limitations, such as overfitting or underfitting issues, and ensemble learning can smooth out model errors and improve generalization by combining multiple models.
Ensemble learning can be divided into homogeneous and heterogeneous ensembles. Homogeneous ensembles refer to using the same learning algorithm to construct multiple models, while heterogeneous ensembles involve using different learning algorithms to construct multiple models. In practical applications, ensemble methods based on bagging, boosting, and stacking are the most common and popular.
### 2.1.2 Principles of Ensemble Learning for Improving Forecast Accuracy
The reasons why ensemble learning can improve predictive accuracy mainly include the following points:
- **Error Decomposition**: Ensemble learning improves model performance by decomposing bias and variance. Different models may exhibit bias or variance on different subsets of data, and combining them can offset their errors, resulting in a reduction in overall error.
- **Model Diversity**: The models in the ensemble should have a certain degree of diversity, which can be obtained from the data level (e.g., different subsamples) or the model level (e.g., different algorithms or model structures). Diversity ensures the independence of erroneous predictions among models, thereby enhancing the overall performance of the ensemble.
- **Combination of Strong Learners**: Although a single strong learner may already have good performance, combining multiple strong learners can further reduce overall errors, improving the stability and reliability of the model.
## 2.2 Core Algorithms of Ensemble Learning
### 2.2.1 Bagging Method
Bagging, short for Bootstrap Aggregating, is a parallel ensemble learning method that constructs multiple models by repeatedly randomly sampling with replacement from the original training set, and ultimately combines the predictions of these models through voting (for classification problems) or averaging (for regression problems) to obtain the final result.
#### Key Algorithm Features:
- **Bootstrap Sampling**: Randomly drawing samples with replacement from the original data set to train the models.
- **Parallelism**: Each base learner is trained independently, allowing for parallel processing and increased efficiency.
- **Variance Reduction**: Reducing variance and improving overall generalization by combining the predictions of different models.
```python
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
# Creating a Bagging classifier instance based on the decision tree classifier
bagging_clf = BaggingClassifier(DecisionTreeClassifier(),
n_estimators=500,
bootstrap=True,
oob_score=True)
# Training the model
bagging_clf.fit(X_train, y_train)
# Evaluating model performance using OOB data
print('OOB score:', bagging_clf.oob_score_)
```
In the above code, we use the `BaggingClassifier` from the `sklearn` library to create a Bagging ensemble model based on decision tree classifiers. By setting the `n_estimators` parameter to 500, we define 500 base learners. `bootstrap=True` indicates the use of the bootstrap sampling method, and `oob_score=True` allows us to evaluate the model performance using the out-of-sample data (Out-Of-Bag data), which is also a feature of Bagging.
### 2.2.2 Boosting Method
Boosting is a sequential ensemble method that sequentially trains multiple models, with each model attempting to improve upon the performance of the previous one. The key to Boosting is the iterative adjustment of data sample weights, increasing the weights of samples that were incorrectly classified by previous models so that subsequent models pay more attention to these samples.
#### Key Algorithm Features:
- **Sequential Addition of Models**: Each base learner attempts to correct the errors of the previous model.
- **Sample Weight Adjustment**: Increasing the weights of samples that were incorrectly classified by the previous model and decreasing the weights of correctly classified samples.
- **Model Diversity**: Although all models attempt to solve the same problem, Boosting can construct diverse models by adjusting weights.
```python
from sklearn.ensemble import GradientBoostingClassifier
# Creating a Boosting classifier instance
boosting_clf = GradientBoostingClassifier(n_estimators=200)
# Training the model
boosting_clf.fit(X_train, y_train)
# Making predictions with the trained model
predictions = boosting_clf.predict(X_test)
```
The above code uses the `GradientBoostingClassifier`, which is an implementation of the Boosting family in `sklearn`. By setting the `n_estimators` parameter, we define 200 base learners. The Boosting method sequentially constructs decision trees using the Gradient Boosting algorithm, with each tree being built on the reduction of the residuals from the previous step.
### 2.2.3 Stacking Method
Stacking (Stacked Generalization) is another strategy of ensemble learning that uses the predictions of different learning algorithms as input to train a new meta-model to generate the final predictions. Stacking builds a hierarchical structure of machine learning models, allowing different levels of models to learn from and build upon each other.
#### Key Algorithm Features:
- **Two-Level Model Structure**: The first level is the base learner, and the second level is the meta-learner.
- **Complementarity of Different Algorithms**: The base learner can be different algorithms to achieve model complementarity.
- **Importance of Meta-Learner**: The performance of the meta-learner is crucial for the Stacking method.
```python
from sklearn.ensemble import StackingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
# Defining a list of base classifiers
base_clfs = [('logistic', LogisticRegression()),
('svm', SVC()),
('tree', DecisionTreeClassifier())]
# Defining the meta-learner
meta_clf = LogisticRegression()
# Creating a Stacking classifier instance
stacking_clf = StackingClassifier(estimators=base_clfs, final_estimator=meta_clf)
# Training the model
stacking_clf.fit(X_train, y_train)
# Making predictions with the trained model
predictions = stacking_clf.predict(X_test)
```
In the above code, we create a `StackingClassifier` instance containing three base learners, namely logistic regression, support vector machine, and decision tree. The meta-learner uses logistic regression to integrate the outputs of the base learners. The effectiveness of the Stacking method largely depends on the selection of base learners and the meta-learner.
## 2.3 Comparison and Selection of Ensemble Learning Strategies
### 2.3.1 Analysis of the Characteristics of Different Ensemble Strategies
- **Bagging**: Suitable for improving the stability and reliability of strong learners, especially effective in preventing overfitting. Due to its parallelism, Bagging models can be constructed quickly and easily implemented. However, it is not as effective as Boosting in enhancing model predictive performance.
- **Boosting**: Compared to Bagging, Boosting has better predictive performance, especially for complex learners such as decision trees. However, Boosting requires a longer training time and is prone to overfitting. In addition, its sequential nature requires a good complementarity between models.
- **Stacking**: By combining the strengths of different algorithms, Stacking can flexibly integrate various learners. However, the choice of meta-learner and parameter tuning are more complex than other methods, and it relies on the predictive power of base learners, making the choice of base learners crucial.
### 2.3.2 Practical Considerations: Factors in Strategy Selection
The choice of which ensemble learning strategy to use often depends on the specific needs of the problem and the characteristics of the data:
- **Data Volume and Computational Resources**: If the dataset is very large and efficient model training is required, Bagging may be a better choice due to its parallelism, which allows models to be trained quickly. Conversely, if the data volume is not large and computational resources are abundant, Boosting and Stacking may be better options.
- **Complexity of the Problem**: For complex classification or regression tasks, Boosting may perform better. If the problem has a high degree of imbalance, Boosting's weight adjustment mechanism may perform better.
- **Model Diversity**: If the

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
硬件加速在目标检测中的应用:FPGA vs. GPU的性能对比
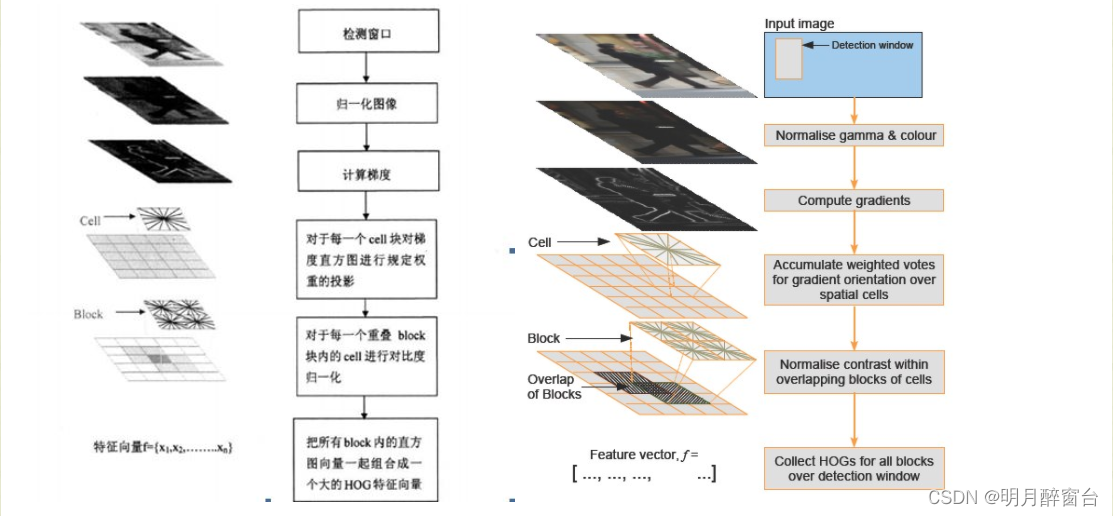
# 1. 目标检测技术与硬件加速概述
目标检测技术是计算机视觉领域的一项核心技术,它能够识别图像中的感兴趣物体,并对其进行分类与定位。这一过程通常涉及到复杂的算法和大量的计算资源,因此硬件加速成为了提升目标检测性能的关键技术手段。本章将深入探讨目标检测的基本原理,以及硬件加速,特别是FPGA和GPU在目标检测中的作用与优势。
## 1.1 目标检测技术的演进与重要性
目标检测技术的发展与深度学习的兴起紧密相关
【商业化语音识别】:技术挑战与机遇并存的市场前景分析
# 1. 商业化语音识别概述
语音识别技术作为人工智能的一个重要分支,近年来随着技术的不断进步和应用的扩展,已成为商业化领域的一大热点。在本章节,我们将从商业化语音识别的基本概念出发,探索其在商业环境中的实际应用,以及如何通过提升识别精度、扩展应用场景来增强用户体验和市场竞争力。
## 1.1 语音识别技术的兴起背景
语音识别技术将人类的语音信号转化为可被机器理解的文本信息,它
Pandas数据转换:重塑、融合与数据转换技巧秘籍

# 1. Pandas数据转换基础
在这一章节中,我们将介绍Pandas库中数据转换的基础知识,为读者搭建理解后续章节内容的基础。首先,我们将快速回顾Pandas库的重要性以及它在数据分析中的核心地位。接下来,我们将探讨数据转换的基本概念,包括数据的筛选、清洗、聚合等操作。然后,逐步深入到不同数据转换场景,对每种操作的实际意义进行详细解读,以及它们如何影响数
优化之道:时间序列预测中的时间复杂度与模型调优技巧
# 1. 时间序列预测概述
在进行数据分析和预测时,时间序列预测作为一种重要的技术,广泛应用于经济、气象、工业控制、生物信息等领域。时间序列预测是通过分析历史时间点上的数据,以推断未来的数据走向。这种预测方法在决策支持系统中占据着不可替代的地位,因为通过它能够揭示数据随时间变化的规律性,为科学决策提供依据。
时间序列预测的准确性受到多种因素的影响,例如数据
NumPy在金融数据分析中的应用:风险模型与预测技术的6大秘籍

# 1. NumPy基础与金融数据处理
金融数据处理是金融分析的核心,而NumPy作为一个强大的科学计算库,在金融数据处理中扮演着不可或缺的角色。本章首先介绍NumPy的基础知识,然后探讨其在金融数据处理中的应用。
## 1.1 NumPy基础
NumPy(N
【循环神经网络】:TensorFlow中RNN、LSTM和GRU的实现

# 1. 循环神经网络(RNN)基础
在当今的人工智能领域,循环神经网络(RNN)是处理序列数据的核心技术之一。与传统的全连接网络和卷积网络不同,RNN通过其独特的循环结构,能够处理并记忆序列化信息,这使得它在时间序列分析、语音识别、自然语言处理等多
【图像分类模型自动化部署】:从训练到生产的流程指南

# 1. 图像分类模型自动化部署概述
在当今数据驱动的世界中,图像分类模型已经成为多个领域不可或缺的一部分,包括但不限于医疗成像、自动驾驶和安全监控。然而,手动部署和维护这些模型不仅耗时而且容易出错。随着机器学习技术的发展,自动化部署成为了加速模型从开发到生产的有效途径,从而缩短产品上市时间并提高模型的性能和可靠性。
本章旨在为读者提供自动化部署图像分类模型的基本概念和流程概览,
PyTorch超参数调优:专家的5步调优指南

# 1. PyTorch超参数调优基础概念
## 1.1 什么是超参数?
在深度学习中,超参数是模型训练前需要设定的参数,它们控制学习过程并影响模型的性能。与模型参数(如权重和偏置)不同,超参数不会在训练过程中自动更新,而是需要我们根据经验或者通过调优来确定它们的最优值。
## 1.2 为什么要进行超参数调优?
超参数的选择直接影响模型的学习效率和最终的性能。在没有经过优化的默认值下训练模型可能会导致以下问题:
- **过拟合**:模型在
Keras注意力机制:构建理解复杂数据的强大模型

# 1. 注意力机制在深度学习中的作用
## 1.1 理解深度学习中的注意力
深度学习通过模仿人脑的信息处理机制,已经取得了巨大的成功。然而,传统深度学习模型在处理长序列数据时常常遇到挑战,如长距离依赖问题和计算资源消耗。注意力机制的提出为解决这些问题提供了一种创新的方法。通过模仿人类的注意力集中过程,这种机制允许模型在处理信息时,更加聚焦于相关数据,从而提高学习效率和准确性。
## 1.2
【数据集加载与分析】:Scikit-learn内置数据集探索指南

# 1. Scikit-learn数据集简介
数据科学的核心是数据,而高效地处理和分析数据离不开合适的工具和数据集。Scikit-learn,一个广泛应用于Python语言的开源机器学习库,不仅提供了一整套机器学习算法,还内置了多种数据集,为数据科学家进行数据探索和模型验证提供了极大的便利。本章将首先介绍Scikit-learn数据集的基础知识,包括它的起源、
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )