Time Series Forecasting Model Selection: An Expert Guide to Finding the Best Approach
发布时间: 2024-09-15 06:26:28 阅读量: 36 订阅数: 29 

multivariate-timeseries-forecasting:一组用于多元时间序列预测的算法
# Machine Learning Methods in Time Series Forecasting
## Theoretical Foundations of Time Series Forecasting
### Concepts and Importance of Time Series
Time series forecasting is a significant branch of data analysis that involves the study of data points arranged in chronological order to predict the values of future data points. Time series data can be continuous, such as stock price fluctuations every second, or discrete, such as monthly sales figures.
In the IT industry, time series forecasting is widely applied to business demand forecasting, network traffic analysis, and energy consumption forecasting, among other areas. Accurate time series analysis empowers businesses to make more scientific decisions, optimize resource allocation, and enhance operational efficiency.
### Key Elements of Time Series Forecasting
The critical elements of time series forecasting include Trend, Seasonality, Cyclicity, and Irregular Component. Understanding these elements is crucial for building an accurate predictive model.
- **Trend** reflects the long-term movement of data, whether it is increasing or decreasing over time.
- **Seasonality** refers to the pattern of data repeating periodically at fixed intervals.
- **Cyclicity** is similar to seasonality but describes periodic fluctuations at non-fixed time intervals.
- **Irregular Component** refers to the impact of random fluctuations or unexpected events on the data.
### Methodologies in Time Series Forecasting
Time series forecasting methods are primarily divided into two categories: quantitative and qualitative. Quantitative methods include statistical models such as ARIMA and exponential smoothing methods, while qualitative methods rely more on expert experience and judgment.
In subsequent chapters, we will delve into specific time series forecasting models and understand how to select and apply these models in practice. Next, we will elaborate on how to use time series data for forecasting through illustrative examples.
# Practical Application and Application of Time Series Forecasting Models
### Understanding the Importance of Time Series Forecasting
In the field of data science, time series forecasting is one of the core issues because it can assist enterprises and organizations in decision-making, predicting market trends, and managing inventory, among other things. Understanding the practical application of time series forecasting models can help us better understand the trends and patterns of data changes and make reasonable predictions about future situations.
### Preparations Before Practicing
Before beginning to build a time series forecasting model, some preparations must be made. This includes data collection, data cleaning, and exploratory data analysis. Data collection requires us to determine the data source, data cleaning involves checking for and correcting missing and abnormal values in the dataset, and exploratory data analysis requires us to use statistical charts, such as box plots and line charts, to observe data characteristics, understanding the temporal attributes and seasonal characteristics of the data.
### Construction and Application of Time Series Forecasting Models
The construction of time series forecasting models can employ ARIMA models, seasonal decomposition models, and machine learning models such as Random Forests and Gradient Boosting Decision Trees. During the model construction process, we need to train and test the model, analyze its performance, and then optimize based on the model's predictive results.
#### Example Application of ARIMA Model
Taking the ARIMA model as an example, the ARIMA model is an autoregressive integrated moving average model that can describe the three key components of time series data: the autoregressive part (AR), the difference part (I), and the moving average part (MA).
```python
from statsmodels.tsa.arima.model import ARIMA
# Assume we have a set of time series data data
# Applying the ARIMA model
model = ARIMA(data, order=(1, 1, 1))
model_fit = model.fit()
# Forecasting the data for the next time point
forecast = model_fit.forecast(steps=1)
print(forecast)
```
In the above code, we first imported the ARIMA model, then instantiated it with a set of assumed time series data, setting the model's parameters to one autoregressive term, one difference order, and one moving average term. Next, we called the fit method to train the model and the forecast method to predict the data for the next time point.
#### Example Application of Seasonal Decomposition Model
The seasonal decomposition model can decompose a sequence with obvious seasonal characteristics and predict future seasonal behavior.
```python
from statsmodels.tsa.seasonal import seasonal_decompose
# Perform seasonal decomposition on the data
decomposition = seasonal_decompose(data, model='multiplicative')
# Plot the results of seasonal decomposition
decomposition.plot()
```
### Challenges in Practice
In the practice of time series forecasting models, we will encounter various challenges, such as data non-stationarity, model overfitting, and underfitting. We need to ensure data stability through data differentiation, seasonal adjustment, and other methods, and avoid model overfitting and underfitting through techniques such as cross-validation.
### Summary of This Chapter
Through the introduction of this chapter, we have understood the importance of the practice and application of time series forecasting models, the preparations before model construction, and the practical application examples of ARIMA and seasonal decomposition models. At the same time, we have also realized the challenges that may be encountered in practice and the strategies that need to be adopted. In the next chapter, we will delve deeper into model evaluation, optimization, and advanced applications.
# Evaluation and Selection of Time Series Forecasting Models
## The Importance of Model Evaluation
In the field of time series forecasting, choosing the appropriate model is crucial for the accuracy of the prediction results. Evaluating models allows us to understand the model's fit to historical data and its predictive ability for future data. There are many indicators for measuring model performance, such as Mean Squared Error (MSE), Root Mean Squared Error (RMSE), and Mean Absolute Error (MAE).
### Model Evaluation Indicators
#### Mean Squared Error (MSE)
MSE is the average of the squared prediction errors, and its formula is:
```
MSE = 1/n * Σ (yi - ŷi)²
```
Where n is the number of samples, yi is the true value, and ŷi is the predicted value.
```python
from sklearn.metrics import mean_squared_error
import numpy as np
# Assume y_true is the array of true values, and y_pred is the array of predicted v
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【停车场管理新策略:E7+平台高级数据分析】
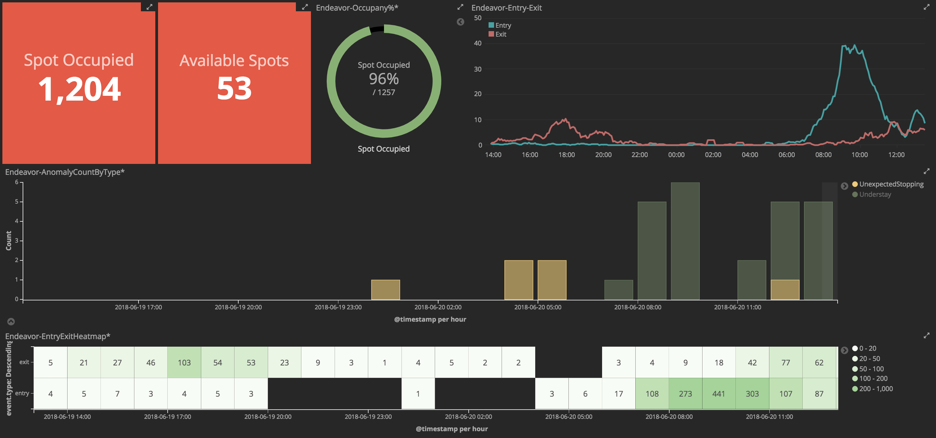
# 摘要
E7+平台是一个集数据收集、整合和分析于一体的智能停车场管理系统。本文首先对E7+平台进行介绍,然后详细讨论了停车场数据的收集与整合方法,包括传感器数据采集技术和现场数据规范化处理。在数据分析理论基础章节,本文阐述了统计分析、时间序列分析、聚类分析及预测模型等高级数据分析技术。E7+平台数据分析实践部分重点分析了实时数据处理及历史数据分析报告的生成。此外,本文还探讨了高级分析技术在交通流
【固件升级必经之路】:从零开始的光猫固件更新教程

# 摘要
固件升级是光猫设备持续稳定运行的重要环节,本文对固件升级的概念、重要性、风险及更新前的准备、下载备份、更新过程和升级后的测试优化进行了系统解析。详细阐述了光猫的工作原理、固件的作用及其更新的重要性,以及在升级过程中应如何确保兼容性、准备必要的工具和资料。同时,本文还提供了光猫固件下载、验证和备份的详细步骤,强调了更新过程中的安全措施,以及更新后应如何进行测试和优化配置以提高光猫的性能和稳定性。
【功能深度解析】:麒麟v10 Openssh新特性应用与案例研究

# 摘要
本文详细介绍了麒麟v10操作系统集成的OpenSSH的新特性、配置、部署以及实践应用案例。文章首先概述了麒麟v10与OpenSSH的基础信息,随后深入探讨了其核心新特性的三个主要方面:安全性增强、性能提升和用户体验改进。具体包括增加的加密算法支持、客户端认证方式更新、传输速度优化和多路复用机制等。接着,文中描述了如何进行安全配置、高级配置选项以及部署策略,确保系
QT多线程编程:并发与数据共享,解决之道详解

# 摘要
本文全面探讨了基于QT框架的多线程编程技术,从基础概念到高级应用,涵盖线程创建、通信、同步,以及数据共享与并发控制等多个方面。文章首先介绍了QT多线程编程的基本概念和基础架构,重点讨论了线程间的通信和同步机制,如信号与槽、互斥锁和条件变量。随后深入分析了数据共享问题及其解决方案,包括线程局部存储和原子操作。在
【Green Hills系统性能提升宝典】:高级技巧助你飞速提高系统性能
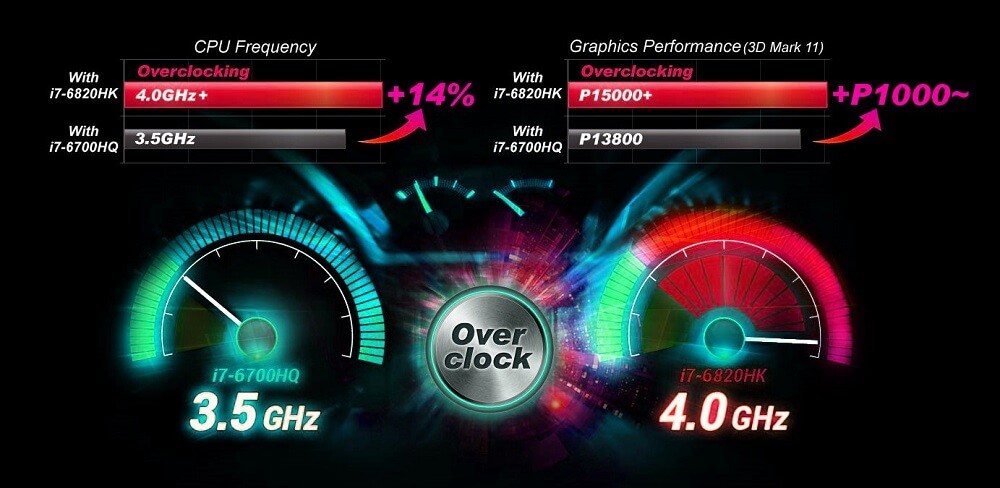
# 摘要
系统性能优化是确保软件高效、稳定运行的关键。本文首先概述了性能优化的重要性,并详细介绍了性能评估与监控的方法,包括对CPU、内存和磁盘I/O性能的监控指标以及相关监控工具的使用。接着,文章深入探讨了系统级性能优化策略,涉及内核调整、应用程序优化和系统资源管理。针对内存管理,本文分析了内存泄漏检测、缓存优化以及内存压缩技术。最后,文章研究了网络与
MTK-ATA与USB互操作性深入分析:确保设备兼容性的黄金策略
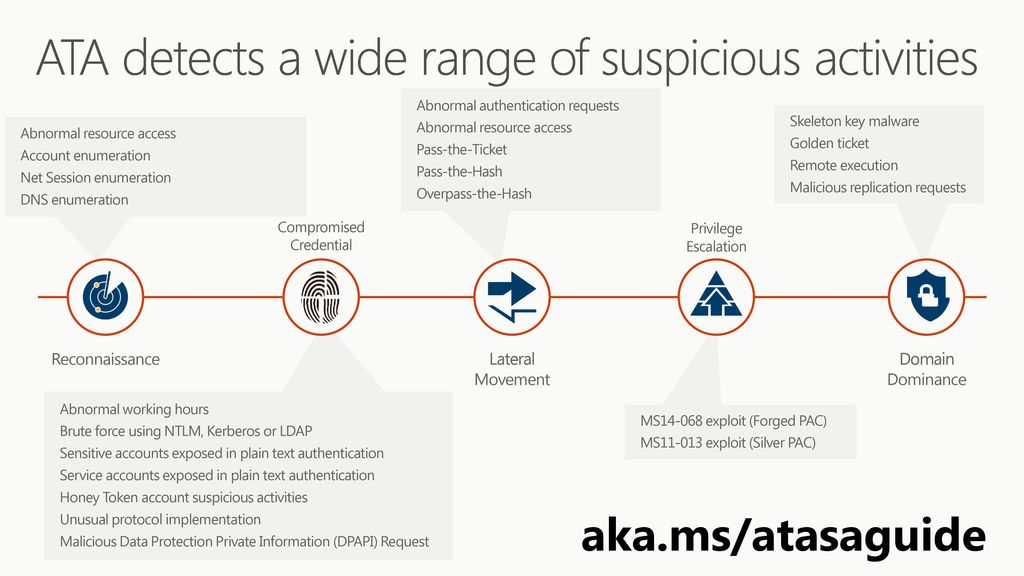
# 摘要
本文深入探讨了MTK-ATA与USB技术的互操作性,重点分析了两者在不同设备中的应用、兼容性问题、协同工作原理及优化调试策略。通过阐述MTK-ATA技术原理、功能及优化方法,并对比USB技术的基本原理和分类,本文揭示了两者结合时可能遇到的兼容性问题及其解决方案。同时,通过多个实际应用案例的分析,本文展示
零基础学习PCtoLCD2002:图形用户界面设计与LCD显示技术速成

# 摘要
随着图形用户界面(GUI)和显示技术的发展,PCtoLCD2002作为一种流行的接口工具,已经成为连接计算机与LCD显示设备的重要桥梁。本文首先介绍了图形用户界面设计的基本原则和LCD显示技术的基础知识,然后详细阐述了PCtoLCD200
【TIB文件编辑终极教程】:一学就会的步骤教你轻松打开TIB文件

# 摘要
TIB文件格式作为特定类型的镜像文件,在数据备份和系统恢复领域具有重要的应用价值。本文从TIB文件的概述和基础知识开始,深入分析了其基本结构、创建流程和应用场景,同时与其他常见的镜像文件格式进行了对比。文章进一步探讨了如何打开和编辑TIB文件,并详细介绍了编辑工具的选择、安装和使用方法。本文还对TIB文件内容的深入挖掘提供了实践指导,包括数据块结构的解析
单级放大器稳定性分析:9个最佳实践,确保设备性能持久稳定

# 摘要
单级放大器稳定性对于电子系统性能至关重要。本文从理论基础出发,深入探讨了单级放大器的工作原理、稳定性条件及其理论标准,同时分析了稳定性分析的不同方法。为了确保设计的稳定性,本文提供了关于元件选择、电路补偿技术及预防振荡措施的最佳实践。此外,文章还详细介绍了稳定性仿真与测试流程、测试设备的使用、测试结果的分析方法以及仿真与测试结果的对比研究。通过对成功与失败案例的分析,总结了实际应用中稳定性解决方案的实施经验与教训。最后,展望了未来放
信号传输的秘密武器:【FFT在通信系统中的角色】的深入探讨

# 摘要
快速傅里叶变换(FFT)是一种高效的离散傅里叶变换算法,广泛应用于数字信号处理领域,特别是在频谱分析、滤波处理、压缩编码以及通信系统信号处理方面。本文
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )