Feature Engineering for Time Series Forecasting: Experts Guide You in Building Forecasting Gold Standards
发布时间: 2024-09-15 06:30:46 阅读量: 44 订阅数: 27 
## Chapter 1: Fundamental Theories of Time Series Forecasting
In this chapter, we will delve into the core concepts and theoretical foundations of time series forecasting. Time series forecasting is a process that uses historical data and specific mathematical models to predict data at a certain point in the future or within a period of time. Time series data typically refers to observations ordered in time, such as stock prices, temperature changes, sales records, and more.
Time series analysis focuses on four basic components:
1. Trend: The long-term upward or downward movement.
2. Seasonality: Patterns that repeat at fixed intervals.
3. Cyclical: Fluctuations with non-fixed periods, similar to economic cycles.
4. Irregular: Unpredictable random fluctuations.
Understanding these components is crucial for constructing accurate time series forecasting models. The following chapters will interpret each part in detail and discuss how they are closely integrated with feature engineering, data preprocessing, and model construction and evaluation in practical applications.
## Chapter 2: The Importance of Feature Engineering in Time Series Forecasting
### 2.1 The Relationship Between Feature Engineering and Time Series Forecasting
#### Challenges in Time Series Forecasting
As a branch of data analysis, time series forecasting plays a significant role in business and scientific research. For instance, in economic analysis, stock price prediction, weather forecasting, and supply chain management, time series forecasting is an essential tool for predicting future trends and making decisions. However, time series data is typically noisy, non-stationary, and seasonal, posing many challenges for forecasting.
#### The Role of Feature Engineering
Feature engineering is a critical step in addressing such issues. It involves extracting information from raw data to construct features that assist in the prediction task. In time series forecasting, feature engineering encompasses preprocessing of raw data and includes feature selection, construction, and transformation, aiming to improve model performance. Feature engineering can enhance the signal that the model learns, reduce noise and dimensionality, and thus increase the model's predictive accuracy and generalization ability.
#### The Importance of Feature Engineering
Good features can capture potential regularities and trends in data, allowing the model to better understand and predict the future. An effective feature engineering process can significantly improve model performance, sometimes even more so than model selection and hyperparameter tuning. Through feature engineering, we can extract time dependencies, periodicity, and other characteristics from time series data, providing more useful information for the model.
#### Challenges in Feature Engineering
Feature engineering is an iterative process that requires domain knowledge. It necessitates that analysts have a deep understanding of the dataset, the actual meanings behind the data, and the business logic. Additionally, feature engineering for time series data often involves complex temporal dependencies that may require sophisticated statistical methods and machine learning algorithms to capture. Feature selection and construction not only require professional knowledge but also a significant amount of experimentation and validation to determine.
### 2.2 The Application of Feature Engineering in Different Scenarios
#### Scenario 1: Financial Industry
In the financial industry, time series forecasting is commonly used for stock price prediction and the development of trading strategies. Here, feature engineering might include calculating historical price information, trading volume, moving averages, etc. By analyzing patterns and signals in historical data, feature engineering can help predict future stock trends.
#### Scenario 2: Manufacturing
In manufacturing, time series forecasting can be used to predict equipment failures and maintenance needs. Feature engineering might involve analyzing sensor data such as temperature, pressure, and sound from equipment operation. By analyzing these sensor data, we can extract features indicating the health of the equipment, which can then be used to predict potential failures.
#### Scenario 3: Retail
In retail, time series forecasting is typically used for sales forecasting and inventory management. Feature engineering might include factors such as seasonality, promotional activities, holidays, and other factors that affect sales. By extracting and analyzing these features, retailers can more accurately predict future sales figures, thus effectively managing inventory and formulating sales strategies.
### 2.3 Best Practices in Feature Engineering
#### Best Practices in Feature Selection
Feature selection aims to choose the most helpful subset from a large number of features. This can be achieved through statistical tests, model-based feature importance evaluations, and correlation-based filtering. For example, models like Random Forests or Gradient Boosting Trees can be used to assess feature importance. In addition, considering the correlation between different features and avoiding multicollinearity is an important consideration in feature selection.
#### Best Practices in Feature Construction
Feature construction involves creating new features through mathematical transformations or combining existing ones. This can be accomplished by defining transformations based on domain knowledge, aggregation functions, or interaction terms. For example, in time series, data within a certain time window can be aggregated into averages or sums to create new features; or by considering lag values in the time series to capture dynamic features. When constructing features, it is essential to consider the actual meaning of the data and business logic to ensure that new features are meaningful.
#### Best Practices in Feature Transformation
Feature transformation is used to improve the distribution of features or make them more consistent with the model'***mon transformation methods include standardization, normalization, logarithmic transformation, Box-Cox transformation, etc. For example, in many machine learning models, the scale of features can significantly affect the model's performance. Therefore, standardizing or normalizing features to a certain range can improve the model's convergence speed and prediction accuracy. Furthermore, for positively skewed data, logarithmic transformation can help reduce the impact of extreme values, making the data more normally distributed.
#### Best Practices in Feature Reduction
Feature reduction is the process of reducing the number of features, which helps prevent overfitting, increase the model's interpretability, and reduce the consumption of computational resources. Dimensionality reduction can be achieved through algorithms such as Principal Component Analysis (PCA) and Linear Discriminant Analysis (LDA). In time series forecasting, PCA can identify the most important components of the data, which are summaries of linear combinations of the original features and capture the main variations in the data. Dimensionality reduction techniques are particularly useful in dealing with high-dimensional time series data, significantly enhancing model performance.
### 2.4 The Impact of Feature Engineering on Model Performance
#### Positive Impacts of Feature Engineering on Model Performance
Op

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
模型参数泛化能力:交叉验证与测试集分析实战指南

# 1. 交叉验证与测试集的基础概念
在机器学习和统计学中,交叉验证(Cross-Validation)和测试集(Test Set)是衡量模型性能和泛化能力的关键技术。本章将探讨这两个概念的基本定义及其在数据分析中的重要性。
## 1.1 交叉验证与测试集的定义
交叉验证是一种统计方法,通过将原始数据集划分成若干小的子集,然后将模型在这些子集上进行训练和验证,以
探索与利用平衡:强化学习在超参数优化中的应用
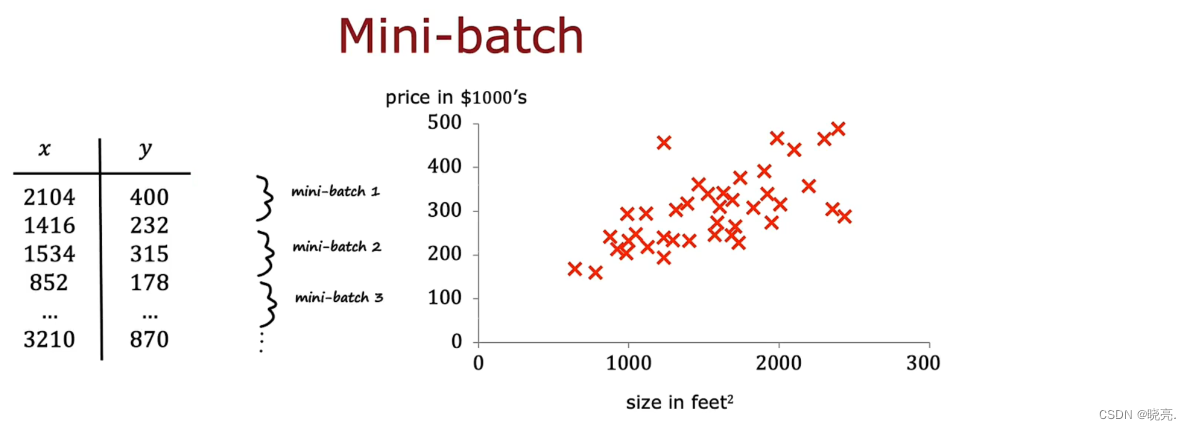
# 1. 强化学习与超参数优化的交叉领域
## 引言
随着人工智能的快速发展,强化学习作为机器学习的一个重要分支,在处理决策过程中的复杂问题上显示出了巨大的潜力。与此同时,超参数优化在提高机器学习模型性能方面扮演着关键角色。将强化学习应用于超参数优化,不仅可实现自动化,还能够通过智能策略提升优化效率,对当前AI领域的发展产生了深远影响。
## 强化学习与超参数优化的关系
强化学习能够通过与环境的交互来学
【目标变量优化】:机器学习中因变量调整的高级技巧
# 1. 目标变量优化概述
在数据科学和机器学习领域,目标变量优化是提升模型预测性能的核心步骤之一。目标变量,又称作因变量,是预测模型中希望预测或解释的变量。通过优化目标变量,可以显著提高模型的精确度和泛化能力,进而对业务决策产生重大影响。
## 目标变量的重要性
目标变量的选择与优化直接关系到模型性能的好坏。正确的目标变量可以帮助模
极端事件预测:如何构建有效的预测区间
# 1. 极端事件预测概述
极端事件预测是风险管理、城市规划、保险业、金融市场等领域不可或缺的技术。这些事件通常具有突发性和破坏性,例如自然灾害、金融市场崩盘或恐怖袭击等。准确预测这类事件不仅可挽救生命、保护财产,而且对于制定应对策略和减少损失至关重要。因此,研究人员和专业人士持
贝叶斯优化:智能搜索技术让超参数调优不再是难题
# 1. 贝叶斯优化简介
贝叶斯优化是一种用于黑盒函数优化的高效方法,近年来在机器学习领域得到广泛应用。不同于传统的网格搜索或随机搜索,贝叶斯优化采用概率模型来预测最优超参数,然后选择最有可能改进模型性能的参数进行测试。这种方法特别适用于优化那些计算成本高、评估函数复杂或不透明的情况。在机器学习中,贝叶斯优化能够有效地辅助模型调优,加快算法收敛速度,提升最终性能。
接下来,我们将深入探讨贝叶斯优化的理论基础,包括它的工作原理以及如何在实际应用中进行操作。我们将首先介绍超参数调优的相关概念,并探讨传统方法的局限性。然后,我们将深入分析贝叶斯优化的数学原理,以及如何在实践中应用这些原理。通过对
机器学习性能评估:时间复杂度在模型训练与预测中的重要性
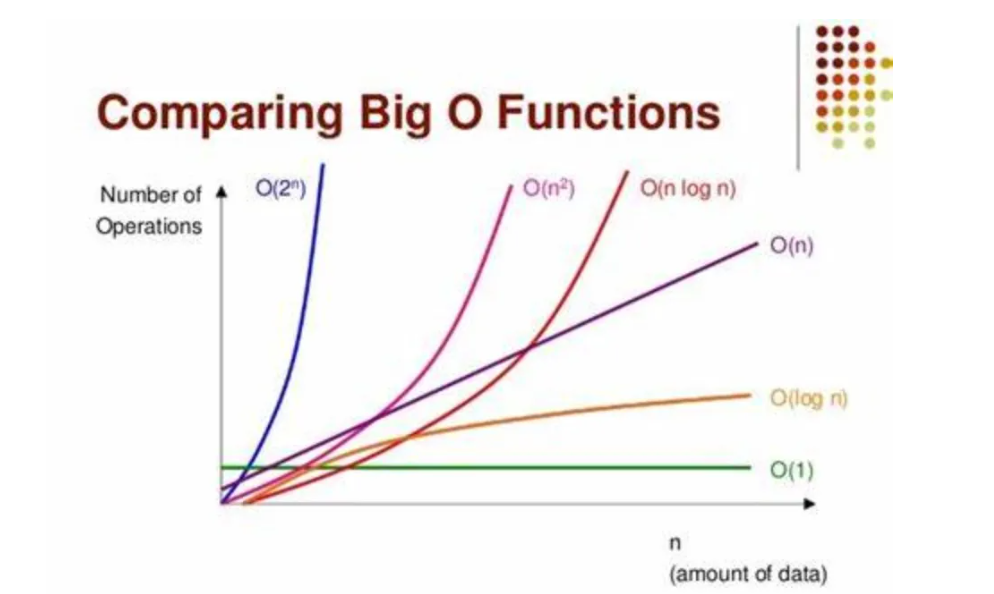
# 1. 机器学习性能评估概述
## 1.1 机器学习的性能评估重要性
机器学习的性能评估是验证模型效果的关键步骤。它不仅帮助我们了解模型在未知数据上的表现,而且对于模型的优化和改进也至关重要。准确的评估可以确保模型的泛化能力,避免过拟合或欠拟合的问题。
## 1.2 性能评估指标的选择
选择正确的性能评估指标对于不同类型的机器学习任务至关重要。例如,在分类任务中常用的指标有
【Python预测模型构建全记录】:最佳实践与技巧详解
# 1. Python预测模型基础
Python作为一门多功能的编程语言,在数据科学和机器学习领域表现得尤为出色。预测模型是机器学习的核心应用之一,它通过分析历史数据来预测未来的趋势或事件。本章将简要介绍预测模型的概念,并强调Python在这一领域中的作用。
## 1.1 预测模型概念
预测模型是一种统计模型,它利用历史数据来预测未来事件的可能性。这些模型在金融、市场营销、医疗保健和其
机器学习模型验证:自变量交叉验证的6个实用策略
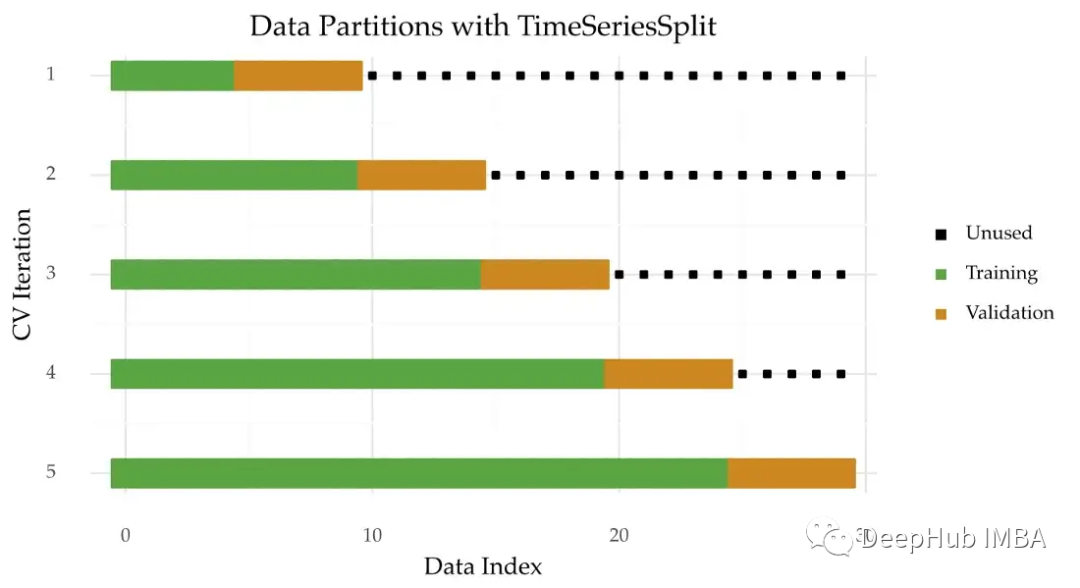
# 1. 交叉验证在机器学习中的重要性
在机器学习和统计建模中,交叉验证是一种强有力的模型评估方法,用以估计模型在独立数据集上的性能。它通过将原始数据划分为训练集和测试集来解决有限样本量带来的评估难题。交叉验证不仅可以减少模型因随机波动而导致的性能评估误差,还可以让模型对不同的数据子集进行多次训练和验证,进而提高评估的准确性和可靠性。
## 1.1 交叉验证的目的和优势
交叉验证
【游戏开发内存挑战】:空间复杂度如何影响游戏性能
# 1. 游戏内存管理概述
在当今数字娱乐行业中,游戏的内存管理已成为游戏性能优化的关键因素之一。内存管理不仅关乎到游戏运行的流畅度,还直接关联到用户体验的质量。随着游戏技术的快速发展,复杂的图形渲染、物理模拟、AI算法等大量消耗内存资源,使得内存管理成为一个不可忽视的议题。
## 内存管理的重要性
内存管理的重要性可以从以下两个方面进行阐释
时间序列分析的置信度应用:预测未来的秘密武器
# 1. 时间序列分析的理论基础
在数据科学和统计学中,时间序列分析是研究按照时间顺序排列的数据点集合的过程。通过对时间序列数据的分析,我们可以提取出有价值的信息,揭示数据随时间变化的规律,从而为预测未来趋势和做出决策提供依据。
## 时间序列的定义
时间序列(Time Series)是一个按照时间顺序排列的观测值序列。这些观测值通常是一个变量在连续时间点的测量结果,可以是每秒的温度记录,每日的股票价
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )