Time Series Causal Relationship Analysis: An Expert Guide to Identification and Modeling
发布时间: 2024-09-15 07:00:37 阅读量: 71 订阅数: 29 

Causal analysis: R.pdf
# 1. Overview of Machine Learning Methods in Time Series Causality Analysis
In the realm of data analysis, understanding the dynamic interactions between variables is key to time series causality analysis. It goes beyond mere correlation, focusing instead on uncovering the underlying causal connections. Thanks to their unique temporal dimension, time series data offer rich information for observing causal effects. In this chapter, we will introduce time series causality analysis, discussing its definition, importance, and potential value in real-world applications. Furthermore, this chapter aims to lay a solid foundation for understanding subsequent chapters.
## 1.1 Characteristics of Time Series Data
Time series data is a series of observations arranged in chronological order, typically used for analyzing and predicting trends and patterns that evolve over time. Its characteristics include temporal correlation, seasonality, and trend. It is precisely these features that, when combined with causal relationship exploration, reveal the dynamic causal chains between different events or variables.
## 1.2 Necessity of Causal Relationship Analysis
In disciplines such as economics, biology, and sociology, correctly understanding the causal relationships between variables is crucial for prediction and decision-making. However, finding true causal relationships in observational data is often more complex than it appears. This section will explore why traditional correlation analysis falls short and emphasize the importance of causal relationship analysis across various scientific fields.
## 1.3 Prospects for Applying Time Series Causality Analysis
Time series causality analysis not only helps to uncover causal pathways between variables but also has broad application prospects in fields such as financial risk management, economic policy-making, and disease control. This section will briefly introduce some specific application scenarios to inspire readers' interest in further studying causal relationship analysis.
# 2. Theoretical Foundations of Time Series Causality
## 2.1 Definition and Importance of Causality
### 2.1.1 Differences Between Causality and Correlation
Causality and correlation are two foundational concepts in statistics and data analysis. They differ markedly in definition and are often confused in practice. Correlation describes the strength and direction of the relationship between two variables, but it does not indicate whether one variable causes another. For instance, in weather forecasting, the relationship between air pressure and weather changes has a high correlation, but this does not mean that changes in air pressure directly cause changes in the weather.
In contrast, causality emphasizes that after one event (the cause) occurs, another event (the effect) follows. In other words, a causal relationship requires a temporal sequence and a logical necessity. If an event does not occur, the subsequent event will not occur either, and such a relationship can be considered causal. For example, if an area increases its afforestation efforts, and subsequently, the air quality and soil conservation in that area improve, then afforestation and environmental improvement can be considered a causal relationship.
### 2.1.2 History and Methodology of Causal Inference
The history of causal inference dates back to the early 20th century, when statistical methods began attempting to distinguish between correlation and causality. By the mid-20th century, statisticians had developed more complex mathematical models to explain this relationship. One of the most famous theories is the "Granger Causality" proposed by economist David Hendry, which identifies causal relationships between variables through time series data analysis.
Subsequently, Judea Pearl's causal diagram models (Causal Diagrams) and structural equation models (SEMs) provided a more solid theoretical foundation for causal inference. Pearl's models interpret causal relationships as structures where variables are connected by directed edges, indicating a direct or indirect influence of one variable on another.
In terms of methodology, econometric techniques such as instrumental variables (IV) and difference-in-differences (DID) are commonly used causal inference methods. In recent years, Bayesian networks, latent variable models, and machine learning methods like random forests and deep learning have been introduced into causal relationship analysis, providing new insights and tools.
## 2.2 Types of Causal Models
### 2.2.1 Linear and Nonlinear Causal Models
Among causal model classifications, linear causal models are the most basic and common form. They assume that the relationship between variables can be described by a linear equation. For example, a simple time series causal model can be expressed as:
\[ Y_t = \beta_0 + \beta_1 X_t + \varepsilon_t \]
where \( Y_t \) is the outcome variable, \( X_t \) is the cause variable, \( \beta_1 \) represents the magnitude of the causal effect, and \( \varepsilon_t \) is the error term.
However, not all causal relationships are linear. Nonlinear causal models allow the relationship between outcome and cause variables to vary with different values of the variables, making them more suitable for describing interactions in complex systems. Examples include polynomial regression models, neural network models, and certain types of nonlinear difference equations.
### 2.2.2 Static and Dynamic Causal Models
Static models generally describe the causal relationship between variables at a particular moment or in the short term, ignoring the impact of time factors on variable relationships. In contrast, dynamic causal models consider the dynamic changes of variables over time, typically involving lag effects, cumulative effects, and feedback mechanisms.
For example, in financial markets, a dynamic causal model might consider the historical performance of an investment strategy on current decision-making. Dynamic models often use time series analysis methods such as autoregressive models (e.g., ARIMA) or difference equations to build.
## 2.3 Methods for Identifying Causality
### 2.3.1 Granger Causality Test
The Granger causality test is a widely used statistical method for testing whether one time series can provide predictive information about another time series. If adding a time series improves the prediction of another time series, given other relevant variable information, then it is considered that the former Granger causes the latter.
The steps for conducting a Granger causality test are roughly as follows:
1. Check the stationarity of the series; if not stationary, difference.
2. Build a vector autoregressive model (VAR) ***
***pare the restricted VAR model (excluding certain variables) with the unrestricted VAR model (including all variables).
4. Use the F-test to determine if it is statistically significant to reject the null hypothesis.
An important limitation of the Granger causality test is that it cannot provide a true causal relationship, only indicating whether one variable can statistically predict another variable's changes.
### 2.3.2 Causal Diagrams and Structural Equation Models
Causal diagrams represent causal relationships between variables graphically, with nodes representing variables and directed edges representing causal relationships. Structural equation models combine regression analysis and factor analysis, describing direct and indirect effects between variables.
The typical steps for using causal diagrams and structural equation models for causal inference are as follows:
1. Define the causal diagram and determine the causal relationships between variables.
2. Extract the structural equation model from the diagram.
3. Estimate model parameters using observed data.
4. Perform goodness-of-fit tests and hypothesis testing on the model.
This method allows for a more intuitive understanding of causal paths in complex systems, especially when dealing with systems that

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【技术教程五要素】:高效学习路径构建的5大策略
# 摘要
技术学习的本质与价值在于其能够提升个人和组织的能力,以应对快速变化的技术环境。本文探讨了学习理论的构建与应用,包括认知心理学和教育心理学在技术学习中的运用,以及学习模式从传统教学到在线学习的演变。此外,本文还关注实践技能的培养与提升,强调技术项目管理的重要性以及技术工具与资源的利用。在高效学习方法的探索与实践中,本文提出多样化的学习方法、时间管理与持续学习策略。最后,文章展望了未来技术学习面临的挑战与趋势,包括技术快速发展的挑战和人工智能在技术教育中的应用前景。
【KEBA机器人维护秘籍】:专家教你如何延长设备使用寿命

# 摘要
本文系统地探讨了KEBA机器人的维护与优化策略,涵盖了从基础维护知识到系统配置最佳实践的全面内容。通过分析硬件诊断、软件维护、系统优化、操作人员培训以及实际案例研究,本文强调了对KEBA机器人进行系统维护的重要性,并为操作人员提供了一系列技能提升和故障排除的方法。文章还展望了未来维护技术的发展趋势,特别是预测性维护和智能化技术在提升机器人性能和可靠性方面的应用前景。
# 关键字
KEBA机器人;硬件诊断;
【信号完整性优化】:Cadence SigXplorer高级使用案例分析
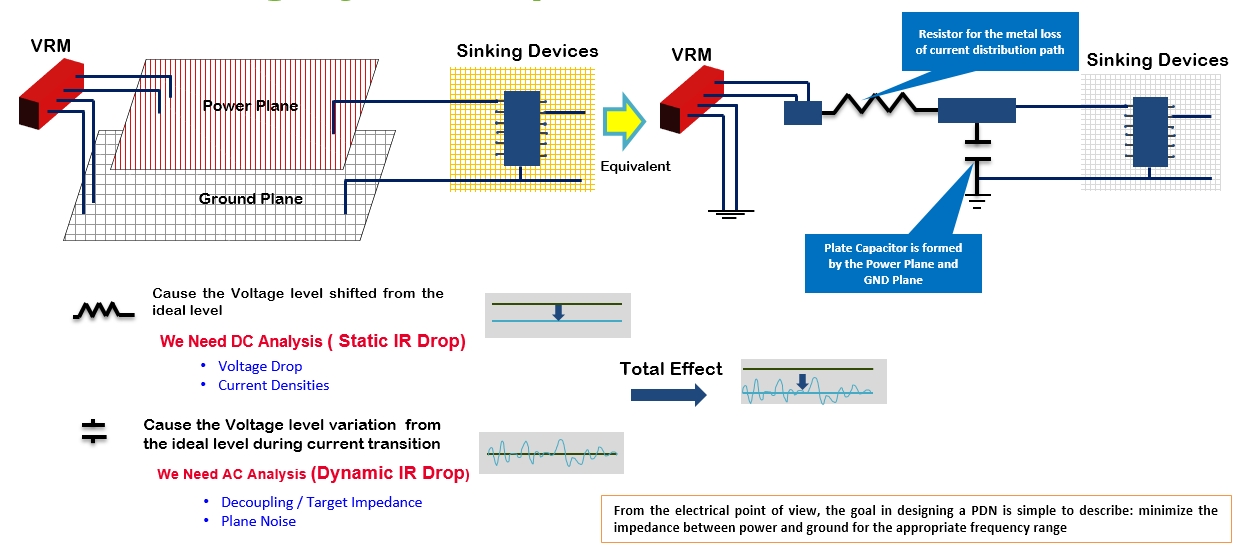
# 摘要
信号完整性是高速电子系统设计中的关键因素,影响着电路的性能与可靠性。本文首先介绍了信号完整性的基础概念,为理解后续内容奠定了基础。接着详细阐述了Cadence SigXplorer工具的界面和功能,以及如何使用它来分析和解决信号完整性问题。文中深入讨论了信号完整性问题的常见类型,如反射、串扰和时序问题,并提供了通过仿真模拟与实
【IRIG 106-19安全规定:数据传输的守护神】:保障您的数据安全无忧
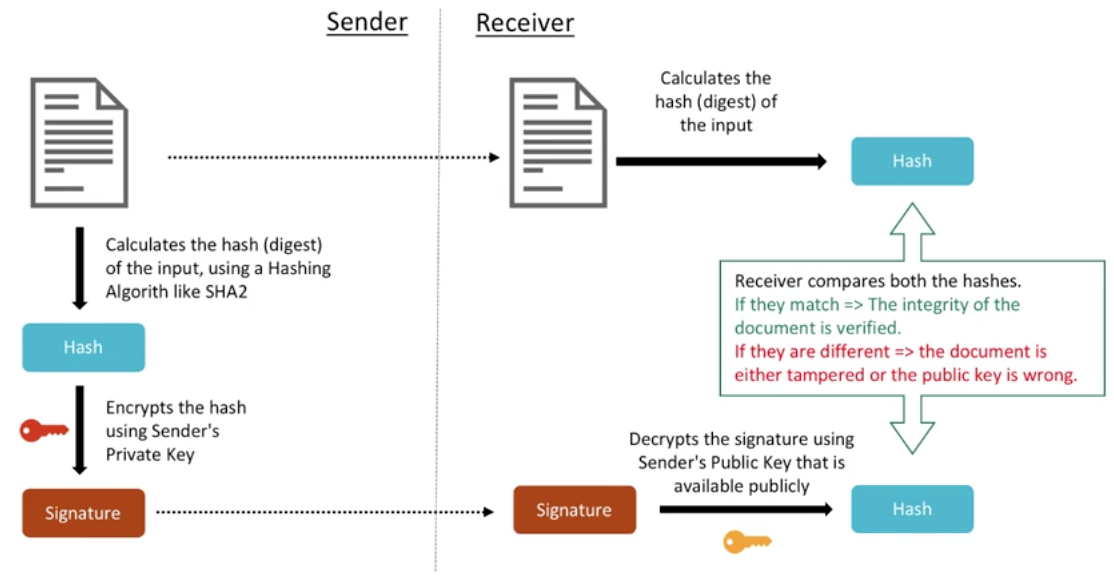
# 摘要
本文全面概述了IRIG 106-19安全规定,并对其技术基础和实践应用进行了深入分析。通过对数据传输原理、安全威胁与防护措施的探讨,本文揭示了IRIG 106-19所确立的技术框架和参数,并详细阐述了关键技术的实现和应用。在此基础上,本文进一步探讨了数据传输的安全防护措施,包括加密技术、访问控制和权限管理,并通过实践案例
【Python数据处理实战】:轻松搞定Python数据处理,成为数据分析师!

# 摘要
随着数据科学的蓬勃发展,Python语言因其强大的数据处理能力而备受推崇。本文旨在全面概述Python在数据处理中的应用,从基础语法和数据结构讲起,到必备工具的深入讲解,再到实践技巧的详细介绍。通过结合NumPy、Pandas和Matplotlib等库,本文详细介绍了如何高效导入、清洗、分析以及可视化数据,确保读者能掌握数据处理的核心概念和技能。最后,通过一个项目实战章
Easylast3D_3.0高级建模技巧大公开:专家级建模不为人知的秘密
# 摘要
Easylast3D_3.0是一款先进的三维建模软件,广泛应用于工程、游戏设计和教育领域。本文系统介绍了Easylast3D_3.0的基础概念、界面布局、基本操作技巧以及高级建模功能。详细阐述了如何通过自定义工作空间、视图布局、基本建模工具、材质与贴图应用、非破坏性建模技术、高级表面处理、渲染技术等来提升建模效率和质量。同时,文章还探讨了脚本与自动化在建模流
PHP脚本执行系统命令的艺术:安全与最佳实践全解析

# 摘要
PHP脚本执行系统命令的能力增加了其灵活性和功能性,但同时也引入了安全风险。本文介绍了PHP脚本执行系统命令的基本概念,分析了PHP中执行系统命令
PCB设计技术新视角:FET1.1在QFP48 MTT上的布局挑战解析
# 摘要
本文详细探讨了FET1.1技术在PCB设计中的应用,特别强调了QFP48 MTT封装布局的重要性。通过对QFP48 MTT的物理特性和电气参数进行深入分析,文章进一步阐述了信号完整性和热管理在布局设计中的关键作用。文中还介绍了FET1.1在QFP48 MTT上的布局实践,从准备、执行到验证和调试的全过程。最后,通过案例研究,本文展示了FET1.1布局技术在实际应用中可能遇到的问题及解决策略,并展望了未来布
【Sentaurus仿真速成课】:5个步骤带你成为半导体分析专家

# 摘要
本文全面介绍了Sentaurus仿真软件的基础知识、理论基础、实际应用和进阶技巧。首先,讲述了Sentaurus仿真的基本概念和理论,包括半导体物理基础、数值模拟原理及材料参数的处理。然后,本文详细阐述了Sentaurus仿真
台达触摸屏宏编程初学者必备:基础指令与实用案例分析

# 摘要
本文旨在全面介绍台达触摸屏宏编程的基础知识和实践技巧。首先,概述了宏编程的核心概念与理论基础,详细解释了宏编程指令体系及数据处理方法,并探讨了条件判断与循环控制。其次,通过实用案例实践,展现了如何在台达触摸屏上实现基础交互功能、设备通讯与数据交换以及系统与环境的集成。第三部分讲述了宏编程的进阶技巧,包括高级编程技术、性能优化与调试以及特定领域的应用。最后,分析了宏编程的未来趋势,包括智能化、自动化的新趋势,开源社区与生态的贡献,以及宏编程教育与培训的现状和未来发展。
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )