【In-Depth Analysis of the ARIMA Model】: Mastering Classical Methods for Time Series Forecasting
发布时间: 2024-09-15 06:34:01 阅读量: 77 订阅数: 29 

时间序列预测:Forecasting the Time Series of Apple Inc.'s Stock
# Machine Learning Methods in Time Series Forecasting
Time series analysis is a crucial method in statistics used to study the patterns and characteristics of data points over time. The ARIMA model, which stands for Autoregressive Integrated Moving Average Model, is a classical model in time series analysis used for predicting future data points. The ARIMA model predicts future data points by considering the lagged values of the time series itself and historical errors.
The ARIMA model consists of three main components: the Autoregressive (AR) part, the Integrated (I) part, and the Moving Average (MA) part. The AR part reflects the correlation between the current value of the time series and its past values; the Integrated part is used to transform a non-stationary time series into a stationary one, which is necessary to meet the requirements of the ARMA model; the MA part reflects the correlation between the current value of the time series and past prediction errors.
This chapter will introduce the basic concepts and components of the ARIMA model and outline its applications in data analysis. Subsequent chapters will delve into the theoretical foundations, practical applications, and software implementation of the model in more complex scenarios.
# 2. Theoretical Foundations of the ARIMA Model
### 2.1 Introduction to Time Series Analysis
#### 2.1.1 Characteristics of Time Series Data
Time series data is a set of data points arranged in chronological order, usually collected at a fixed frequency (such as per second, per hour, per month, per year, etc.). Characteristics of time series data include time dependency, seasonal changes, trends, cyclical patterns, and unpredictability. Due to the unique timestamps of time series data, they have broad application value in various fields such as economics, finance, and industrial production. For example, company sales, stock prices, and industrial electricity consumption are all typical examples of time series data.
When analyzing, special attention should be paid to the non-stationarity of the data, meaning that with the passage of time, its statistical characteristics, such as mean and variance, may change. Non-stationary time series analysis is the core application scenario for the ARIMA model.
#### 2.1.2 The Importance of Time Series Analysis
Time series analysis is crucial for prediction, decision-making support, and understanding patterns of data change. By analyzing time series data, one can uncover trends and cyclical patterns hidden within the data, providing valuable predictions for future events. This type of analysis is significant for businesses in formulating long-term strategic plans, governments in creating economic policies, and researchers in data analysis.
### 2.2 Basic Components of the ARIMA Model
#### 2.2.1 Autoregressive (AR) Part
The autoregressive part represents the linear relationship between the current value of the time series and its historical values. Specifically, the AR model of order p (AR(p)) can be represented as:
\[ Y_t = c + \phi_1Y_{t-1} + \phi_2Y_{t-2} + \dots + \phi_pY_{t-p} + \epsilon_t \]
where \(Y_t\) is the observation at time t, \(c\) is the constant term, \(\phi\) is the model parameter, and \(\epsilon_t\) is the white noise term.
The AR part mainly reflects the influence of past lagged values on the current value, and the introduction of these lagged values can help the model capture the memory characteristics of time series data.
#### 2.2.2 Integrated (I) Part
Differencing is the process of achieving stability by differencing the time series data n times. Differencing can eliminate the non-stationarity of the time series, especially the characteristics of trends and seasonality. For the ARIMA model, we usually adopt first-order or second-order differencing, namely:
\[ \Delta Y_t = Y_t - Y_{t-1} \]
or
\[ \Delta^2 Y_t = \Delta Y_t - \Delta Y_{t-1} = Y_t - 2Y_{t-1} + Y_{t-2} \]
Differencing operation essentially constructs a stationary time series, as differencing operations help remove trends and seasonality from the data, providing a basis for establishing an ARMA model.
#### 2.2.3 Moving Average (MA) Part
The moving average part considers the lagged prediction errors of the time series. The MA(q) model can be represented as:
\[ Y_t = \mu + \epsilon_t + \theta_1\epsilon_{t-1} + \theta_2\epsilon_{t-2} + \dots + \theta_q\epsilon_{t-q} \]
where \(\mu\) is the constant term, \(\theta\) is the model parameter, and \(\epsilon\) is the white noise term.
The moving average part helps to describe the autocorrelation of the time series, predicting the current value through a linear combination of historical prediction errors.
### 2.3 Model Parameter Selection and Identification
#### 2.3.1 Stationarity Test
Before modeling, ***mon stationarity tests include the Augmented Dickey-Fuller Test (ADF test). The ADF test determines whether the data is stationary by judging whether the unit root of the time series data exists. If the ADF statistic is less than a certain critical value, or the p-value is less than the significance level (e.g., 0.05), then the data can be considered stationary.
#### 2.3.2 Standard Process of Model Identification
Model identification typically relies on Autocorrelation Function (ACF) and Partial Autocorrelation Function (PACF) plots. The ACF plot shows the correlation between the time series and its lagged values; the PACF plot shows the partial correlation between the time series and its lagged values, given certain intermediate lagged values.
By observing the ACF and PACF plots, one can roughly judge the order of the AR and MA parts. For example, if the PACF cuts off while the ACF trails off, it may be an AR model; if the ACF cuts off while the PACF trails off, it may be an MA model.
#### 2.3.3 Parameter Estimation and Model Testing
Parameter estimation is performed using methods such as maximum likelihood estimation or least squares estimation to determine the parameter values in the ARIMA model. After parameter estimation, model testing is necessary, such as white noise tests and residual autocorrelation tests, to ensure that the model has not missed important information, and the residual series is a white noise series.
Model testing usually involves residual analysis, meaning that residuals should exhibit a white noise process without identifiable patterns and correlations. If the residual series has autocorrelation, it indicates that the model may not have fully captured the information in the data.
During parameter estimation and model testing, statistical software such as the `forecast` package in R or the `statsmodels` library in Python can be used to perform these operations and analyses. In subsequent chapters, we will demonstrate how to implement these analytical steps using specific datasets.
# 3. Practical Application of the ARIMA Model
## 3.1 Data Preparation and Preprocessing
### 3.1.1 Data Cleaning and Transformation
In the practical application of data science, data cleaning and transformation are key first steps because the accuracy of subsequent analysis directly depends on the quality of the input data. Before building an ARIMA model, it must be ensured that the input time series data is clean and uniformly formatted. Data cleaning typically includes dealing with missing values, outliers, duplicate records, and unifying data formats.
First, missing values in the data need to be appropriately handled, usually with the following methods:
- Delete records containing missing values.
- Fill in missing values with the mean, median, or mode.
- Use interpolation methods to fill in, such as time series interpolation.
```python
import pandas as pd
# Sample code: data cleaning, handling missing values
data = pd.read_csv('timeseries_data.csv') # Read time series data
# Delete records with missing values
data_cleaned = data.dropna()
# Or fill in missing values with the mean
data_filled = data.fillna(data.mean())
```
### 3.1.2 Ensuring Data Stationarity
Stationarity is a basic prerequisite in time series analysis, and only when the time series is stationary can we use the ARIMA model. Stationarity refers to the statistical characteristics of the time series, such as the mean and variance, not changing over time. Non-stationary time series often contain trends or seasonal components, which can affect the model's predictive performance.
To ensure data stationarity, we need to perform the following operations:
- Visualize the time series to check for trends and seasonality.
- Calculate the Autocorrelation Coefficient (ACF) and Partial Autocorrelation Coefficient (PACF) of the time series.
- Use differencing operations to remove trends and seasonal components from the time series.
```python
from statsmodels.tsa.stattools import adfuller
# Check the stationarity of the time series
def test_stationarity(timeseries):
# Use ADF test
result = adfuller(timeseries, autolag='AIC')
print('ADF Statistic: %f' % result[0])
print('p-value: %f' % result[1])
print('Critical Values:')
for key, value in result[4].items():
print('\t%s: %.3f' % (key, value))
# Assume data_cleaned is a cleaned time series data column
test_stationarity(data_cleaned)
```
## 3.2 Building and Training the ARIMA Model
### 3.2.1 Building the Model Using Statistical Software
In practical work, data analysts typically use statistical software such as R, Python's `statsmodels` or `pandas` packages to build ARIMA models. In R language, the `forecast` package provides a convenient ARIMA model building function, while in Python, the `ARIMA` class in the `statsmodels` library can be used directly to fit the model.
Building an ARIMA model requires specifying three parameters: p (the order of the autoregressive term), d (the number of differences), and q (the order of the moving average term). The choice of these parameters needs to be based on the results of previous stationarity tests and the analysis of ACF and PACF plots.
```r
# Building an ARIMA model in R using the forecast package
library(forecast)
# Assume time_series is a preprocessed time series vector
arima_model <- auto.arima(time_series)
# View model summary
summary(arima_model)
```
### 3.2.2 Model Fitting and Validation
After fitting the ARIMA model, its performance needs to be validated. This typically involves dividing the dataset into a training set and a test set, fitting the model on the training set, and validating the model'***mon validation metrics include Mean Squared Error (MSE), Root Mean Squared Error (RMSE), and Mean Absolute Error (MAE).
```python
from sklearn.metrics import mean_squared_error, mean_absolute_error
# Divide the data into training and test sets
train_size = int(len(data_cleaned) * 0.8)
train, test = data_cleaned[0:train_size], data_cleaned[train_size:]
# Build an ARIMA model
model = ARIMA(train, order=(1,1,1))
model_fit = model.fit()
# Make predictions
predictions = model_fit.predict(start=len(train), end=len(train)+len(test)-1, dynamic=False)
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
S32K SPI开发者必读:7大优化技巧与故障排除全攻略
# 摘要
本文深入探讨了S32K微控制器的串行外设接口(SPI)技术,涵盖了从基础知识到高级应用的各个方面。首先介绍了SPI的基础架构和通信机制,包括其工作原理、硬件配置以及软件编程要点。接着,文章详细讨论了SPI的优化技巧,涵盖了代码层面和硬件性能提升的策略,并给出了故障排除及稳定性的提升方法。实战章节着重于故障排除,包括调试工具的使用和性能瓶颈的解决。应用实例和扩展部分分析了SPI在
图解数值计算:快速掌握速度提量图的5个核心构成要素
# 摘要
本文全面探讨了速度提量图的理论基础、核心构成要素以及在多个领域的应用实例。通过分析数值计算中的误差来源和减小方法,以及不同数值计算方法的特点,本文揭示了实现高精度和稳定性数值计算的关键。同时,文章深入讨论了时间复杂度和空间复杂度的优化技巧,并展示了数据可视化技术在速度提量图中的作用。文中还举例说明了速度提量图在
动态规划:购物问题的终极解决方案及代码实战

# 摘要
动态规划是解决优化问题的一种强大技术,尤其在购物问题中应用广泛。本文首先介绍动态规划的基本原理和概念,随后深入分析购物问题的动态规划理论,
【随机过程精讲】:工程师版习题解析与实践指南
# 摘要
随机过程是概率论的一个重要分支,被广泛应用于各种工程和科学领域中。本文全面介绍了随机过程的基本概念、分类、概率分析、关键理论、模拟实现以及实践应用指南。从随机变量的基本统计特性讲起,深入探讨了各类随机过程的分类和特性,包括马尔可夫过程和泊松过程。文章重点分析了随机过程的概率极限定理、谱分析和最优估计方法,详细解释了如何通过计算机模拟和仿真软件来实现随机过程的模拟。最后,本文通过工程问题中随机过程的实际应用案例,以
【QSPr高级应用案例】:揭示工具在高通校准中的关键效果
# 摘要
本论文旨在介绍QSPr工具及其在高通校准中的基础和应用。首先,文章概述了QSPr工具的基本功能和理论框架,探讨了高通校准的重要性及其相关标准和流程。随后,文章深入分析了QSPr工具的核心算法原理和数据处理能力,并提供了实践操作的详细步骤,包括数据准备、环境搭建、校准执行以及结果分析和优化。此外,通过具体案例分析展示了QSPr工具在不同设备校准中的定制
Tosmana配置精讲:一步步优化你的网络映射设置

# 摘要
Tosmana作为一种先进的网络映射工具,为网络管理员提供了一套完整的解决方案,以可视化的方式理解网络的结构和流量模式。本文从基础入门开始,详细阐述了网络映射的理论基础,包括网络映射的定义、作用以及Tosmana的工作原理。通过对关键网络映射技术的分析,如设备发现、流量监控,本文旨在指导读者完成Tosmana网络映射的实战演练,并深入探讨其高级应用,包括自动化、安全威胁检测和插件应用。最
【Proteus与ESP32】:新手到专家的库添加全面攻略

# 摘要
本文详细介绍Proteus仿真软件和ESP32微控制器的基础知识、配置、使用和高级实践。首先,对Proteus及ESP32进行了基础介绍,随后重点介绍了在Proteus环境下搭建仿真环境的步骤,包括软件安装、ESP32库文件的获取、安装与管理。第三章讨论了ESP32在Proteus中的配置和使用,包括模块添加、仿真
【自动控制系统设计】:经典措施与现代方法的融合之道
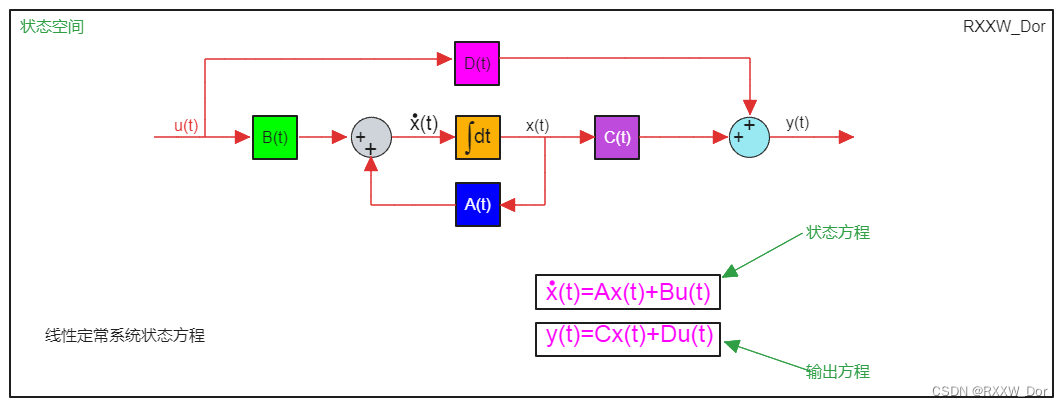
# 摘要
自动控制系统是工业、航空、机器人等多个领域的核心支撑技术。本文首先概述了自动控制系统的基本概念、分类及其应用,并详细探讨了经典控制理论基础,包括开环和闭环控制系统的原理及稳定性分析方法。接着,介绍了现代控制系统的实现技术,如数字控制系统的原理、控制算法的现代实现以及高级控制策略。进一步,本文通过设计实践,阐述了控制系统设计流程、仿真测试以及实际应用案例。此外,分析了自动控制系统设计的当前挑战和未
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )