【Machine Learning Time Series Forecasting: From Beginner to Expert】: Mastering Core Applications
发布时间: 2024-09-15 06:24:45 阅读量: 42 订阅数: 42 
# [Machine Learning Time Series Forecasting: From Beginner to Expert, Mastering Core Applications](https://***/167ae4fd6205b00d002cd00dbedee4fb0421d60c/e4f89/images/time-series-vectors-1.png)
## 1. Foundations of Time Series Forecasting
Time series forecasting is a core task in the field of data analysis. It involves predicting future trends by analyzing the temporal dependencies in historical data. The process includes data collection, processing, modeling, and analysis and is often applied to financial market analysis, weather forecasting, sales forecasting, inventory management, and more.
In the foundational chapter, we will focus on the characteristics of time series data, including its structure, trends, and seasonality. We will then explore key components of time series analysis: data stationarity and autocorrelation, which are crucial for building effective forecasting models.
Additionally, this chapter introduces basic statistical methods such as moving averages and exponential smoothing, which provide an intuitive foundation for time series forecasting and lay a solid groundwork for learning more complex models. By the end of this chapter, readers should have a basic framework for time series forecasting and a solid foundation for further learning and application.
## 2. Applications of Machine Learning Theory in Time Series
Time series forecasting is an interdisciplinary field that combines theories and techniques from statistics, economics, machine learning, and more. This chapter will delve into the application of machine learning theory in time series forecasting, including an overview of machine learning models, common algorithms for time series forecasting, feature engineering, and data preprocessing. Through the study of this content, readers will better understand and master how to apply machine learning techniques to practical problems in time series forecasting.
### 2.1 Overview of Machine Learning Models
#### 2.1.1 Supervised and Unsupervised Learning Models
In the realm of time series forecasting, machine learning models can be divided into supervised and unsupervised learning. Supervised learning models are typically used for datasets with input and expected output labels. For instance, by analyzing historical time series data to predict future numerical points, ***
***mon supervised learning algorithms in time series forecasting include linear regression, support vector machines, decision trees, random forests, and neural networks. The goal of these algorithms is to learn a model that can map input time series to output labels through the training dataset.
In contrast, unsupervised learning does not rely on labeled training data. Its aim is to discover patterns and structures in the data. In time series forecasting, unsupervised learning can be used for data preprocessing (such as anomaly detection) and feature extraction (such as obtaining new representations through clustering). Common unsupervised learning methods include K-means clustering, Principal Component Analysis (PCA), and autoencoders.
#### 2.1.2 Evaluation Metrics for Models
In time series forecasting problems, evaluating model performance is crucial. Evaluation metrics for time series forecasting should reflect the differences between predicted and actual values and adapt to specific characteristics of time series data, such as serial correlation, seasonality, ***
***mon evaluation metrics include Mean Squared Error (MSE), Root Mean Squared Error (RMSE), Mean Absolute Error (MAE), and Mean Absolute Percentage Error (MAPE). These metrics quantify the differences between predicted and actual values from different perspectives, helping us measure the predictive performance of models.
MSE and RMSE give higher weight to larger prediction errors, making them particularly suitable for evaluating the overall closeness of predicted values to actual values. MAE and MAPE, on the other hand, focus more on the average size of errors and are not affected by outliers, making them more robust when dealing with time series data with extreme values.
In practice, the choice of evaluation metrics often depends on specific problems and business needs. The choice of evaluation metrics and the optimization of model performance are closely linked, and appropriate evaluation metrics help us more accurately ***
***
***
***
***
*** `statsmodels` library. Below is a simple example of constructing and forecasting an ARIMA model:
```python
import statsmodels.api as sm
import pandas as pd
from matplotlib import pyplot as plt
# Assume we have a time series dataset
data = pd.read_csv('timeseries_data.csv', index_col='date', parse_dates=True)
series = data['value']
# Define model parameters
p, d, q = 1, 1, 1
# Create and fit the ARIMA model
model = sm.tsa.ARIMA(series, order=(p, d, q))
results = model.fit()
# Forecast future values
forecast = results.forecast(steps=5)
print(forecast)
# Plot the original data and forecasts
plt.plot(series)
plt.plot(forecast)
plt.title('ARIMA Forecast')
plt.show()
```
In this example, we first import the necessary libraries, then read the time series data. We define the ARIMA model order as (p=1, d=1, q=1) and construct and fit the model using the `ARIMA` class from the `statsmodels` library. Finally, we use the `forecast` method to predict the next 5 time points and plot the forecast results alongside the original data using the matplotlib library.
### 2.2.2 Random Forests and Gradient Boosting Trees
Random Forests and Gradient Boosting Trees are typical representatives of ensemble learning methods. They improve the accuracy and stability of models by constructing multiple decision trees. Random Forest introduces randomness during each tree's training process to avoid overfitting, while Gradient Boosting Trees iteratively add trees to improve predictive performance.
A significant advantage of Random Forest in time series forecasting is its ability to effectively handle high-dimensional data and nonlinear relationships. It captures complex relationships between features by randomly selecting a subset of features at each tree split. On the other hand, Gradient Boosting Trees excel in continuous target prediction and complex nonlinear regression problems because they gradually build the model, with each iteration attempting to correct the prediction errors from the previous iteration.
### 2.2.3 Applications of Deep Learning in Time Series
In recent years, the application of deep learning in the field of time series forecasting has gradually increased, especially for datasets with complex nonlinear relationships. Deep learning models can automatically extract high-order features and learn data representations in multi-layer network structures, giving them an advantage in capturing long-term dependencies within time series data.
Recurrent Neural Networks (RNNs) and their variants, such as Long Short-Term Memory (LSTM) networks and Gated Recurrent Units (GRUs), are commonly used deep learning models for time series forecasting. These models are specifically designed to handle sequential data and can effectively deal with long-distance dependencies within time series data.
LSTM is a special type of RNN that introduces gating mechanisms (including forget, input, and output gates) to address the vanishing and exploding gradient problems of traditional RNNs, making it perform better on long-term dependency issues. GRU is a variant of LSTM that simplifies its structure while retaining most of its advantages.
Below is a simple example of using LSTM for time series forecasting, where we use Keras to build an LSTM model:
```python
from keras.models import Sequential
from keras.layers import LSTM, Dense
# Assume X_train and Y_train are the prepared training data and labels
X_train = ... # Training input data
Y_train = ... # Training output data
# Create an LSTM model
model = Sequential()
model.add(LSTM(50, activation='relu', input_shape=(X_train.shape[1], X_train.shape[2])))
model.add(Dense(1))
***pile(optimizer='adam', loss='mse')
# Train the model
model.fit(X_train, Y_train, epochs=20, batch_size=72)
# Use the trained model to make predictions
# Assume X_test is the test data
X_test = ... # Test input data
y_pred = model.predict(X_test)
print(y_pred)
```
In this code example, we first import the necessary libraries and prepare the training data `X_train` and `Y_train`. Then we create a sequential model containing a single LSTM layer and an output layer. In the LSTM layer, we set 50 neurons and use ReLU as the activation function. Since we assume the data has been normalized, the `input_shape` should match the dimensions of the data.
When compiling the model, we select the 'adam' optimizer and the Mean Squared Error (MSE) loss function. We then train the model for 20 epochs with a batch size of 72. Finally, we use the test data `X_test` to make predictions with the trained model and print the results.
## 2.3 Feature Engineering and Data Preprocessing
### 2.3.1 Feature Selection Techniques
Feature selection involves selecting the most useful subset of features from the original feature set to improve the predictive performance of the model. A good feature subset should reduce the complexity of the model, prevent overfitting, and improve the generalization ability of the model.
In time series forecasting problems, common feature selection methods include univariate feature selection methods, model-based feature selection methods, and correlation-based feature selection methods. Univariate feature selection methods typically select features based on statistical tests (such as chi-squared tests). Model-based methods use machine learning models to evaluate the importance of features. Correlation-based methods select features that have a higher correlation with the target variable.
### 2.3.2 Data Normalization and Standardization
Data normalization (or standardization) refers to adjusting the range of feature values to a standard interval, such as [0,1] or [-1,1]. This is very important for machine learning models because many algorithms are sensitive to the scale of input data. Standardized data helps accel***
***mon data normalization methods include Min-Max scaling, Z-score normalization, etc. For example, the `MinMaxScaler` and `StandardScaler` classes in the `sklearn` library can conveniently be used to normalize data.
### 2.3.3 Strategies for Handling Missing Data
When dealing with time series data, we often encounter missing data. Missing data can be caused by various reasons, such as equipment failure, data collection issues, data transmission errors, etc. Correctly handling missing data is crucial for building an effective predictive model.
Basic strategies for dealing with missing values include deleting samples with missing values, using data interpolation to fill in missing values, or employing model predictions to fill in missing values. In time series data, because the data has a sequential nature, using time series interpolation methods (such as linear interpolation, time-weighted interpolation, etc.) to fill in missing values is very common.
In practice, we should choose an appropriate strategy for handling missing data based on specific problems, the type and amount of missing data, etc. If the proportion of missing data is not large and does not affect the overall distribution of data, we can choose to delete samples with missing values. If there is a lot of missing data, or if each time point's data is very important, then data interpolation or predicting missing values may be a better choice.
# 3. Practical Tips for Time Series Forecasting
## 3.1 Data Preparation Before Practice
### 3.1.1 Data Collection and Cleaning
In the practice of time series analysis, the quality of data often determines the accuracy and reliability of the analysis results. Data collection and cleaning are the first steps in time series forecasting, involving ***mon steps in this process include data merging, handling missing values, identifying, and correcting outliers.
First, data merging usually needs to ensure the consistency of timestamps to ensure the continuity of time series. When merging multiple datasets, it is crucial to ensure accurate correspondence between time points. Next, for handling missing values, common strategies include interpolation methods (such as linear interpolation, polynomial interpolation) and model prediction methods (such as using ARIMA models to fill in time series).
When identifying and processing outliers, common statistical methods include Z-Score analysis, boxplot analysis, density-based methods, etc. In terms of processing methods, deletion, replacement, or retention strategies can be chosen based on the nature of the outliers and the purpose of the analysis.
### 3.1.2 Methods for Splitting Datasets
Once the dataset is ready, the next step is to split the dataset into training and testing sets for model training and validation. For time series data, different from the general random splitting method, time-order***mon splitting methods include:
- **Rolling Split**: Based on a certain window size, the window is gradually moved forward, moving one time point or a certain time step forward each time, generating training and testing sets.
- **Time Series Cross-Validation**: When performing cross-validation on time series data, it is necessary to ensure that the sorting order of the data is not disrupted.
In Python's `sklearn` library, the `TimeSeriesSplit` class can be used to implement time series cross-validation.
```python
from sklearn.model_selection import TimeSeriesSplit
# Create a cross-validation splitting object, n_splits represents the number of splits
tscv = TimeSeriesSplit(n_splits=5)
for train_index, test_index in tscv.split(X):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
# Here, model training and prediction are performed
```
## 3.2 Model Training and Validation
### 3.2.1 Application of Cross-Validation in Time Series
As a model selection and evaluation technique, cross-validation is widely used in time series analysis. Unlike traditional cross-validation, time series cross-validation must consider the temporal order and cannot randomly shuffle the data. When using it, the following factors should be considered:
- **Splitting Strategy**: Choose an appropriate time series cross-validation strategy, such as forward chaining, where each split keeps earlier data points in the training set.
- **Number of Groups**: Increasing the number of groups can provide more training/testing opportunities, but it also increases computational costs.
- **Data Characteristics**: If the time series data has seasonal characteristics, it is necessary to ensure that each training set in cross-validation contains a complete seasonal cycle.
### 3.2.2 Hyperparameter Tuning and Model Selection
Model hyperparameter tuning is the process of adjusting model configurations to improve predictive performance. In time series forecasting, common hyperparameter tuning methods include Grid Search, Random Search, and Bayesian Optimization.
- **Grid Search** finds the best parameters by exhaustively enumerating all possible parameter combinations.
- **Random Search** randomly selects parameter combinations from a specified parameter distribution, which is more efficient than grid search in large parameter spaces.
- **Bayesian Optimization** uses probabilistic models to select parameter combinations, able to find better parameter combinations within a limited number of iterations.
Code example: Using `GridSearchCV` for hyperparameter optimization of an ARIMA model.
```python
from sklearn.model_selection import GridSearchCV
from statsmodels.tsa.arima.model import ARIMA
# Define the parameter range
param_grid = {
'order': [(1, 1, 1), (2, 1, 2)],
'seasonal_order': [(1, 1, 1, 12)]
}
# Create an ARIMA model instance
model = ARIMA(endog=y, exog=X, order=param_grid['order'][0], seasonal_order=param_grid['seasonal_order'][0])
# Apply grid search
grid_search = GridSearchCV(estimator=model, param_grid=param_grid, scoring='neg_mean_squared_error', cv=3, n_jobs=-1)
grid_search.fit(y, exogenous=X)
# Output the best parameters
best_params = grid_search.best_params_
```
## 3.3 Interpretation and Application of Forecasting Results
### 3.3.1 Interpretation of Results and Report Writing
Interpreting model forecasting results and report writing are key steps in transforming technical results into business decision support. This process not only requires analysts to accurately interpret model forecasting results but also to closely link these results with business goals and actual scenarios.
- **Result Interpretation**: Translate the model's numerical forecasting results into indicators with practical business significance, such as growth rates, trend changes, etc.
- **Report Writing**: When writing reports, focus on the logic, organization, and readability of the report, usually including an abstract, methodology, results, discussion, and recommendations.
### 3.3.2 Limitations of Model Predictions and Countermeasures
No predictive model can perfectly predict future events, ***mon limitations and countermeasures include:
- **Data Limitations**: Incomplete, missing, or poor-quality data collection processes can affect the accuracy of the model. Countermeasures include continuous data quality monitoring and improvements in data collection methods.
- **Model Limitations**: The selected model may not be applicable to all forecasting scenarios. Countermeasures include comparing multiple models or introducing new forecasting technologies.
- **Environmental Changes**: Changes in the external environment may affect the validity of forecasting results. Countermeasures include regularly retraining the model, introducing new predictive variables, and features.
The application of tables and code blocks makes technical details more concrete and easier to understand. In practical work, practitioners can effectively prepare data, train and validate models, and reasonably interpret and apply forecasting results based on the content of this chapter.
# 4. Advanced Topics in Time Series Forecasting
Time series forecasting is an evolving and deepening field. With the evolution of models and analytical methods, many advanced topics have emerged. These topics delve into the complexity of time series data and provide more precise and in-depth analytical methods. This chapter will delve into three advanced topics: multivariate time series analysis, decomposition and seasonal adjustment of time series, and anomaly detection in time series forecasting.
## 4.1 Multivariate Time Series Analysis
In many real-world scenarios, the time series we focus on are often related to multiple other time series. For example, there is a certain correlation between stock market indices and individual stock prices, as well as between climate conditions and energy consumption. The purpose of multivariate time series analysis is to explore the relationships between multiple time series to make more accurate predictions.
### 4.1.1 Vector Autoregression Model (VAR)
The VAR model is a common method for multivariate time series analysis. It not only captures the endogeneity of time series but can also analyze the mutual influences between multiple time series. The VAR model assumes that every variable in the system is a linear function of the lagged values of other variables in the system.
In the VAR model, each variable is represented as a linear combination of its own lagged values and the lagged values of other variables. For example, if there are two time series variables Y and X, a VAR(1) model can be represented as:
\[
\begin{align*}
Y_t &= c + \phi_{11}Y_{t-1} + \phi_{12}X_{t-1} + \epsilon_{1t} \\
X_t &= d + \phi_{21}Y_{t-1} + \phi_{22}X_{t-1} + \epsilon_{2t} \\
\end{align*}
\]
where c and d are constants, \(\phi_{ij}\) are coefficients, and \(\epsilon_{1t}\) and \(\epsilon_{2t}\) are error terms.
A key step in the VAR model is to determine the optimal lag order of the model, usually selected using information criteria (such as AIC or BIC).
### 4.1.2 Cointegration and Error Correction Models
When the linear combination of two or more non-stationary time series is stationary, these time series are considered to have a cointegration relationship. This relationship implies that although individual time series are non-stationary, there is some long-term stable relationship between them.
One application of cointegration is the error correction model (ECM), which describes how time series adjust through a long-term relationship when short-term fluctuations occur. The ECM model can capture the dynamic adjustment process when data deviates from long-term equilibrium, helping to understand the long-term equilibrium relationship between variables.
### Code Example: Constructing a VAR Model Using Python
To demonstrate how to construct a VAR model using the statsmodels library in Python, the following code block provides the basic steps and logical analysis.
```python
import numpy as np
import pandas as pd
from statsmodels.tsa.api import VAR
import statsmodels.api as sm
# Assume df is a DataFrame containing time series data with columns Y and X
df = pd.read_csv('multivariate_timeseries.csv')
# Convert the data into a format suitable for the VAR model
endog = df[['Y', 'X']]
# Select the optimal lag order
model = VAR(endog)
results = model.select_order(10)
# Construct a VAR model using the optimal lag order
var_model = VAR(endog)
var_results = var_model.fit(maxlags=***c)
# Output a summary of the model results
print(var_results.summary())
```
In the above code, the `select_order` function is used to automatically select the optimal lag order, while the `fit` function fits the VAR model based on the selected lag order. Finally, the `summary()` function outputs a detailed statistical summary of the model.
## 4.2 Decomposition and Seasonal Adjustment of Time Series
Time series data is often influenced by seasonal factors, such as climate, holidays, and cultural events. To analyze and predict the trend and cyclical components of data more clearly, we need to decompose and seasonally adjust the time series.
### 4.2.1 Methods of Time Series Decomposition
The methods of time series decomposition mainly include two types: additive models and multiplicative models. The additive model is suitable when the amplitude of seasonal variation is unrelated to the overall level, while the multiplicative model is suitable when the amplitude of seasonal variation is proportional to the overall level.
The additive model is represented as:
\[ Y_t = T_t + S_t + C_t + e_t \]
where \(T_t\) is the trend component, \(S_t\) is the seasonal component, \(C_t\) is the cyclical component, and \(e_t\) is the random error.
The multiplicative model is represented as:
\[ Y_t = T_t \times S_t \times C_t \times e_t \]
### 4.2.2 Seasonal Adjustment Techniques
Seasonal adjustment is ***mon seasonal adjustment methods include the moving average method and the X-11/X-12-ARIMA method.
The moving average method estimates the seasonal component by using a sliding average. For each seasonal cycle, calculate an average value and subtract this average from the original data to obtain seasonally adjusted data.
### Code Example: Time Series Decomposition in Python
Next, we will demonstrate how to decompose time series using the statsmodels library in Python, with the additive model as an example.
```python
from statsmodels.tsa.seasonal import seasonal_decompose
# Load time series data
ts = pd.read_csv('timeseries.csv', index_col='date', parse_dates=True)
# Decompose the time series
decomposition = seasonal_decompose(ts['value'], model='additive')
# Display the decomposition results
decomposition.plot()
```
Using the `seasonal_decompose` function, we can decompose the time series and visualize the individual components using the `plot()` function.
## 4.3 Anomaly Detection in Time Series Forecasting
Anomalies are values that are significantly different from other observations in the dataset. In time series analysis, anomalies may indicate potential errors, data collection issues, or unusual events in the data. Correctly identifying and handling anomalies is an important step in improving prediction accuracy.
### 4.3.1 Concept of Anomalies and Detection Methods
There are various methods for detecting anomalies, ***mon statistical methods include Z-scores, while common machine learning methods include Isolation Forest and One-Class Support Vector Machine (One-Class SVM).
### 4.3.2 Impact of Anomalies on Predictions and Countermeasures
The existence of anomalies can severely distort the analysis results of time series. Therefore, it is necessary to detect and handle anomalies in time series data before making predictions. Handling methods include deleting, replacing, or using special methods such as robust regression to reduce the impact of anomalies on prediction results.
### Code Example: Detecting Anomalies Using Python
Next is a Python code example using Isolation Forest to detect anomalies.
```python
from sklearn.ensemble import IsolationForest
# Assume df is a DataFrame containing time series data with a column named 'value'
df = pd.read_csv('timeseries.csv')
# Prepare data
data = df['value'].values.reshape(-1, 1)
# Initialize the Isolation Forest model
clf = IsolationForest(n_estimators=100, max_samples='auto', contamination=float(.01), max_features=1.0)
# Fit the model and predict anomalies
clf.fit(data)
preds = clf.predict(data)
# Filter out anomalies
df['anomaly'] = preds
anomalies = df[df['anomaly'] == -1]
print(anomalies)
```
In this code, the `IsolationForest` model is fitted to the data and generates predictions for anomalies. Anomalies are marked as -1 and can be filtered out from the dataset. This allows analysts to further inspect these anomalies and decide how to handle them.
### 4.3.3 Data Table: Anomaly Case Analysis
To further analyze the impact of anomalies, we can create a table to show a comparison of prediction results before and after anomaly detection.
| Date | Original Value | Forecasted Value | Anomaly Tag | Processed Forecasted Value |
|------------|----------------|------------------|-------------|----------------------------|
| 2022-01-01 | 120 | 123 | No | 123 |
| 2022-01-02 | 98 | 105 | Yes | -- |
| 2022-01-03 | 104 | 106 | No | 106 |
| ... | ... | ... | ... | ... |
In the table above, anomalies are marked as "Yes," and after processing, we can see that for dates containing anomalies, the forecasted values are excluded or specially handled.
Through the exploration of these advanced topics, we can see the expanding boundaries of the time series forecasting field. Multivariate time series analysis, decomposition and seasonal adjustment of time series, and anomaly detection are all indispensable advanced techniques for moving towards higher levels of time series forecasting. Mastering these advanced topics will help us build more precise and robust time series forecasting models.
# 5. Case Studies and Practical Exercises
In practical applications, time series forecasting techniques can have a significant impact across various fields, not limited to theoretical discussions but focusing more on how to transform these theories into actual operations. In this chapter, we will deeply analyze different industry forecasting cases through a practical perspective, demonstrating the construction process, optimization strategies, and the application of forecasting results for time series forecasting models.
## 5.1 Financial Market Forecasting Case
The financial market, especially the stock market, has always been a hotspot for time series forecasting research due to its inherent volatility and uncertainty. In this section, we will delve into how to build a stock price forecasting model and analyze its application in risk management.
### 5.1.1 Stock Price Forecasting Model in Practice
The stock price forecasting model is a typical case of financial market time series analysis. The construction and optimization process of the model can be divided into the following steps:
1. **Data Collection**: Acquire historical stock price data from financial markets, including information such as opening price, closing price, highest price, lowest price, and trading volume.
2. **Feature Selection**: Choose suitable features for prediction. This usually includes technical indicators, macroeconomic indicators, and company fundamentals.
3. **Data Preprocessing**: This includes handling missing values, detecting and processing outliers, and data normalization.
4. **Model Construction**: ***mon models include ARIMA, Random Forest, Neural Networks, etc.
5. **Model Training and Validation**: Train the model using historical data and evaluate the model's performance using a validation set.
6. **Model Forecasting and Optimization**: Apply the model to forecast future stock prices and adjust model parameters based on the forecast results to achieve more accurate predictions.
Below is a simple example of constructing a stock price forecasting model using Python's `pandas` library and `statsmodels` package to implement an ARIMA model:
```python
import pandas as pd
from statsmodels.tsa.arima.model import ARIMA
# Assume the dataframe 'df' contains historical stock closing price data
df = pd.read_csv('stock_prices.csv')
time_series = df['close_price']
# Construct an ARIMA model
model = ARIMA(time_series, order=(5, 1, 0))
model_fit = model.fit()
# Forecast
forecast = model_fit.forecast(steps=5) # Forecast the next 5 days
print(forecast)
```
In the code above, `order=(5, 1, 0)` are the parameters of the ARIMA model, representing the order of the AR term, the degree of differencing, and the order of the MA term, respectively. `model_fit.forecast(steps=5)` is used to forecast the next 5 days.
### 5.1.2 Application in Risk Management
In risk management, accurately forecasting stock prices can help investors understand future market trends, making wiser investment decisions. The main应用场景s of risk management include:
1. **Stop-loss Point Setting**: By predicting stock price trends, sell stocks in a timely manner when prices reach certain thresholds to avoid greater losses.
2. **Position Management**: Adjust stock positions in the portfolio based on forecast results to optimize the balance between risk and return.
3. **Market Trend Analysis**: Forecast models can help identify market trends, providing a basis for long-term investment decisions.
4. **Capital Allocation**: Allocate funds reasonably based on predicted market fluctuations to avoid a breakdown of the capital chain during market downturns.
## 5.2 Energy Consumption Forecasting Case
Energy consumption forecasting is crucial for energy planning and management. Accurate predictions can help energy companies, government agencies, and communities make better decisions about energy allocation.
### 5.2.1 Forecast Model Construction
Constructing an energy consumption forecasting model involves the following key steps:
1. **Data Collection**: Obtain historical energy consumption data, including records of electricity, natural gas, gasoline, and other energy sources.
2. **Correlation Analysis**: Analyze the correlation between energy consumption and factors such as weather, economic activities, and seasonal factors.
3. **Feature Engineering**: Based on the results of correlation analysis, perform feature selection and construction, which may include factors such as temperature, humidity, and specific holidays.
4. **Model Selection and Training**: Select an appropriate model for training based on the characteristics of the data. For example, energy consumption data may exhibit cyclical and seasonal patterns, so a seasonal ARIMA (SARIMA) model could be considered.
5. **Result Verification and Optimization**: Validate the model's accuracy and generalization ability using techniques such as cross-validation and optimize the model based on the verification results.
Below is an example using Python's `pandas` and `statsmodels` libraries to construct a SARIMA model:
```python
from statsmodels.tsa.statespace.sarimax import SARIMAX
# Assume df is a DataFrame containing energy consumption data
energy_consumption = df['energy_consumption']
# Construct a SARIMA model
model = SARIMAX(energy_consumption, order=(1, 1, 1), seasonal_order=(1, 1, 1, 12))
model_fit = model.fit(disp=False)
# Forecast
forecast = model_fit.forecast(steps=12) # Forecast the next 12 months
print(forecast)
```
In the above code, `seasonal_order=(1, 1, 1, 12)` defines the parameters of the seasonal ARIMA model, where the last parameter 12 represents the months in a year, indicating that the model will consider data with a 12-month cycle.
### 5.2.2 Application of Forecast Results in Energy Management
The application of energy consumption forecasting models in energy management includes:
1. **Electricity Dispatching**: Optimize the allocation of electric power resources, especially during peak hours and in areas with high electricity consumption.
2. **Energy Procurement Planning**: Arrange energy procurement and storage reasonably based on future demand forecasts.
3. **Energy Saving and Emission Reduction**: Through forecasting results, energy companies can implement more effective energy-saving and emission reduction strategies.
4. **Pricing Decisions**: Energy suppliers can adjust energy prices based on forecast results to balance supply and demand.
## 5.3 Retail Sales Forecasting Case
In retail, sales forecasting is crucial for inventory management, supply chain optimization, and the formulation of promotional strategies.
### 5.3.1 Challenges and Opportunities in Demand Forecasting
The main challenges faced in retail sales forecasting include:
1. **Product Diversity**: A wide variety of retail products require more complex forecasting models.
2. **Seasonal Fluctuations**: Holidays and promotion seasons have a significant impact on sales.
3. **Supply Chain Complexity**: The instability of the supply chain may lead to decreased forecasting accuracy.
4. **Consumer Behavior Changes**: Changes in consumer preferences increase the uncertainty of sales forecasting.
Despite these challenges, sales forecasting also brings significant opportunities:
1. **Inventory Optimization**: Accurate sales forecasting can significantly reduce inventory costs and reduce overstock.
2. **Personalized Marketing**: By analyzing sales trends, customers can be provided with a more personalized shopping experience.
3. **Supply Chain Collaboration**: Forecast results can promote collaboration among supply chain parties, improving overall efficiency.
4. **Dynamic Pricing**: Sales forecasting supports retailers in implementing dynamic pricing strategies to attract more consumers.
### 5.3.2 Impact of Forecast Results on Inventory Management
In inventory management, the application of sales forecasting is reflected in:
1. **Replenishment Strategy**: Develop a reasonable replenishment plan based on forecast results to ensure adequate inventory while avoiding overstock.
2. **Inventory Optimization**: Dynamically adjust inventory levels to reduce the risk of overstock and free up capital.
3. **Reducing Stockouts**: Accurate forecasting helps reduce stockouts due to insufficient inventory.
4. **Product Lifecycle Management**: Through sales trend analysis, rationally plan product launch and withdrawal times.
The above case studies and practical exercises demonstrate the practical applications of time series forecasting techniques in different fields. Through these cases, we can see that building effective forecasting models requires not only a deep understanding of the theoretical foundations of time series analysis but also consideration of the specific needs and challenges of the industry. Moreover, the construction and optimization of models is an iterative process that requires the integration of business knowledge and the latest data analysis techniques to achieve stable and reliable forecasting results in a complex and ever-changing environment.
# 6. Future Trends of Time Series Forecasting Technologies
## 6.1 Recent Advances in Machine Learning Technologies
With the enhancement of computing power and the progress of algorithms, machine learning has become an important tool for time series forecasting. In recent years, some significant advances have made forecasting models more accurate and efficient.
### 6.1.1 Deep Learning and Time Series Forecasting
Deep learning technologies can automatically extract features from large-scale unstructured data through the construction of multi-layer neural networks, providing new possibilities for time series forecasting. In particular, recurrent neural networks (RNN) and their variants, long short-term memory networks (LSTM) and gated recurrent units (GRU), have achieved significant success in the field of sequence prediction. These models are capable of handling time dependencies within sequential data and excel in capturing long-term trends and cyclical patterns.
The following is a simplified LSTM model example using the Keras library for time series data forecasting:
```python
from keras.models import Sequential
from keras.layers import LSTM, Dense
# Assume we already have preprocessed time series data train_X, train_y
model = Sequential()
model.add(LSTM(50, activation='relu', input_shape=(n_timesteps, n_features)))
model.add(Dense(1))
***pile(optimizer='adam', loss='mse')
# Train the model
model.fit(train_X, train_y, epochs=200, verbose=0)
# Make a prediction
y_pred = model.predict(test_X)
```
In the code
 最低0.47元/天 解锁专栏
最低0.47元/天 解锁专栏 送3个月
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Python print语句装饰器魔法:代码复用与增强的终极指南

# 1. Python print语句基础
## 1.1 print函数的基本用法
Python中的`print`函数是最基本的输出工具,几乎所有程序员都曾频繁地使用它来查看变量值或调试程序。以下是一个简单的例子来说明`print`的基本用法:
```python
print("Hello, World!")
```
这个简单的语句会输出字符串到标准输出,即你的控制台或终端。`prin
Python数组在科学计算中的高级技巧:专家分享

# 1. Python数组基础及其在科学计算中的角色
数据是科学研究和工程应用中的核心要素,而数组作为处理大量数据的主要工具,在Python科学计算中占据着举足轻重的地位。在本章中,我们将从Python基础出发,逐步介绍数组的概念、类型,以及在科学计算中扮演的重要角色。
## 1.1 Python数组的基本概念
数组是同类型元素的有序集合,相较于Python的列表,数组在内存中连续存储,允
Python序列化与反序列化高级技巧:精通pickle模块用法

# 1. Python序列化与反序列化概述
在信息处理和数据交换日益频繁的今天,数据持久化成为了软件开发中不可或缺的一环。序列化(Serialization)和反序列化(Deserialization)是数据持久化的重要组成部分,它们能够将复杂的数据结构或对象状态转换为可存储或可传输的格式,以及还原成原始数据结构的过程。
序列化通常用于数据存储、
Python pip性能提升之道
# 1. Python pip工具概述
Python开发者几乎每天都会与pip打交道,它是Python包的安装和管理工具,使得安装第三方库变得像“pip install 包名”一样简单。本章将带你进入pip的世界,从其功能特性到安装方法,再到对常见问题的解答,我们一步步深入了解这一Python生态系统中不可或缺的工具。
首先,pip是一个全称“Pip Installs Pac
Parallelization Techniques for Matlab Autocorrelation Function: Enhancing Efficiency in Big Data Analysis
# 1. Introduction to Matlab Autocorrelation Function
The autocorrelation function is a vital analytical tool in time-domain signal processing, capable of measuring the similarity of a signal with itself at varying time lags. In Matlab, the autocorrelation function can be calculated using the `xcorr
【Python集合异常处理攻略】:集合在错误控制中的有效策略

# 1. Python集合的基础知识
Python集合是一种无序的、不重复的数据结构,提供了丰富的操作用于处理数据集合。集合(set)与列表(list)、元组(tuple)、字典(dict)一样,是Python中的内置数据类型之一。它擅长于去除重复元素并进行成员关系测试,是进行集合操作和数学集合运算的理想选择。
集合的基础操作包括创建集合、添加元素、删除元素、成员测试和集合之间的运
Python装饰模式实现:类设计中的可插拔功能扩展指南
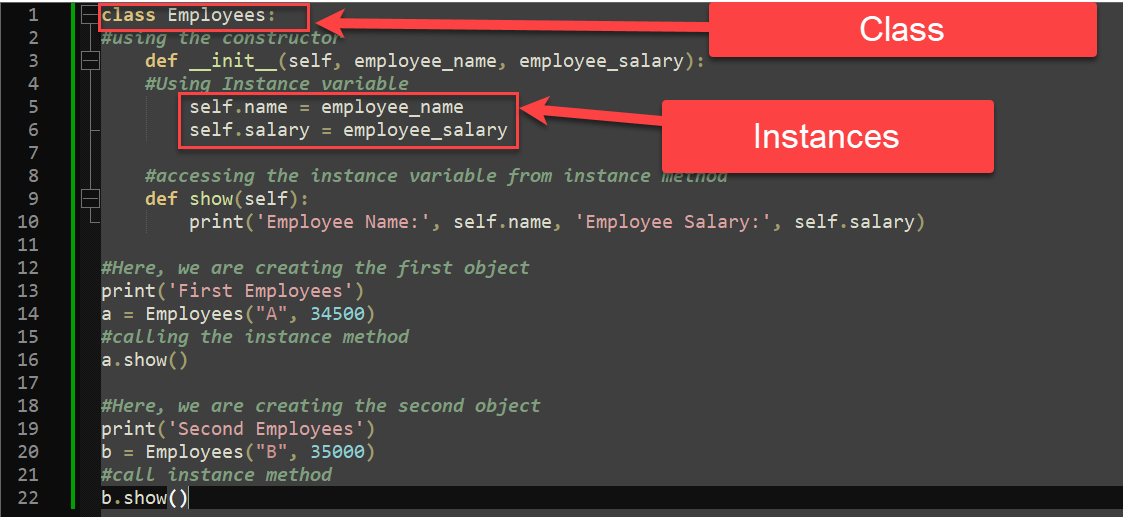
# 1. Python装饰模式概述
装饰模式(Decorator Pattern)是一种结构型设计模式,它允许动态地添加或修改对象的行为。在Python中,由于其灵活性和动态语言特性,装饰模式得到了广泛的应用。装饰模式通过使用“装饰者”(Decorator)来包裹真实的对象,以此来为原始对象添加新的功能或改变其行为,而不需要修改原始对象的代码。本章将简要介绍Python中装饰模式的概念及其重要性,为理解后
Python版本与性能优化:选择合适版本的5个关键因素

# 1. Python版本选择的重要性
Python是不断发展的编程语言,每个新版本都会带来改进和新特性。选择合适的Python版本至关重要,因为不同的项目对语言特性的需求差异较大,错误的版本选择可能会导致不必要的兼容性问题、性能瓶颈甚至项目失败。本章将深入探讨Python版本选择的重要性,为读者提供选择和评估Python版本的决策依据。
Python的版本更新速度和特性变化需要开发者们保持敏锐的洞
【Python字典内存管理】:避免内存泄漏,提升性能的高级技巧
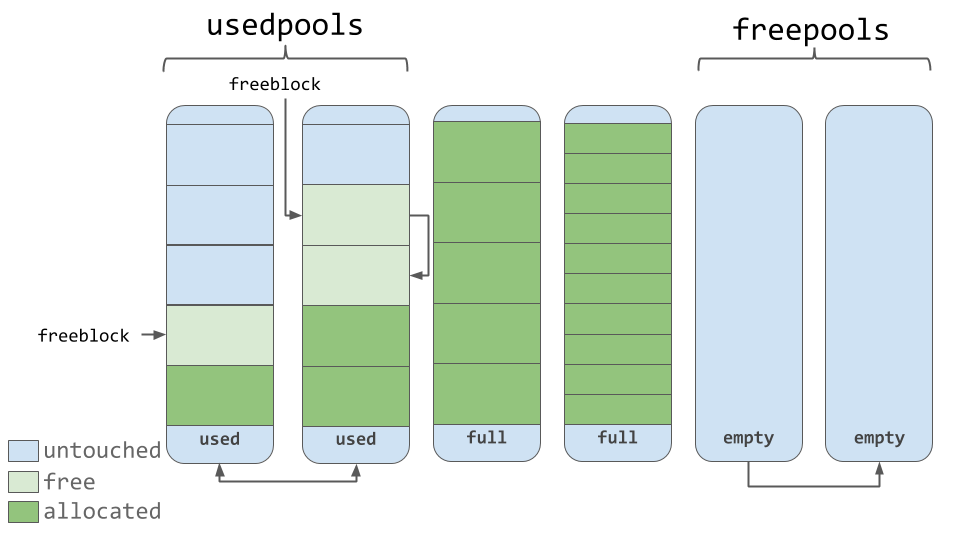
# 1. Python字典基础与内存机制
Python字典是构建于哈希表之上的高级数据结构,用于存储键值对(key-value pairs)。在本章中,我们将从基础开始,逐步深入探讨Python字典背后的内存机制。
## 1.1 字典对象的内存布局
在内存层面,Python字典主要由两个部分组成:键(keys)和值(values)。字典会根据键的哈希值来存储数据,保证数据的快
Pandas中的文本数据处理:字符串操作与正则表达式的高级应用

# 1. Pandas文本数据处理概览
Pandas库不仅在数据清洗、数据处理领域享有盛誉,而且在文本数据处理方面也有着独特的优势。在本章中,我们将介绍Pandas处理文本数据的核心概念和基础应用。通过Pandas,我们可以轻松地对数据集中的文本进行各种形式的操作,比如提取信息、转换格式、数据清洗等。
我们会从基础的字
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )