Loss Function in YOLOv10: In-depth Analysis, Understanding Its Design and Role
发布时间: 2024-09-13 20:24:37 阅读量: 169 订阅数: 42 

离散数学课后题答案+sdut往年试卷+复习提纲资料
# 1. Overview of YOLOv10
YOLOv10 is an advanced object detection algorithm renowned for its speed and accuracy. It employs a single forward pass to detect objects in images, making it more efficient than traditional region-based methods. The loss function in YOLOv10 plays a crucial role in the algorithm's performance, combining cross-entropy loss, coordinate loss, and confidence loss to optimize the model's detection and localization of objects.
# 2. Theoretical Basis of YOLOv10 Loss Function
The loss function of YOLOv10 consists of three parts: cross-entropy loss, coordinate loss, and confidence loss. These three loss functions work together to guide the model in learning the object detection task.
### 2.1 Cross-Entropy Loss
Cross-entropy loss measures the difference between the predicted class probability distribution and the true class distribution. In object detection, each grid cell predicts a class probability distribution, representing the probability of different classes being present in that grid cell. The true class distribution is represented by a one-hot encoded vector, where only the element corresponding to the target class is 1, and all other elements are 0. The formula for calculating cross-entropy loss is as follows:
```python
L_cls = -∑(p_i * log(q_i))
```
Where:
* L_cls: Cross-entropy loss
* p_i: Predicted class probability distribution
* q_i: True class distribution
### 2.2 Coordinate Loss
Coordinate loss measures the difference between the predicted bounding box and the true bounding box. YOLOv10 uses center point error loss and width and height error loss to calculate coordinate loss.
#### 2.2.1 Center Point Error Loss
Center point error loss measures the distance between the predicted bounding box center point and the true bounding box center point. The formula for calculating center point error loss is as follows:
```python
L_cent = ∑((x_pred - x_true)^2 + (y_pred - y_true)^2)
```
Where:
* L_cent: Center point error loss
* x_pred: Predicted bounding box center point x coordinate
* x_true: True bounding box center point x coordinate
* y_pred: Predicted bounding box center point y coordinate
* y_true: True bounding box center point y coordinate
#### 2.2.2 Width and Height Error Loss
Width and height error loss measures the difference between the predicted bounding box's width and height and the true bounding box's width and height. The formula for calculating width and height error loss is as follows:
```python
L_wh = ∑((w_pred - w_true)^2 + (h_pred - h_true)^2)
```
Where:
* L_wh: Width and height error loss
* w_pred: Predicted bounding box width
* w_true: True bounding box width
* h_pred: Predicted bounding box height
* h_true: True bounding box height
### 2.3 Confidence Loss
Confidence loss measures the confidence of the predicted bounding box in containing the target. YOLOv10 uses object confidence loss and background confidence loss to calculate confidence loss.
#### 2.3.1 Object Confidence Loss
Object confidence loss measures the difference between the confidence that the predicted bounding box contains the target and the true confidence. The formula for calculating object confidence loss is as follows:
```python
L_obj = -∑(p_obj * log(q_obj))
```
Where:
* L_obj: Object confidence loss
* p_obj: Confidence that the predicted bounding box contains the target
* q_obj: True confidence that the bounding box contains the target
#### 2.3.2 Background Confidence Loss
Background confidence loss measures the difference between the confidence that the predicted bounding box does not contain the target and the true confidence. The formula for calculating background confidence loss is as follows:
```python
L_noobj = -∑((1 - p_obj) * log(1 - q_obj))
```
Where:
* L_noobj: Background confidence loss
* p_obj: Confidence that the predicted bounding box contains the target
* q_obj: True confidence that the bounding box contains the target
# 3.1 Calculation of Cross-Entropy Loss
Cross-entropy loss is used to measure the difference between the predicted value and the true value. In object detection, cross-entropy loss is used to measure the difference between the predicted class probabilities and the true class. The formula for calculating cross-entropy loss in YOLOv10 is:
```python
CE_loss = -y_true * log(y_pred) - (1 - y_true) * log(1 - y_pred)
```
Where:
* `y_true` represents the true class label, in one-hot encoded form
* `y_pred` represents the predicted class probabilities, in softmax output
**Parameter Explanation:**
* `y_true`: True class label, with the shape of `(batch_size, num_classes)`
* `y_pred`: Predicted class probabilities, with the shape of `(batch_size, num_classes)`
**Code Logic Interpretation:**
1. For each sample, calculate the cross-entropy loss between the predicted class probabilities and the true class labels.
2. For each sample, sum the cross-entropy loss for all classes.
3. Average the cross-entropy loss across all samples to obtain the final cross-entropy loss.
### 3.2 Calculation of Coordinate Loss
Coordinate loss is used to measure the difference between the predicted bounding box and the true bounding box. The formula for calculating coordinate loss in YOLOv10 is:
```python
coord_loss = lambda_coord * (
(y_true[:, :, :, 0] - y_pred[:, :, :, 0]) ** 2
+ (y_true[:, :, :, 1] - y_pred[:, :, :, 1]) ** 2
+ (y_true[:, :, :, 2] - y_pred[:, :, :, 2]) ** 2
+ (y_true[:, :, :, 3] - y_pred[:, :, :, 3]) ** 2
)
```
Where:
* `y_true` represents the true bounding box, with the shape of `(batch_size, num_boxes, 4)`, where 4 represents the center point coordinates `(x, y)` and the width and height `(w, h)` of the bounding box.
* `y_pred` represents the predicted bounding box, with the shape of `(batch_size, num_boxes, 4)`.
* `lambda_coord` is the weight coefficient for coordinate loss.
**Parameter Explanation:**
* `y_true`: True bounding box, with the shape of `(batch_size, num_boxes, 4)`
* `y_pred`: Predicted bounding box, with the shape of `(batch_size, num_boxes, 4)`
* `lambda_coord`: Weight coefficient for coordinate loss, used to balance coordinate loss and confidence loss
**Code Logic Interpretation:**
1. For each sample, calculate the difference between the predicted bounding box and the true bounding box.
2. For each sample, sum the squared differences for all bounding boxes.
3. Average the squared differences across all samples to obtain the final coordinate loss.
### 3.3 Calculation of Confidence Loss
Confidence loss is used to measure the overlap between the predicted bounding box and the true bounding box. The formula for calculating confidence loss in YOLOv10 is:
```python
conf_loss = lambda_conf * (
y_true[:, :, :, 4] * (
(y_true[:, :, :, 4] - y_pred[:, :, :, 4]) ** 2
)
+ (1 - y_true[:, :, :, 4]) * (
(y_true[:, :, :, 5] - y_pred[:, :, :, 5]) ** 2
)
)
```
Where:
* `y_true` represents the true bounding box, with the shape of `(batch_size, num_boxes, 6)`, where 6 represents the center point coordinates `(x, y)`, width and height `(w, h)`, object confidence `(obj)`, and background confidence `(noobj)` of the bounding box.
* `y_pred` represents the predicted bounding box, with the shape of `(batch_size, num_boxes, 6)`.
* `lambda_conf` is the weight coefficient for confidence loss.
**Parameter Explanation:**
* `y_true`: True bounding box, with the shape of `(batch_size, num_boxes, 6)`
* `y_pred`: Predicted bounding box, with the shape of `(batch_size, num_boxes, 6)`
* `lambda_conf`: Weight coefficient for confidence loss, used to balance confidence loss and coordinate loss
**Code Logic Interpretation:**
1. For each sample, calculate the overlap between the predicted bounding box and the true bounding box.
2. For each sample, sum the squared overlaps for all bounding boxes.
3. Average the squared overlaps across all samples to obtain the final confidence loss.
# 4. Optimization of YOLOv10 Loss Function
### 4.1 Weight Balancing
In the YOLOv10 loss function, the weight balancing of different loss terms is crucial. Weight balancing can control the influence of different loss terms on the total loss, thereby adjusting the direction of the model's training.
In YOLOv10, the total loss is usually calculated using the following formula:
```python
total_loss = λ1 * cross_entropy_loss + λ2 * coordinate_loss + λ3 * confidence_loss
```
Where, λ1, λ2, and λ3 are the weights for cross-entropy loss, coordinate loss, and confidence loss, respectively.
Weight balancing can be optimized through the following methods:
- **Grid Search:** By grid searching different weight combinations, the optimal weight configuration can be found.
- **Adaptive Weight Adjustment:** Dynamically adjust weights based on the model's performance during training.
- **Empirical Rules:** Set weights based on experience and intuition, for example, for object detection tasks, the weight of coordinate loss is usually set higher than that of cross-entropy loss and confidence loss.
### 4.2 Regularization
Regularization techniques can prevent model overfitting and improve the model'***mon regularization techniques in the YOLOv10 loss function include:
- **Weight Decay:** Add a weight decay term to the loss function to penalize large values of the model's weights.
- **Data Augmentation:** Increase the diversity of training data through data augmentation techniques such as random cropping, rotation, and flipping to prevent the model from overfitting to a specific dataset.
- **Dropout:** Randomly drop some nodes in the neural network during training to prevent the model from overly relying on specific features.
### 4.3 Hard Example Mining
Hard example mining techniques can identify and process samples that are difficult to classify in the training set, thereby improving the model's ability to handle difficult cases. In the YOLOv10 loss function, hard example mining can be achieved through the following methods:
- **Confidence-Based Hard Example Mining:** Identify samples with low confidence as hard cases based on the model's predicted confidence.
- **Gradient-Based Hard Example Mining:** Identify samples with large gradients by calculating the norm of the model's gradients.
- **Loss-Based Hard Example Mining:** Identify samples with large loss values based on the model's predicted loss.
Through hard example mining, the model can focus on samples that are difficult to classify, thereby improving the overall performance of the model.
# 5.1 Training of Object Detection Models
**5.1.1 Preparation of Training Dataset**
Training object detection models requires preparing a high-quality training dataset. The dataset should contain a large number of annotated images, including various object categories, sizes, and shapes. The images should be diverse, covering different scenes, lighting conditions, and backgrounds.
**5.1.2 Model Configuration**
Before training the model, model parameters need to be configured, including the network architecture, hyperparameters, and training strategies. The network architecture determines the model's structure and capacity, hyperparameters control the training process, and the training strategy specifies the optimization algorithm, learning rate, and training cycles.
**5.1.3 Model Training**
The model training process involves feeding the training dataset into the model and using the backpropagation algorithm to update the model weights. The backpropagation algorithm calculates the gradient of the loss function and updates the weights based on the gradient to minimize the loss. The training process is carried out over multiple epochs, with each epoch containing multiple training batches.
**5.1.4 Training Monitoring**
During the training process, it is necessary to monitor the model's training progress and performance. This can be achieved by tracking the loss function and accuracy on the training and validation sets. Monitoring results help identify issues during training, such as overfitting or underfitting, and adjustments can be made as needed.
**Code Block 5.1: YOLOv10 Model Training in PyTorch**
```python
import torch
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
# Prepare training dataset
train_dataset = datasets.CocoDetection(root="path/to/train", annFile="path/to/train.json")
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
# Define model
model = YOLOv10()
# Define loss function
loss_fn = YOLOv10Loss()
# Define optimizer
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# Train model
for epoch in range(100):
for batch in train_loader:
images, targets = batch
outputs = model(images)
loss = loss_fn(outputs, targets)
optimizer.zero_grad()
loss.backward()
optimizer.step()
```
**Code Logic Analysis:**
* This code block demonstrates the process of training the YOLOv10 model using PyTorch.
* It first prepares the training dataset and loads it into the DataLoader.
* Then, it defines the YOLOv10 model, loss function, and optimizer.
* The training loop iterates over epochs and batches of the training dataset, computes the loss, and uses backpropagation to update the model weights.
**Parameter Explanation:**
* `root`: Root directory of training images.
* `annFile`: Path to the JSON file containing annotations for training images.
* `batch_size`: Size of training batches.
* `shuffle`: Whether to shuffle the training dataset at the beginning of each epoch.
* `lr`: Learning rate of the optimizer.
## 5.2 Model Performance Evaluation
After training, it is necessary to evaluate the model's performance. Evaluation is typically performed on a validation set or test set, which is different from the training set and is used to assess the model's generalization ability.
**5.2.1 Selection of Metrics**
The performance of object detection models is usually evaluated using the following metrics:
***Mean Average Precision (mAP):** Measures the accuracy and recall of the model in detecting objects.
***Precision:** Measures the proportion of objects correctly detected by the model.
***Recall:** Measures the proportion of objects detected by the model out of all objects.
***Mean Absolute Error (MAE):** Measures the average distance between the model's predicted bounding boxes and the true bounding boxes.
**5.2.2 Evaluation Process**
The evaluation process involves inputting the validation or test set into the model and calculating the evaluation metrics. The results can be used to compare the performance of different models and identify areas for improvement.
**Code Block 5.2: YOLOv10 Model Evaluation in PyTorch**
```python
import torch
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
# Prepare validation dataset
val_dataset = datasets.CocoDetection(root="path/to/val", annFile="path/to/val.json")
val_loader = DataLoader(val_dataset, batch_size=32, shuffle=False)
# Define model
model = YOLOv10()
# Define evaluation metrics
evaluator = COCOEvaluator()
# Evaluate model
for batch in val_loader:
images, targets = batch
outputs = model(images)
evaluator.update(outputs, targets)
# Obtain evaluation results
results = evaluator.get_results()
```
**Code Logic Analysis:**
* This code block demonstrates the process of evaluating the YOLOv10 model using PyTorch.
* It first prepares the validation dataset and loads it into the DataLoader.
* Then, it defines the YOLOv10 model and evaluator.
* The evaluation loop iterates over batches of the validation dataset, computes predictions, and updates the evaluator.
* Finally, it obtains the evaluation results, such as mAP, precision, and recall.
**Parameter Explanation:**
* `root`: Root directory of validation images.
* `annFile`: Path to the JSON file containing annotations for validation images.
* `batch_size`: Size of validation batches.
* `shuffle`: Whether to shuffle the validation dataset at the beginning of each epoch.
# 6. Future Development of YOLOv10 Loss Function
### 6.1 Innovative Design of Loss Function
As the field of computer vision continues to develop, object detection algorithms are also advancing. To improve the performance of object detection models, researchers are exploring new loss function designs.
**IOU Loss**
IOU loss (Intersection over Union Loss) is a loss function based on the Intersection over Union (IOU) metric. IOU measures the degree of overlap between the predicted bounding box and the true bounding box. IOU loss penalizes the difference between predicted and true bounding boxes by minimizing IOU.
**GIoU Loss**
GIoU loss (Generalized Intersection over Union Loss) is a generalization of IOU loss. GIoU loss considers not only the IOU but also the smallest closed region that encompasses both bounding boxes. GIoU loss penalizes the difference between predicted and true bounding boxes by minimizing GIoU.
### 6.2 Fusion with Other Loss Functions
Researchers are also exploring methods to fuse the YOLOv10 loss function with other loss functions.
**Focal Loss**
Focal Loss is a loss function designed to address the problem of class imbalance in object detection. Focal Loss assigns higher weights to negative samples to penalize the model's misclassification of negative samples.
**Smooth L1 Loss**
Smooth L1 Loss is a loss function used for regression tasks. Smooth L1 Loss uses L1 loss for small errors and L2 loss for large errors. Smooth L1 Loss can effectively handle large errors present in regression tasks.
By fusing the YOLOv10 loss function with other loss functions, the performance of object detection models can be further improved.

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
J1939高级分析实战:CANoe中的诊断通信与故障诊断案例研究
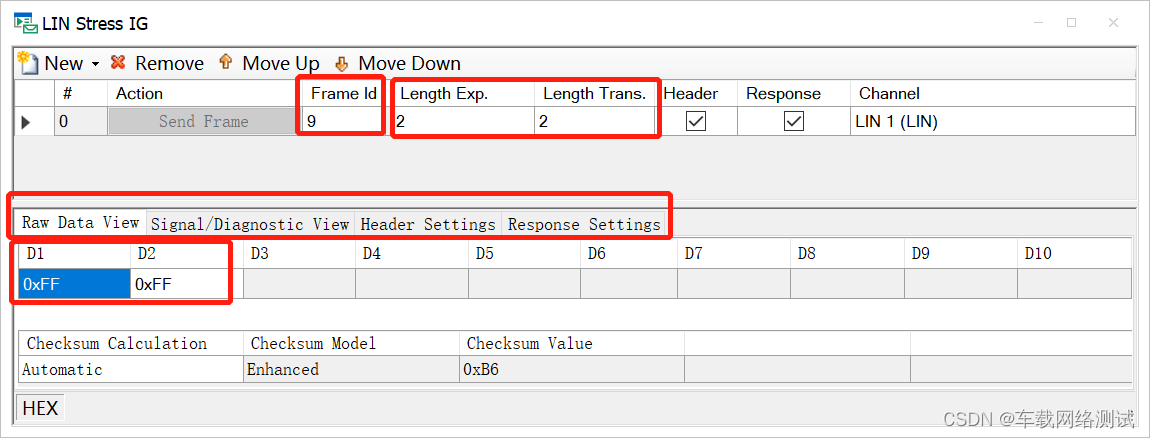
# 摘要
本文详细介绍了J1939协议的基础知识、诊断通信原理及在CANoe环境下的配置和应用。首先概述了J1939协议的基本架构和诊断数据包的结构,并分析了其诊断通信的实现机制。随后,探讨了如何在CANoe软件中进行J1939诊断配置,以及如何模拟和分析诊断功能。文章还提供了J1939故障诊断的实际案例,包括故障代码的读取、清除以及诊断过程的实战演练。最后,对J1939诊断通信的安全性进行了分析,并探讨了其自动化、智能化的趋势和
C++异常处理艺术:习题与最佳实践,打造健壮代码
# 摘要
本文全面探讨了C++异常处理的基础知识、理论与技巧、进阶技术,以及在实际应用中的案例和性能影响与优化方法。首先,文章介绍了异常处理的基础和理论,包括异常处理机制的理解、异常分类与特性以及如何设计健壮的异常安全代码。接着,文章深入探讨了异常处理的最佳实践,包括自定义异常类、异常捕获与处理策略以及异常与资源管理。在实际应用案例中,文章分析了异常处理在库设计、第三方库异常处理以及系统编程中的应用。最后,文章讨论了异常处理的性能影响、优化策略,并对未来C++异常处理的发展趋势进行了展望。本文旨在为C++开发者提供一个系统性的异常处理知识框架,帮助他们编写出既健壮又高效的代码。
# 关键字
系统性能升级秘籍:BES2300-L优化技巧与成功案例
# 摘要
BES2300-L系统作为研究焦点,本文首先概述了其基本架构与性能基础。随后,对BES2300-L进行了深入的性能评估和监控,包括评估方法论的解析、系统资源管理策略、以及网络性能优化技术的探讨。紧接着,本文详细介绍了BES2300-L系统调优实践,包括系统参数、内核配置以及应用层性能优化。此外,对于系统故障的诊断与解
自动化调度系统中的权限管理与安全策略(安全至上)
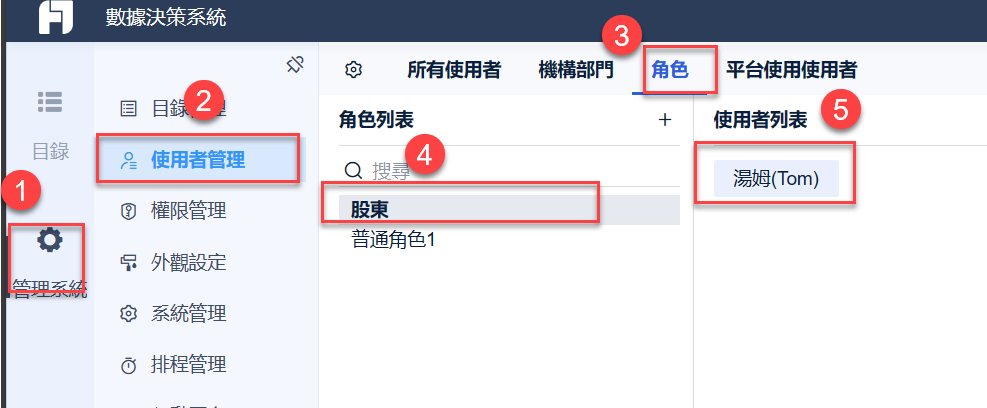
# 摘要
本文详细探讨了自动化调度系统的权限管理基础和高效权限模型的理论基础,重点分析了基于角色的权限控制(RBAC)模型及其在自动化调度中的应用,并讨论了最小权限原则和职责分离策略的实施细节。文章进一步阐述了安全策略的规划、身份验证、授权机制、安全审计和监控的实施方法。在实践中,本文提供了策略实施的软件工具和方法,安全漏洞的发现与修补流程,以及合规性标准的建立。最后,展望了自动化调度系
Multisim JK触发器仿真:掌握设计与测试的六大技巧(专家建议)

# 摘要
本文对Multisim软件环境下JK触发器的仿真进行了全面的介绍和分析。首先概述了JK触发器的仿真概况和基础理论,包括其工作原理、逻辑状态转换规则及电路设计。
【办公高效秘籍】:富士施乐DocuCentre SC2022高级功能全解析(隐藏技能大公开)
# 摘要
本文全面介绍DocuCentre SC2022的功能和使用技巧,内容涵盖从基本的界面导航到高级的文档管理、打印技术和网络连接管理。通过解析高级扫描功能和文档整理策略,提出提高办公效率的设置调整方法。此外,本文还探讨了打印技术的成本控制、网络连接安全性以及远程打印管理。最后,分析了设备的高级功能和定制化办公解决方案,展望了办公自动化未来的发展趋势,包括集成解决方案和机器学习的应用。
# 关键字
DocuCentre SC2022;文档管理;打印技术;网络连接;成本控制;办公自动化
参考资源链接:[富士施乐DocuCentre SC2022操作手册](https://wenku.cs
XJC-CF3600F保养专家

# 摘要
本文综述了XJC-CF3600F设备的概况、维护保养理论与实践,以及未来展望。首先介绍设备的工作原理和核心技术,然后详细讨论了设备的维护保养理论,包括其重要性和磨损老化规律。接着,文章转入操作实践,涵盖了日常检查、定期保养、专项维护,以及故障诊断与应急响应的技巧和流程。案例分析部分探讨了成功保养的案例和经验教训,并分析了新技术在案例中的应用及其对未来保养策略的
提升系统响应速度:OpenProtocol-MTF6000性能优化策略

# 摘要
本文全面探讨了OpenProtocol-MTF6000系统的性能分析与优化,首先介绍了系统的总体概述,随后深入分析了影响性能的关键指标和理论基础。在此基础上,文中详述了实践中性能调优的技巧,包括系统参数、应用程序以及负载均衡和扩展性策略
【Python降级实战秘籍】:精通版本切换的10大步骤与技巧
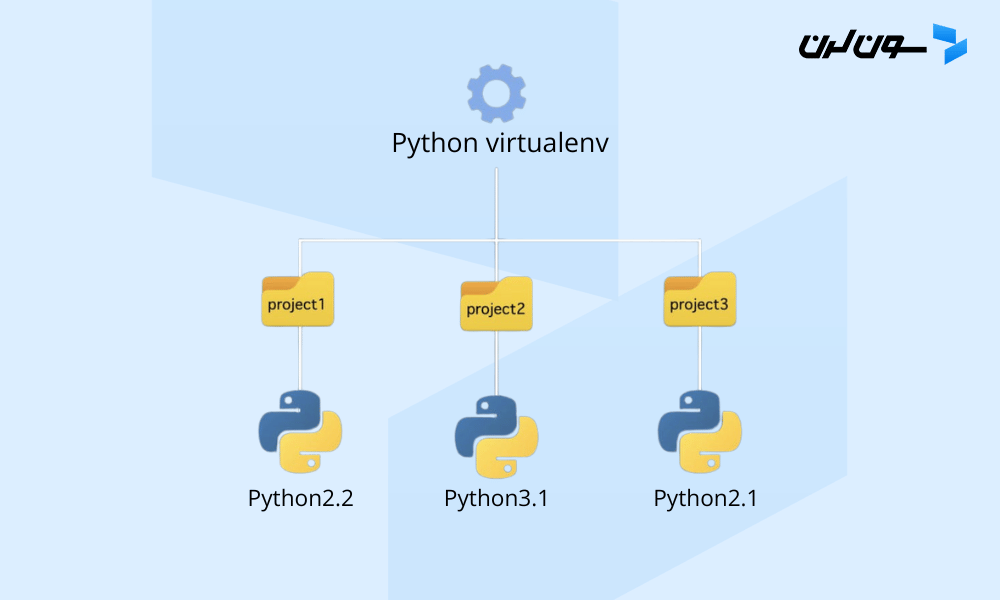
# 摘要
本文针对Python版本管理的需求与实践进行了全面探讨。首先介绍了版本管理的必要性与基本概念,然后详细阐述了版本切换的准备工作,包括理解命名规则、安装和配置管理工具以及环境变量的设置。进一步,本文提供了一个详细的步骤指南,指导用户如何执行Python版本的切换、降级操作,并提供实战技巧和潜在问题的解决方案。最后,文章展望了版本管理的进阶应用和降级技术的未来,讨论了新兴工具的发展趋势以及降级技术面临的挑战和创新方
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )