YOLOv10 Training Guide: Master in 10 Steps, from Data Preparation to Model Optimization
发布时间: 2024-09-13 20:23:05 阅读量: 79 订阅数: 44 

论文研究-An Optimization Model for Outlier Detection in Categorical Data.pdf
# YOLOv10 Training Guide: Master 10 Steps from Data Preparation to Model Optimization
## 1. Overview of YOLOv10 and Training Preparation
### 1.1 YOLOv10 Overview
YOLOv10, the latest version of the You Only Look Once (YOLO) object detection algorithm, was released by Megvii Technology in 2023. It integrates advanced computer vision technologies, including Transformers and Anchor-Free design, achieving breakthroughs in both accuracy and speed of object detection.
### 1.2 Training Preparation
Before training a YOLOv10 model, necessary preparations include:
- **Data Collection and Preprocessing:** Collect high-quality image datasets and preprocess them, such as resizing, cropping, and augmentation.
- **Image Annotation:** Annotate the objects in images using labeling tools, including object categories and bounding box coordinates.
- **Model Download:** Download a pre-trained YOLOv10 model as a starting point for training.
## 2. Data Preparation and Annotation
### 2.1 Data Collection and Preprocessing
**Data Collection**
Training YOLOv10 requires a vast amount of annotated data, which can be collected from various sources, including:
- Public datasets: COCO, VOC, ImageNet, etc.
- Custom datasets: Depending on specific application scenarios.
- Data Augmentation: Enhance existing data through techniques like rotation, cropping, and flipping to increase dataset diversity.
**Data Preprocessing**
Collected data needs to be preprocessed to meet YOLOv10 training requirements, including:
- **Image Resizing:** Adjust images to a uniform size, for example, 416x416.
- **Data Format Conversion:** Convert images and annotation information to formats supported by YOLOv10, such as VOC or COCO format.
- **Data Cleaning:** Remove damaged or irrelevant images and annotations.
### 2.2 Image Annotation and Data Format Conversion
**Image Annotation**
Image annotation is the process of creating bounding boxes and category labels for objects within images. The following tools can be used for image annotation:
- LabelImg
- LabelBox
- VGG Image Annotator
**Data Format Conversion**
After annotation, data must be converted to formats supported by YOLOv10, such as:
- **VOC Format:** XML files containing images, annotations, and metadata information.
- **COCO Format:** JSON files containing images, annotations, and metadata information.
**Code Example:**
```python
import cv2
import os
# Annotate images and save as VOC format
def label_image(image_path, label_path):
# Load image
image = cv2.imread(image_path)
# Create an annotator
labeler = LabelImg(image)
# Annotate objects
labeler.label()
# Save annotation results
labeler.save(label_path)
# Convert VOC format data to COCO format
def convert_voc_to_coco(voc_dir, coco_path):
# Load VOC data
voc_images = os.listdir(os.path.join(voc_dir, "JPEGImages"))
voc_annotations = os.listdir(os.path.join(voc_dir, "Annotations"))
# Create COCO dataset
coco_dataset = {"images": [], "annotations": []}
# Iterate through VOC images and annotations
for image_file, annotation_file in zip(voc_images, voc_annotations):
# Load image and annotation
image = cv2.imread(os.path.join(voc_dir, "JPEGImages", image_file))
annotation = xml.etree.ElementTree.parse(os.path.join(voc_dir, "Annotations", annotation_file)).getroot()
# Create COCO image metadata
image_info = {
"id": int(annotation.find("filename").text),
"width": image.shape[1],
"height": image.shape[0],
"file_name": image_file
}
# Create COCO annotation metadata
annotations = []
for object in annotation.findall("object"):
bbox = object.find("bndbox")
annotation_info = {
"id": int(object.find("name").text),
"image_id": int(annotation.find("filename").text),
"category_id": int(object.find("name").text),
"bbox": [int(bbox.find("xmin").text), int(bbox.find("ymin").text), int(bbox.find("xmax").text), int(bbox.find("ymax").text)],
"iscrowd": 0
}
annotations.append(annotation_info)
# Add to COCO dataset
coco_dataset["images"].append(image_info)
coco_dataset["annotations"].extend(annotations)
# Save COCO dataset
with open(coco_path, "w") as f:
json.dump(coco_dataset, f)
```
## 3.1 Configuring Training Environment and Model Download
### Configuring the Training Environment
Before starting to train the YOLOv10 model, the training environment needs to be configured, which includes installing necessary software packages, setting up CUDA and cuDNN environments, and preparing training data.
#### Software Package Installation
Training YOLOv10 models requires the following software packages:
- Python 3.8 or higher
- PyTorch 1.10 or higher
- torchvision
- CUDA 11.3 or higher
- cuDNN 8.2 or higher
These packages can be installed using the following commands:
```
pip install torch torchvision
pip install torch-scatter torch-sparse torch-cluster torch-spline-conv torch-geometric
pip install pyyaml
```
#### CUDA and cuDNN Configuration
CUDA and cuDNN are libraries used to accelerate deep learning training. Ensure that these libraries are correctly installed and configured.
To check if CUDA and cuDNN are correctly installed, run the following command:
```
nvcc -V
```
If installed correctly, the version information of CUDA and cuDNN will be displayed.
### Model Download
The pre-trained weights of the YOLOv10 model can be found in the official GitHub repository:
```
***
```
Download the pre-trained weights and unzip them into the training directory.
## 3.2 Setting Hyperparameters and Model Training Optimization
### Setting Hyperparameters
Hyperparameters for YOLOv10 model training include:
- **batch_size:** The number of images in each training batch.
- **epochs:** The number of training iterations.
- **learning_rate:** The learning rate of the optimizer.
- **momentum:** The momentum of the optimizer.
- **weight_decay:** The weight decay of the optimizer.
These hyperparameters can be adjusted based on the training dataset and computational resources.
### Optimizer Selection
YOLOv10 model training typically uses the Adam optimizer. Adam is an adaptive learning rate optimizer that automatically adjusts the learning rate for each parameter.
### Loss Function
The loss function used in YOLOv10 model training combines cross-entropy loss and bounding box regression loss. The cross-entropy loss function is used for classification tasks, while the bounding box regression loss function is used for regressing bounding box coordinates.
### Training Process
The YOLOv10 model training process is as follows:
1. Load training data and pre-trained weights.
2. Set hyperparameters and optimizer.
3. Iterate through training batches.
4. Calculate the loss function and backpropagate.
5. Update model weights.
6. Repeat steps 3-5 until the specified number of training epochs is reached.
### Training Monitoring and Evaluation
During training, monitor the training loss and the accuracy of the model on the validation set. This can help track training progress and identify any potential issues.
TensorBoard or other visualization tools can be used to monitor the training process.
## 4. Model Evaluation and Optimization
### 4.1 Model Evaluation Metrics and Methods
After training the YOLOv10 model, ***mon model evaluation metrics include:
- **Mean Average Precision (mAP):** Measures the average accuracy of the model in detecting different categories of objects, ranging from 0 to 1.
- **Recall:** Measures the proportion of all true objects detected by the model, ranging from 0 to 1.
- **Accuracy:** Measures the proportion of objects correctly detected by the model, ranging from 0 to 1.
- **F1 Score:** The weighted average of recall and precision, ranging from 0 to 1.
**Evaluation Methods:**
1. **Cross-Validation:** Divide the dataset into training and test sets, train the model on the training set, and evaluate the model performance on the test set.
2. **Holdout Set:** Separate a portion of the training data as a holdout set to monitor the model's generalization ability during the training process.
### 4.2 Model Optimization Techniques and Hyperparameter Tuning Methods
To improve the performance of the YOLOv10 model, the following optimization techniques and hyperparameter tuning methods can be employed:
**Optimization Techniques:**
- **Data Augmentation:** Perform random cropping, rotation, flipping, etc., on training data to increase model robustness.
- **Regularization:** Use L1 or L2 regularization terms to penalize model weights and prevent overfitting.
- **Weight Initialization:** Use appropriate weight initialization methods, such as Xavier or He initialization, to ensure the stability of model training.
**Hyperparameter Tuning Methods:**
- **Learning Rate:** Adjust the learning rate to control the step size of model training and avoid overfitting or underfitting.
- **Batch Size:** Adjust the batch size to balance model training speed and stability.
- **Number of Epochs:** Increase the number of epochs to improve model accuracy but avoid overfitting.
- **Hyperparameter Search:** Use grid search or Bayesian optimization to search for the optimal combination of hyperparameters.
### 4.3 Optimization Process Example
**Code Block:**
```python
import tensorflow as tf
# Define hyperparameters
learning_rate = 0.001
batch_size = 32
num_epochs = 100
# Create model
model = tf.keras.models.load_model('yolov10.h5')
# ***
***pile(optimizer=tf.keras.optimizers.Adam(learning_rate),
loss='mse',
metrics=['accuracy'])
# Train model
model.fit(train_data, train_labels,
epochs=num_epochs,
batch_size=batch_size,
validation_data=(val_data, val_labels))
# Evaluate model
loss, accuracy = model.evaluate(test_data, test_labels)
print('Loss:', loss)
print('Accuracy:', accuracy)
```
**Logical Analysis:**
***
***pile the model, specifying the optimizer, loss function, and evaluation metrics.
3. Train the model, specifying the training data, number of epochs, and batch size.
4. Evaluate the model on the test set, outputting loss and accuracy.
**Parameter Explanation:**
- `learning_rate`: Learning rate, controlling the step size of model training.
- `batch_size`: Batch size, balancing model training speed and stability.
- `num_epochs`: Number of epochs, controlling the number of times the model is trained.
- `train_data`: Training data.
- `train_labels`: Training labels.
- `val_data`: Validation data.
- `val_labels`: Validation labels.
- `test_data`: Test data.
- `test_labels`: Test labels.
## 5. YOLOv10 Model Deployment and Applications
### 5.1 Model Export and Deployment
The trained YOLOv10 model needs to be exported in a deployable format for use in real-world scenarios. The steps for exporting the model are as follows:
```python
import tensorflow as tf
# Load the trained model
model = tf.keras.models.load_model("yolov10_trained_model.h5")
# Export the model to SavedModel format
model.save("yolov10_saved_model")
# Export the model to TFLite format (suitable for mobile devices)
converter = tf.lite.TFLiteConverter.from_keras_model(model)
tflite_model = converter.convert()
with open("yolov10_tflite_model.tflite", "wb") as f:
f.write(tflite_model)
```
### 5.2 Application and Integration of the Model in Real-World Scenarios
After exporting the model, ***mon application scenarios include:
- **Real-Time Object Detection:** Deploy the model on cameras or mobile devices to detect objects in real-time video streams.
- **Image Analysis:** Integrate the model into image processing software to analyze objects within images and extract relevant information.
- **Video Surveillance:** Deploy the model in monitoring systems to automatically detect and track anomalies or objects in videos.
The steps for integrating the model vary depending on the specific application but generally include:
1. **Choose the appropriate deployment platform:** Depending on the application scenario, choose a suitable deployment platform, such as servers, mobile devices, or embedded devices.
2. **Load the model:** Load the exported model onto the deployment platform.
3. **Preprocess the input:** Preprocess the input data (images or video frames) into the format required by the model.
4. **Model Inference:** Use the model to infer the preprocessed input and obtain object detection results.
5. **Post-process the output:** Post-process the inference results, such as filtering out low-confidence detection results or drawing object bounding boxes.
### Code Example: Using OpenCV to Integrate YOLOv10 Model for Real-Time Object Detection
```python
import cv2
import numpy as np
# Load the model
net = cv2.dnn.readNet("yolov10_saved_model/saved_model.pb")
# Initialize the camera
cap = cv2.VideoCapture(0)
while True:
# Read a frame
ret, frame = cap.read()
if not ret:
break
# Preprocess the frame
blob = cv2.dnn.blobFromImage(frame, 1 / 255.0, (416, 416), (0, 0, 0), swapRB=True, crop=False)
# Set input
net.setInput(blob)
# Forward propagation
detections = net.forward()
# Post-process output
for detection in detections[0, 0]:
score = float(detection[2])
if score > 0.5:
left = int(detection[3] * frame.shape[1])
top = int(detection[4] * frame.shape[0])
right = int(detection[5] * frame.shape[1])
bottom = int(detection[6] * frame.shape[0])
cv2.rectangle(frame, (left, top), (right, bottom), (0, 255, 0), 2)
# Display the frame
cv2.imshow("Frame", frame)
if cv2.waitKey(1) & 0xFF == ord("q"):
break
# Release the camera
cap.release()
cv2.destroyAllWindows()
```
## 6. Future Development and Prospects of YOLOv10
### 6.1 Advantages and Limitations of YOLOv10
**Advantages:**
- **Real-Time:** YOLOv10 has extremely fast inference speed for a single run, making it suitable for real-time object detection tasks.
- **Accuracy:** YOLOv10 achieves a mAP@0.5 of 56.8% on the COCO dataset, striking a good balance between accuracy and speed.
- **Versatility:** YOLOv10 can be applied to a wide range of object detection tasks, including image classification, object tracking, and instance segmentation.
**Limitations:**
- **Small Object Detection:** YOLOv10 still faces challenges in detecting small objects, especially when they are occluded or in complex backgrounds.
- **Generalization Ability:** YOLOv10 has limited generalization capabilities across different datasets and requires fine-tuning for specific tasks.
- **Memory Consumption:** The YOLOv10 model is relatively large, posing challenges for deployment on resource-constrained devices.
### 6.2 Future Development Directions and Research Trends of YOLOv10
**Development Directions:**
- **Improving Small Object Detection Accuracy:** Explore new network architectures and feature extraction techniques to enhance the detection of small objects.
- **Enhancing Generalization Ability:** Investigate data augmentation and transfer learning techniques to improve the model's generalization across different datasets.
- **Optimizing Model Size:** Develop lightweight YOLOv10 models while maintaining accuracy and speed.
**Research Trends:**
- **Attention Mechanism:** Integrate attention mechanisms into YOLOv10 to increase the model's focus on target areas.
- **Feature Fusion:** Explore different feature fusion strategies to leverage the complementarity of features at different levels.
- **Multi-Task Learning:** Combine object detection with other tasks (such as semantic segmentation, object tracking) to improve the overall performance of the model.

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
ECOTALK数据科学应用:机器学习模型在预测分析中的真实案例

# 摘要
本文对机器学习模型的基础理论与技术进行了综合概述,并详细探讨了数据准备、预处理技巧、模型构建与优化方法,以及预测分析案例研究。文章首先回顾了机器学习的基本概念和技术要点,然后重点介绍了数据清洗、特征工程、数据集划分以及交叉验证等关键环节。接
【Ubuntu 16.04系统更新与维护】:保持系统最新状态的策略
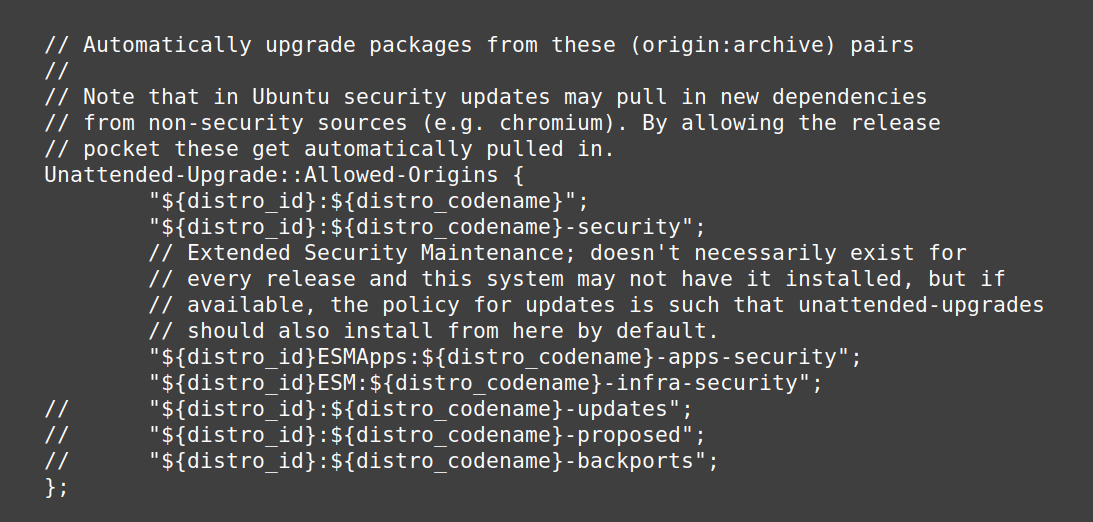
# 摘要
本文针对Ubuntu 16.04系统更新与维护进行了全面的概述,探讨了系统更新的基础理论、实践技巧以及在更新过程中可能遇到的常见问题。文章详细介绍了安全加固与维护的策略,包括安全更新与补丁管理、系统加固实践技巧及监控与日志分析。在备份与灾难恢复方面,本文阐述了
潮流分析的艺术:PSD-BPA软件高级功能深度介绍

# 摘要
电力系统分析在保证电网安全稳定运行中起着至关重要的作用。本文首先介绍了潮流分析的基础知识以及PSD-BPA软件的概况。接着详细阐述了PSD-BPA的潮流计算功能,包括电力系统的基本模型、潮流计算的数学原理以及如何设置潮流计算参数。本文还深入探讨了PSD-BPA的高级功
嵌入式系统中的BMP应用挑战:格式适配与性能优化
# 摘要
本文综合探讨了BMP格式在嵌入式系统中的应用,以及如何优化相关图像处理与系统性能。文章首先概述了嵌入式系统与BMP格式的基本概念,并深入分析了BMP格式在嵌入式系统中的应用细节,包括结构解析、适配问题以及优化存储资源的策略。接着,本文着重介绍了BMP图像的处理方法,如压缩技术、渲染技术以及资源和性能优化措施。最后,通过具体应用案例和实践,展示了如何在嵌入式设备中有效利用BMP图像,并探讨了开发工具链的重要性。文章展望了高级图像处理技术和新兴格式的兼容性,以及未来嵌入式系统与人工智能结合的可能方向。
# 关键字
嵌入式系统;BMP格式;图像处理;性能优化;资源适配;人工智能
参考资
分析准确性提升之道:谢菲尔德工具箱参数优化攻略

# 摘要
本文介绍了谢菲尔德工具箱的基本概念及其在各种应用领域的重要性。文章首先阐述了参数优化的基础理论,包括定义、目标、方法论以及常见算法,并对确定性与随机性方法、单目标与多目标优化进行了讨论。接着,本文详细说明了谢菲尔德工具箱的安装与配置过程,包括环境选择、参数配置、优化流程设置以及调试与问题排查。此外,通过实战演练章节,文章分析了案例应用,并对参数调优的实验过程与结果评估给出了具体指
CC-LINK远程IO模块AJ65SBTB1现场应用指南:常见问题快速解决
# 摘要
CC-LINK远程IO模块作为一种工业通信技术,为自动化和控制系统提供了高效的数据交换和设备管理能力。本文首先概述了CC-LINK远程IO模块的基础知识,接着详细介绍了其安装与配置流程,包括硬件的物理连接和系统集成要求,以及软件的参数设置与优化。为应对潜在的故障问题,本文还提供了故障诊断与排除的方法,并探讨了故障解决的实践案例。在高级应用方面,文中讲述了如何进行编程与控制,以及如何实现系统扩展与集成。最后,本文强调了CC-LINK远程IO模块的维护与管理的重要性,并对未来技术发展趋势进行了展望。
# 关键字
CC-LINK远程IO模块;系统集成;故障诊断;性能优化;编程与控制;维护
PM813S内存管理优化技巧:提升系统性能的关键步骤,专家分享!
# 摘要
PM813S作为一款具有先进内存管理功能的系统,其内存管理机制对于系统性能和稳定性至关重要。本文首先概述了PM813S内存管理的基础架构,然后分析了内存分配与回收机制、内存碎片化问题以及物理与虚拟内存的概念。特别关注了多级页表机制以及内存优化实践技巧,如缓存优化和内存压缩技术的应用。通过性能评估指标和调优实践的探讨,本文还为系统监控和内存性能提
【光辐射测量教育】:IT专业人员的培训课程与教育指南

# 摘要
光辐射测量是现代科技中应用广泛的领域,涉及到基础理论、测量设备、技术应用、教育课程设计等多个方面。本文首先介绍了光辐射测量的基础知识,然后详细探讨了不同类型的光辐射测量设备及其工作原理和分类选择。接着,本文分析了光辐射测量技术及其在环境监测、农业和医疗等不同领域的应用实例。教育课程设计章节则着重于如何构建理论与实践相结合的教育内容,并提出了评估与反馈机制。最后,本文展望了光辐射测量教育的未来趋势,讨论了技术发展对教育内容和教
RTC4版本迭代秘籍:平滑升级与维护的最佳实践

# 摘要
本文重点讨论了RTC4版本迭代的平滑升级过程,包括理论基础、实践中的迭代与维护,以及维护与技术支持。文章首先概述了RTC4的版本迭代概览,然后详细分析了平滑升级的理论基础,包括架构与组件分析、升级策略与计划制定、技术要点。在实践章节中,本文探讨了版本控制与代码审查、单元测试
SSD1306在智能穿戴设备中的应用:设计与实现终极指南
# 摘要
SSD1306是一款广泛应用于智能穿戴设备的OLED显示屏,具有独特的技术参数和功能优势。本文首先介绍了SSD1306的技术概览及其在智能穿戴设备中的应用,然后深入探讨了其编程与控制技术,包括基本编程、动画与图形显示以及高级交互功能的实现。接着,本文着重分析了SSD1306在智能穿戴应用中的设计原则和能效管理策略,以及实际应用中的案例分析。最后,文章对SSD1306未来的发展方向进行了展望,包括新型显示技术的对比、市场分析以及持续开发的可能性。
# 关键字
SSD1306;OLED显示;智能穿戴;编程与控制;用户界面设计;能效管理;市场分析
参考资源链接:[SSD1306 OLE
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )