YOLOv10 Deployment and Optimization: From Model Deployment to Performance Tuning, Enhancing Model Efficiency
发布时间: 2024-09-13 20:36:31 阅读量: 10 订阅数: 11 
# Deployment and Optimization of YOLOv10: Enhancing Model Efficiency from Deployment to Performance Tuning
## 1. YOLOv10 Model Deployment
### 1.1 Model Download and Environment Setup
- Download the pretrained YOLOv10 model weights and configuration files.
- Configure necessary software environments, including Python, PyTorch, and CUDA.
- Install the official YOLOv10 library or third-party implementations.
### 1.2 Selection and Installation of Model Inference Engine
- Choose an appropriate inference engine such as TensorRT, ONNX Runtime, or OpenVINO.
- Install the inference engine and configure options compatible with the YOLOv10 model.
- Optimize the inference engine settings for the best performance.
## 2. YOLOv10 Model Optimization
### 2.1 Model Quantization and Pruning
#### 2.1.1 Principles and Methods of Model Quantization
Model quantization is a technique that converts floating-point models into fixed-point models, effectively reducing the size of the model and computational cost. The main methods for YOLOv10 model quantization include:
- **Integer Quantization:** Convert floating-point weights and activation values to integers to reduce storage and computational overhead.
- **Binarization:** Convert weights and activation values to binary values (0 or 1) to further reduce computational cost.
The quantization process typically involves the following steps:
1. **Training Quantization-Aware Models:** Use quantization-aware training algorithms during training to introduce quantization errors into the floating-point model.
2. **Calibration:** Calibrate the quantized model with a representative dataset to minimize quantization errors.
3. **Quantization:** Convert the floating-point model into a fixed-point model and adjust quantization parameters based on calibration results.
#### 2.1.2 Strategies and Practices of Model Pruning
Model pruning is a technique that removes redundant weights to reduce the size of the model and computational cost. The main strategies for YOLOv10 model pruning include:
- **Weight Pruning:** Remove weights that have a smaller impact on the model output, usually using regularization techniques or pruning algorithms.
- **Channel Pruning:** Remove channels that have a smaller impact on the model output, typically evaluated using activation maps of convolution layers.
The pruning process typically involves the following steps:
1. **Training Prunable Models:** Use prunable training algorithms during training to introduce redundant weights into the model.
2. **Evaluation:** Evaluate the model with a representative dataset and identify redundant weights.
3. **Pruning:** Remove redundant weights based on evaluation results and retrain the model to restore performance.
### 2.2 Algorithm Optimization and Hyperparameter Tuning
#### 2.2.1 Algorithm Optimization Techniques and Case Studies
Alg***mon techniques for YOLOv10 model optimization include:
- **Improving the Backbone Network:** Use deeper or wider backbone networks to enhance the model's feature extraction capabilities.
- **Enhancing Feature Fusion:** Use attention mechanisms or skip-layer connections to enhance feature fusion at different stages.
- **Optimizing the Loss Function:** Modify the loss function to more effectively handle class imbalance or small object detection issues.
#### 2.2.2 Principles and Methods of Hyperparameter Tuning
Hyperparamet***mon hyperparameters for YOLOv10 model optimization include:
- **Learning Rate:** Controls the learning step during model training.
- **Batch Size:** Specifies the number of samples in each training batch.
- **Regularization Parameters:** Control the degree of overfitting in the model.
Hyperparameter tuning typically involves the following steps:
1. **Determine Hyperparameter Ranges:** Based on experience or literature, determine the reasonable range of hyperparameter values.
2. **Grid Search or Random Search:** Use grid search or random search algo
 最低0.47元/天 解锁专栏
最低0.47元/天 解锁专栏 送3个月
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Python版本与性能优化:选择合适版本的5个关键因素

# 1. Python版本选择的重要性
Python是不断发展的编程语言,每个新版本都会带来改进和新特性。选择合适的Python版本至关重要,因为不同的项目对语言特性的需求差异较大,错误的版本选择可能会导致不必要的兼容性问题、性能瓶颈甚至项目失败。本章将深入探讨Python版本选择的重要性,为读者提供选择和评估Python版本的决策依据。
Python的版本更新速度和特性变化需要开发者们保持敏锐的洞
Parallelization Techniques for Matlab Autocorrelation Function: Enhancing Efficiency in Big Data Analysis
# 1. Introduction to Matlab Autocorrelation Function
The autocorrelation function is a vital analytical tool in time-domain signal processing, capable of measuring the similarity of a signal with itself at varying time lags. In Matlab, the autocorrelation function can be calculated using the `xcorr
Pandas中的文本数据处理:字符串操作与正则表达式的高级应用

# 1. Pandas文本数据处理概览
Pandas库不仅在数据清洗、数据处理领域享有盛誉,而且在文本数据处理方面也有着独特的优势。在本章中,我们将介绍Pandas处理文本数据的核心概念和基础应用。通过Pandas,我们可以轻松地对数据集中的文本进行各种形式的操作,比如提取信息、转换格式、数据清洗等。
我们会从基础的字
Python pip性能提升之道
# 1. Python pip工具概述
Python开发者几乎每天都会与pip打交道,它是Python包的安装和管理工具,使得安装第三方库变得像“pip install 包名”一样简单。本章将带你进入pip的世界,从其功能特性到安装方法,再到对常见问题的解答,我们一步步深入了解这一Python生态系统中不可或缺的工具。
首先,pip是一个全称“Pip Installs Pac
Image Processing and Computer Vision Techniques in Jupyter Notebook
# Image Processing and Computer Vision Techniques in Jupyter Notebook
## Chapter 1: Introduction to Jupyter Notebook
### 2.1 What is Jupyter Notebook
Jupyter Notebook is an interactive computing environment that supports code execution, text writing, and image display. Its main features include:
-
Python print语句装饰器魔法:代码复用与增强的终极指南

# 1. Python print语句基础
## 1.1 print函数的基本用法
Python中的`print`函数是最基本的输出工具,几乎所有程序员都曾频繁地使用它来查看变量值或调试程序。以下是一个简单的例子来说明`print`的基本用法:
```python
print("Hello, World!")
```
这个简单的语句会输出字符串到标准输出,即你的控制台或终端。`prin
【Python集合异常处理攻略】:集合在错误控制中的有效策略

# 1. Python集合的基础知识
Python集合是一种无序的、不重复的数据结构,提供了丰富的操作用于处理数据集合。集合(set)与列表(list)、元组(tuple)、字典(dict)一样,是Python中的内置数据类型之一。它擅长于去除重复元素并进行成员关系测试,是进行集合操作和数学集合运算的理想选择。
集合的基础操作包括创建集合、添加元素、删除元素、成员测试和集合之间的运
Python序列化与反序列化高级技巧:精通pickle模块用法

# 1. Python序列化与反序列化概述
在信息处理和数据交换日益频繁的今天,数据持久化成为了软件开发中不可或缺的一环。序列化(Serialization)和反序列化(Deserialization)是数据持久化的重要组成部分,它们能够将复杂的数据结构或对象状态转换为可存储或可传输的格式,以及还原成原始数据结构的过程。
序列化通常用于数据存储、
Python类私有化艺术:封装与访问控制的智慧
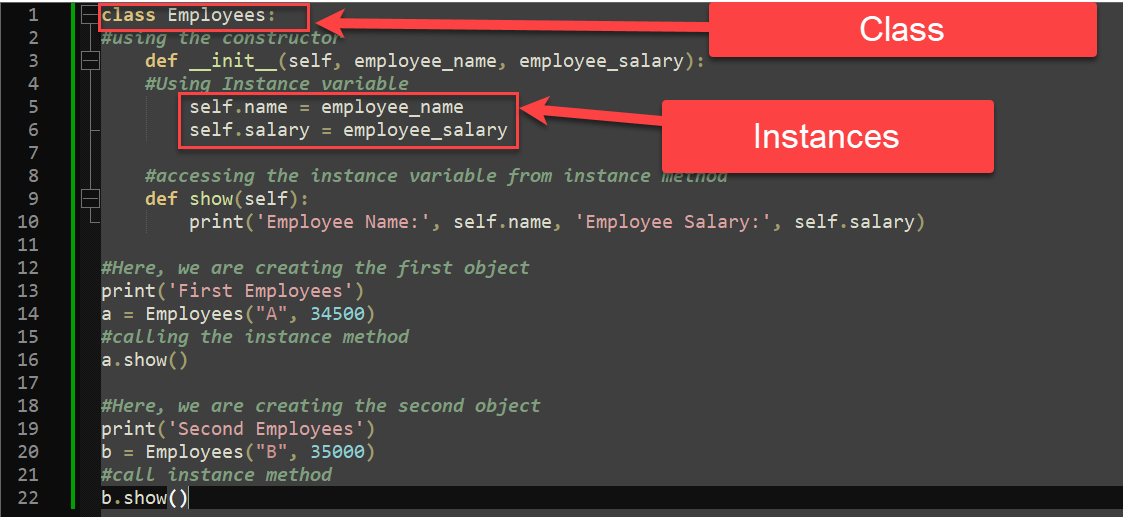
# 1. Python类私有化简介
Python作为一种面向对象的编程语言,其类的私有化特性对于代码的封装和保护起着至关重要的作用。在本章中,我们将简要介绍Python类私有化的概念,以及它在编程实践中的基本应用。
## 1.1 Python类私有化的概念
在Python中,私有化是指将类的属性和方法的可见性限制在类的内部,从而阻止外部对这些成员的直接访问。通过在成员名称前添加双下划线(__)来实现私
Python数组在科学计算中的高级技巧:专家分享

# 1. Python数组基础及其在科学计算中的角色
数据是科学研究和工程应用中的核心要素,而数组作为处理大量数据的主要工具,在Python科学计算中占据着举足轻重的地位。在本章中,我们将从Python基础出发,逐步介绍数组的概念、类型,以及在科学计算中扮演的重要角色。
## 1.1 Python数组的基本概念
数组是同类型元素的有序集合,相较于Python的列表,数组在内存中连续存储,允
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )