YOLOv10 Application Cases: Exploring Successful Practices Across Various Domains, Inspiring Innovative Ideas
发布时间: 2024-09-13 20:48:52 阅读量: 24 订阅数: 42 

Python Deep Learning: Exploring deep learning techniques, neural network
# 1. Overview of YOLOv10
YOLOv10 represents a significant breakthrough in the field of object detection, ***pared to previous versions of YOLO, YOLOv10 incorporates innovations and optimizations in network architecture, algorithmic principles, and training strategies.
YOLOv10 employs a new network architecture, which includes a backbone network and a detection head. The backbone network is responsible for extracting image features, while the detection head predicts the locations and categories of objects. This modular design allows YOLOv10 to achieve faster detection speeds while maintaining high accuracy.
Furthermore, YOLOv10 introduces new algorithmic principles such as Bag-of-Freebies (BoF) and Deep Supervision. BoF is a regularization technique that enhances the model's generalization ability. Deep Supervision is a training strategy that strengthens the model's feature extraction capabilities at different scales. These innovations significantly improve the object detection performance of YOLOv10.
# 2. Theoretical Foundations of YOLOv10
### 2.1 Evolution of Object Detection Algorithms
**The Evolution of Object Detection Algorithms**
The development of object detection algorithms has transitioned from traditional methods to deep learning approaches. Traditional methods mainly include sliding window detectors and region proposal-based detectors, which require predefined target regions and feature extraction, leading to large computational costs and low accuracy.
The emergence of deep learning methods has greatly improved the performance of object detection. Deep Convolutional Neural Networks (CNNs) can automatically extract image features and perform object detection through an end-to-end approach. The YOLO (You Only Look Once) algorithm is a milestone in the field of object detection, transforming the task into a regression problem and achieving real-time object detection.
**Advantages of YOLOv10**
YOLOv10 is the latest version of the YOLO algorithm, ***pared to previous YOLO versions, YOLOv10 boasts the following advantages:
***Faster detection speed:** YOLOv10 employs a lightweight network architecture and optimizes network layers and training strategies to achieve a detection speed of over 160 frames per second.
***Higher accuracy:** YOLOv10 utilizes a new object detection head and loss function, enhancing the model's ability to detect small and densely clustered objects.
***Better generalization ability:** YOLOv10 has been trained on a variety of datasets, demonstrating good generalization and the ability to accurately detect objects in different scenarios and conditions.
### 2.2 Network Architecture and Algorithmic Principles of YOLOv10
**YOLOv10 Network Architecture**
YOLOv10 adopts a lightweight CSPDarknet53 network as its backbone. The CSPDarknet53 network consists of multiple CSP modules and residual modules, possessing strong feature extraction capabilities.
**Algorithmic Principles of YOLOv10**
The algorithmic principles of YOLOv10 are illustrated in the following diagram:
[mermaid]
graph LR
subgraph YOLOv10 Algorithmic Principles
A[Input Image] --> B[CSPDarknet53 Backbone Network]
B --> C[Feature Extraction]
C --> D[Object Detection Head]
D --> E[Boundary Box Regression]
D --> F[Confidence Prediction]
D --> G[Category Prediction]
E --> H[Final Boundary Box]
F --> I[Final Confidence]
G --> J[Final Category]
end
[/mermaid]
1. **Input Image:** The algorithm first feeds the input image into the CSPDarknet53 backbone network for feature extraction.
2. **Feature Extraction:** The backbone network extracts features from the image and outputs feature maps.
3. **Object Detection Head:** The feature maps are sent to the object detection head, which consists of multiple convolutional layers and fully connected layers.
4. **Boundary Box Regression:** The object detection head outputs parameters for boundary box regression, used to predict the coordinates of the object's boundary box.
5. **Confidence Prediction:** The object detection head outputs confidence predictions, used to predict the probability of an object's presence.
6. **Category Prediction:** The object detection head outputs category predictions, used to predict the object's category.
7. **Final Boundary Box:** The boundary box regression parameters are combined with anchor boxes to obtain the final boundary box coordinates.
8. **Final Confidence:** The confidence prediction is combined with the probability of the object's presence to obtain the final confidence.
9. **Final Category:** The category prediction is combined with the object's category to obtain the final category.
**YOLOv10 Loss Function**
YOLOv10 employs a compound loss function consisting of boundary box regression loss, confidence loss, and category loss. The boundary box regression loss uses the GIOU loss, confidence loss employs binary cross-entropy loss, and category loss uses cross-entropy loss.
**Code Example**
```python
import torch
import torch.nn as nn
class YOLOv10(nn.Module):
def __init__(self):
super(YOLOv10, self).__init__()
# ...
def forward(self, x):
# ...
# Object Detection Head
detection_head = self.detection_head(x)
# Boundary Box Regression
bboxes = self.bbox_reg(detection_head)
# Confidence Prediction
confidences = self.conf_pred(detection_head)
# Category Prediction
classes = self.cls_pred(detection_head)
# ...
return bboxes, confidences, classes
```
**Logical Analysis**
This code implements the forward propagation process of the YOLOv10 algorithm. It first feeds the input image into the backbone network for feature extraction, then sends the feature maps to the object detection head for object detection. The object detection head outputs parameters for boundary box regression, confidence prediction, and category prediction. Finally, the boundary box regression parameters are combined with anchor boxes to obtain the final boundary box coordinates; the confidence prediction is combined with the probability of the object's presence to obtain the final confidence; the category prediction is combined with the object's category to obtain the final category.
# 3. Practical Applications of YOLOv10
### 3.1 Image Object Detection
Image object detection is an important application of YOLOv10, capable of recognizing and locating objects within images. YOLOv10 performs exceptionally well in image object detection, with its speed and accuracy widely recognized.
#### 3.1.1 Face Detection and Recognition
Face detection and recognition is an important task within image object detection, widely used in security surveillance, human-computer interaction, and other fields. YOLOv10 can efficiently and accurately detect faces and extract facial features to achieve face recognition.
```python
import cv2
import numpy as np
# Load YOLOv10 model
net = cv2.dnn.readNet("yolov10.weights", "yolov10.cfg")
# Load image
image = cv2.imread("image.jpg")
# Preprocess image
blob = cv2.dnn.blobFromImage(image, 1 / 255.0, (416, 416), (0, 0, 0), swapRB=True, crop=False)
# Set input
net.setInput(blob)
# Forward propagation
detections = net.forward()
# Parse detection results
for detection in detections[0, 0]:
confidence = detection[2]
if confidence > 0.5:
x1, y1, x2, y2 = detection[3:7] * np.array([image.shape[1], image.shape[0], image.shape[1], image.shape[0]])
cv2.rectangle(image, (int(x1), int(y1)), (int(x2), int(y2)), (0, 255, 0), 2)
# Display results
cv2.imshow("Face Detection", image)
cv2.waitKe
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
电子行业物流优化:EIA-481-D中文版的实际应用案例分析
# 摘要
EIA-481-D标准作为一种行业规范,对电子行业的物流流程产生深远影响,通过优化物料包装和标识追踪,有效减少物流错误,降低成本。该标准不仅提高了供应链的效率和透明度,也促进了质量管理的改进。本文介绍了EIA-481-D标准的内涵、物流优化原理及其在供应链中的作用,并通过多个实际应用案例,分析了不同规模企业实施标准的经验和挑战。此外,文章还探讨了电子行业物流优化的实践策略,包括流程优化、技术支持及持续改进方法,并对标准未来的发展趋势进行了展望。
# 关键字
EIA-481-D标准;物流优化;供应链管理;质量管理体系;实践策略;电子元件分销商
参考资源链接:[EIA-481-D中文
SAPSD定价逻辑优化:提升效率的10大策略与技巧

# 摘要
SAPSD定价逻辑是集成了基本定价原则、核心算法和市场适应性分析的复杂系统,旨在为企业提供高效的定价策略。本文首先概述了SAPSD定价逻辑及其理论基础,重点分析了其基本原则、核心算法及市场适应性。接着,探讨了通过数据驱动、实时定价调整和多维度策略组合等优化策略来改进定价逻辑,这些策略在实践中
绘图专家:ASPEN PLUS 10.0流程图技巧,让工艺流程一目了然
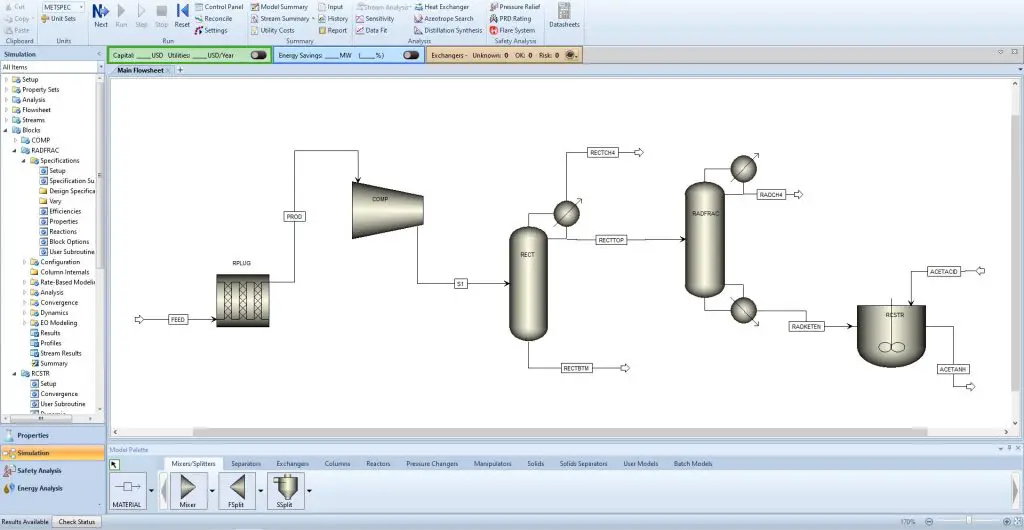
# 摘要
ASPEN PLUS 10.0作为一种强大的化工模拟软件,其流程图功能对于工程设计至关重要。本文全面介绍了ASPEN PLUS 10.0的基本操作、流程图的基本元素和高级技巧,以及其在工艺设计中的具体应用。通过详细阐述流程图的组件、符号、创建编辑方法以及数据流和连接线的管理,本文旨在帮助用户提升流程图的制作质量和效率。同时,深入探讨了自定义图形、模板的创建与应用、复杂流程的简化与可视化以及动态数据链接的重要
Amlogic S805多媒体应用大揭秘:视频音频处理效率提升手册

# 摘要
本文对Amlogic S805多媒体处理器进行了全面介绍和性能优化分析。首先概述了S805的基本特点,随后聚焦于视频和音频处理能力的提升。通过对视频编解码基础、播放性能优化以及高清视频解码器案例的研究,探讨了硬件加速技术和软件层面的优化策略。音频处理章节分析了音频编解码技术要点、播放录制的优化方法和音频增强技术的应用。最后,本文详细描述了多
提升记忆力的系统规划口诀:理论与实践的完美结合

# 摘要
记忆力的提升是认知心理学研究中的重要议题,影响因素多样,包括遗传、环境、生活习惯等。本文首先概述记忆力的理论基础,探讨不同理论模型如多重存储模型和工作记忆模型,并分析记忆力的影响因素。随后,文章详细介绍了科学的记忆力提升方法,包括记忆训练技巧、饮食与生活方式调整,以及认知训练工具和资源的使用。通过实践案例分析,文章进一步展示了记忆力提升的有效策
PLC程序开发优化指南:控制逻辑设计的最佳实践
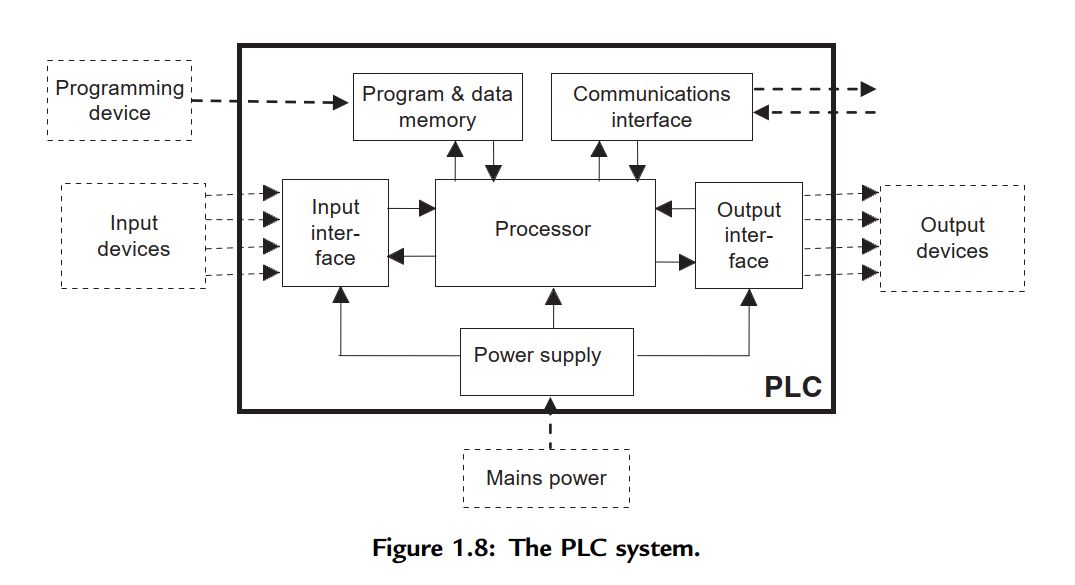
# 摘要
本文综合探讨了PLC(可编程逻辑控制器)程序开发的关键知识和实践技巧,旨在为工程技术人员提供系统的学习和参考。从基础理论、控制逻辑设计到编程实践,再到高级应用和案例研究,文章涵盖了PLC技术的多个重要方面。文中详细阐述了控制逻辑设计的理论基础、编程原则与优化方法,以及在实际应用中需要注意的调试与故障排除技巧。同时,还探讨了PLC在工业通讯和远程监控方面的应用,以及安全性与冗余设计的重要性。最后,文
华为LTE功率计算v1:功率控制算法的详细解读
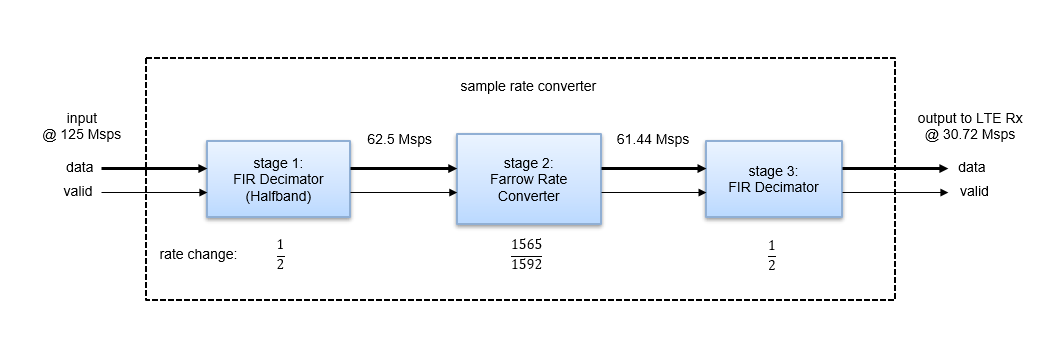
# 摘要
本文综述了华为LTE功率控制的技术细节和应用实践。首先概述了LTE功率控制的基本概念和理论基础,重点分析了功率控制在无线通信中的作用、主要类型及其关键参数。接着深入探讨了华为LTE功率控制算法,包括开环和闭环功率控制策略以及在特定场景下的优化策略。随后,文章详细描述了如何在实际应用中建立功率计算模型,并通过案例研究进行问题诊断与解决。最后,文章分析了当前华为LTE功率控
ADS变压器稳定性改进:揭秘模型分析与优化的核心方法

# 摘要
变压器作为电力系统中的关键设备,其稳定性对于整个电网的可靠运行至关重要。本文首先阐述了变压器稳定性的重要性,然后从理论基础、稳定性分析方法和优化策略三个方面进行了深入探讨。通过ADS软件工具的应用,我们分析了变压器模型的线性和非线性表达,并提出了基于ADS的稳定性仿真方法。此外,文章还探讨了硬件设计与软件算法上的优化策略,
LSM6DS3功耗管理秘籍:延长移动设备续航的策略
# 摘要
LSM6DS3传感器在现代移动设备中广泛使用,其功耗问题直接影响设备性能和续航能力。本文首先对LSM6DS3传感器进行概览,随后深入探讨其功耗管理原理,包括工作模式、理论基础及测试分析方法。接着,文章从软硬件层面分享了功耗管理的实践技巧,并通过案例分析展示了优化成效及挑战。在移动设备中的节能应用方面,本文讨论了数据采集与移动应用层的优化策略,以及跨平台节能技术。最后,文章展望了新技术如低功耗蓝牙和人工智能在功耗管理中的潜在影响,以及绿色能源技术与可持续发展的结合。本研究为移动设备的功耗管理提供了深入见解和实践指导,对未来节能技术的发展趋势进行了预测和建议。
# 关键字
LSM6DS
【多线程编程秘诀】:提升凌华IO卡处理能力的PCI-Dask.dll技巧

# 摘要
多线程编程是提高软件性能的重要技术,尤其在处理IO卡数据时,它能够显著提升数据吞吐和处理效率。本文从多线程基础和原理出发,深入探讨其在IO卡处理中的应用,结合PCI-Dask.dll技术,介绍了如何在多线程环境下进行编程实践以及提升IO卡性能的技巧。通过案例分析,本文分享了优化IO卡性能的成功实践
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )