Anchor Box Strategy in YOLOv10: The Foundation for Optimizing Object Detection, Enhancing Model Accuracy
发布时间: 2024-09-13 20:29:09 阅读量: 38 订阅数: 42 

Optimizing the F-measure for Threshold-free Salient Object Detection (ICCV 2019)
# The Anchoring Strategy in YOLOv10: The Cornerstone of Optimizing Object Detection, Enhancing Model Accuracy
# 1. An Overview of Object Detection
Object detection is a fundamental task in computer vision, aiming to identify and localize specific objects within images or videos. Unlike image classification, which only requires the recognition of objects, object detection also needs to determine their positions in the image.
Object detection algorithms generally consist of two steps: the first is to generate candidate regions, which are image areas that may contain targets; the second is to classify these candidate regions and predict the bounding boxes of the targets. The anchoring strategy is an essential component of object detection algorithms, as it provides guidance for the generation of candidate regions.
# 2. Fundamental Theories of the Anchoring Strategy
### 2.1 The Concept and Role of Anchor Boxes
In object detection tasks, an anchor box (or prior box) is a predefined rectangular box that represents potential positions and sizes where objects may appear. The anchoring strategy is a crucial component of object detection models, determining how the model maps features in the input image to target bounding boxes.
The main roles of anchor boxes include:
- **Providing Prior Knowledge:** Anchor boxes provide the model with prior knowledge about potential positions and sizes of objects. This helps the model learn features of target bounding boxes more effectively during training.
- **Reducing Search Space:** The anchoring strategy breaks the object detection task down into a series of classification and regression problems. By using anchor boxes, the model can limit the search space to the areas covered by the anchor boxes, reducing computational complexity.
- **Improving Localization Accuracy:** Anchor boxes can help the model locate objects more accurately. By regressing the anchor boxes, the model can predict the offset of the target bounding box relative to the anchor box, resulting in more precise target bounding boxes.
### 2.2 The Generation Mech***
***mon methods include:
- **Based on Image Size:** Divide the image into a grid and generate multiple anchor boxes in each grid cell, with the size and shape of the anchor boxes determined by the image size.
- **Based on Feature Map Size:** Divide the feature map into a grid and generate multiple anchor boxes in each grid cell, with the size and shape of the anchor boxes determined by the feature map size.
- **Based on Clustering:** Cluster the target bounding boxes in the training set and use the cluster centers as anchor boxes.
#### Code Example:
```python
import numpy as np
def generate_anchors(image_size, feature_map_size, anchor_scales, anchor_ratios):
"""
Generates anchor boxes based on image size.
Parameters:
image_size: The size of the image, (height, width)
feature_map_size: The size of the feature map, (height, width)
anchor_scales: Scales of the anchor boxes
anchor_ratios: Aspect ratios of the anchor boxes
Returns:
anchors: Generated anchor boxes, (num_anchors, 4)
"""
image_height, image_width = image_size
feature_height, feature_width = feature_map_size
anchor_scales = np.array(anchor_scales)
anchor_ratios = np.array(anchor_ratios)
num_anchors = len(anchor_scales) * len(anchor_ratios)
anchors = np.zeros((num_anchors, 4))
for i in range(len(anchor_scales)):
for j in range(len(anchor_ratios)):
anchor_height = anchor_scales[i] * image_height / feature_height
anchor_width = anchor_scales[i] * image_width / feature_width
anchor_center_x = (j + 0.5) * image_width / feature_width
anchor_center_y = (i + 0.5) * image_height / feature_height
anchors[i * len(anchor_ratios) + j, :] = [anchor_center_x, anchor_center_y, anchor_width, anchor_height]
return anchors
```
#### Code Logic Analysis:
This code generates anchor boxes based on the image size. It divides the image into a grid and generates multiple anchor boxes in each grid cell. The size and shape of the anchor boxes are determined by the image size and predefined anchor scales and aspect ratios.
#### Parameter Explanation:
- `image_size`: The size of the image, formatted as `(height, width)`.
- `feature_map_size`: The size of the feature map, formatted as `(height, width)`.
- `anchor_scales`: Anchor scales, representing the ratio of anchor boxes to image size.
- `anchor_ratios`: Anchor aspect ratios, representing the ratio of width to height of anchor boxes.
#

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
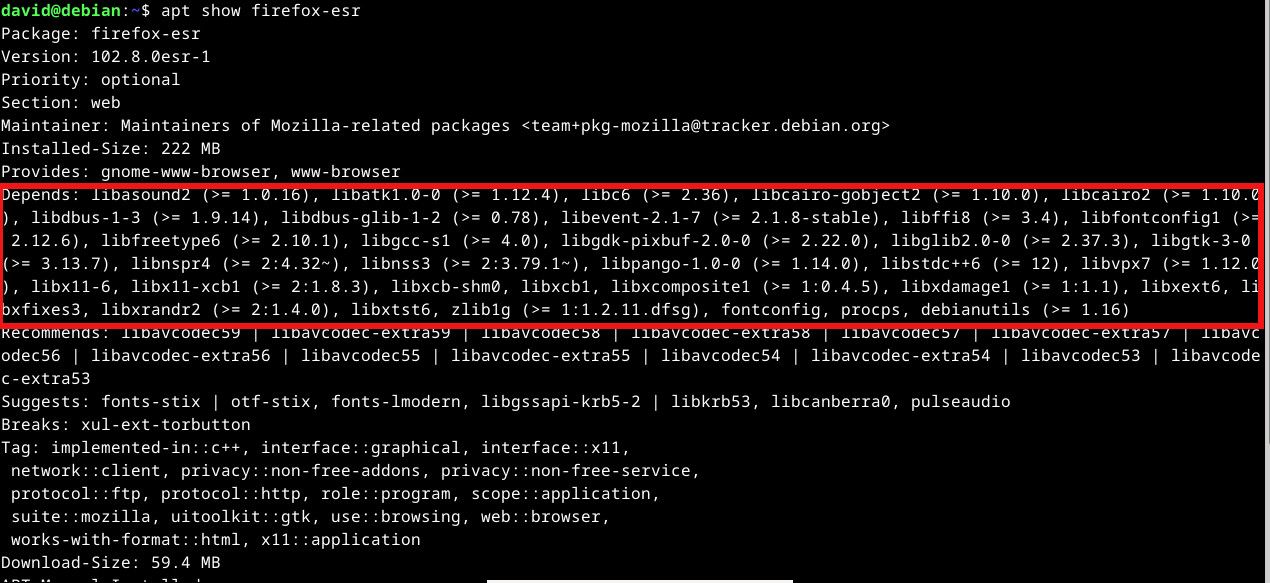
Linux软件包管理师:笔试题实战指南,精通安装与模块管理
# 摘要
随着开源软件的广泛使用,Linux软件包管理成为系统管理员和开发者必须掌握的重要技能。本文从概述Linux软件包管理的基本概念入手,详细介绍了几种主流Linux发行版中的包管理工具,包括APT、YUM/RPM和DNF,以及它们的安装、配置和使用方法。实战技巧章节深入讲解了如何搜索、安装、升级和卸载软件包,以及
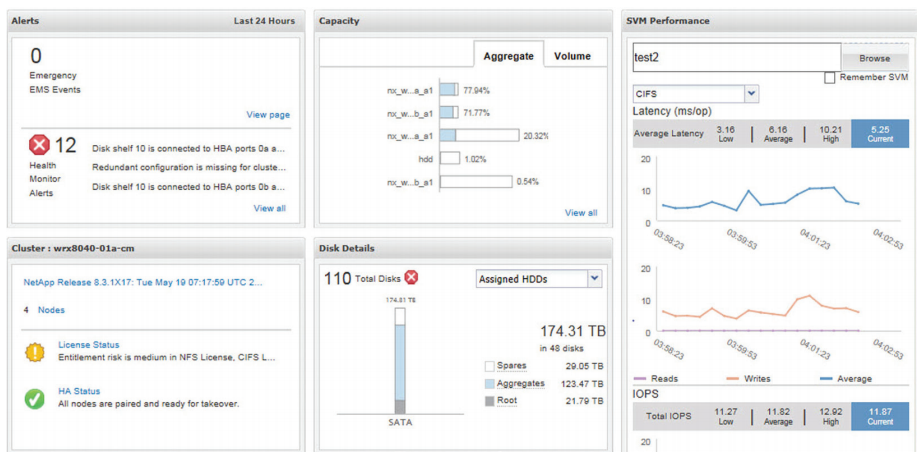
NetApp存储监控与性能调优:实战技巧提升存储效率
# 摘要
NetApp存储系统因其高性能和可靠性在企业级存储解决方案中广泛应用。本文系统地介绍了NetApp存储监控的基础知识、存储性能分析理论、性能调优实践、监控自动化与告警设置,以及通过案例研究与实战技巧的分享,提供了深入的监控和优化指南。通过对存储性能指标、监控工具和调优策略的详细探讨,本文旨在帮助读者理解如何更有效地管理和提升NetApp存储系统的性能,确保数据安全和业务连续性
Next.js数据策略:API与SSG融合的高效之道

# 摘要
Next.js是一个流行且功能强大的React框架,支持服务器端渲染(SSR)和静态站点生成(SSG)。本文详细介绍了Next.js的基础概念,包括SSG的工作原理及其优势,并探讨了如何高效构建静态页面,以及如何将API集成到Next.js项目中实现数据的动态交互和页面性能优化。此外,本文还展示了在复杂应用场景中处理数据的案例,并探讨了Next.js数据策略的
【通信系统中的CD4046应用】:90度移相电路的重要作用(行业洞察)
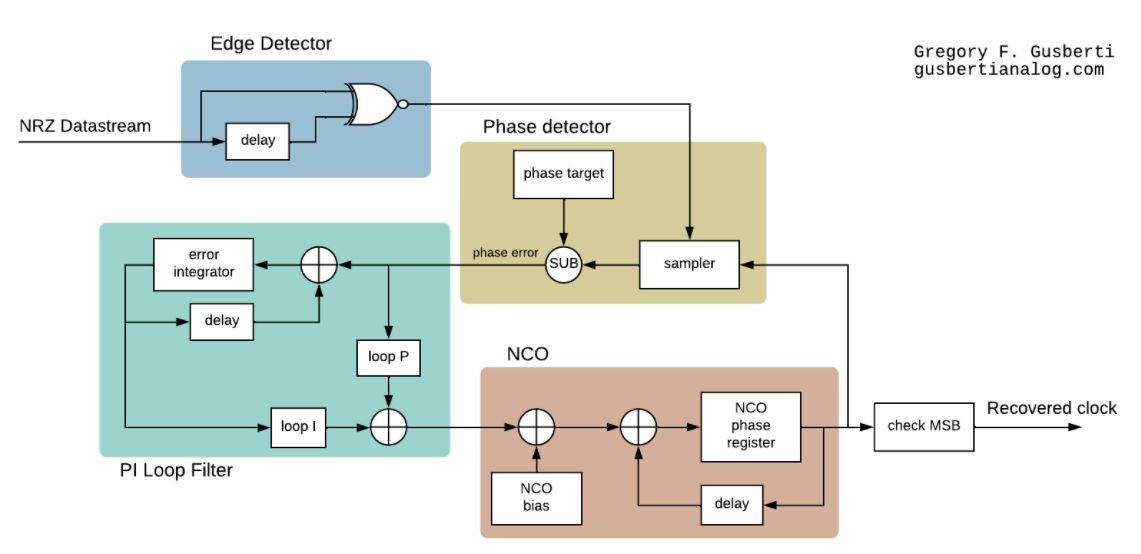
# 摘要
本文详细介绍了CD4046在通信系统中的应用,首先概述了CD4046的基本原理和功能,包括其工作原理、内部结构、主要参数和性能指标,以及振荡器和相位比较器的具体应用。随后,文章探讨了90度移相电路在通信系统中的关键作用,并针对CD4046在此类电路中的应用以及优化措施进行了深入分析。第三部分聚焦于CD4046在无线和数字通信中的应用实践,提供应用案例和遇到的问题及解决策略。最后,
下一代网络监控:全面适应802.3BS-2017标准的专业工具与技术
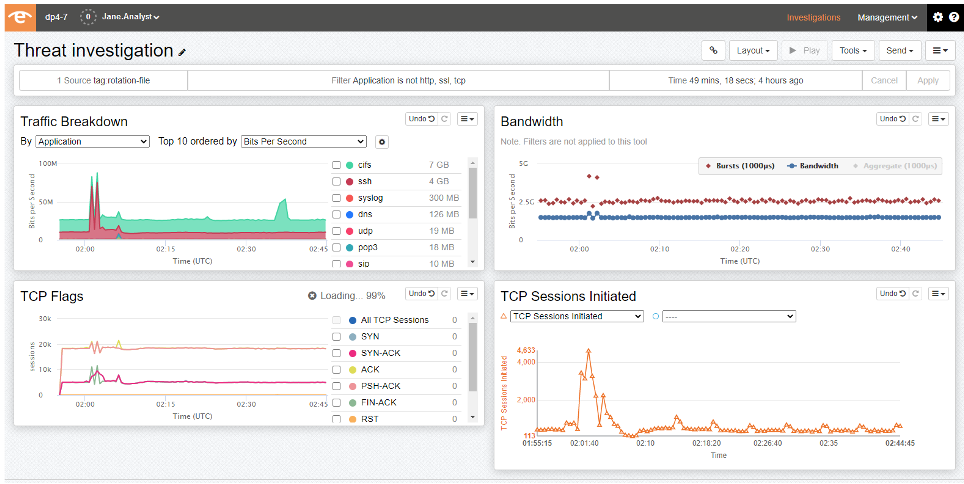
# 摘要
下一代网络监控技术是应对现代网络复杂性和高带宽需求的关键。本文首先介绍了网络监控的全局概览,随后深入探讨了802.3BS-2017标准的背景意义、关键特性及其对现有网络的影响。文中还详细阐述了网络监控工具的选型、部署以及配置优化,并分析了如何将这些工具应用于802.3BS-2017标准中,特别是在高速网络环境和安全性监控方面。最后
【Verilog硬件设计黄金法则】:inout端口的高效运用与调试

# 摘要
本文详细介绍了Verilog硬件设计中inout端口的使用和高级应用。首先,概述了inout端口的基础知识,包括其定义、特性及信号方向的理解。其次,探讨了inout端口在模块间的通信实现及端口绑定问题,以及高速信号处理和时序控制时的技术挑战与解决方案。文章还着重讨论了调试inout端口的工具与方法,并提供了常见问题的解决案例,包括信号冲突和设计优化。最后,通过实践案例分析,展现了inout端口在实际项目中的应用和故障排
【电子元件质量管理工具】:SPC和FMEA在检验中的应用实战指南

# 摘要
本文围绕电子元件质量管理,系统地介绍了统计过程控制(SPC)和故障模式与效应分析(FMEA)的理论与实践。第一章为基础理论,第二章和第三章分别深入探讨SPC和FMEA在质量管理中的应用,包括基本原理、实操技术、案例分析以及风险评估与改进措施。第四章综合分析了SPC与FMEA的整合策略和在质量控制中的综合案例研究,阐述了两种工具在电子元件检验中的协同作用。最后,第五章展望了质量管理工具的未来趋势,探讨了新
【PX4开发者福音】:ECL EKF2参数调整与性能调优实战

# 摘要
ECL EKF2算法是现代飞行控制系统中关键的技术之一,其性能直接关系到飞行器的定位精度和飞行安全。本文系统地介绍了EKF2参数调整与性能调优的基础知识,详细阐述了EKF2的工作原理、理论基础及其参数的理论意义。通过实践指南,提供了一系列参数调整工具与环境准备、常用参数解读与调整策略,并通过案例分析展示了参数调整在不同环境下的应用。文章还深入探讨了性能调优的实战技巧,包括性能监控、瓶颈
【黑屏应对策略】:全面梳理与运用系统指令

# 摘要
系统黑屏现象是计算机用户经常遇到的问题,它不仅影响用户体验,还可能导致数据丢失和工作延误。本文通过分析系统黑屏现象的成因与影响,探讨了故障诊断的基础方法,如关键标志检查、系统日志分析和硬件检测工具的使用,并识别了软件冲突、系统文件损坏以及硬件故障等常见黑屏原因。进一步,文章介绍了操作系统底层指令在预防和解决故障中的应用,并探讨了命令行工具处理故障的优势和实战案例。最后,本
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )