Comparative Analysis of YOLOv8 with Other Object Detection Algorithms
发布时间: 2024-09-15 07:14:23 阅读量: 49 订阅数: 23 
# Comparative Analysis of YOLOv8 Against Other Object Detection Algorithms
## 1. Overview of Object Detection Algorithms
Object detection is a crucial task in computer vision, aimed at identifying and locating targets within images or videos. Object detection algorithms are generally categorized into two types: ***o-stage algorithms, such as Faster R-CNN, first generate object proposal regions and then classify and regress each region. One-stage algorithms, like YOLOv8, predict the bounding boxes and classes directly from the input image or video.
## 2. Architecture and Principles of YOLOv8
### 2.1 Network Structure of YOLOv8
YOLOv8 employs a deep Convolutional Neural Network (CNN) as its backbone, consisting of the following components:
- **Input Layer:** Accepts input images, typically 416x416 pixels.
- **Convolutional Layers:** Extract image features using 3x3 and 1x1 convolutional kernels.
- **Pooling Layers:** Reduce the resolution of feature maps through max pooling or average pooling.
- **Activation Functions:** Non-linear activation functions such as Leaky ReLU or Mish.
- **Residual Connections:** Connect feature maps from lower layers with higher layers to enhance gradient flow.
- **Neck Network:** Fuses feature maps from different levels to obtain multi-scale feature representations.
- **Detection Head:** Predicts bounding boxes and class probabilities.
The network structure of YOLOv8 can be depicted as:
```mermaid
graph LR
subgraph Backbone
InputLayer --> ConvLayer1 --> PoolingLayer1 --> ConvLayer2 --> PoolingLayer2 --> ... --> ConvLayerN --> PoolingLayerN
end
subgraph Neck
Backbone --> NeckLayer1 --> NeckLayer2 --> ... --> NeckLayerM
end
subgraph DetectionHead
Neck --> DetectionLayer1 --> DetectionLayer2 --> ... --> DetectionLayerK
end
Backbone --> Neck
Neck --> DetectionHead
```
### 2.2 Training Process of YOLOv8
The training process of YOLOv8 mainly involves the following steps:
1. **Data Preprocessing:** Resize images to 416x416 pixels and apply data augmentation techniques such as random cropping, flipping, and color jittering.
2. **Model Initialization:** Initialize the network with pre-trained weights.
3. **Loss Function:** Use a composite loss function, including classification loss, bounding box loss, and confidence loss.
4. **Optimizer:** Utilize optimizers such as Adam or SGD.
5. **Training Loop:** Iteratively update the model weights to minimize the loss function.
### 2.3 Inference Process of YOLOv8
The inference process of YOLOv8 mainly involves the following steps:
1. **Input Image:** Receive the input image, typically 416x416 pixels.
2. **Forward Propagation:** Pass the image through the network, extract features, and predict bounding boxes and class probabilities.
3. **Non-Maximum Suppression (NMS):** Remove overlapping bounding boxes, keeping only the highest confidence bounding boxes.
4. **Post-processing:** Convert the predicted bounding boxes and class probabilities into final detection results.
Code block:
```python
import cv2
import numpy as np
# Load the model
net = cv2.dnn.readNet("yolov8.weights", "yolov8.cfg")
# Preprocess the image
image = cv2.imread("image.jpg")
image = cv2.resize(image, (416, 416))
# Forward propagation
blob = cv2.dnn.blobFromImage(image, 1 / 255.0, (416, 416), (0, 0, 0), swapRB=True, crop=False)
net.setInput(blob)
detections = net.forward()
# Post-processing
for detection in detections:
# Parse bounding boxes and class probabilities
confidence = detection[5]
if confidence > 0.5:
x, y, w, h = detection[0:4] * np.array([image.shape[1], image.shape[0], image.shape[1], image.shape[0]])
class_id = np.argmax(detection[5:])
# Draw the bounding box
cv2.rectangle(image, (int(x - w / 2), int(y - h / 2)), (int(x + w / 2), int(y + h / 2)), (0, 255, 0), 2)
```
Logical analysis:
- `cv2.dnn.readNet()`: Load the YOLOv8 model.
- `cv2.dnn.blobFromImage()`: Preprocess the image for model input.
- `net.setInput()`: Set the preprocessed image as model input.
- `net.forward()`: Perform forward propagation to predict bounding boxes and class probabilities.
- `np.argmax()`: Get the index of the maximum value in class probabilities, i.e., the class ID.
- `cv2.rectangle()`: Draw the detected bounding boxes on the image.
## ***parison of YOLOv8 with Other Object Detection Algorithms
### 3.1 Comparison with Faster R-CNN
#### 3.1.1 Comparison of Algorithm Architecture
Both YOLOv8 and Faster R-CNN are one-stage object detection algorithms, but their architectures differ. Faster R-CNN employs a two-stage detection process, including a Region Proposal Network (RPN) and a target classification network. The RPN generates candidate regions, and the target classification network classifies these regions and regresses bounding boxes.
In contrast, YOLOv8 adopts a single-stage detection process that directly maps input images to bounding boxes and class probabilities. It uses a single network to perform object detection without generating candidate regions.
| Feature | YOLOv8 | Faster R-CNN |
|---|---|---|
| Detection Process | One-stage | Two-stage |
| Candidate Region Generation | None | RPN |
| Network Structure | Single network | RPN + Classification network |
#### 3.1.2 Performance Comparison
In terms of performance, YOLOv8 and Faster R-CNN have their own strengths and weaknesses.
| Metric | YOLOv8 | Faster R-CNN |
|---|---|---|
| Detection Speed | Faster | Slower |
| Detection Accuracy | Slightly lower | Higher |
| Memory Usage | Smaller | Larger |
YOLOv8 has faster detection speed because it uses a one-stage detection process without the need for candidate region generation. Faster R-CNN has higher detection accuracy because its two-stage detection process allows for more refined classification and bounding box regression.
### 3.2 Comparison with SSD
#### 3.2.1 Comparison of Algorithm Architecture
Both YOLOv8 and SSD are one-stage object detection algorithms, but their architectures also differ. SSD uses multiple convolutional layers and anchor boxes to generate bounding boxes and class probabilities. It uses a single network to perform object detection without generating candidate regions.
In comparison, YOLOv8 uses a backbone network and a detection head to generate bounding boxes and class probabilities. The backbone network is responsible for extracting image features, while the detection head processes these features and generates detection results.
| Feature | YOLOv8 | SSD |
|---|---|---|
| Detection Process | One-stage | One-stage |
| Candidate Region Generation | None | Anchor boxes |
| Network Structure | Backbone network + Detection head | Multiple convolutional layers |
#### 3.2.2 Performance Comparison
In terms of performance, YOLOv8 and SSD also have their own advantages and disadvantages.
| Metric | YOLOv8 | SSD |
|---|---|---|
| Detection Speed | Faster | Slightly slower |
| Detection Accuracy | Slightly lower | Higher |
| Memory Usage | Smaller | Larger |
YOLOv8 has faster detection speed because it uses a backbone network and a detection head, which can process image features more efficiently. SSD has higher detection accuracy because it uses multiple convolutional layers and anchor boxes to generate more refined bounding boxes.
## 4. Practical Applications of YOLOv8
### 4.1 Image Object Detection
#### 4.1.1 Deployment and Usage of YOLOv8
**Deployment Steps:**
1. Install the YOLOv8 library.
2. Download a pre-trained model.
3. Load the model and initialize.
4. Preprocess the input image.
5. Perform object detection.
6. Post-process the detection results.
**Code Example:**
```python
import cv2
import numpy as np
import yolov8
# Load the model
model = yolov8.load_model("yolov8.pt")
# Load the image
image = cv2.imread("image.jpg")
# Preprocess the image
image = cv2.resize(image, (640, 640))
image = image / 255.0
# Perform object detection
results = model(image)
# Post-process the detection results
for result in results:
label = result["label"]
confidence = result["confidence"]
bbox = result["bbox"]
cv2.rectangle(image, (bbox[0], bbox[1]), (bbox[2], bbox[3]), (0, 255, 0), 2)
cv2.putText(image, label, (bbox[0], bbox[1] - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
# Display the detection results
cv2.imshow("Image", image)
cv2.waitKey(0)
```
#### 4.1.2 Actual Applications of Object Detection
***Security Surveillance:** Real-time detection and identification of suspicious individuals or objects to trigger alarms.
***Medical Image Analysis:** Assisting doctors in diagnosing diseases, such as detecting lesions in X-rays.
***Industrial Inspection:** Automatically detecting defective products on the production line to improve quality control efficiency.
***Autonomous Driving:** Real-time detection of pedestrians, vehicles, and other obstacles to ensure driving safety.
### 4.2 Video Object Detection
#### 4.2.1 Deployment and Usage of YOLOv8 in Videos
**Deployment Steps:**
1. Install the YOLOv8 library.
2. Download a pre-trained model.
3. Load the model and initialize.
4. Open video stream.
5. Perform object detection on each frame.
6. Post-process the detection results.
**Code Example:**
```python
import cv2
import numpy as np
import yolov8
# Load the model
model = yolov8.load_model("yolov8.pt")
# Open video stream
cap = cv2.VideoCapture("video.mp4")
# Perform object detection on each frame
while True:
ret, frame = cap.read()
if not ret:
break
# Preprocess the image
frame = cv2.resize(frame, (640, 640))
frame = frame / 255.0
# Perform object detection
results = model(frame)
# Post-process the detection results
for result in results:
label = result["label"]
confidence = result["confidence"]
bbox = result["bbox"]
cv2.rectangle(frame, (bbox[0], bbox[1]), (bbox[2], bbox[3]), (0, 255, 0), 2)
cv2.putText(frame, label, (bbox[0], bbox[1] - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
# Display the detection results
cv2.imshow("Frame", frame)
if cv2.waitKey(1) & 0xFF == ord("q"):
break
# Release the video stream
cap.release()
cv2.destroyAllWindows()
```
#### 4.2.2 Actual Applications of Video Object Detection
***Video Surveillance:** Real-time detection and identification of suspicious individuals or objects in videos to trigger alarms.
***Motion Analysis:** Analyzing the movements of athletes to provide training feedback and suggestions for improvement.
***Traffic Management:** Detecting and counting vehicles on the road to optimize traffic flow.
***Wildlife Monitoring:** Monitoring the activities and population distribution of wildlife for conservation and research purposes.
## 5. Optimization and Improvements of YOLOv8
### 5.1 Model Optimization
#### 5.1.1 Model Pruning
**Principle:**
Model pruning is a model optimization technique that reduces the model size and computational cost by removing unimportant neurons or connections.
**Specific Operations:**
- **Network Structure Pruning:** Remove unimportant layers or modules.
- **Weight Pruning:** Remove unimportant weights, such as weights with smaller absolute values.
**Code Example:**
```python
import torch
from torch.nn.utils import prune
# Define the model
model = torch.nn.Sequential(
torch.nn.Linear(100, 50),
torch.nn.ReLU(),
torch.nn.Linear(50, 10)
)
# Prune network structure
prune.random_unstructured(model, amount=0.2)
# Prune weights
prune.l1_unstructured(model, amount=0.2)
```
**Logical Analysis:**
- `prune.random_unstructured` function randomly removes 20% of the network structure.
- `prune.l1_unstructured` function removes 20% of the weights based on the L1 norm.
#### 5.1.2 Quantization
**Principle:**
Quantization is a model optimization technique that converts floating-point weights and activation values into low-precision data types, such as int8 or int16.
**Specific Operations:**
- **Weight Quantization:** Convert floating-point weights into low-precision data types.
- **Activation Quantization:** Convert floating-point activation values into low-precision data types.
**Code Example:**
```python
import torch
from torch.quantization import QuantStub, DeQuantStub
# Define the model
model = torch.nn.Sequential(
QuantStub(),
torch.nn.Linear(100, 50),
DeQuantStub(),
torch.nn.ReLU(),
QuantStub(),
torch.nn.Linear(50, 10),
DeQuantStub()
)
# Quantize the model
torch.quantization.quantize_dynamic(model, {torch.nn.Linear}, dtype=torch.qint8)
```
**Logical Analysis:**
- `QuantStub` and `DeQuantStub` modules are used to mark quantization and dequantization positions.
- `torch.quantization.quantize_dynamic` function dynamically quantizes the model to int8.
### 5.2 Algorithm Improvements
#### 5.2.1 Improvement of Loss Function
**Principle:**
The loss function is used to measure the difference between the model's predictions and the true labels. Improving the loss function can enhance the model's performance.
**Specific Operations:**
- **Focal Loss:** A loss function designed for class imbalance issues.
- **IoU Loss:** A loss function that measures the overlap between predicted boxes and ground truth boxes.
**Code Example:**
```python
import torch
from torch.nn import BCEWithLogitsLoss, MSELoss
# Define Focal Loss
focal_loss = BCEWithLogitsLoss(reduction='none')
# Define IoU Loss
iou_loss = MSELoss(reduction='none')
```
**Logical Analysis:**
- `BCEWithLogitsLoss` function is used to calculate binary cross-entropy loss.
- `MSELoss` function is used to calculate mean squared error loss.
#### 5.2.2 Improvement of Data Augmentation Strategy
**Principle:**
Data augmentation can increase the diversity of training data and improve the generalization ability of the model.
**Specific Operations:**
- **Random Cropping:** Randomly crop out regions of different sizes and aspect ratios from the image.
- **Random Rotation:** Randomly rotate the image by a certain angle.
- **Random Flipping:** Randomly flip the image horizontally or vertically.
**Code Example:**
```python
import torchvision.transforms as transforms
# Define data augmentation strategies
transform = ***pose([
transforms.RandomCrop(224),
transforms.RandomRotation(15),
transforms.RandomHorizontalFlip()
])
```
**Logical Analysis:**
- `transforms.RandomCrop` function randomly crops images.
- `transforms.RandomRotation` function randomly rotates images.
- `transforms.RandomHorizontalFlip` function randomly flips images horizontally.
# Future Development Directions of YOLOv8
As a leading-edge algorithm in the field of object detection, the future development directions of YOLOv8 mainly focus on the following aspects:
- **Model Lightening:** With the popularity of edge devices and mobile devices, the demand for lightweight object detection models continues to grow. The future development of YOLOv8 will focus on further optimizing the model structure, reducing the amount of computation and memory usage, allowing it to be deployed on devices with limited resources.
- **Accuracy Enhancement:** Although YOLOv8 has made significant progress in accuracy, there is still room for improvement. Future research will explore new network architectures, feature extraction methods, and loss functions to further enhance the model's detection accuracy.
- **Generalization Ability Enhancement:** The generalization ability of YOLOv8 across different scenarios and datasets still needs improvement. Future research will focus on the robustness of the model, enabling it to adapt to various environments and target types, enhancing its applicability in practical applications.
- **Real-time Optimization:** For real-time object detection applications, inference speed is critical. The future development of YOLOv8 will explore technologies such as parallel computing, model compression, and hardware optimization to further improve inference efficiency and meet real-time requirements.
- **Multi-task Fusion:** Object detection algorithms are highly synergistic with other computer vision tasks, such as image segmentation, pose estimation, and action recognition. The future development of YOLOv8 will explore multi-task fusion technologies, enabling the model to perform multiple tasks simultaneously, enhancing the practicality and efficiency of the model.
## 6.2 Future Trends of Object Detection Algorithms
In addition to the specific development directions of YOLOv8, the overall future trends of object detection algorithms are also worth noting:
- **End-to-end Learning:** Traditional object detection algorithms are typically divided into target proposal and classification stages. Future research will explore end-to-end learning methods, merging these two stages into a unified network, simplifying the model structure, and improving inference efficiency.
- **Self-supervised Learning:** Self-supervised learning techniques utilize unlabeled data for model training, effectively reducing dependence on annotated data. Future research will explore applying self-supervised learning to object detection algorithms to enhance the model's generalization ability and robustness.
- **Interpretability Enhancement:** The decision-making process of object detection algorithms is often black-boxed, making it difficult to understand. Future research will be dedicated to improving the model's interpretability, providing reasonable explanations for detection results and increasing user trust in the model.
- **Cross-modal Fusion:** Object detection algorithms typically rely on single-modal data, such as images or videos. Future research will explore cross-modal fusion technologies, combining different modal data to enhance the model's perceptual and understanding capabilities.
- **Application Scenario Expansion:** Object detection algorithms are widely applied in fields such as security surveillance, autonomous driving, and medical imaging. Future research will explore applying object detection technology to more emerging fields, such as industrial automation, environmental monitoring, and smart city construction.

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
ABB机器人SetGo指令脚本编写:掌握自定义功能的秘诀

# 摘要
本文详细介绍了ABB机器人及其SetGo指令集,强调了SetGo指令在机器人编程中的重要性及其脚本编写的基本理论和实践。从SetGo脚本的结构分析到实际生产线的应用,以及故障诊断与远程监控案例,本文深入探讨了SetGo脚本的实现、高级功能开发以及性能优化
PS2250量产兼容性解决方案:设备无缝对接,效率升级

# 摘要
PS2250设备作为特定技术产品,在量产过程中面临诸多兼容性挑战和效率优化的需求。本文首先介绍了PS2250设备的背景及量产需求,随后深入探讨了兼容性问题的分类、理论基础和提升策略。重点分析了设备驱动的适配更新、跨平台兼容性解决方案以及诊断与问题解决的方法。此外,文章还
计算几何:3D建模与渲染的数学工具,专业级应用教程

# 摘要
计算几何和3D建模是现代计算机图形学和视觉媒体领域的核心组成部分,涉及到从基础的数学原理到高级的渲染技术和工具实践。本文从计算几何的基础知识出发,深入
【Wireshark与Python结合】:自动化网络数据包处理,效率飞跃!
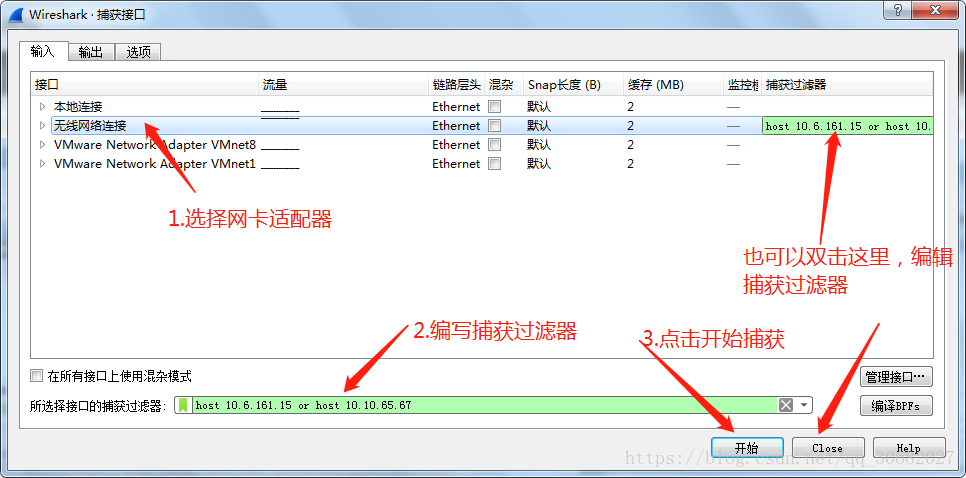
# 摘要
本文旨在探讨Wireshark与Python结合在网络安全和网络分析中的应用。首先介绍了网络数据包分析的基础知识,包括Wireshark的使用方法和网络数据包的结构解析。接着,转
OPPO手机工程模式:硬件状态监测与故障预测的高效方法

# 摘要
本论文全面介绍了OPPO手机工程模式的综合应用,从硬件监测原理到故障预测技术,再到工程模式在硬件维护中的优势,最后探讨了故障解决与预防策略。本研究详细阐述了工程模式在快速定位故障、提升维修效率、用户自检以及故障预防等方面的应用价值。通过对硬件监测技术的深入分析、故障预测机制的工作原理以及工程模式下的故障诊断与修复方法的探索,本文旨在为
NPOI高级定制:实现复杂单元格合并与分组功能的三大绝招
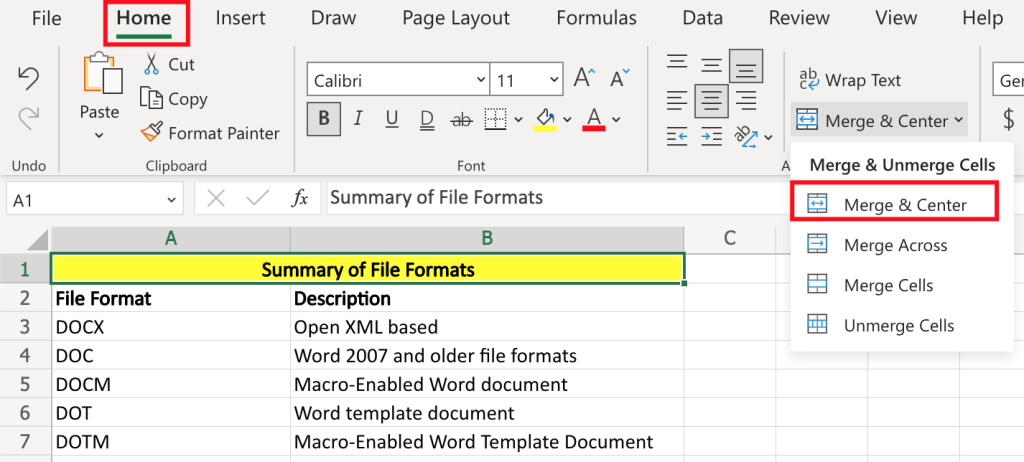
# 摘要
本文详细介绍了NPOI库在处理Excel文件时的各种操作技巧,包括安装配置、基础单元格操作、样式定制、数据类型与格式化、复杂单元格合并、分组功能实现以及高级定制案例分析。通过具体的案例分析,本文旨在为开发者提供一套全面的NPOI使用技巧和最佳实践,帮助他们在企业级应用中优化编程效率,提
【矩阵排序技巧】:Origin转置后矩阵排序的有效方法

# 摘要
矩阵排序是数据分析和工程计算中的重要技术,本文对矩阵排序技巧进行了全面的概述和探讨。首先介绍了矩阵排序的基础理论,包括排序算法的分类和性能比较,以及矩阵排序与常规数据排序的差异。接着,本文详细阐述了在Origin软件中矩阵的基础操作,包括矩阵的创建、导入、转置操作,以及转置后矩阵的结构分析。在实践中,本文进一步介绍了Origin中基于行和列的矩阵排序步骤和策略,以及转置后
电路理论解决实际问题:Electric Circuit第10版案例深度剖析
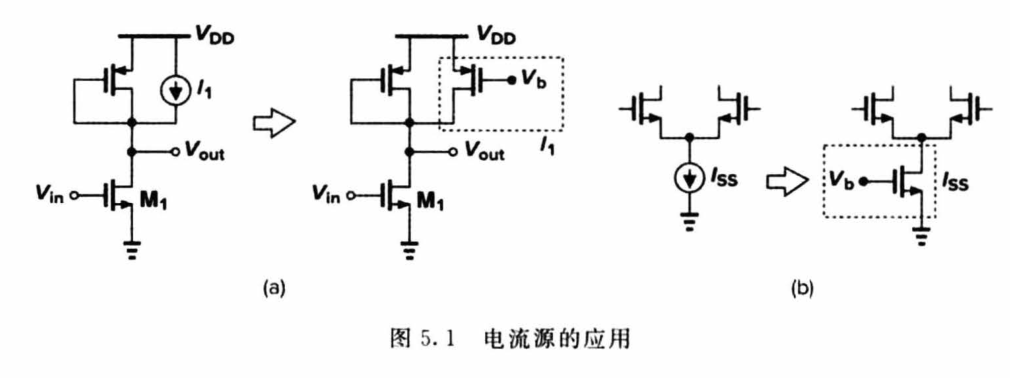
# 摘要
本论文深入回顾了电路理论基础知识,并构建了电路分析的理论框架,包括基尔霍夫定律、叠加原理和交流电路理论。通过电路仿真软件的实际应用章节,本文展示了如何利用这些工具分析复杂电路、进行故障诊断和优化设计。在电路设计案例深度剖析章节,本文通过模拟电路、数字电路及混合信号电路设计案例,提供了具体的电路设计经验。此外,本文还探讨了现代电路理论在高频电路设计、
SPI总线编程实战:从初始化到数据传输的全面指导
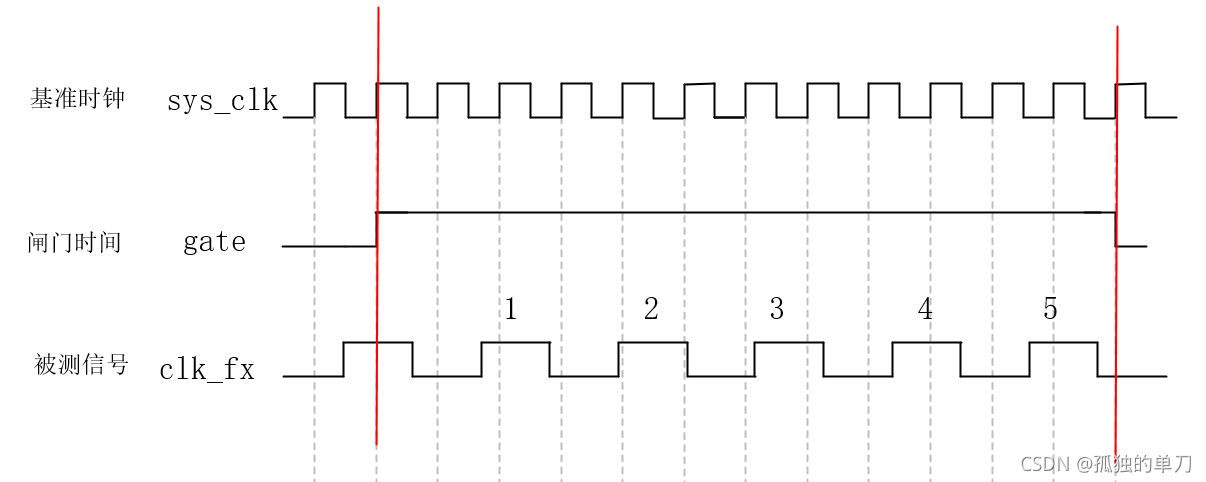
# 摘要
SPI总线技术作为高速串行通信的主流协议之一,在嵌入式系统和外设接口领域占有重要地位。本文首先概述了SPI总线的基本概念和特点,并与其他串行通信协议进行
跨学科应用:南京远驱控制器参数调整的机械与电子融合之道
# 摘要
远驱控制器作为一种创新的跨学科技术产品,其应用覆盖了机械系统和电子系统的基础原理与实践。本文从远驱控制器的机械和电子系统基础出发,详细探讨了其设计、集成、调整和优化,包括机械原理与耐久性、电子组件的集成与控制算法实现、以及系统的测试与性能评估。文章还阐述了机械与电子系统的融合技术,包括同步协调和融合系统的测试。案例研究部分提供了特定应用场景的分析、设计和现场调整的深入讨论。最后,本文对
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )