YOLOv8 Practical Case: Intelligent Robot Visual Navigation and Obstacle Avoidance
发布时间: 2024-09-15 07:52:42 阅读量: 32 订阅数: 23 
# Section 1: Overview and Principles of YOLOv8
YOLOv8 is the latest version of the You Only Look Once (YOLO) object detection algorithm, ***pared to previous versions of YOLO, YOLOv8 has seen significant improvements in accuracy and speed.
YOLOv8 employs a new network architecture known as Cross-Stage Partial Connections (CSP). The CSP architecture reduces the amount of computation required by introducing skip connections at different stages of the network while maintaining the accuracy of the model. Additionally, YOLOv8 utilizes the Path Aggregation Network (PAN) module, which enhances the model's feature extraction capabilities by fusing feature maps from different stages.
In terms of training, YOLOv8 adopts self-supervised learning techniques, meaning the model is trained without human annotations. This allows the model to learn from vast amounts of unlabeled data, thereby improving the model's generalization capabilities.
# Section 2: Intelligent Robot Vision Navigation
### 2.1 Theoretical Foundations of Robot Vision Navigation
#### 2.1.1 SLAM and Visual Odometry
**Simultaneous Localization and Mapping (SLAM)**: SLAM is a robotic technique used for building environmental maps and estimating the robot's position simultaneously. It is achieved by fusing data from sensors such as LiDAR, cameras.
**Visual Odometry**: Visual odometry is a form of SLAM technology that uses only camera data to estimate a robot's motion and position. It is implemented by tracking feature points in a sequence of images.
#### 2.1.2 Applications of Deep Learning in Vision Navigation
Deep learning models, such as YOLOv8, have been widely applied to robot vision navigation. They can perform real-time object detection, which is crucial for environmental perception and path planning.
### 2.2 YOLOv8 in Practice for Robot Vision Navigation
#### 2.2.1 Model Training and Deployment
**Model Training:**
- Gather an image dataset with labeled objects.
- Train the YOLOv8 model to detect specific categories (e.g., pedestrians, vehicles).
- Optimize model parameters to improve accuracy and speed.
**Model Deployment:**
- Deploy the trained model onto the robot platform.
- Optimize model inference time to meet real-time navigation requirements.
#### 2.2.2 Real-Time Object Detection and Navigation Decisions
**Real-Time Object Detection:**
- Use the YOLOv8 model to detect objects in the environment in real time.
- Extract information such as object location, category, and confidence.
**Navigation Decisions:**
- Based on detected objects, the robot makes navigation decisions.
- Avoid obstacles, follow paths, or navigate to specified locations.
#### 2.2.3 Obstacle Avoidance and Path Planning
**Obstacle Avoidance:**
- Use YOLOv8 to detect obstacles and estimate their positions.
- Generate obstacle avoidance paths based on this information.
**Path Planning:**
- Plan a safe path using detected objects and obstacles.
- Consider path length, obstacle distance, and navigation objectives.
### 2.2.4 Obstacle Avoidance Algorithm Optimization and Evaluation
**Algorithm Optimization:**
- Adjust algorithm parameters to improve obstacle avoidance efficiency.
- Consider robot dynamics and environmental complexity.
**Algorithm Evaluation:**
- Evaluate the performance of the obstacle avoidance algorithm using simulations or real-world scenarios.
- Measure success rates, path lengths, and navigation times.
### Code Example: YOLOv8 Real-Time Object Detection
```python
import cv2
import numpy as np
# Load YOLOv8 model
net = cv2.dnn.readNet("yolov8.weights", "yolov8.cfg")
# Read image
image = cv2.imread("image.jpg")
# Preprocess image
blob = cv2.dnn.blobFromImage(image, 1 / 255.0, (416, 416), (0, 0, 0), swapRB=True, crop=False)
# Set input
net.setInput(blob)
# Forward propagation
detections = net.forward()
# Parse detection results
for detection in detections[0, 0]:
confidence = detection[2]
if confidence > 0.5:
x, y, w, h = detection[3:7] * np.array([image.shape[1], image.shape[0], image.shape[1], image.shape[0]])
cv2.rectangle(image, (x - w / 2, y - h / 2), (x + w / 2, y + h / 2), (0, 255, 0), 2)
# Display detection results
cv2.imshow("Image", image)
cv2.waitKey(0)
```
**Code Logic Analysis:**
- Load the YOLOv8 model an

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
ABB机器人SetGo指令脚本编写:掌握自定义功能的秘诀

# 摘要
本文详细介绍了ABB机器人及其SetGo指令集,强调了SetGo指令在机器人编程中的重要性及其脚本编写的基本理论和实践。从SetGo脚本的结构分析到实际生产线的应用,以及故障诊断与远程监控案例,本文深入探讨了SetGo脚本的实现、高级功能开发以及性能优化
【Wireshark与Python结合】:自动化网络数据包处理,效率飞跃!
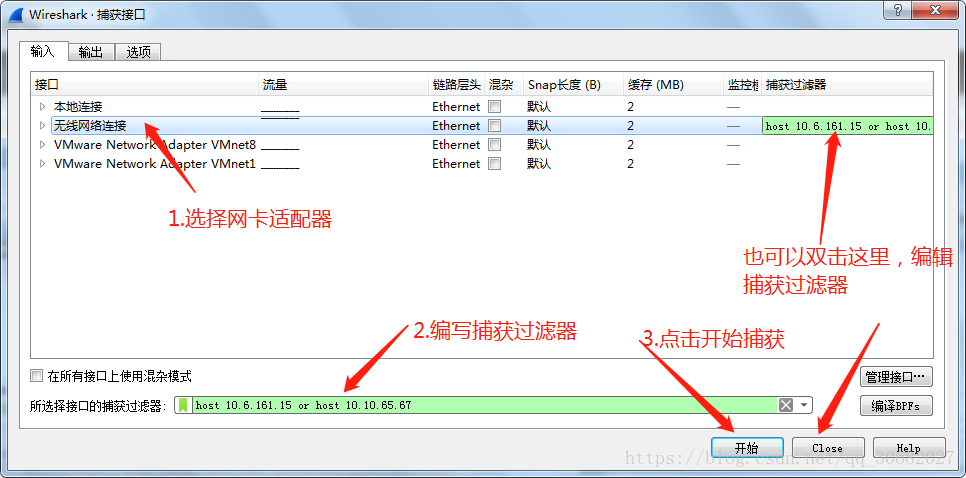
# 摘要
本文旨在探讨Wireshark与Python结合在网络安全和网络分析中的应用。首先介绍了网络数据包分析的基础知识,包括Wireshark的使用方法和网络数据包的结构解析。接着,转
OPPO手机工程模式:硬件状态监测与故障预测的高效方法

# 摘要
本论文全面介绍了OPPO手机工程模式的综合应用,从硬件监测原理到故障预测技术,再到工程模式在硬件维护中的优势,最后探讨了故障解决与预防策略。本研究详细阐述了工程模式在快速定位故障、提升维修效率、用户自检以及故障预防等方面的应用价值。通过对硬件监测技术的深入分析、故障预测机制的工作原理以及工程模式下的故障诊断与修复方法的探索,本文旨在为
NPOI高级定制:实现复杂单元格合并与分组功能的三大绝招
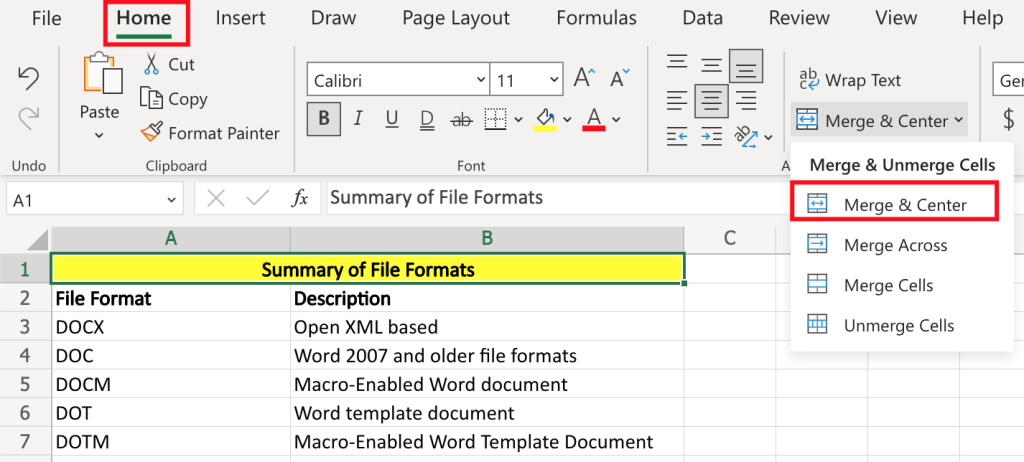
# 摘要
本文详细介绍了NPOI库在处理Excel文件时的各种操作技巧,包括安装配置、基础单元格操作、样式定制、数据类型与格式化、复杂单元格合并、分组功能实现以及高级定制案例分析。通过具体的案例分析,本文旨在为开发者提供一套全面的NPOI使用技巧和最佳实践,帮助他们在企业级应用中优化编程效率,提
【矩阵排序技巧】:Origin转置后矩阵排序的有效方法

# 摘要
矩阵排序是数据分析和工程计算中的重要技术,本文对矩阵排序技巧进行了全面的概述和探讨。首先介绍了矩阵排序的基础理论,包括排序算法的分类和性能比较,以及矩阵排序与常规数据排序的差异。接着,本文详细阐述了在Origin软件中矩阵的基础操作,包括矩阵的创建、导入、转置操作,以及转置后矩阵的结构分析。在实践中,本文进一步介绍了Origin中基于行和列的矩阵排序步骤和策略,以及转置后
SPI总线编程实战:从初始化到数据传输的全面指导
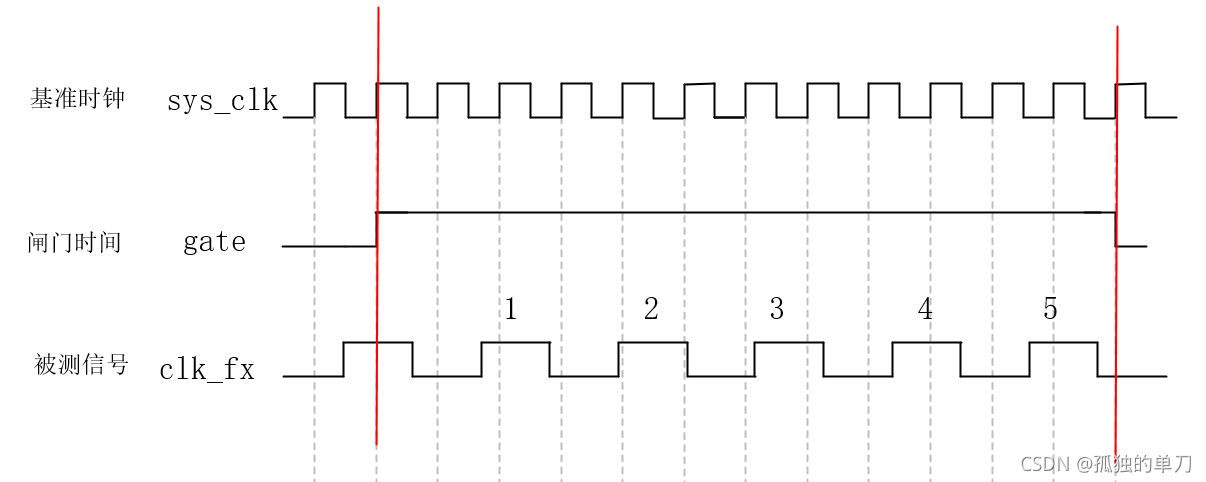
# 摘要
SPI总线技术作为高速串行通信的主流协议之一,在嵌入式系统和外设接口领域占有重要地位。本文首先概述了SPI总线的基本概念和特点,并与其他串行通信协议进行
电路分析难题突破术:Electric Circuit第10版高级技巧揭秘
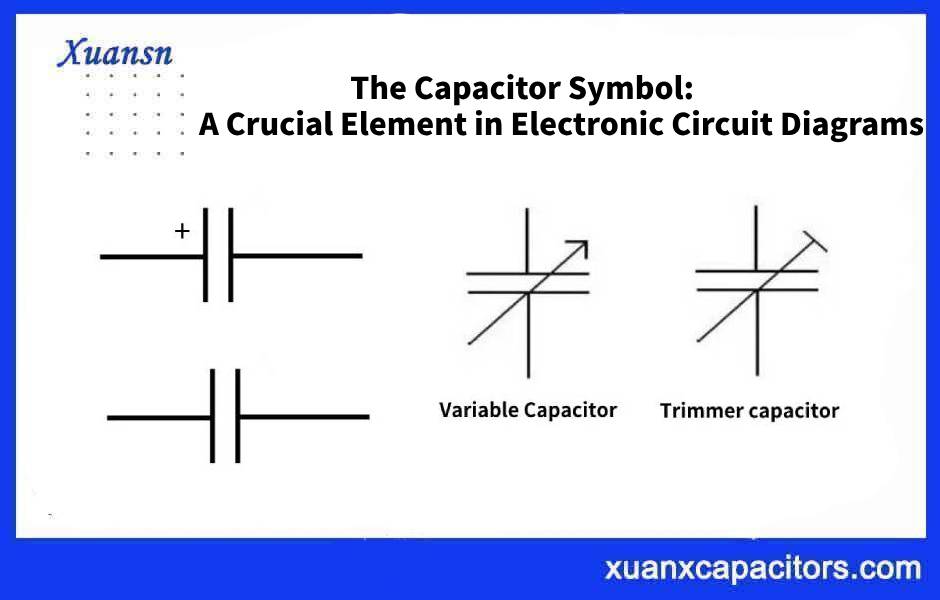
# 摘要
本文系统地介绍了电路理论的核心基础与分析方法,涵盖了复杂电路建模、时域与频域分析以及数字逻辑与模拟电路的高级技术。首先,我们讨论了理想与实际电路元件模型之间的差异,电路图的简化和等效转换技巧,以及线性和非线性电路的分析方法。接着,文章深入探讨了时域和频域分析的关键技巧,包括微分方程、拉普拉斯变换、傅里叶变换的应用以及相互转换的策略。此外,本文还详
ISO 9001:2015标准中文版详解:掌握企业成功实施的核心秘诀
# 摘要
ISO 9001:2015是国际上广泛认可的质量管理体系标准,它提供了组织实现持续改进和顾客满意的框架。本文首先概述了ISO 9001:2015标准的基本内容,并详细探讨了七个质量管理原则及其在实践中的应用策略。接着,本文对标准的关键条款进行了解析,阐明了组织环境、领导作用、资源管理等方面的具体要求。通过分析不同行业,包括制造业、服务业和IT行业中的应
计算几何:3D建模与渲染的数学工具,专业级应用教程

# 摘要
计算几何和3D建模是现代计算机图形学和视觉媒体领域的核心组成部分,涉及到从基础的数学原理到高级的渲染技术和工具实践。本文从计算几何的基础知识出发,深入
PS2250量产兼容性解决方案:设备无缝对接,效率升级

# 摘要
PS2250设备作为特定技术产品,在量产过程中面临诸多兼容性挑战和效率优化的需求。本文首先介绍了PS2250设备的背景及量产需求,随后深入探讨了兼容性问题的分类、理论基础和提升策略。重点分析了设备驱动的适配更新、跨平台兼容性解决方案以及诊断与问题解决的方法。此外,文章还
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )