YOLOv8 Practical Case: Crop Pest and Disease Detection in Smart Agriculture
发布时间: 2024-09-15 07:42:49 阅读量: 23 订阅数: 23 

tomato-crop-disease-detection-and-pest-management-server-master.zip
# 1. YOLOv8 Overview
YOLOv8 represents a groundbreaking advancement in the field of object detection, elevating both the accuracy and speed to new heights. YOLOv8 employs an innovative neural network architecture that combines the strengths of Convolutional Neural Networks (CNN) ***pared to previous versions of YOLO, YOLOv8 shows significant improvements in both accuracy and speed.
In YOLOv8, CNNs are utilized for image feature extraction, while Transformers handle sequence data. This combination enables YOLOv8 to capture both local and global features of images. Furthermore, YOLOv8 introduces new training strategies, such as self-supervised learning and knowledge distillation, further enhancing the model's performance.
# 2. Crop Pest and Disease Detection
### 2.1 Problem Definition and Data Preparation
#### 2.1.1 Common Types of Crop Pests and Diseases
There is a wide variety of crop pests and diseases, ***mon types include:
- **Diseases:** Caused by pathogens such as fungi, bacteria, and viruses, examples include powdery mildew, rust, and leaf spot.
- **Pests:** Caused by insects, mites, nematodes, etc., examples include aphids, spider mites, and corn borers.
- **Weeds:** Plants that compete with crops for nutrients, water, and sunlight, examples include barnyardgrass, foxtail, and crabgrass.
#### 2.1.2 Dataset Collection and Preprocessing
Training a crop pest and disease detection model requires a substantial amount of high-quality data. Dataset collection involves:
- **Image Acquisition:** Capturing crop images using cameras or drones at different growth stages and under various environmental conditions.
- **Annotation:** Labeling pests and diseases in the images, including location, type, and severity.
Data preprocessing includes:
- **Image Preprocessing:** Adjusting image size, format, and enhancing contrast.
- **Data Augmentation:** Techniques such as rotation, flipping, and cropping to increase dataset diversity.
- **Data Splitting:** Dividing the dataset into training, validation, and test sets.
### 2.2 Model Training and Evaluation
#### 2.2.1 YOLOv8 Model Structure and Training Parameters
YOLOv8 adopts the improved CSPDarknet53 backbone network, featuring:
- **CSP Structure:** Reduces computational load and improves feature extraction efficiency through cross-stage partial connections.
- **Mish Activation Function:** A non-monotonic activation function that enhances model convergence and robustness.
- **PAN Path Aggregation Network:** Fuses feature maps of different scales, enhancing the accuracy and robustness of object detection.
Training parameters include:
- **Batch Size:** The number of images in each training batch, affecting training speed and memory consumption.
- **Learning Rate:** The step size used by the optimizer to update model parameters, impacting model convergence speed and final performance.
- **Weight Decay:** Prevents overfitting by penalizing large weight values to regularize the model.
#### 2.2.2 Training Process and Evaluation Metrics
The model training is an iterative process, consisting of:
- **Forward Propagation:** Inputting images and predicting target locations and categories through the model.
- **Backward Propagation:** Calculating the loss function between predictions and true labels, and backpropagating errors to update model parameters.
Evaluation metrics include:
- **Mean Average Precision (mAP):** Measures the accuracy and recall of the model in detecting different categories of objects.
- **Frames Per Second (FPS):** Measures the real-time detection speed of the model.
- **Loss Function:** Measures the difference between model predictions and true labels, such as cross-entropy loss or IoU loss.
### 2.3 Model Deployment and Application
#### 2.3.1 Model Optimization and Deployment Methods
Model optimization can reduce model size and computational requirements, facilitating deployment. Optimization methods include:
- **Quantization:** Converting floating-point weights and activations to lower precision integers.
- **Pruning:** Removing unimportant network connections and weights.
- **Distillation:** Transferring knowledge from a large teacher model to a smaller student model.
Deployment methods include:
- **Local Deployment:** Deploying the model on edge devices or servers for real-time detection.
- **Cloud Deployment:** Deploying the model on cloud platforms for scalability and high performance.
#### 2.3.2 Real-time Detection and Result Presentation
Once deployed, the model can perform real-time detection:
- **Image Input:** Input the image to be detected.
- **Model Inference:** The model predicts target locations and categories.
- **Result Presentation:** Draws detection boxes and labels on the image.
Detection results can be presented in the following ways:
- **Visualization Interface:** Display detection results on Web or mobile applications.
- **API Interface:** Provides RESTful API interfaces for easy integration with other systems.
- **File Output:** Exports detection results as CSV or JSON files.
# 3.1 Convolutional Neural Networks (CNN)
#### 3.1.1 Basic Principles and Architecture of CNN
A Convolutional Neural Network (CNN) is a deep learning model designed specifically for processing grid-like data, such as images and videos. The core concept of CNNs is the use of convolutional operations to extract local features from the data.

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
PS2250量产兼容性解决方案:设备无缝对接,效率升级

# 摘要
PS2250设备作为特定技术产品,在量产过程中面临诸多兼容性挑战和效率优化的需求。本文首先介绍了PS2250设备的背景及量产需求,随后深入探讨了兼容性问题的分类、理论基础和提升策略。重点分析了设备驱动的适配更新、跨平台兼容性解决方案以及诊断与问题解决的方法。此外,文章还
【矩阵排序技巧】:Origin转置后矩阵排序的有效方法

# 摘要
矩阵排序是数据分析和工程计算中的重要技术,本文对矩阵排序技巧进行了全面的概述和探讨。首先介绍了矩阵排序的基础理论,包括排序算法的分类和性能比较,以及矩阵排序与常规数据排序的差异。接着,本文详细阐述了在Origin软件中矩阵的基础操作,包括矩阵的创建、导入、转置操作,以及转置后矩阵的结构分析。在实践中,本文进一步介绍了Origin中基于行和列的矩阵排序步骤和策略,以及转置后
跨学科应用:南京远驱控制器参数调整的机械与电子融合之道
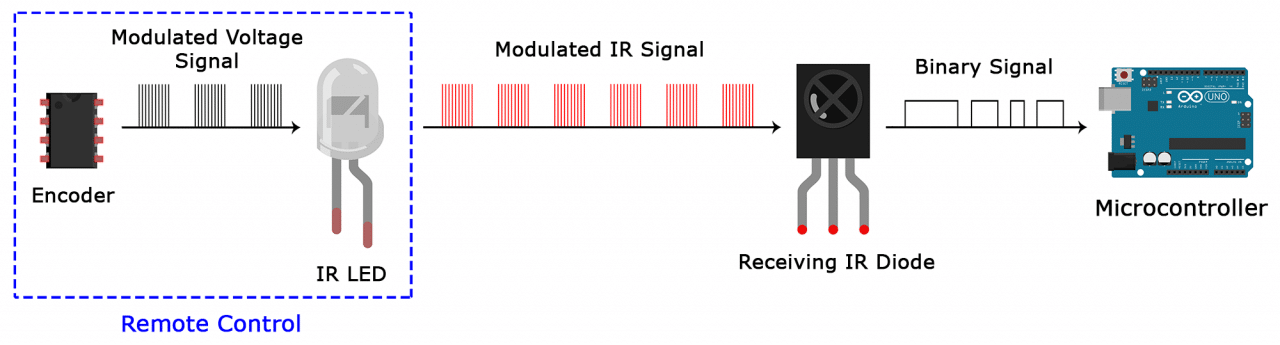
# 摘要
远驱控制器作为一种创新的跨学科技术产品,其应用覆盖了机械系统和电子系统的基础原理与实践。本文从远驱控制器的机械和电子系统基础出发,详细探讨了其设计、集成、调整和优化,包括机械原理与耐久性、电子组件的集成与控制算法实现、以及系统的测试与性能评估。文章还阐述了机械与电子系统的融合技术,包括同步协调和融合系统的测试。案例研究部分提供了特定应用场景的分析、设计和现场调整的深入讨论。最后,本文对
【Wireshark与Python结合】:自动化网络数据包处理,效率飞跃!
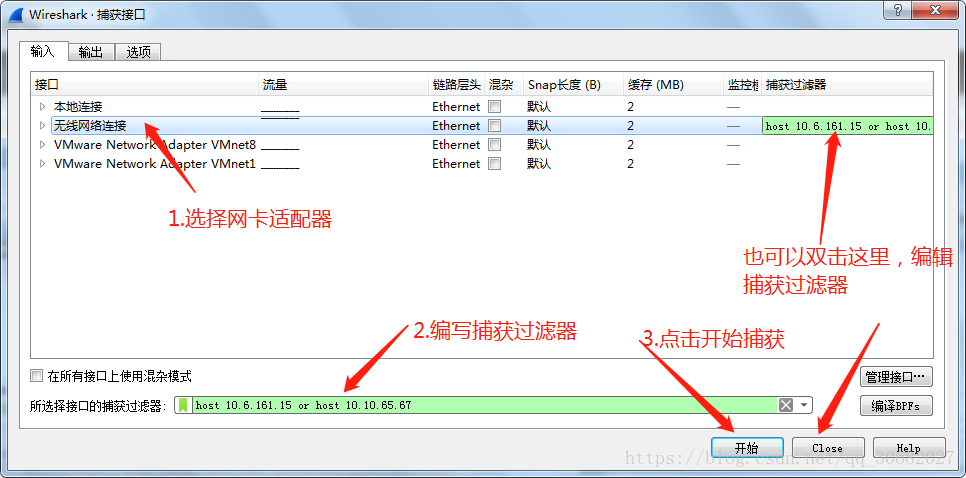
# 摘要
本文旨在探讨Wireshark与Python结合在网络安全和网络分析中的应用。首先介绍了网络数据包分析的基础知识,包括Wireshark的使用方法和网络数据包的结构解析。接着,转
模式识别:图像处理中的数学模型,专家级应用技巧
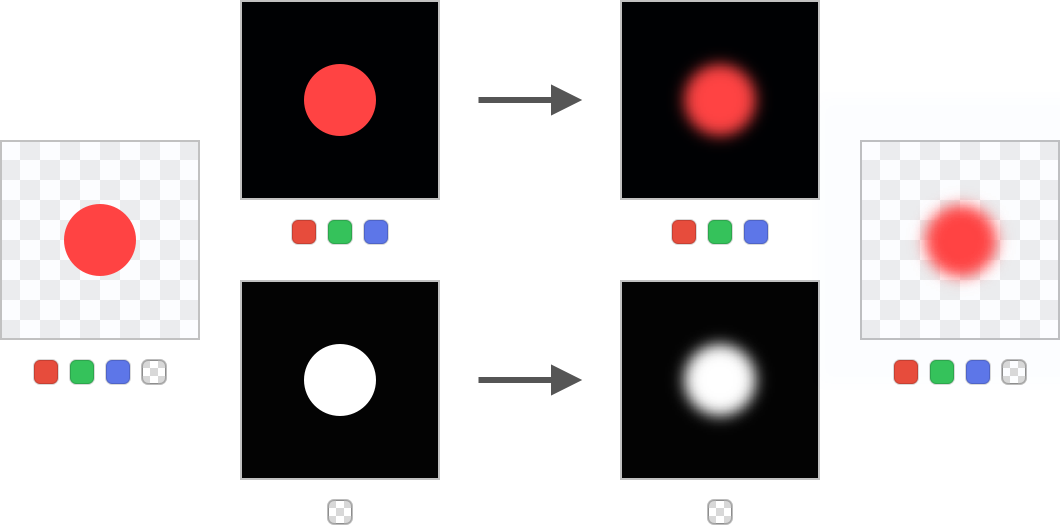
# 摘要
模式识别与图像处理是信息科学领域中关键技术,广泛应用于图像分析、特征提取、识别和分类任务。本文首先概述了模式识别和图像处理的基础知识,随后深入探讨了在图像处理中应用的数学模型,包括线性代数、概率论与统计模型、优化理论等,并且分析了高级图像处理算法如特征检测、图像分割与配准融合。接着,本文重点介绍了机器学习方法在模式识别中的应用,特别是在图像识别领域的监督学习、无监督学习和深度学习方法。最后,文章分享了模式识别中的专家级应
NPOI性能调优:内存使用优化和处理速度提升的四大策略

# 摘要
NPOI库作为.NET平台上的一个常用库,广泛应用于处理Excel文档,但其性能问题一直是开发者面临的挑战之一。本文首先介绍了NPOI库的基本概念及其性能问题,随后深入分析了内存使用的现状与挑战,探讨了内存消耗原因及内存泄漏的预防。
ABB机器人SetGo指令脚本编写:掌握自定义功能的秘诀

# 摘要
本文详细介绍了ABB机器人及其SetGo指令集,强调了SetGo指令在机器人编程中的重要性及其脚本编写的基本理论和实践。从SetGo脚本的结构分析到实际生产线的应用,以及故障诊断与远程监控案例,本文深入探讨了SetGo脚本的实现、高级功能开发以及性能优化
电子电路实验新手必看:Electric Circuit第10版实验技巧大公开
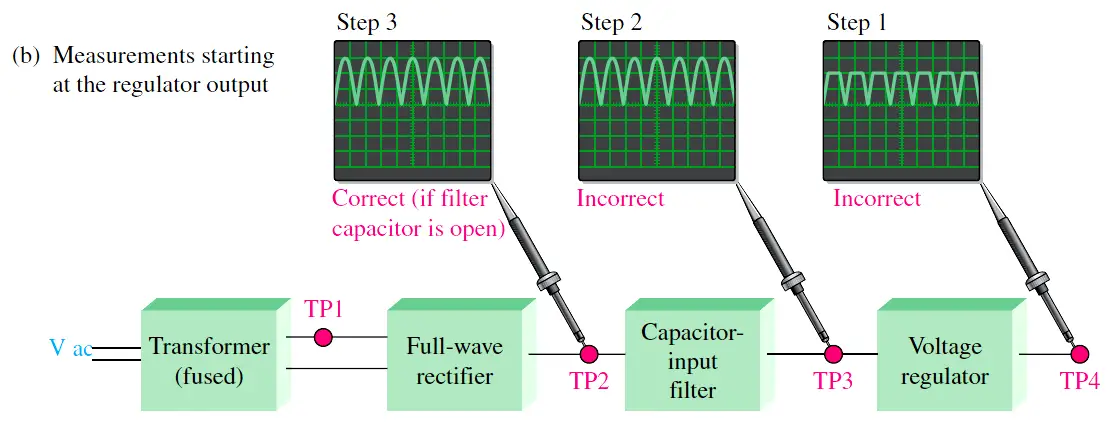
# 摘要
本文旨在深入理解Electric Circuit实验的教学目标和实践意义,涵盖了电路理论的系统知识解析、基础实验操作指南、进阶实验技巧以及实验案例分析与讨论。文章首先探讨了基本电路元件的特性和工作原理,随后介绍了电路定律和分析方法,包括多回路电路
OPPO手机工程模式:硬件状态监测与故障预测的高效方法

# 摘要
本论文全面介绍了OPPO手机工程模式的综合应用,从硬件监测原理到故障预测技术,再到工程模式在硬件维护中的优势,最后探讨了故障解决与预防策略。本研究详细阐述了工程模式在快速定位故障、提升维修效率、用户自检以及故障预防等方面的应用价值。通过对硬件监测技术的深入分析、故障预测机制的工作原理以及工程模式下的故障诊断与修复方法的探索,本文旨在为
SPI总线编程实战:从初始化到数据传输的全面指导
# 摘要
SPI总线技术作为高速串行通信的主流协议之一,在嵌入式系统和外设接口领域占有重要地位。本文首先概述了SPI总线的基本概念和特点,并与其他串行通信协议进行
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )