YOLOv8 Model Performance Evaluation and Metric Interpretation
发布时间: 2024-09-15 07:30:37 阅读量: 43 订阅数: 46 
# 1. Introduction to the YOLOv8 Model
The YOLOv8 is a single-stage object detection model developed by Ultralytics, renowned for its exceptional speed and accuracy. Built upon the YOLOv7 architecture, it has made significant improvements in terms of accuracy and efficiency. YOLOv8 employs the Bag of Freebies (BoF) strategy, introducing a series of training tricks and optimizations that enhance performance without altering the model architecture. These techniques include adaptive batch normalization, deep supervision, data augmentation, and mixed-precision training.
# 2. Theoretical Evaluation of the YOLOv8 Model
### 2.1 Accuracy, Recall, and F1 Score
**Accuracy**: Measures the proportion of the number of samples correctly predicted by the model.
**Recall**: Measures the proportion of all true positives predicted by the model.
**F1 Score**: An indicator that considers both accuracy and recall, calculated using the formula:
```
F1 = 2 * (Accuracy * Recall) / (Accuracy + Recall)
```
### 2.2 Intersection over Union (IoU) and Average Precision (AP)
**Intersection over Union (IoU)**: A metric that measures the degree of overlap between the predicted bounding box and the ground truth bounding box, calculated using the formula:
```
IoU = (Area of Intersection of Predicted and Ground Truth Boxes) / (Area of Union of Predicted and Ground Truth Boxes)
```
**Average Precision (AP)**: Measures the average accuracy of the model across different IoU thresholds.
### 2.3 Loss Functions and Optimization Algorithms
**Loss Function**: Measures the difference between the model'***mon loss functions include:
***Cross-Entropy Loss**: Used for classification tasks, calculated using the formula:
```
L_CE = - Σ (y_true * log(y_pred) + (1 - y_true) * log(1 - y_pred))
```
***Mean Squared Error Loss**: Used for regression tasks, calculated using the formula:
```
L_MSE = Σ (y_true - y_pred)^2
```
**Optimization Algorithm**: ***mon optimization algorithms include:
***Gradient Descent**: Updates parameters along the gradient direction, calculated using the formula:
```
w = w - α * ∇L(w)
```
***Momentum Gradient Descent**: Introduces a momentum term to accelerate convergence, calculated using the formula:
```
v = β * v + (1 - β) * ∇L(w)
w = w - α * v
```
# 3. Practical Evaluation of the YOLOv8 Model
### 3.1 Dataset Preparation and Preprocessing
**Dataset Preparation**
Evaluating the YOLOv8 model requires the use of high-quality, ***mon datasets include COCO, VOC, and ImageNet. These datasets provide a large number of annotated images and labels, covering various scenarios and object categories.
**Data Preprocessing**
Before training and evaluating the YOLOv8 model, data preprocessing is necessary, including:
- **Image Resizing**: Adjusting images to the required size for model input, typically 416x416 or 640x640.
- **Data Augmentation**: Applying data augmentation techniques such as random cropping, flipping, scaling, and color jittering to improve the model's generalization ability.
- **Label Conversion**: Converting image labels into a format recognizable by the model, usually bounding box coordinates and class labels.
### 3.2 Model Training and Evaluation
**Model Training**
The YOLOv8 model is trained using the PyTorch framework. The training process includes the following steps:
- **Data Loading**: Loading images and labels from the prep

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐
专栏目录
最低0.47元/天 解锁专栏
买1年送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【R语言Capet包集成挑战】:解决数据包兼容性问题与优化集成流程
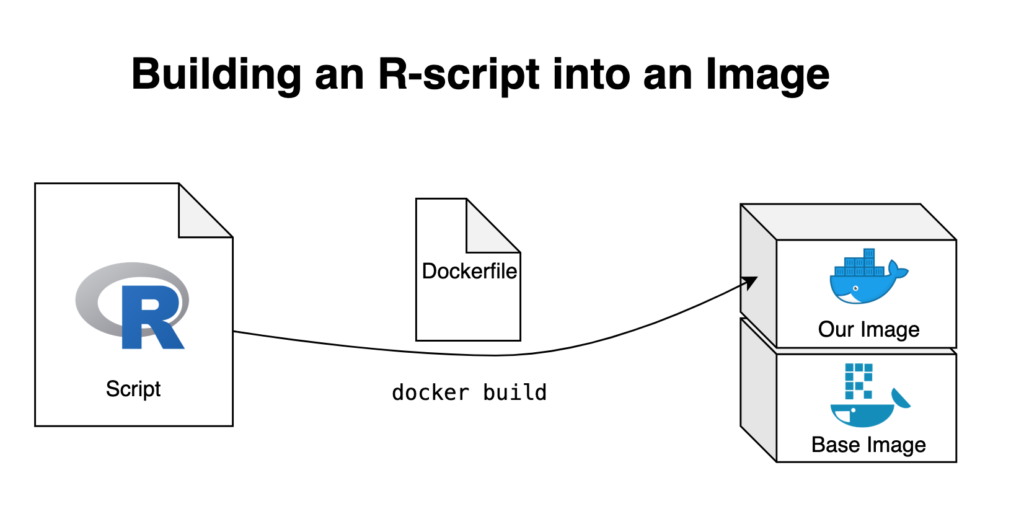
# 1. R语言Capet包集成概述
随着数据分析需求的日益增长,R语言作为数据分析领域的重要工具,不断地演化和扩展其生态系统。Capet包作为R语言的一个新兴扩展,极大地增强了R在数据处理和分析方面的能力。本章将对Capet包的基本概念、功能特点以及它在R语言集成中的作用进行概述,帮助读者初步理解Capet包及其在
【多层关联规则挖掘】:arules包的高级主题与策略指南
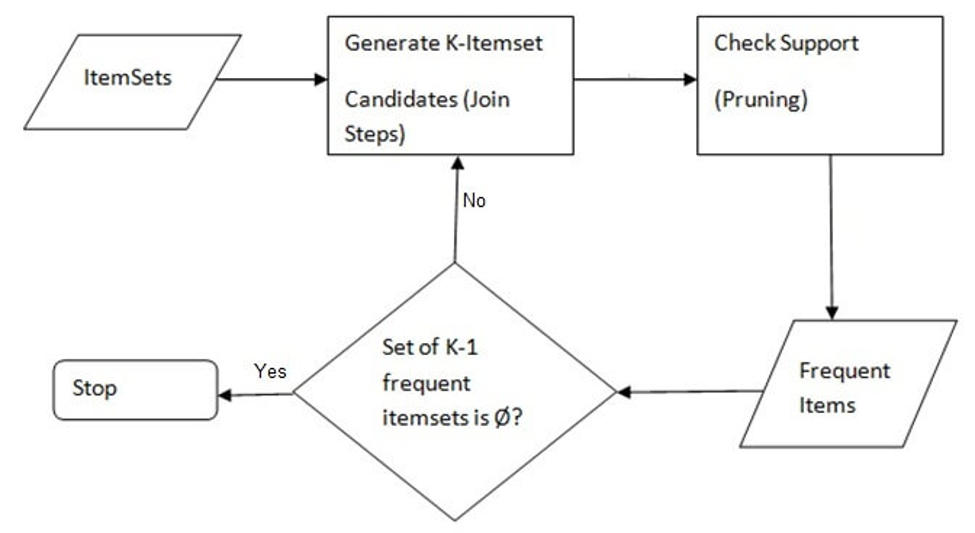
# 1. 多层关联规则挖掘的理论基础
关联规则挖掘是数据挖掘领域中的一项重要技术,它用于发现大量数据项之间有趣的关系或关联性。多层关联规则挖掘,在传统的单层关联规则基础上进行了扩展,允许在不同概念层级上发现关联规则,从而提供了更多维度的信息解释。本章将首先介绍关联规则挖掘的基本概念,包括支持度、置信度、提升度等关键术语,并进一步阐述多层关联规则挖掘的理论基础和其在数据挖掘中的作用。
## 1.1 关联规则挖掘
时间数据统一:R语言lubridate包在格式化中的应用

# 1. 时间数据处理的挑战与需求
在数据分析、数据挖掘、以及商业智能领域,时间数据处理是一个常见而复杂的任务。时间数据通常包含日期、时间、时区等多个维度,这使得准确、高效地处理时间数据显得尤为重要。当前,时间数据处理面临的主要挑战包括但不限于:不同时间格式的解析、时区的准确转换、时间序列的计算、以及时间数据的准确可视化展示。
为应对这些挑战,数据处理工作需要满足以下需求:
【R语言caret包多分类处理】:One-vs-Rest与One-vs-One策略的实施指南
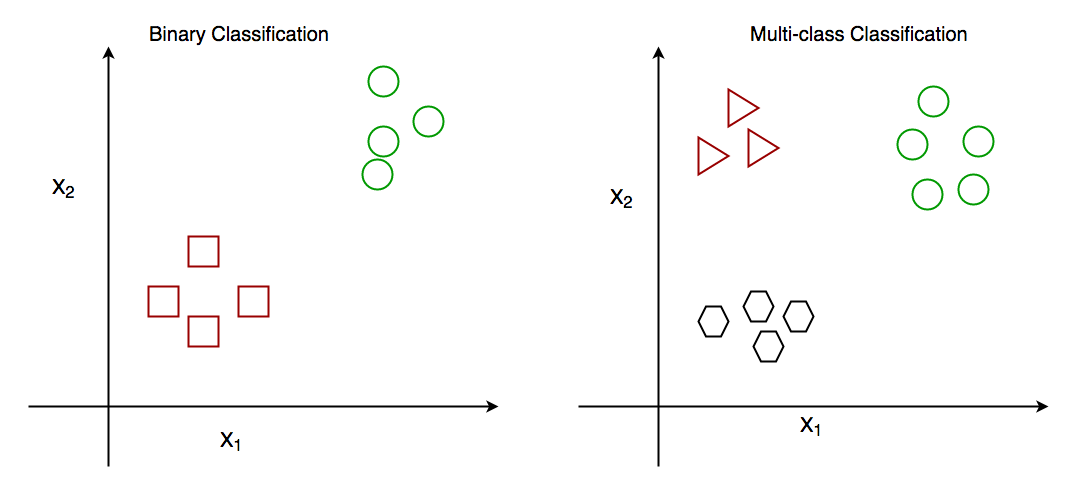
# 1. R语言与caret包基础概述
R语言作为统计编程领域的重要工具,拥有强大的数据处理和可视化能力,特别适合于数据分析和机器学习任务。本章节首先介绍R语言的基本语法和特点,重点强调其在统计建模和数据挖掘方面的能力。
## 1.1 R语言简介
R语言是一种解释型、交互式的高级统计分析语言。它的核心优势在于丰富的统计包
机器学习数据准备:R语言DWwR包的应用教程

# 1. 机器学习数据准备概述
在机器学习项目的生命周期中,数据准备阶段的重要性不言而喻。机器学习模型的性能在很大程度上取决于数据的质量与相关性。本章节将从数据准备的基础知识谈起,为读者揭示这一过程中的关键步骤和最佳实践。
## 1.1 数据准备的重要性
数据准备是机器学习的第一步,也是至关重要的一步。在这一阶
dplyr包函数详解:R语言数据操作的利器与高级技术

# 1. dplyr包概述
在现代数据分析中,R语言的`dplyr`包已经成为处理和操作表格数据的首选工具。`dplyr`提供了简单而强大的语义化函数,这些函数不仅易于学习,而且执行速度快,非常适合于复杂的数据操作。通过`dplyr`,我们能够高效地执行筛选、排序、汇总、分组和变量变换等任务,使得数据分析流程变得更为清晰和高效。
在本章中,我们将概述`dplyr`包的基
R语言中的概率图模型:使用BayesTree包进行图模型构建(图模型构建入门)

# 1. 概率图模型基础与R语言入门
## 1.1 R语言简介
R语言作为数据分析领域的重要工具,具备丰富的统计分析、图形表示功能。它是一种开源的、以数据操作、分析和展示为强项的编程语言,非常适合进行概率图模型的研究与应用。
```r
# 安装R语言基础包
install.packages("stats")
```
## 1.2 概率图模型简介
概率图模型(Probabi
【R语言数据包mlr的深度学习入门】:构建神经网络模型的创新途径

# 1. R语言和mlr包的简介
## 简述R语言
R语言是一种用于统计分析和图形表示的编程语言,广泛应用于数据分析、机器学习、数据挖掘等领域。由于其灵活性和强大的社区支持,R已经成为数据科学家和统计学家不可或缺的工具之一。
## mlr包的引入
mlr是R语言中的一个高性能的机器学习包,它提供了一个统一的接口来使用各种机器学习算法。这极大地简化了模型的选择、训练
R语言文本挖掘实战:社交媒体数据分析

# 1. R语言与文本挖掘简介
在当今信息爆炸的时代,数据成为了企业和社会决策的关键。文本作为数据的一种形式,其背后隐藏的深层含义和模式需要通过文本挖掘技术来挖掘。R语言是一种用于统计分析、图形表示和报告的编程语言和软件环境,它在文本挖掘领域展现出了强大的功能和灵活性。文本挖掘,简而言之,是利用各种计算技术从大量的
R语言e1071包处理不平衡数据集:重采样与权重调整,优化模型训练

# 1. 不平衡数据集的挑战和处理方法
在数据驱动的机器学习应用中,不平衡数据集是一个常见而具有挑战性的问题。不平衡数据指的是类别分布不均衡,一个或多个类别的样本数量远超过其他类别。这种不均衡往往会导致机器学习模型在预测时偏向于多数类,从而忽视少数类,造成性能下降。
为了应对这种挑战,研究人员开发了多种处理不平衡数据集的方法,如数据层面的重采样、在算法层面使用不同
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )