Model Comparison: 5 Strategies to Avoid Traps and Choose the Right Model
发布时间: 2024-09-15 11:21:12 阅读量: 22 订阅数: 26 
# Model Selection Avoiding Pitfalls: 5 Strategies to Help You Choose the Right Model
## 1.1 Why Model Selection is Critical
In machine learning projects, choosing the right model is crucial for final performance. An appropriate model can effectively capture the patterns in the data, achieve high accuracy in predictions, and ensure generalization on new data. Conversely, an inappropriate model can lead to overfitting or underfitting, thus affecting the predictive outcomes.
## 1.2 Main Challenges in Model Selection
The primary challenges in model selection include, but are not limited to, the size and quality of the dataset, the diversity of features, constraints on computational resources, and the complexity of the model. Moreover, the interpretability of the model and actual business requirements are factors that need consideration. Balancing model performance against resource consumption is necessary under limited information and resources.
## 1.3 Common Misconceptions in the Selection Process
During the model selection process, some common misconceptions exist, such as overly relying on a single evaluation metric, neglecting the generalization ability of the model, and blindly pursuing complexity. The correct approach involves considering multiple evaluation metrics, employing appropriate cross-validation methods, and considering the business scenario and the interpretability of the model.
Model selection is not just a technical issue; it involves understanding the problem, insight into the data, and a deep understanding of the business. This requires data scientists to possess comprehensive knowledge structures and rigorous thinking habits to make the most appropriate choice among many models.
# 2. Theoretical Foundations and Model Comparison Methods
Model selection is a multi-dimensional process that involves not only performance evaluation but also comparison between models and choosing the one that best fits a specific dataset. In this chapter, we delve into the theoretical foundations of model evaluation, model comparison methods, and how to verify a model's generalization ability using various approaches.
## 2.1 Basic Metrics for Model Evaluation
Model evaluation metrics are the yardstick by which we measure model performance. They help us understand how a model performs on specific tasks. Here are some of the basic evaluation metrics commonly used in machine learning.
### 2.1.1 Accuracy, Precision, and Recall
In classification problems, accuracy, precision, and recall are the three basic and essential concepts.
**Accuracy** measures the proportion of correctly predicted samples out of the total samples. The formula is:
```math
Accuracy = \frac{TP + TN}{TP + TN + FP + FN}
```
Where TP (True Positive) represents the number of samples correctly predicted as the positive class, TN (True Negative) represents the number of samples correctly predicted as the negative class, FP (False Positive) represents the number of samples incorrectly predicted as the positive class, and FN (False Negative) represents the number of samples incorrectly predicted as the negative class.
**Precision** measures the proportion of samples predicted as the positive class that are actually positive. The formula is:
```math
Precision = \frac{TP}{TP + FP}
```
**Recall**, also known as the true positive rate, measures the proportion of actual positive samples that are correctly predicted as positive by the model. The formula is:
```math
Recall = \frac{TP}{TP + FN}
```
In practical applications, these three metrics are often in conflict, requiring a trade-off based on the specific needs of the task.
### 2.1.2 ROC Curve and AUC Value
**ROC Curve** (Receiver Operating Characteristic Curve) is a curve drawn with the true positive rate (recall) as the vertical axis and the false positive rate (1 - specificity) as the horizontal axis. It reflects the classification performance of the model at different threshold settings.
**AUC Value** (Area Under Curve) is the area under the ROC curve, used to measure the strength of the model's classification ability. AUC values range between 0 and 1, with values closer to 1 indicating better classification ability.
ROC curves and AUC values can provide effective performance evaluation for datasets with imbalanced classes.
## 2.2 Statistical Tests for Model Comparison
After determining the basic evaluation metrics of the model, we also need to confirm the statistical significance of these metrics through statistical tests.
### 2.2.1 Hypothesis Testing Theory
Hypothesis testing is a common method in statistics used to examine whether there are significant differences between two or more datasets. It typically includes two hypotheses: the null hypothesis (H0) and the alternative hypothesis (H1). Through statistical analysis of the data, we decide whether to reject the null hypothesis.
In model comparison, we often test whether there is a significant difference in performance between two models. If two models do not significantly differ, then choosing the simpler or more easily interpretable model might be the better choice.
### 2.2.2 t-tests and ANOVA for Model Comparison
**t-test** (t-test) is commonly used to compare whether there is a significant difference in the means of two models, suitable for small sample sizes. Depending on the independence of the samples, t-tests are divided into independent sample t-tests and paired sample t-tests.
**ANOVA** (Analysis of Variance) is used to compare if there is a significant difference in the means of three or more models. If ANOVA indicates significant differences, then post hoc tests (such as Tukey's HSD) can be used to determine which model pairs have significant differences.
## 2.3 Cross-Validation and Model Generalization Ability
Cross-validation is a powerful model evaluation technique that ensures the stability and accuracy of model evaluation.
### 2.3.1 k-Fold Cross-Validation
In k-fold cross-validation, the dataset is randomly divided into k similar-sized, mutually exclusive subsets. The model training and validation steps are repeated k times, each time selecting a different subset as the validation set, and the remainder as the training set. The final performance evaluation is based on the average of all k validation results. k-fold cross-validation is particularly suitable for datasets with relatively small amounts of data.
### 2.3.2 Leave-One-Out Cross-Validation (LOOCV) and Adaptive Cross-Validation Methods
**Leave-One-Out Cross-Validation (LOOCV)** is an extreme form of k-fold cross-validation, where k equals the number of samples. Thus, only one sample is used for validation each time, and the remainder are used for training. LOOCV ensures the largest possible training set, but the computational cost is high and it is suitable for very small sample sizes.
**Adaptive Cross-Validation Methods** automatically select the number of folds based on the characteristics of the dataset, which can be seen as an optimization of k-fold cross-validation. These methods use specific criteria (such as information criteria) to determine the optimal number of k, balancing computational cost and evaluation accuracy.
In Chapter 2, we have explored some theoretical foundations and comparison methods for model evaluation, helping readers understand how to evaluate and compare different models theoretically. In the subsequent chapters, we will introduce methods for data preprocessing and feature selection, which are key steps in practical applications and important preparatory processes before model training.
# 3. Data Preprocessing and Feature Selection
Data preprocessing and feature selection are crucial steps in machine learning and data analysis. They directly affect the model's performance and the reliability of the results. In this chapter, we will delve into techniques for data preprocessing, including methods for handling missing values and outliers. Then, we will elaborate on two important techniques in feature engineering: Principal Component Analysis (PCA) and model-based feature selection methods.
## 3.1 Techniques for Data Cleaning
The quality of the dataset largely determines the performance of machine learning models. Data cleaning is a critical step to ensure data quality, with the core being the handling of missing and outlier values in the data.
### 3.1.1 Handling Missing Values
Missing values are a common data issue in practical applications. We can handle missing data through various methods, including:
- Deleting records or features containing missin

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
支付接口集成与安全:Node.js电商系统的支付解决方案

# 1. Node.js电商系统支付解决方案概述
随着互联网技术的迅速发展,电子商务系统已经成为了商业活动中不可或缺的一部分。Node.js,作为一款轻量级的服务器端JavaScript运行环境,因其实时性、高效性以及丰富的库支持,在电商系统中得到了广泛的应用,尤其是在处理支付这一关键环节。
支付是电商系统中至关重要的一个环节,它涉及到用户资金的流
【资源调度优化】:平衡Horovod的计算资源以缩短训练时间

# 1. 资源调度优化概述
在现代IT架构中,资源调度优化是保障系统高效运行的关键环节。本章节首先将对资源调度优化的重要性进行概述,明确其在计算、存储和网络资源管理中的作用,并指出优化的目的和挑战。资源调度优化不仅涉及到理论知识,还包含实际的技术应用,其核心在于如何在满足用户需求的同时,最大化地提升资源利用率并降低延迟。本章
【社交媒体融合】:将社交元素与体育主题网页完美结合

# 1. 社交媒体与体育主题网页融合的概念解析
## 1.1 社交媒体与体育主题网页融合概述
随着社交媒体的普及和体育活动的广泛参与,将两者融合起来已经成为一种新的趋势。社交媒体与体育主题网页的融合不仅能够增强用户的互动体验,还能利用社交媒体的数据和传播效应,为体育活动和品牌带来更大的曝光和影响力。
## 1.2 融合的目的和意义
社交媒体与体育主题网页融合的目的在于打造一个互动性强、参与度高的在线平台,通过这
Standard.jar维护与更新:最佳流程与高效操作指南

# 1. Standard.jar简介与重要性
## 1.1 Standard.jar概述
Standard.jar是IT行业广泛使用的一个开源工具库,它包含了一系列用于提高开发效率和应用程序性能的Java类和方法。作为一个功能丰富的包,Standard.jar提供了一套简化代码编写、减少重复工作的API集合,使得开发者可以更专注于业
Python遗传算法的并行计算:提高性能的最新技术与实现指南
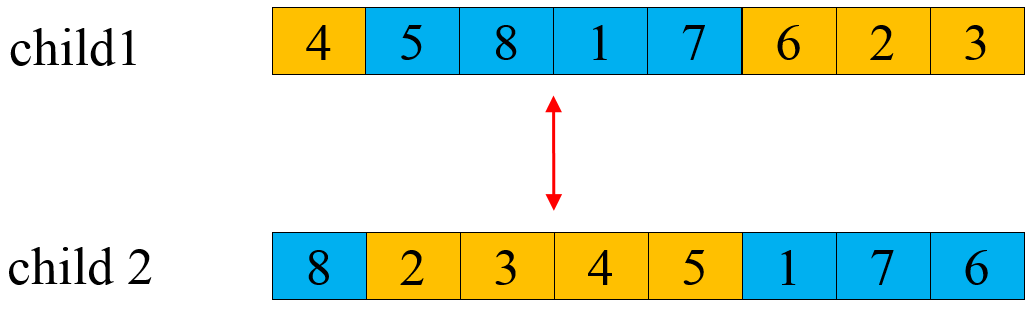
# 1. 遗传算法基础与并行计算概念
遗传算法是一种启发式搜索算法,模拟自然选择和遗传学原理,在计算机科学和优化领域中被广泛应用。这种算法在搜索空间中进行迭代,通过选择、交叉(杂交)和变异操作,逐步引导种群进化出适应环境的最优解。并行计算则是指使用多个计算资源同时解决计算问题的技术,它能显著缩短问题求解时间,提高计算效率。当遗传算法与并行计算结合时,可以处理更为复杂和大规模的优化问题,其并行化的核心是减少计算过程中的冗余和依赖,使得多个种群或子种群可以独
自动化部署的魅力:持续集成与持续部署(CI_CD)实践指南
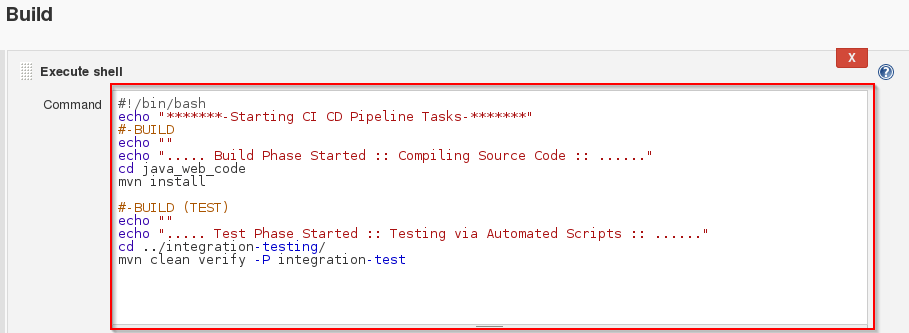
# 1. 持续集成与持续部署(CI/CD)概念解析
在当今快速发展的软件开发行业中,持续集成(Continuous Integration,CI)和持续部署(Continuous Deployment,CD)已成为提高软件质量和交付速度的重要实践。CI/CD是一种软件开发方法,通过自动化的
MATLAB图像特征提取与深度学习框架集成:打造未来的图像分析工具

# 1. MATLAB图像处理基础
在当今的数字化时代,图像处理已成为科学研究与工程实践中的一个核心领域。MATLAB作为一种广泛使用的数学计算和可视化软件,它在图像处理领域提供了强大的工具包和丰富的函数库,使得研究人员和工程师能够方便地对图像进行分析、处理和可视化。
## 1.1 MATLAB中的图像处理工具箱
MATLAB的图像处理工具箱(Image Pro
网络隔离与防火墙策略:防御网络威胁的终极指南
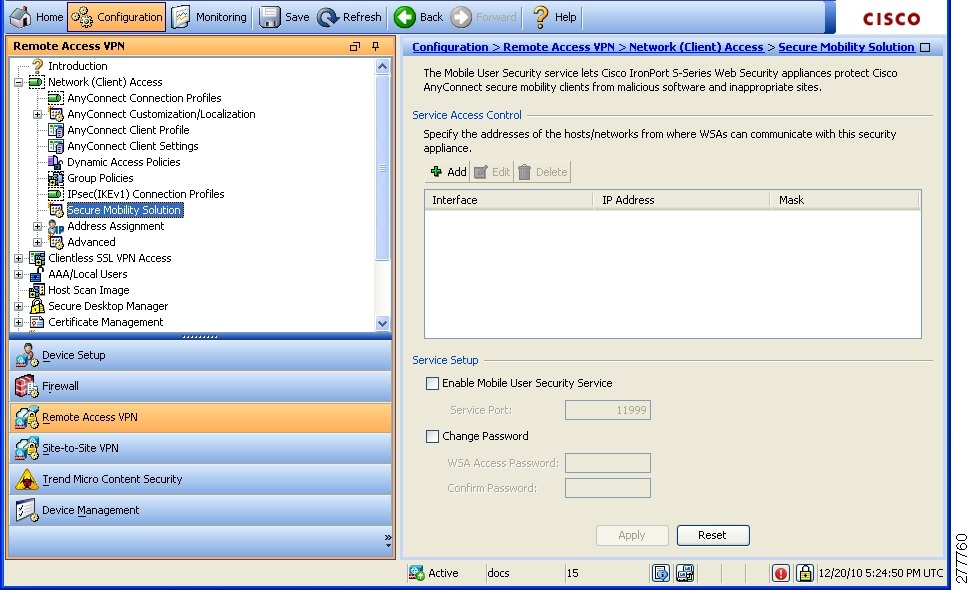
# 1. 网络隔离与防火墙策略概述
## 网络隔离与防火墙的基本概念
网络隔离与防火墙是网络安全中的两个基本概念,它们都用于保护网络不受恶意攻击和非法入侵。网络隔离是通过物理或逻辑方式,将网络划分为几个互不干扰的部分,以防止攻击的蔓延和数据的泄露。防火墙则是设置在网络边界上的安全系统,它可以根据预定义的安全规则,对进出网络
【直流调速系统可靠性提升】:仿真评估与优化指南
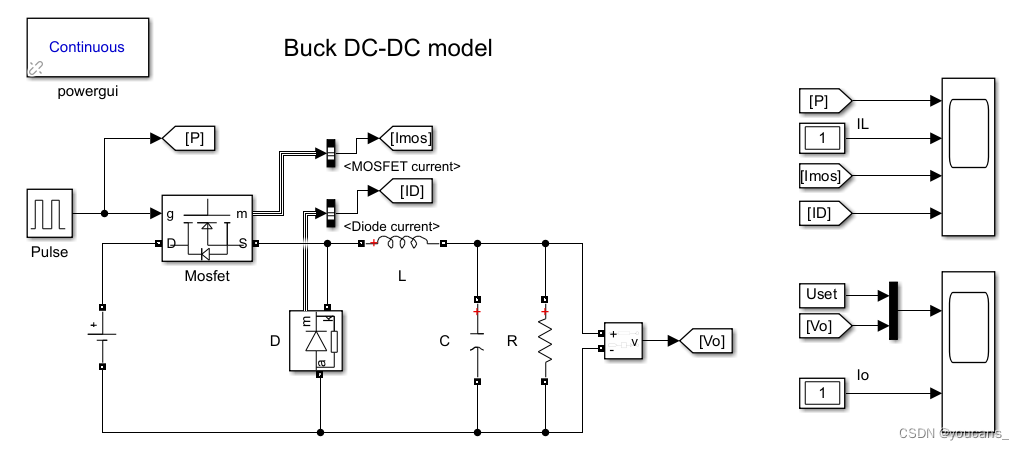
# 1. 直流调速系统的基本概念和原理
## 1.1 直流调速系统的组成与功能
直流调速系统是指用于控制直流电机转速的一系列装置和控制方法的总称。它主要包括直流电机、电源、控制器以及传感器等部件。系统的基本功能是根据控制需求,实现对电机运行状态的精确控制,包括启动、加速、减速以及制动。
## 1.2 直流电机的工作原理
直流电机的工作原理依赖于电磁感应。当电流通过转子绕组时,电磁力矩驱动电机转
JSTL响应式Web设计实战:适配各种设备的网页构建秘籍
# 1. 响应式Web设计的理论基础
响应式Web设计是创建能够适应多种设备屏幕尺寸和分辨率的网站的方法。这不仅提升了用户体验,也为网站拥有者节省了维护多个版本网站的成本。理论基础部分首先将介绍Web设计中常用的术语和概念,例如:像素密度、视口(Viewport)、流式布局和媒体查询。紧接着,本章将探讨响应式设计的三个基本组成部分:弹性网格、灵活的图片以及媒体查询。最后,本章会对如何构建一个响应式网页进行初步的概述,为后续章节使用JSTL进行实践
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )