The Ultimate Guide to Machine Learning Model Selection: 20 Secrets and Tips from Novice to Expert
发布时间: 2024-09-15 11:08:59 阅读量: 31 订阅数: 26 
# 1. Overview of Machine Learning Model Selection
In today's data-driven world, machine learning has become an indispensable tool for analyzing and understanding complex data patterns. Model selection, as a crucial part of machine learning projects, determines the quality and generalization capability of the patterns learned from data. This chapter will outline the necessity of model selection and provide a starting point for readers to delve into more detailed discussions.
Machine learning model selection involves not only the comparison of algorithms but also a series of steps including understanding the problem, preprocessing data, training, validating, and testing the model. The correct model selection can help us build robust and accurate prediction systems, providing strong support for actual business decision-making.
In the next chapter, we will further explore the theoretical foundations and principles of model selection, gradually delving into various aspects of machine learning model selection, laying a solid foundation for building efficient machine learning systems.
# 2. Theoretical Foundations and Principles of Model Selection
## 2.1 Basic Concepts of Machine Learning
### 2.1.1 Definition and Types of Machine Learning
Machine learning is an interdisciplinary field that involves probability theory, statistics, approximation theory, convex analysis, and computational complexity theory, among other disciplines. Its goal is to enable computers to simulate the human learning process through algorithms, learn patterns from data, and predict unknown data.
Machine learning models are generally divided into two categories: supervised learning and unsupervised learning:
- **Supervised Learning**: Models are trained on labeled datasets with the goal of predicting output results. Depending on the type of output results, supervised learning can be further classified into classification (Classification) and regression (Regression). The output of classification problems is discrete categories, while the output of regression problems is continuous numerical values.
- **Unsupervised Learning**: ***mon unsupervised learning tasks include clustering (Clustering) and dimensionality reduction (Dimensionality Reduction).
### 2.1.2 Standards for Evaluating Mode***
***mon evaluation criteria include:
- **Accuracy**: The proportion of the number of samples correctly predicted by the model to the total number of samples. Although accuracy is an intuitive performance indicator, it may be misleading in imbalanced datasets.
- **Precision** and **Recall**: Precision is the proportion of correctly predicted positive samples to the total number of samples predicted as positive, while recall is the proportion of correctly predicted positive samples to the total number of actual positive samples. These two metrics are important considerations when dealing with classification problems, especially in imbalanced datasets.
- **F1 Score**: The harmonic mean of precision and recall, used to comprehensively evaluate model performance.
- **Area Under the ROC Curve (AUC-ROC)**: The ROC curve reflects the model's ability to distinguish between positive and negative samples. The higher the AUC value, the better the model's generalization ability.
## 2.2 Principles of Model Selection
### 2.2.1 Factors to Consider When Choosing a Model
Selecting an appropriate machine learning model requires considering multiple factors, including:
- **Problem Type**: Choose the most suitable model type based on the nature of the problem, for example, for classification problems, logistic regression, support vector machines, or neural networks might be appropriate choices.
- **Data Scale and Quality**: The size of the dataset, the types, and quality of features will all affect the choice of model. Some models may require a large amount of data to perform well, while others can handle small amounts of data effectively.
- **Model Interpretability**: In certain application scenarios, such as medical diagnosis, model interpretability is crucial, and linear regression, decision trees, and other more easily interpretable models may be needed.
### 2.2.2 Relationship Between Model Complexity and Data Scale
There is a balance between model complexity and the amount of available data. Simple models (like linear regression) may not need much data, ***plex models (like neural networks) can fit the data better, but they also require a large amount of data to avoid overfitting and to train a model with strong generalization ability.
- **Small Datasets**: For small datasets, it is generally recommended to use models with lower complexity.
- **Large Datasets**: Large datasets better support complex models, especially deep learning models.
### 2.2.3 Strategies to Avoid Overfitting and Underfitting
Overfitting and underfitting are two common problems encountered during model training:
- **Overfitting**: The model performs well on training data but has poor predictive power on new data. To avoid overfitting, one can increase the amount of training data, use regularization techniques (such as L1 and L2 regularization), reduce model complexity, or stop training early.
- **Underfitting**: The model cannot capture the patterns in the data, and it performs poorly both on training data and new data. Solutions to underfitting typically include increasing model complexity, reducing regularization intensity, or improving model feature representation.
```python
# Python Example: Using Regularization to Prevent Overfitting
from sklearn.linear_model import RidgeClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# Load Dataset
iris = load_iris()
X, y = iris.data, iris.target
# Split Train and Test Sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Use Ridge Classifier with L2 Regularization
ridge_clf = RidgeClassifier(alpha=1.0)
ridge_clf.fit(X_train, y_train)
# Calculate Test Set Accuracy
print("Ridge Classifier Test Accuracy:", ridge_clf.score(X_test, y_test))
```
In the above code, we used a Ridge Classifier with L2 regularization to prevent overfitting and evaluated the model's performance with training and test accuracy. The regularization parameter `alpha` controls the strength of regularization and needs to be adjusted based on actual data.
# 3. Practical Skills and Model Evaluation
Practical skills and model evaluation are crucial in machine learning projects, as they directly affect the final performance and applicability of the model. In this chapter, we will delve into techniques for feature engineering, strategies for model validation and selection, and demonstrate how to choose suitable machine learning models through case studies.
## Techniques for Feature Engineering
Feature engineering is the process of transforming raw data into features that can be effectively utilized by models in machine learning. Good feature engineering can significantly improve model performance.
### Methods for Feature Selection
Feature selection aims to select the most contributive features for the prediction task from the original dataset. This can reduce the complexity of the model and lower the risk of overfitting.
#### 3.1.1 Filtering Methods (Filter Methods)
Filter methods assess the relationship between each feature and the target variable through statistical tests, which are commonly used for preliminary feature selection. For example, using chi-square tests, information gain, or correlation coefficients.
```python
from sklearn.feature_selection import SelectKBest, chi2
# Assume X is the feature matrix and y is the target variable
selector = SelectKBest(chi2, k=10)
X_new = selector.fit_transform(X, y)
# Output the selected features
selected_features = X.columns[selector.get_support()]
```
The above code uses the chi-square test as the scoring function and selects the top 10 features with the highest scores. The `k` parameter can be adjusted according to actual conditions.
#### 3.1.2 Wrapper Methods (Wrapper Methods)
Wrapper methods attempt to find the best combination of features, with recursive feature elimination (RFE) being a typical example.
```python
from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression
# Initialize the model
model = LogisticRegression()
# RFE Method
rfe = RFE(estimator=model, n_features_to_select=10)
X_rfe = rfe.fit_transform(X, y)
# View the selected features
selected_features = X.columns[rfe.support_]
```
RFE iteratively selects the best subset of features, and the `n_features_to_select` parameter specifies the number of features to select.
#### 3.1.3 Embedded Methods (Embedded Methods)
Embedded methods combine the advantages of filtering and wrapper methods, and feature selection is performed during the model training process.
```python
from sklearn.ensemble import RandomForestClassifier
# Random forest is an ensemble learning method that has built-in feature importance assessment
forest = RandomForestClassifier(n_estimators=100)
forest.fit(X, y)
# Output the importance scores for each feature
importances = forest.feature_importances_
```
In the random forest model, feature importance can be obtained through the `feature_importances_` attribute.
### Feature Scaling and Transformation Techniques
Feature scaling ensures that all features are within the same numerical range, thus preventing features with larger numerical ranges from disproportionately affecting model training.
#### 3.1.4 Standardization and Normalization
Standardization and normalization are the most common feature scaling methods.
```python
from sklearn.preprocessing import StandardScaler
# Standardize Features
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
```
Standardization scales the data so that the mean is 0 and the standard deviation is 1.
```python
from sklearn.preprocessing import MinMaxScaler
# Normalize Features
scaler = MinMaxScaler()
X_normalized = scaler.fit_transform(X)
```
Normalization scales the data between 0 and 1.
### Feature Transformation Techniques
Feature transformation techniques map data from the original feature space to a new space to reveal complex relationships and patterns in the data.
#### 3.1.5 Principal Component Analysis (PCA)
PCA is a commonly used data reduction technique that can transform data into a new space while retaining most of the information in the data.
```python
from sklearn.decomposition import PCA
# PCA Dimensionality Reduction
pca = PCA(n_components=5)
X_pca = pca.fit_transform(X)
```
The `n_components` parameter can be used to set the desired number of dimensions.
## Model Validation and Selection
Model validation and selection are key steps in determining the final model, involving the evaluation of the model's generalization ability and the selection of the optimal model from among them.
### Strategies for Cross-Validation
Cross-validation is a method for evaluating a model's generalization ability, with the most common being k-fold cross-validation.
```python
from sklearn.model_selection import cross_val_score
# Use k-fold Cross-Validation to Evaluate the Model
scores = cross_val_score(estimator=model, X=X, y=y, cv=5)
print("Cross-validation scores:", scores)
```
In this example, we used 5-fold cross-validation, where the `cv` parameter represents the number of folds.
### Criteria and Methods for Model Selection
When selecting the best model, we typically consider multiple evaluation metrics, such as accuracy, precision, recall, F1 score, etc.
#### 3.2.1 Scoring Functions
In scikit-learn, we can use different scoring functions to evaluate models.
```python
from sklearn.metrics import accuracy_score, precision_score
# Assume y_pred is the model's prediction result
y_pred = model.predict(X)
# Calculate Accuracy and Precision
accuracy = accuracy_score(y, y_pred)
precision = precision_score(y, y_pred)
```
Accuracy is the proportion of correct predictions, while precision is the proportion of correctly predicted positive samples to the total number of samples predicted as positive.
#### 3.2.2 Model Selection
Model selection requires a comprehensive consideration of the model's performance and actual application needs, such as computational resources, model interpretability, etc.
```python
from sklearn.model_selection import GridSearchCV
# Use Grid Search for Hyperparameter Optimization
param_grid = {'C': [0.1, 1, 10], 'kernel': ['linear', 'rbf']}
grid_search = GridSearchCV(estimator=model, param_grid=param_grid, cv=5)
grid_search.fit(X, y)
# Output the Best Parameter Combination
best_params = grid_search.best_params_
```
`GridSearchCV` exhaustively enumerates specified parameter values and uses cross-validation to find the most outstanding model.
### Case Study: Selecting the Appropriate Machine Learning Model
In this section, we will demonstrate how to apply the above theories to select an appropriate machine learning model through a specific case.
#### 3.2.3 Case Selection Criteria and Data Preparation
Suppose we are solving a binary classification problem, the goal is to predict whether a customer will churn.
```python
# Data Loading
import pandas as pd
data = pd.read_csv('customer_churn.csv')
X = data.drop('Churn', axis=1)
y = data['Churn']
```
#### 3.2.4 Model Training and Validation
Next, we use several different types of machine learning models, such as logistic regression, support vector machines, and random forests, for training and validation.
```python
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
# Data Splitting
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Model Training
models = {
'Logistic Regression': LogisticRegression(),
'SVC': SVC(),
'Random Forest': RandomForestClassifier()
}
for name, model in models.items():
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
print(name, accuracy_score(y_test, y_pred))
```
By comparing the accuracy of different models, we can preliminarily assess which models are more suitable for the current prediction task.
#### 3.2.5 Final Model Selection and Evaluation
In practical applications, we also need to consider other factors, such as the model's prediction time, interpretability, etc., and ultimately select the model that best meets business needs.
```python
# Further Evaluate the Model using Random Forest as an Example
from sklearn.metrics import classification_report, confusion_matrix
# More Detailed Performance Analysis
print(classification_report(y_test, y_pred))
print(confusion_matrix(y_test, y_pred))
```
The classification report and confusion matrix provide detailed performance metrics for the model, including precision, recall, and F1 score.
Through this case study, we understand that in practical applications, selecting a model requires considering multiple factors, not just the accuracy of the model.
In the next chapter, we will continue to delve into advanced models and optimization techniques, which will help us further improve the performance and reliability of the model.
# 4. Advanced Models and Optimization Techniques
## 4.1 Exploration of Advanced Models
### 4.1.1 Methods and Advantages of Ensemble Learning
In the field of machine learning, ensemble learning is a paradigm that constructs and combines multiple learners to solve problems that a single learner cannot address. The core idea of ensemble learning is to improve the overall prediction accuracy and robustness by constructing and combining multiple learners. This method is effective because different models may perform better on different subsets of the data, and by ensemble, the advantages of these subsets can be combined, thereby enhancing the overall prediction performance.
The main methods of ensemble learning include:
- Bagging (Bootstrap Aggregating): By bootstrap sampling from the original dataset, multiple subsets are drawn with replacement, and models are independently trained on each subset. The results of these models are then combined through voting or averaging methods. A typical example is the random forest, which constructs multiple decision trees and combines their predictions.
- Boosting: This method involves continuous iteration, where each model attempts to correct the errors of the previous model, forming a strong learner. A successful example is gradient boosting trees (Gradient Boosting Tree).
- Stacking (Stacked Generalization): This method uses different models as "base learners" and utilizes a "meta-learner" to make the final decision based on these base learners' predictions. These base learners can be of different types, such as decision trees, support vector machines, etc.
The advantages of ensemble learning lie in:
- Robustness: Since the ensemble is based on the predictions of multiple learners, it is usually more stable than a single model.
- Reduction of Variance and Bias: While ensemble learning may not significantly reduce bias, it can effectively reduce variance.
- Prevention of Overfitting: Especially, the random subspace in the Bagging method helps reduce the variance of the model, thereby alleviating the problem of overfitting.
### 4.1.2 Application of Deep Learning in Model Selection
Deep learning is a branch of machine learning that consists of neural networks with multiple layers of nonlinear transformations capable of learning. In model selection, deep learning plays an extremely important role, especially in fields such as image recognition, natural language processing, and speech recognition.
Deep learning methods typically involve large amounts of data and complex network structures, making them advantageous in handling nonlinear, high-dimensional data. Deep learning models have the following advantages and challenges in model selection:
- Automatic Feature Extraction: Deep learning models can automatically learn complex features from data without the need for manual feature design.
- Scalability: Deep learning models can be easily scaled to large datasets, and model performance usually improves as the amount of data increases.
- Requirement for Large Computational Resources: Training complex deep learning models requires high-performance GPUs or TPUs.
- Poor Interpretability: Deep learning models are often considered "black boxes," and their decision-making processes are difficult to explain.
Due to the high costs associated with choosing and tuning deep learning models, it is necessary to carefully evaluate whether the problem is suitable for deep learning methods and whether there is enough data and computational resources to support the training and deployment of the model before deciding to use deep learning models.
## 4.2 Hyperparameter Tuning
### 4.2.1 Basic Methods of Hyperparameter Tuning
In machine learning models, hyperparameters are those that need to be set before learning algorithms, controlling the high-level configuration of the learning process, such as the number of layers in the network, the number of nodes in each layer, the learning rate, etc., which are different from the parameters in the model training process. The choice of hyperparameters directly affects the performance of the model.
Basic methods for hyperparameter tuning include:
- Grid Search: Exhaustively search through predefined hyperparameter combinations, using cross-validation to evaluate the performance of each combination, and selecting the best set.
- Random Search: Randomly select hyperparameter combinations for evaluation. Random search is often more efficient than grid search, especially when the hyperparameter space is large.
- Model-Based Search: Use heuristic methods or model-based methods to select hyperparameters, such as Bayesian optimization.
The key to hyperparameter tuning lies in:
- Evaluation Metrics: Choose appropriate performance metrics as evaluation criteria.
- Search Strategy: Select an appropriate search strategy to more efficiently find the optimal hyperparameters.
- Parallel Computing: Use parallel computing whenever possible to speed up the hyperparameter search process.
### 4.2.2 Using Grid Search and Random Search for Hyperparameter Optimization
#### Grid Search
Grid search is an exhaustive search method that defines a search range and step size for a parameter and searches through all possible combinations within that range, using cross-validation to evaluate the performance of each combination. Grid search ensures finding the optimal parameter combination, but the computational cost will skyrocket as the number of parameters increases.
Example code block:
```python
from sklearn.model_selection import GridSearchCV
# Assume we have a model and a range of parameters
parameters = {'n_estimators': [100, 300, 500], 'max_features': ['auto', 'sqrt', 'log2']}
# Use Random Forest as the base classifier
clf = GridSearchCV(estimator=RandomForestClassifier(), param_grid=parameters, cv=5)
clf.fit(X_train, y_train)
# Output the best parameters and corresponding performance metrics
print("Best parameters set found on development set:")
print(clf.best_params_)
```
Execution logic explanation:
- Define a parameter grid `parameters`, where the set parameters are the `n_estimators` and `max_features` of the Random Forest classifier.
- Use `GridSearchCV` for grid search, where `cv=5` indicates using 5-fold cross-validation.
- Use the `fit` method to train the dataset `X_train` and `y_train`, and find the optimal parameter combination.
- `clf.best_params_` will output the found best parameter combination.
#### Random Search
Unlike grid search, random search randomly selects parameter values and searches for them a specified number of times. This makes random search more efficient when dealing with high-dimensional hyperparameter spaces, especially when some parameters are more important than others.
Example code block:
```python
from sklearn.model_selection import RandomizedSearchCV
# Define a parameter distribution
param_dist = {'n_estimators': [100, 300, 500, 800, 1200],
'max_features': ['auto', 'sqrt', 'log2'],
'max_depth': [None, 10, 20, 30]}
# Use Random Forest as the base classifier
clf = RandomizedSearchCV(estimator=RandomForestClassifier(), param_distributions=param_dist, n_iter=10, cv=5, random_state=1)
clf.fit(X_train, y_train)
# Output the best parameters and corresponding performance metrics
print("Best parameters set found on development set:")
print(clf.best_params_)
```
Execution logic explanation:
- Use `RandomizedSearchCV` for random search, where `n_iter=10` indicates selecting 10 sets of parameters randomly from the parameter distribution for search.
- The setting of other parameters is similar to grid search, using 5-fold cross-validation and setting the random state `random_state` for reproducibility of results.
- The output `clf.best_params_` also gives the optimal parameter combination.
### 4.2.3 Practice: Using Bayesian Optimization Techniques for Parameter Tuning
Bayesian optimization is a more efficient hyperparameter optimization method that uses the Bayesian optimization algorithm to select the optimal parameter combination. The Bayesian optimization algorithm updates a probabilistic model in each iteration to predict the performance under given parameters and uses this model to select parameters for future iterations.
Example code block:
```python
from sklearn.model_selection import BayesSearchCV
from skopt.space import Real, Categorical, Integer
# Define the search space
search_space = {
'n_estimators': Integer(100, 1500),
'max_features': Categorical(['auto', 'sqrt', 'log2']),
'max_depth': Integer(3, 15),
'learning_rate': Real(0.01, 0.3)
}
# Create a Bayesian optimizer
opt = BayesSearchCV(estimator=RandomForestClassifier(), search_spaces=search_space, n_iter=50, cv=5, random_state=1)
# Start the search
opt.fit(X_train, y_train)
# Output the best parameters and corresponding performance metrics
print("Best parameters set found on development set:")
print(opt.best_params_)
```
Execution logic explanation:
- Use `BayesSearchCV` for Bayesian optimization search, defining the search space for hyperparameters, where `n_estimators` and `max_depth` are integer ranges, `max_features` is a categorical variable, and `learning_rate` is a continuous real number.
- Set the number of iterations `n_iter=50`, indicating 50 iterations of search.
- The output `opt.best_params_` gives the best parameter combination found after Bayesian optimization.
Bayesian optimization can find better parameter combinations faster than grid search and random search, especially in high-dimensional hyperparameter spaces. However, it is more complex and computationally expensive. Beginners or those with limited resources may start with grid search and random search before considering Bayesian optimization.
# 5. Case Studies and Future Trends
## 5.1 Real-World Case Analysis
### 5.1.1 Case Selection Criteria and Data Preparation
When selecting a case for analysis, we should follow some clear criteria. First, the case should be representative, preferably a problem commonly found in the industry. For example, in the financial sector, we can choose credit scoring or fraud detection as a case. Second, the difficulty of the case should be moderate, as overly simple cases cannot reflect the complexity of model selection, while overly complex cases may cause the analysis to lose focus.
Data preparation is one of the key steps in case studies. It includes data collection, cleaning, feature engineering, and dividing the dataset into training and test sets. The dataset should be large enough to ensure statistical significance but not too large to make the analysis impractical. To ensure the effectiveness and reproducibility of the model, data sets are usually randomly divided, ensuring the repeatability of the division process.
Below is a simple Python code example for preparing the dataset:
```python
import pandas as pd
from sklearn.model_selection import train_test_split
# Load the dataset
data = pd.read_csv('data.csv')
# Data cleaning (example)
data.dropna(inplace=True)
# Feature selection (example)
features = data[['feature1', 'feature2', 'feature3']]
target = data['target']
# Splitting the dataset
X_train, X_test, y_train, y_test = train_test_split(features, target, test_size=0.2, random_state=42)
# Save the split datasets
X_train.to_csv('X_train.csv', index=False)
X_test.to_csv('X_test.csv', index=False)
y_train.to_csv('y_train.csv', index=False)
y_test.to_csv('y_test.csv', index=False)
```
### 5.1.2 Model Deployment and Monitoring
Once the machine learning model has been selected and trained, the next step is to deploy it into a production environment and continuously monitor it. This usually involves the following steps:
1. **Model Conversion**: Convert the trained model into a format that can be called externally, such as saving it as a pickle file or converting it into a web service API.
2. **Deployment**: Deploy the model to a server or cloud platform, ensuring it can accept external requests and make predictions.
3. **Monitoring**: Monitor the performance of the model in actual applications. This includes continuously tracking the accuracy of the model's predictions and monitoring the model's resource usage (such as CPU and memory usage).
4. **Updates and Maintenance**: As time passes and data changes, the model may become outdated. Regularly retrain the model and update it with new data.
Code example (assuming we use the Flask framework to deploy the model):
```python
from flask import Flask, request, jsonify
import joblib
app = Flask(__name__)
# Load the model
model = joblib.load('model.pkl')
@app.route('/predict', methods=['POST'])
def predict():
data = request.json
pred = model.predict([data])
return jsonify({'prediction': pred.tolist()})
if __name__ == '__main__':
app.run(debug=True, host='*.*.*.*', port=5000)
```
## 5.2 Future Directions for Machine Learning Model Selection
### 5.2.1 Development Trends of AutoML
As machine learning applications continue to expand, AutoML has become a hot topic in the industry. AutoML refers to the automation of the machine learning process, including automation of feature engineering, model selection, model training, and model optimization. Its goal is to enable non-experts to efficiently use machine learning technology while reducing reliance on professional data scientists.
Currently, Google's AutoML, Microsoft's Azure Machine Learning, and H2O are all making continuous progress in this field. Future development trends include increasing the level of automation, reducing the need for manual intervention, and providing more efficient model training and optimization methods.
### 5.2.2 Prospects for the Application of Emerging Technologies in Model Selection
With technological advancements, emerging technologies such as Neural Architecture Search (NAS) and quantum computing are expected to significantly impact model selection. NAS can automatically discover the optimal neural network architecture within a predefined search space, significantly improving model performance and reducing the complexity and time required for manual design.
Quantum computing, as another frontier research field, may change the landscape of machine learning in the future with its unique computing capabilities. If quantum computing can achieve large-scale commercial applications, it may introduce entirely new model selection and optimization algorithms, breaking through existing performance limits.
Despite this, these technologies are still in development, and their potential and challenges in practical applications remain to be further explored. As technology matures, they will provide new possibilities for machine learning model selection and may lead a new round of technological revolutions.

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Keras注意力机制:构建理解复杂数据的强大模型

# 1. 注意力机制在深度学习中的作用
## 1.1 理解深度学习中的注意力
深度学习通过模仿人脑的信息处理机制,已经取得了巨大的成功。然而,传统深度学习模型在处理长序列数据时常常遇到挑战,如长距离依赖问题和计算资源消耗。注意力机制的提出为解决这些问题提供了一种创新的方法。通过模仿人类的注意力集中过程,这种机制允许模型在处理信息时,更加聚焦于相关数据,从而提高学习效率和准确性。
## 1.2
PyTorch超参数调优:专家的5步调优指南

# 1. PyTorch超参数调优基础概念
## 1.1 什么是超参数?
在深度学习中,超参数是模型训练前需要设定的参数,它们控制学习过程并影响模型的性能。与模型参数(如权重和偏置)不同,超参数不会在训练过程中自动更新,而是需要我们根据经验或者通过调优来确定它们的最优值。
## 1.2 为什么要进行超参数调优?
超参数的选择直接影响模型的学习效率和最终的性能。在没有经过优化的默认值下训练模型可能会导致以下问题:
- **过拟合**:模型在
Pandas数据转换:重塑、融合与数据转换技巧秘籍

# 1. Pandas数据转换基础
在这一章节中,我们将介绍Pandas库中数据转换的基础知识,为读者搭建理解后续章节内容的基础。首先,我们将快速回顾Pandas库的重要性以及它在数据分析中的核心地位。接下来,我们将探讨数据转换的基本概念,包括数据的筛选、清洗、聚合等操作。然后,逐步深入到不同数据转换场景,对每种操作的实际意义进行详细解读,以及它们如何影响数
【数据集加载与分析】:Scikit-learn内置数据集探索指南

# 1. Scikit-learn数据集简介
数据科学的核心是数据,而高效地处理和分析数据离不开合适的工具和数据集。Scikit-learn,一个广泛应用于Python语言的开源机器学习库,不仅提供了一整套机器学习算法,还内置了多种数据集,为数据科学家进行数据探索和模型验证提供了极大的便利。本章将首先介绍Scikit-learn数据集的基础知识,包括它的起源、
硬件加速在目标检测中的应用:FPGA vs. GPU的性能对比
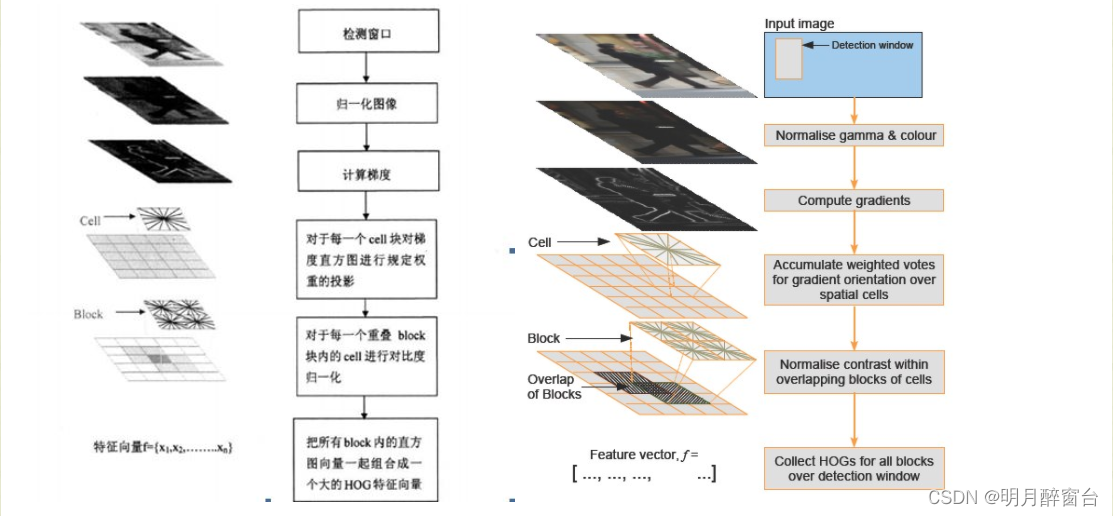
# 1. 目标检测技术与硬件加速概述
目标检测技术是计算机视觉领域的一项核心技术,它能够识别图像中的感兴趣物体,并对其进行分类与定位。这一过程通常涉及到复杂的算法和大量的计算资源,因此硬件加速成为了提升目标检测性能的关键技术手段。本章将深入探讨目标检测的基本原理,以及硬件加速,特别是FPGA和GPU在目标检测中的作用与优势。
## 1.1 目标检测技术的演进与重要性
目标检测技术的发展与深度学习的兴起紧密相关
NumPy中的文件输入输出:持久化数据存储与读取的4大技巧

# 1. NumPy概述与数据持久化基础
在本章中,我们将对NumPy进行一个初步的探讨,并且将重点放在其数据持久化的基础方面。NumPy是Python中用于科学计算的基础库,它提供了高性能的多维数组对象和用于处理这些数组的工具。对于数据持久化而言,它确保了数据能够在程序运行之间保持可用性。数据持久化是数据科学和机器学习项目中不可或缺的一部分,特别是在处理
【图像分类模型自动化部署】:从训练到生产的流程指南

# 1. 图像分类模型自动化部署概述
在当今数据驱动的世界中,图像分类模型已经成为多个领域不可或缺的一部分,包括但不限于医疗成像、自动驾驶和安全监控。然而,手动部署和维护这些模型不仅耗时而且容易出错。随着机器学习技术的发展,自动化部署成为了加速模型从开发到生产的有效途径,从而缩短产品上市时间并提高模型的性能和可靠性。
本章旨在为读者提供自动化部署图像分类模型的基本概念和流程概览,
【循环神经网络】:TensorFlow中RNN、LSTM和GRU的实现

# 1. 循环神经网络(RNN)基础
在当今的人工智能领域,循环神经网络(RNN)是处理序列数据的核心技术之一。与传统的全连接网络和卷积网络不同,RNN通过其独特的循环结构,能够处理并记忆序列化信息,这使得它在时间序列分析、语音识别、自然语言处理等多
【商业化语音识别】:技术挑战与机遇并存的市场前景分析
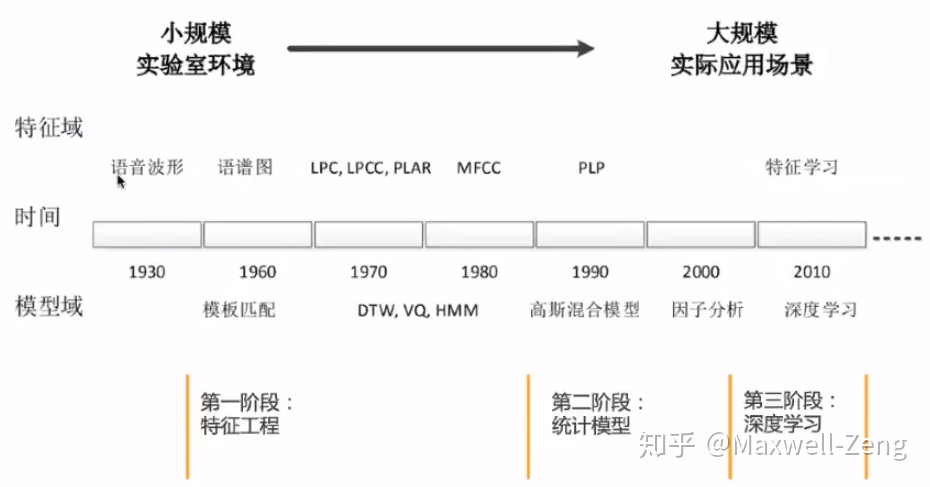
# 1. 商业化语音识别概述
语音识别技术作为人工智能的一个重要分支,近年来随着技术的不断进步和应用的扩展,已成为商业化领域的一大热点。在本章节,我们将从商业化语音识别的基本概念出发,探索其在商业环境中的实际应用,以及如何通过提升识别精度、扩展应用场景来增强用户体验和市场竞争力。
## 1.1 语音识别技术的兴起背景
语音识别技术将人类的语音信号转化为可被机器理解的文本信息,它
优化之道:时间序列预测中的时间复杂度与模型调优技巧
# 1. 时间序列预测概述
在进行数据分析和预测时,时间序列预测作为一种重要的技术,广泛应用于经济、气象、工业控制、生物信息等领域。时间序列预测是通过分析历史时间点上的数据,以推断未来的数据走向。这种预测方法在决策支持系统中占据着不可替代的地位,因为通过它能够揭示数据随时间变化的规律性,为科学决策提供依据。
时间序列预测的准确性受到多种因素的影响,例如数据
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )