Why Explainability in Models Matters: 4 Methods to Achieve Interpretable AI
发布时间: 2024-09-15 11:36:35 阅读量: 31 订阅数: 31 

How-to-Design-a-Good-API-and-Why-it-Matters:约书亚·布洛赫 (Joshua Bloch) 在
# The Importance of Model Interpretability: Achieving Explainable AI with 4 Methods
## 1. The Necessity of Model Interpretability
The importance of model interpretability has been a widely discussed topic in the construction and deployment of artificial intelligence systems in recent years. This is not only because algorithms and models have become more complex, but also because for many applications, transparency and interpretability are crucial for building user trust, ensuring fairness, and complying with regulations. Understanding the decision-making process of a model enables us to diagnose and improve the model more effectively, reduce biases, and promote interdisciplinary collaboration. This chapter will discuss the necessity of model interpretability in the AI field and lay the theoretical and practical groundwork for subsequent discussions.
Model interpretability is not just a technical issue; it also involves legal, ethical, and moral aspects. For example, in the financial services industry, model interpretability helps prevent unfair credit scoring; in the medical field, explainable AI can enhance doctors' trust in disease predictions and treatment plans. Therefore, exploring interpretability is not only an aspect of improving AI technology; it also involves how we better apply these technologies in society. With the development of explainable AI, we can look forward to smarter, more transparent, and more morally responsible AI systems.
## 2. Fundamental Theories of Model Interpretability
### 2.1 Interpretability Issues in Machine Learning
Interpretability in machine learning models refers to the degree to which a model's predictions or decision-making process can be understood and explained by humans. This is a complex and challenging issue in machine learning, especially deep learning, as these models are often considered "black boxes" because their internal mechanisms are opaque.
#### 2.1.1 The Relationship Between Interpretability and Complex Models
Deep learning models are often criticized for lacking interpretability due to their complexity. These models typically contain billions of parameters and learn data representations through multiple levels of abstraction. Despite this, the black-box nature of these models may be acceptable in some cases, such as image recognition tasks where models can accurately identify objects in an image without necessarily knowing how they do so. However, as models are applied in decision support, medical diagnosis, legal judgments, and other critical areas, understanding their internal logic becomes increasingly important.
In some cases, interpretability can be traded off with model performance. For example, simplified models may have an advantage in interpretability but may sacrifice some predictive accuracy. Therefore, finding a balance between model complexity and interpretability is a key issue faced by researchers and practitioners.
#### 2.1.2 The Application of Interpretability in Different Fields
In various fields, interpretability is not just a technical issue but also an important legal and ethical one. For example, in the financial services industry, regulatory agencies may require that the decision-making process of models must be interpretable so that errors can be traced and corrected when they occur. In the medical field, doctors and patients need to understand how models arrive at specific treatment recommendations to promote better decision-making and trust.
Furthermore, the interpretability of models can help researchers and engineers identify and correct biases in models, which is crucial for enhancing the fairness and transparency of the models. Through model interpretability, we can better understand how models handle data from different groups and ensure that models do not unintentionally amplify existing inequalities.
### 2.2 A Comparison Between Interpretable Models and Black-Box Models
Compared to black-box models, the key advantage of interpretable models is that they can provide insights into their predictions, which is crucial for promoting user trust and model transparency.
#### 2.2.1 The Limitations of Black-Box Models
Black-box models are difficult to interpret because their decision-making processes are not intuitive. For example, deep neural networks model data by learning complex nonlinear functions, but these functions are usually difficult to explain intuitively.
The limitations of black-box models are evident in several aspects. First, their prediction results often lack transparency, making it difficult to assess the reliability of their predictions, especially in high-risk decision-making situations. Second, black-box models may contain biases that are difficult to detect because their decisions are based on complex pattern recognition, which may be inconsistent with human intuition and social values. Additionally, when models make errors, it is challenging to identify the root cause and make corrections due to a lack of transparency.
#### 2.2.2 The Advantages of Interpretable Models
Interpretable models, or white-box models, such as decision trees or linear regression, provide a clearer prediction process. The decision-making processes of these models can be described through simple rules or weight coefficients, making it easier for users to understand the model's prediction results.
A significant advantage of interpretable models is that they provide insights into how data affects model decisions, which is crucial for debugging, improving, and verifying models. For example, in medical diagnosis, doctors may need to know how a disease prediction model arrives at its predictions based on various patient indicators so that they can trust and use the model to make decisions.
Moreover, interpretable models help ensure that models do not unintentionally amplify social biases or unfair phenomena. By examining the internal workings of a model, researchers can identify and adjust features or decision rules that may cause bias, thus improving the fairness and accuracy of the model.
In the next chapter, we will delve into four methods to achieve AI interpretability, including feature importance analysis, model visualization techniques, local vs. global interpretation, and model simplification and surrogate models, to deeply understand how to overcome the limitations of black-box models in practical applications and leverage the advantages of interpretable models.
# 3. Four Methods to Achieve AI Interpretability
## 3.1 Feature Importance Analysis
### 3.1.1 Feature Importance Evaluation Methods
Being able to identify which features significantly impact a model's predictions is crucial when building machine learning models. Feature importance evaluation methods typically include the following:
1. **Model-based methods**: These methods usually incorporate feature importance evaluation during the model training process. For example, in the Random Forest algorithm, the importance of features is determined by calculating the average value of feature split information gain.
2. **Permutation-based methods**: For instance, Permutation Feature Importance, which evaluates the importance of features by observing the decline in model performance when a feature value is permuted.
3. **Model explainer-based methods**: Using model explainers such as LIME and SHAP, which can provide local or global explanations for black-box models.
### 3.1.2 The Application of Feature Importance in Decision Making
Feature importance not only helps us understand the model's decision-making process but is also a tool to improve model performance. By removing features with low importance, we can simplify the model, avoid overfitting, and enhance generalization capabilities. In business decisions, feature importance can reveal the underlying drivers behind data, increasing the transparency of decisions.
#### Example Code Block
The following example, using Python, shows how to use the Random Forest model in the Scikit-learn library to evaluate feature importance:
```python
from sklearn.ensemble import RandomForestClassifier
import numpy as np
# Assuming we have a dataset X and labels y
# X, y = load_your_data()
rf = RandomForestClassifier()
rf.fit(X, y)
# Print feature importance
importances = rf.feature_importances_
indices = np.argsort(importances)[::-1]
for f in range(X.sha
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
噪声不再扰:诊断收音机干扰问题与案例分析

# 摘要
收音机干扰问题是影响无线通信质量的关键因素,本文对干扰的理论基础、诊断方法、解决策略、性能维护及未来展望进行了系统探讨。文章首先概述了干扰问题,然后详细分析了干扰信号的分类、收音机信号接收原理以及干扰的来源和传播机制。第三章介绍了有效的干扰问题检测技术和测量参数,并阐述了诊断流程。第四章通过案例分析,提出了干扰问题的解决和预防方法,并展示了成功解决干扰问题的案例。第五章讨论了收音机性能的
企业网络性能分析:NetIQ Chariot 5.4报告解读实战
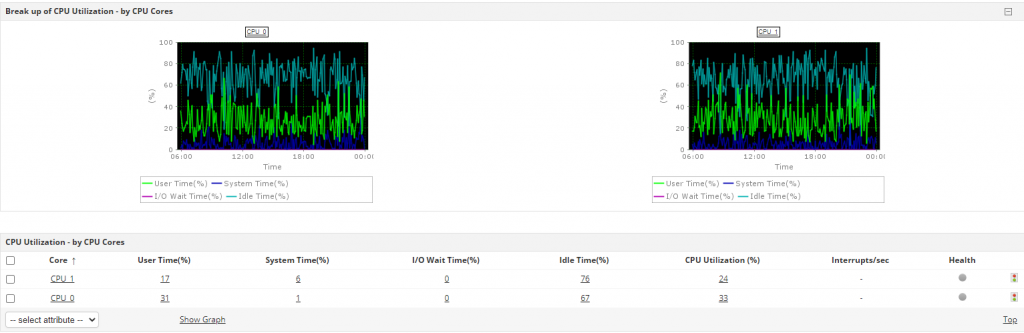
# 摘要
NetIQ Chariot 5.4是一个强大的网络性能测试工具,本文提供了对该工具的全面概览,包括其安装、配置及如何使用它进行实战演练。文章首先介绍了网络性能分析的基础理论,包括关键性能指标(如吞吐量、延迟和包丢失率)和不同性能分析方法(如基线测试、压力测试和持续监控)。随后,重点讨
快速傅里叶变换(FFT)手把手教学:信号与系统的应用实例

# 摘要
快速傅里叶变换(FFT)是数字信号处理领域中的核心算法,它极大地提升了离散傅里叶变换(DFT)的计算效率,使得频谱分析和信号处理变得更加高效。本文首先介绍FFT的基本概念和数学原理,包括连续与离散傅里叶变换的定义及其快速算法的实现方式。随后,文章讨论了在编程语言环境配置和常用FFT库工具的选择,以便为FFT的应用提供必要的工具和环境
【提高PCM测试效率】:最佳实践与策略,优化测试流程
# 摘要
本文全面探讨了PCM测试的重要性和测试流程的理论基础。首先介绍了PCM测试的概念及其在现代测试中的关键作用。随后,深入解析了PCM测试的原理与方法,包括技术的演变历史和核心原理。文章进一步探讨了测试流程优化理论,聚焦于流程中的常见瓶颈及相应的改进策略,并对测试效率的评估指标进行了详尽分析。为提升测试效率,本文提供了从准备、执行到分析与反馈阶段的最佳实
ETA6884移动电源兼容性测试报告:不同设备充电适配真相

# 摘要
移动电源作为一种便携式电子设备电源解决方案,在市场上的需求日益增长。本文首先概述了移动电源兼容性测试的重要性和基本工作原理,包括电源管理系统和充电技术标准。随后,重点分析了ETA6884移动电源的技术规格,探讨了其兼容性技术特征和安全性能评估。接着,本文通过具体的兼容性测试实践,总结了
【Ansys压电分析深度解析】:10个高级技巧让你从新手变专家
# 摘要
本文详细探讨了Ansys软件中进行压电分析的完整流程,涵盖了从基础概念到高级应用的各个方面。首先介绍了压电分析的基础知识,包括压电效应原理、分析步骤和材料特性。随后,文章深入到高级设置,讲解了材料属性定义、边界条件设置和求解器优化。第三章专注于模型构建技巧,包括网格划分、参数化建模和多物理场耦合。第四章则侧重于计算优化方法,例如载荷步控制、收敛性问题解决和结果验证。最后一章通过具体案例展示了高级应用,如传感器设计、能量收集器模拟、超声波设备分析和材料寿命预测。本文为工程技术人员提供了全面的Ansys压电分析指南,有助于提升相关领域的研究和设计能力。
# 关键字
Ansys压电分析;
【计算机科学案例研究】
# 摘要
本文系统地回顾了计算机科学的历史脉络和理论基础,深入探讨了计算机算法、数据结构以及计算理论的基本概念和效率问题。在实践应用方面,文章分析了软件工程、人工智能与机器学习以及大数据与云计算领域的关键技术和应用案例。同时,本文关注了计算机科学的前沿技术,如量子计算、边缘计算及其在生物信息学中的应用。最后,文章评估了计算机科学对社会变革的影响以及伦理法律问题,特别是数据隐
微波毫米波集成电路故障排查与维护:确保通信系统稳定运行

# 摘要
微波毫米波集成电路在现代通信系统中扮演着关键角色。本文首先概述了微波毫米波集成电路的基本概念及其在各种应用中的重要性。接着,深入分析了该领域中故障诊断的理论基础,包括内部故障和外部环境因素的影响。文章详细介绍了故障诊断的多种技术和方法,如信号分析技术和网络参数测试,并探讨了故障排查的实践操作步骤。在第四章中,作者提出了
【活化能实验设计】:精确计算与数据处理秘籍
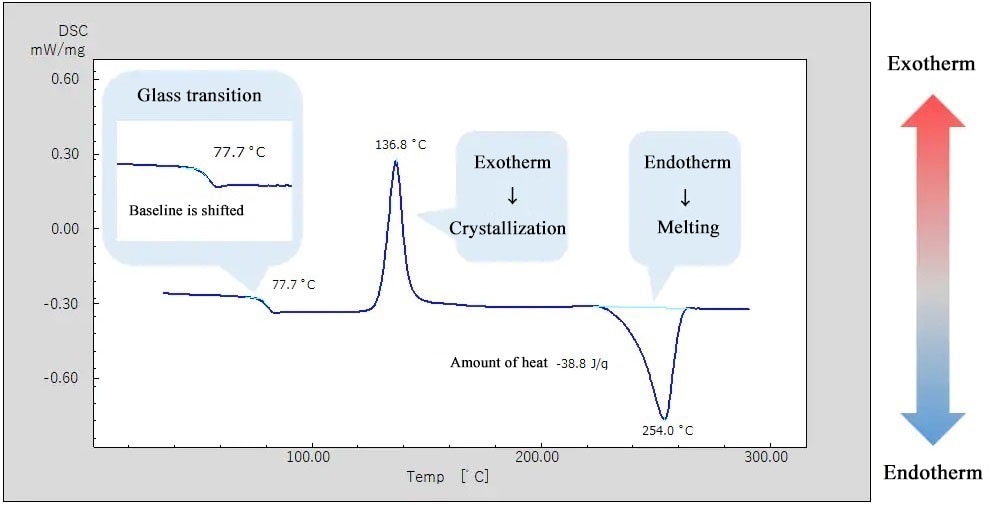
# 摘要
本论文旨在深入分析活化能实验设计的基本科学原理及其在精确测量和计算方面的重要性。文章首先介绍了实验设计的科学原理和实验数据精确测量所需准备的设备与材料。接着,详细探讨了数据采集技术和预处理步骤,以确保数据的高质量和可靠性。第三章着重于活化能的精确计算方法,包括基础和高级计算技术以及计算软件的应用。第四章则讲述了数据处理和
【仿真准确性提升关键】:Sentaurus材料模型选择与分析

# 摘要
本文对Sentaurus仿真软件进行了全面的介绍,阐述了其在材料模型基础理论中的应用,包括能带理论、载流子动力学,以及材料模型的分类和参数影响。文章进一步探讨了选择合适材料模型的方法论,如参数
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )