Real-Time Machine Learning Model Update Strategies: 3 Tips to Keep Your Model Ahead
发布时间: 2024-09-15 11:34:32 阅读量: 33 订阅数: 31 
# Real-Time Machine Learning Model Update Strategies: 3 Techniques to Keep Your Models Ahead
In today's data-driven world, the real-time capability of machine learning models has become a key factor in enhancing corporate competitiveness. With the ongoing evolution of business needs and rapid technological advancements, real-time machine learning models are no longer just an idealized concept but have become an important indicator of an enterprise's level of intelligence.
## 1.1 Definition of Real-Time Machine Learning Models
Real-time machine learning models refer to those that can make predictions or decisions immediately upon the arrival of data. These models are usually deployed in stream processing systems, allowing for rapid responses to data changes, thereby providing immediate insights and behavioral guidance. Unlike traditional batch processing models, real-time models can process data at speeds of microseconds or milliseconds, enabling the system to respond in the shortest possible time.
## 1.2 Importance of Real-Time Machine Learning Models
Real-time machine learning models are crucial for many applications, especially those requiring rapid decision-making support, such as financial services, network monitoring, industrial automation, logistics scheduling, and more. For instance, high-frequency trading systems rely on real-time data to capture market opportunities, while real-time anomaly detection systems can quickly identify and respond to security threats. These use cases illustrate the significant business value and competitive advantages that real-time machine learning models can bring.
# 2. Real-Time Data Stream Processing Mechanism
## 2.1 Concept and Challenges of Real-Time Data Streams
### 2.1.1 Definition of Data Streams
Data streams refer to a series of data items that flow into, are processed, and flow out of a system in a continuous manner. They are characterized by their continuity, speed, and real-time nature. Real-time data stream processing focuses on capturing data instantly, processing it quickly, and generating results to meet real-time business needs. Data streams originate from a wide range of sources, including social networks, sensor networks, financial transactions, and various real-time data sources.
### 2.1.2 Challenges in Data Stream Processing
Due to the high speed of data generation and the need for low-latency processing, real-time data stream processing faces numerous challenges:
- **Speed and Scale**: The high-speed generation of data streams requires processing systems to have extremely high throughput and low-latency response capabilities.
- **Data Consistency**: Data must maintain consistency during streaming processing to ensure the accuracy of processing results.
- **System Resilience**: The system needs to be able to弹性adjust resources to maintain stable operation in the face of surges or fluctuations in data traffic.
- **Fault Tolerance**: Data processing systems must be able to handle various exceptional situations, ensuring the continuity of data streams.
## 2.2 Data Stream Processing Frameworks and Technologies
### 2.2.1 Overview of Stream Processing Frameworks
There are many stream processing frameworks with their own strengths and weaknesses. Popular ones include Apache Kafka, Apache Flink, Apache Storm, and more.
- **Apache Kafka**: Primarily used for building real-time data pipelines and streaming applications, it processes data streams through a publish-subscribe model.
- **Apache Flink**: An open-source streaming framework that supports high throughput and low-latency data processing, with capabilities for event-time processing and state management.
- **Apache Storm**: A distributed real-time computation system that supports multiple programming languages and can reliably process large volumes of data streams.
### 2.2.2 Key Technology Analysis
Key streaming processing technologies include:
- **Event-Time Processing**: Managing the difference between processing time order and event occurrence time to ensure data is ordered correctly.
- **State Management**: Managing state information during streaming processing, such as window calculations, joins, and aggregation operations.
- **Fault Tolerance and Recovery**: Ensuring that processing systems can quickly recover from failures through snapshots, logging, and other mechanisms.
## 2.3 Real-Time Monitoring and Management of Data Streams
### 2.3.1 Real-Time Monitoring Strategies
Real-time monitoring is a crucial aspect of ensuring the stable operation of data stream processing systems. Effective monitoring strategies include:
- **Performance Metric Monitoring**: Real-time monitoring of system performance metrics such as CPU usage, memory consumption, and latency.
- **Data Quality Monitoring**: Checking data streams for anomalies and missing values to ensure data accuracy.
- **Health Status Checks**: Monitoring the health of system components, such as whether stream processing tasks are running normally.
### 2.3.2 Data Quality Management
Data quality management needs to be controlled throughout the lifecycle, from the source to the processing. Main measures include:
- **Data Cleaning**: Cleaning data before processing to remove duplicate and erroneous records.
- **Data Validation**: Applying data rules to incoming data streams to ensure consistency and integrity.
- **Data Visualization**: Displaying key indicators of data streams through charts or dashboards to assist in decision-making.
```mermaid
graph LR
A[Data Source] --> B[Data Cleaning]
B --> C[Data Validation]
C --> D[Data Processing]
D --> E[Real-Time Monitoring]
E --> F[Data Visualization]
```
Next, we will delve into the theoretical foundations of real-time machine learning model update mechanisms and combine theory with practice to explore the future development directions of real-time machine learning models.
# 3. Theoretical Foundations of Model Update Mechanisms
## 3.1 Motivation and Objectives for Model Updates
### 3.1.1 Why Update Models
In rapidly changing data environments, machine learning models can quickly become outdated. User behavior, market trends, technological advancements, and various other factors change over time. Therefore, to maintain the relevance and accuracy of models, regular updates are essential.
The degradation of model performance may be obvious, such as through reduced prediction accuracy or more frequent incorrect classifications. However, performance decline can sometimes be subtle and may require regular monitoring and evaluation to detect. Since this decline typically occurs gradually, it may be overlooked for an extended period. To avoid this, a proactive model update strategy is needed.
Moreover, new data may bring new patterns and trends, and only through regular model updates can these be learned and adapted to. In some applications, such as financial risk assessment or medical diagnosis, the accuracy requirements for models are extremely high, and neglecting timely model updates could lead to serious consequences.
### 3.1.2 Objectives and Principles of Model Updates
The goal of updating models is to maintain or improve their performance while considering costs and operability. This means that update plans need to be carefully designed to ensure models can respond quickly to new data without causing significant disruption to existing workflows.
In the process of updating models, the following principles should be followed:
- **Minimize Downtime**: It is crucial to update models without impacting service, especially in high-traffic online systems.
- **Data Integrity**: Ensure data consistency and integrity during updates to avoid fluctuations in model performance due to data issues.
- **Balance between Automation and Manual Intervention**: While automation can accelerate the update process, in some cases, manual intervention may be needed to ensure models are updated as expected.
In practice, these principles need to be flexibly applied in combination with specific business needs and the environment in which models are used.
## 3.2 Cycle and Strategies for Model Updates
### 3.2.1 Methods for Determining Update Cycles
Determining the optimal model update cycle is key to achieving continuous model improvement. This cycle may be determined by various factors, such as the speed of data change, business needs, and model complexity.
- **Performance-Based Methods**: Monitor model performance metrics, and when these metrics fall below a certain threshold, update the model. Performance metrics can include accuracy, F1 score, recall, and more.
- **Time-Based Methods**: Update the model at fixed time intervals, such as weekly, monthly, or quarterly, regardless of model performance.
- **Event-Based Methods**: Update the model after certain events occur, such as the release of a new dataset or changes in business strategy.
Choosing the appropriate update cycle requires considering the model's performance and needs in specific application scenarios. In some cases, it may be necessary to combine multiple methods to determine the optimal update frequency.
### 3.2.2 Comparison and Selection of Different Update Strategies
Different update strategies have their own advantages and limitations, and the selection of an appropriate strategy requires a comprehensive consideration of model stability, business needs, and resource availability.
- **Offline Updates**: This is a traditional approach where models are fully retrained and validated in an offline environment. The advantage of this strategy is its simplicity and directness, but it may result in longer downtime and higher resource requirements.
- **Online Updates**: Online updates mean that models can accept new training data in real-time and self-improve. This approach can minimize downtime and quickly adapt to new data patterns, but it may increase system complexity.
- **Incremental Updates**: In this strategy, only a portion of the model's parameters is updated each time, rather than the entire model. This helps save resources and speed up updates, but it may affect model performance due to insufficient parameter updates.
Considering the potential impact of update strategies on business and the complexity of actual operations, it is often necessary to conduct multiple experiments to find the best update strategy.
## 3.3 Model Version Control and Rollback Mechanisms
### 3.3.1 Importance of Version Control
Model version control is similar to version control in software development, tracking changes to models over time, preserving details of each version, and allowing developers to roll back to earlier versions when necessary.
The importance of model version control is reflected in several aspects:
- **Auditing and Tracing**: When models encounter issues, it allows for rapid location and rollback to a previous stable version.
- **Experiment Management**: Facilitates the management of various model versions during experiments, comparing performance differences between different versions.
- **Team Collaboration**: In multi-person teams, model version control can prevent chaos and ensure consistency in team members' work.
Model version control usually requires a system similar to Git to record and manage different model versions, their dependencies, and code change history.
### 3.3.2 Design and Implementation of Rollback Strategies
Rollback is an important part of model version control, allowing for rapid recovery to a previous state when model performance declines or new errors are introduced. Designing an effective rollback strategy is crucial.
Rollback strategy design should consider the following:
- **Clear Rollback Criteria**: There should be clear rollback conditions, such as w

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【KEBA机器人高级攻略】:揭秘行业专家的进阶技巧

# 摘要
本论文对KEBA机器人进行全面的概述与分析,从基础知识到操作系统深入探讨,特别关注其启动、配置、任务管理和网络连接的细节。深入讨论了KEBA机器人的编程进阶技能,包括高级语言特性、路径规划及控制算法,以及机器人视觉与传感器的集成。通过实际案例分析,本文详细阐述了KEBA机器人在自动化生产线、高精度组装以及与人类协作方面的应用和优化。最后,探讨了KEBA机器人集成
【基于IRIG 106-19的遥测数据采集】:最佳实践揭秘
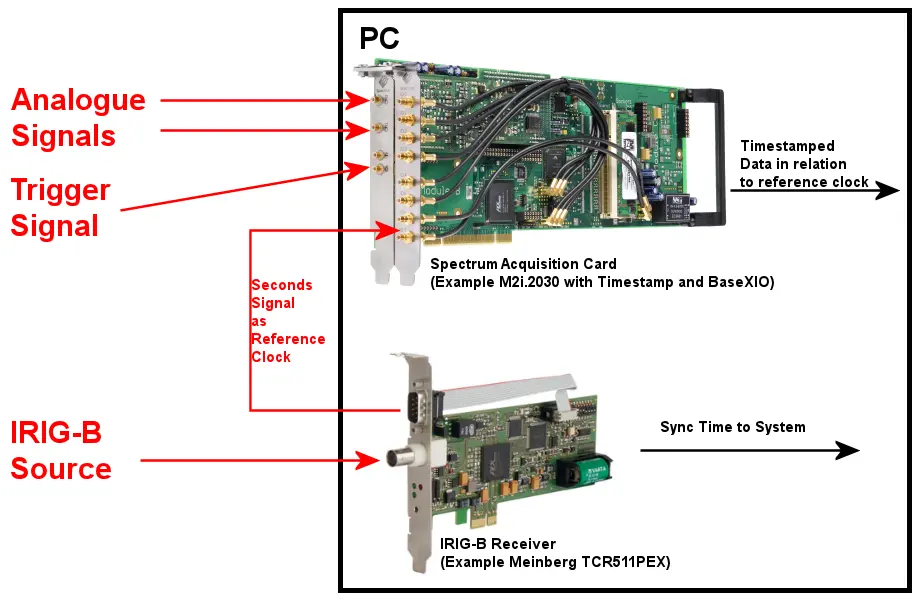
# 摘要
本文系统地介绍了IRIG 106-19标准及其在遥测数据采集领域的应用。首先概述了IRIG 106-19标准的核心内容,并探讨了遥测系统的组成与功能。其次,深入分析了该标准下数据格式与编码,以及采样频率与数据精度的关系。随后,文章详细阐述了遥测数据采集系统的设计与实现,包括硬件选型、软件框架以及系统优化策略,特别是实时性与可靠
【提升设计的艺术】:如何运用状态图和活动图优化软件界面
# 摘要
本文系统地探讨了状态图和活动图在软件界面设计中的应用及其理论基础。首先介绍了状态图与活动图的基本概念和组成元素,随后深入分析了在用户界面设计中绘制有效状态图和活动图的实践技巧。文中还探讨了设计原则,并通过案例分析展示了如何将这些图表有效地应用于界面设计。文章进一步讨论了状态图与活动图的互补性和结合使用,以及如何将理论知识转化为实践中的设计过程。最后,展望了面向未来的软
台达触摸屏宏编程故障不再难:5大常见问题及解决策略

# 摘要
台达触摸屏宏编程是一种为特定自动化应用定制界面和控制逻辑的有效技术。本文从基础概念开始介绍,详细阐述了台达触摸屏宏编程语言的特点、环境设置、基本命令及结构。通过分析常见故障类型和诊断方法,本文深入探讨了故障产生的根源,包括语法和逻辑错误、资源限制等。针对这
构建高效RM69330工作流:集成、测试与安全性的终极指南

# 摘要
本论文详细介绍了RM69330工作流的集成策略、测试方法论以及安全性强化,并展望了其高级应用和未来发展趋势。首先概述了RM69330工作流的基础理论与实践,并探讨了与现有系统的兼容性。接着,深入分析了数据集成的挑战、自动化工作流设计原则以及测试的规划与实施。文章重点阐述了工作流安全性设计原则、安全威胁的预防与应对措施,以及持续监控与审计的重要性。通过案例研究,展示了RM
Easylast3D_3.0速成课:5分钟掌握建模秘籍

# 摘要
Easylast3D_3.0是业界领先的三维建模软件,本文提供了该软件的全面概览和高级建模技巧。首先介绍了软件界面布局、基本操作和建模工具,然后深入探讨了材质应用、曲面建模以及动画制作等高级功能。通过实际案例演练,展示了Easylast3D_3.0在产品建模、角色创建和场景构建方面的应用。此外,本文还讨
【信号完整性分析速成课】:Cadence SigXplorer新手到专家必备指南
# 摘要
本论文旨在系统性地介绍信号完整性(SI)的基础知识,并提供使用Cadence SigXplorer工具进行信号完整性分析的详细指南。首先,本文对信号完整性的基本概念和理论进行了概述,为读者提供必要的背景知识。随后,重点介绍了Cadence SigXplorer界面布局、操作流程和自定义设置,以及如何优化工作环境以提高工作效率。在实践层面,论文详细解释了信号完整性分析的关键概念,包括信号衰
高速信号处理秘诀:FET1.1与QFP48 MTT接口设计深度剖析
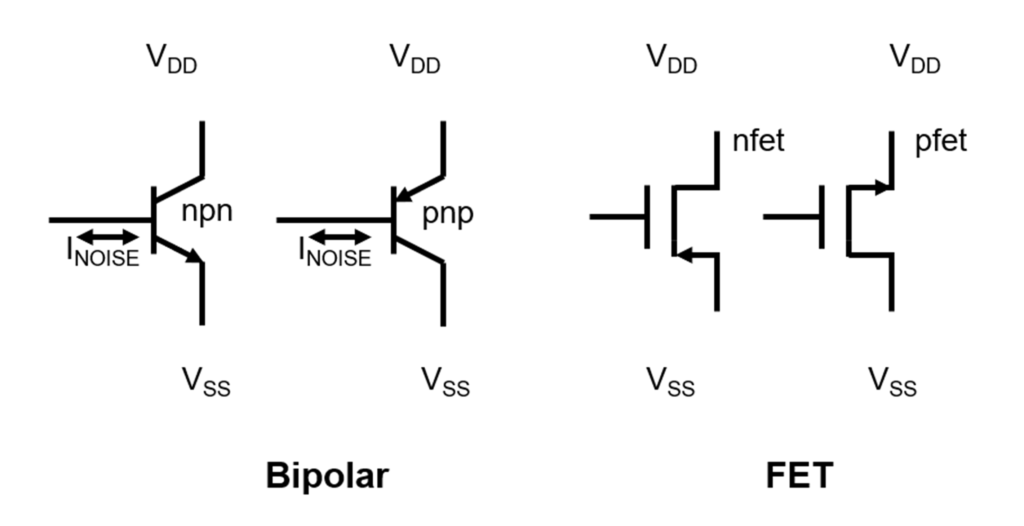
# 摘要
高速信号处理与接口设计在现代电子系统中起着至关重要的作用,特别是在数据采集、工业自动化等领域。本文首先概述了高速信号处理与接口设计的基本概念,随后深入探讨了FET1.1接口和QFP48 MTT接口的技术细节,包括它们的原理、硬件设计要点、软件驱动实现等。接着,分析了两种接口的协同设计,包括理论基础、
【MATLAB M_map符号系统】:数据点创造性表达的5种方法

# 摘要
本文详细介绍了M_map符号系统的基本概念、安装步骤、符号和映射机制、自定义与优化方法、数据点创造性表达技巧以及实践案例分析。通过系统地阐述M_map的坐标系统、个性化符号库的创建、符号视觉效果和性能的优化,本文旨在提供一种有效的方法来增强地图数据的可视化表现力。同时,文章还探讨了M_map在科学数据可视化、商业分析及教育领域的应用,并对其进阶技巧和未来的发展趋势提出了预测和建议。
物流监控智能化:Proton-WMS设备与传感器集成解决方案
# 摘要
物流监控智能化是现代化物流管理的关键组成部分,有助于提高运营效率、减少错误以及提升供应链的透明度。本文概述了Proton-WMS系统的架构与功能,包括核心模块划分和关键组件的作用与互动,以及其在数据采集、自动化流程控制和实时监控告警系统方面的实际应用。此外,文章探讨了设备与传感器集成技术的原理、兼容性考量以及解决过程中的问题。通过分析实施案例,本文揭示了Proton-WMS集成的关键成功要素,并讨论了未来技术发展趋势和系统升级规划,
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )