Advanced Feature Engineering Techniques: 10 Methods to Power Up Your Models
发布时间: 2024-09-15 11:26:11 阅读量: 38 订阅数: 42 
# Advanced Feature Engineering Techniques: 10 Methods to Power Up Your Model
In the realm of machine learning and data analysis, feature engineering is the process of transforming raw data into features that can be used to train efficient learning models. It is a critical step in improving model predictive performance, involving the understanding, transformation, selection, and optimization of data. Effective feature engineering can extract key information, simplify problem complexity, and enhance the efficiency and accuracy of algorithms. This chapter will introduce the basic concepts and core elements of feature engineering, laying the foundation for an in-depth exploration of advanced feature engineering techniques for different types of data in subsequent chapters.
## 1.1 The Importance of Feature Engineering
In practical applications, raw data often cannot be directly used for machine learning models. Data may contain noise, missing values, or inconsistent formats. The primary task of feature engineering is data cleaning and preprocessing to ensure data quality and consistency. In addition, selecting the most explanatory features for the problem can effectively improve model training efficiency and predictive accuracy. For instance, in image recognition tasks, extracting advanced features such as edges and textures from pixel data can better assist classifiers in understanding image content.
## 1.2 The Main Steps of Feature Engineering
Feature engineering typically includes the following core steps:
- Data preprocessing: including data cleaning, normalization, encoding, etc.
- Feature selection: selecting features that help improve model performance from many features.
- Feature construction: creating new features by combining or transforming existing ones.
- Feature extraction: using statistical and mathematical methods to extract information-rich new feature sets from the data.
- Feature evaluation: evaluating the effectiveness and importance of features, providing a basis for feature selection.
Through these steps, we can transform raw data into a high-quality feature set, laying a solid foundation for subsequent model training and testing. Next, we will delve into advanced methods of feature extraction, further revealing the technical details and application scenarios behind feature engineering.
# 2. Advanced Methods of Feature Extraction
Feature extraction is one of the core links in feature engineering, which includes extracting useful information from the original data to form a feature set that can characterize the data properties. This process usually requires the use of statistical methods, model evaluation techniques, and creatively constructing new features.
### 2.1 Statistical-Based Feature Extraction
Statistics provide powerful tools to identify patterns in data, among which entropy and information gain, as well as Principal Component Analysis (PCA), are two commonly used methods.
#### 2.1.1 Applications of Entropy and Information Gain
Entropy is a statistical measure of the disorder of data. In information theory, entropy is used to measure the uncertainty of data. In feature extraction, we usually use information gain to select features. The greater the information gain, the closer the relationship between the feature and the label, and the more helpful it is to extract the feature for classification tasks.
```python
from sklearn.feature_selection import mutual_info_classif
# Assuming X is the feature matrix and y is the label vector
# Use mutual information method to calculate feature selection scores
mi_scores = mutual_info_classif(X, y)
```
The above code uses the scikit-learn library to calculate the mutual information of features, which helps to evaluate the mutual dependence between features and labels. Mutual information is a measure of the interrelation between variables, which is very effective for classification problems. During feature selection, features with higher mutual information values can be chosen.
#### 2.1.2 In-depth Understanding of Principal Component Analysis (PCA)
Principal Component Analysis (PCA) is another powerful feature extraction method. It transforms possibly correlated variables into a set of linearly uncorrelated variables through an orthogonal transformation, known as the principal components. The key to PCA is that it can reduce the dimensionality of data while preserving the most important information, with minimal loss.
```python
from sklearn.decomposition import PCA
import numpy as np
# Assuming X is the normalized feature matrix
pca = PCA(n_components=2) # Retain two principal components
X_pca = pca.fit_transform(X)
```
In the above code, PCA is used for dimensionality reduction. By setting the `n_components` parameter, you can specify the number of principal components to retain. In practical applications, the number of principal components to retain needs to be decided based on the percentage of explained variance. Generally, the principal components that contribute to more than 80% or 90% of the cumulative contribution rate are selected as the feature set after dimensionality reduction.
### 2.2 Model-Based Feature Selection
Model evaluation metrics are directly related to feature selection methods because they provide standards for evaluating the importance of features.
#### 2.2.1 Model Evaluation Metrics and Feature Selection
Model evaluation metrics such as accuracy, recall, F1 score, etc., provide methods for measuring model performance. During the feature selection phase, we can use the scores of these metrics to determine which features are more helpful in improving model performance.
```python
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import RandomForestClassifier
# Assuming X is the feature matrix and y is the label vector
rf = RandomForestClassifier()
scores = cross_val_score(rf, X, y, cv=5)
# Output the average cross-validation score
print("Average cross-validation score:", np.mean(scores))
```
Here, the Random Forest classifier and cross-validation are used to evaluate the feature set. By comparing the performance of models containing different feature sets, we can determine which features are beneficial for model prediction.
#### 2.2.2 Evaluation of Feature Importance Based on Tree Models
Tree models such as decision trees and random forests can provide a measure of feature importance. These models can be used to evaluate the contribution of each feature to the prediction result, thereby achieving model-based feature selection.
```python
importances = rf.feature_importances_
indices = np.argsort(importances)[::-1]
# Print feature importance
for f in range(X.shape[1]):
print("%d. feature %d (%f)" % (f + 1, indices[f], importances[indices[f]]))
```
In the above code snippet, we use the `feature_importances_` attribute of the Random Forest model to view the importance of each feature. Features are sorted by importance, which is very useful for selectively retaining or discarding certain features.
### 2.3 Generation and Application of Combined Features
New features can be generated by combining existing features, capturing the interaction between data.
#### 2.3.1 The Role of Polynomial Features and Cross Features
Polynomial features and cross features are created through the product and power combination of original features. This can increase the model's ability to express complex relationships.
```python
from sklearn.preprocessing import PolynomialFeatures
# Assuming X is the feature matrix
poly = PolynomialFeatures(degree=2, include_bias=False)
X_poly = poly.fit_transform(X)
```
In this code, polynomial features are generated using the `PolynomialFeatures` class, which can create quadratic polynomial combinations of the original features, including the squared terms of individual features. This feature generation method is often used in scenarios where data relationships are believed to be nonlinear.
#### 2.3.2 New Feature Generation Based on Feature Construction
Based on domain knowledge, new features can sometimes be constructed, and such features often significantly improve performance. For example, for time series data, statistical measures of sliding windows can be constructed as features; for text data, features can be constructed through word frequency, sentence length, etc.
```python
# Assuming X is the feature matrix and X_new is the newly constructed feature matrix
X_new = np.hstack([X, X_poly]) # Combine polynomial features with original features
```
By merging the original features with polynomial features, we obtain a richer feature set, which can provide more information in machine learning models, helping to improve the predictive power of the model.
In this chapter, we introduced statistical-based feature extraction methods and how to select features using model evaluation metrics and tree-based methods. We also explored the generation of combined features, including polynomial features and the construction of new features. In the process of feature extraction, mastering and applying these methods can greatly enhance the expressive power of data and lay a solid foundation for subsequent model training.
# 3. Feature Transformation and Normalization Techniques
In the practice of machine learning and data science, feature transformation and normalization are crucial steps. This helps ensure that the model can learn the structure of the data better, while avoiding numerical problems, such as gradient vanishing or gradient explosion. This chapter will delve into nonlinear transformation methods, feature scaling techniques, and feature encoding strategies, putting data in the most suitable state for model learning.
## 3.1 Nonlinear Transformation Methods
### 3.1.1 Power Transform and Box-Cox Transform
In data preprocessing, the power transform is a common method that changes the data distribution by applying a power function, improving the normality of data, thereby enhancing model performance. The formula for the power transform can be expressed as:
\[ Y = X^{\lambda} \]
where, \( \lambda \) is the transformation parameter, which can be estimated by maximizing the log-likelihood function, suitable for continuous variables.
Box-Cox transform is an extension of the power transform, designed to address the situation where there are non-positive numbers in the data. Its transformation formula is as follows:
\[ Y = \begin{cases}
\frac{X^\lambda - 1}{\lambda} & \text{if } \lambda \neq 0 \\
\log(X) & \text{if } \lambda = 0
\end{cases} \]
where, \( \lambda \) is a parameter estimated by maximizing the data's log-likelihood function. If the data contains zeros or negative numbers, the data must first be shifted to make it positive.
### 3.1.2 Applications of Logarithmic and Exponential Transformations
Logarithmic and exponential transformations are special forms of power transforms, particularly useful when data exhibits a skewed distribution, helping to reduce data skewness.
The logarithmic transformation is commonly used to compress larger values and expand smaller ones, helping to balance the data distribution:
\[ Y = \log(X) \]
It is particularly useful when dealing with financial and economic time series data, helping to stabilize data variance.
The exponential transformation is the inverse operation of the logarithmic transformation, used when the data集中 contains negative numbers or zeros:
\[ Y = \exp(X) \]
It is commonly used for inverse power transformations in data, such as in time series forecasting and biostatistics.
## 3.2 Feature Scaling Techniques
### 3.2.1 Min-Max Normalization and Z-score Standardization
The scale of data usually significantly affects model performance, so feature scaling is a necessary step before algorithm training.
Min-Max normalization scales the features to a fixed range, usually the [0,1] interval:
\[ X_{\text{norm}} = \frac{X - X_{\text{min}}}{X_{\text{max}} - X_{\text{min}}} \]
This method is simple and prese

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
GSP TBC高级技巧:效率飞跃的五大策略
# 摘要
本文旨在提升GSP TBC的效率,并从理论到实践对其进行全面概述。首先,介绍了GSP TBC的基本概念、原理及关键因素,奠定了理论基础。随后,阐述了策略设计的原则、步骤和案例分析,提供了实施GSP TBC的策略框架。在实践应用方面,本文详细讨论了实战策略的选择、应用和效果评估,以及优化技巧的原理、方法和案例。进阶技巧部分着重于数据分析和自动化的理论、方法和实践应用。最后,对未来GSP TBC的发展趋势和应用前景进行了探讨,提供了对行业发展的深度见解。整体而言,本文为GSP TBC的理论研究和实际应用提供了详实的指导和展望。
# 关键字
GSP TBC;效率提升;理论基础;实践应用;
【算法设计与数据结构】:李洪伟教授的课程复习与学习心得

# 摘要
本文对算法与数据结构进行了全面的概述和分析。首先介绍了基础数据结构,包括线性结构、树形结构和图结构,并探讨了它们的基本概念、操作原理及应用场景。随后,深入探讨了核心算法原理,包括排序与搜索、动态规划、贪心算法以及字符串处理算法,并对它们的效率和适用性进行了比较。文章还涉及了算法设计中的技巧与优化方法,重点在于算法复杂度分析、优化实践以及数学工具的应用。最后,通过案例分析和项目实践,展
【实用型】:新手入门到老手精通:一步到位的TI-LMP91000模块编程教程
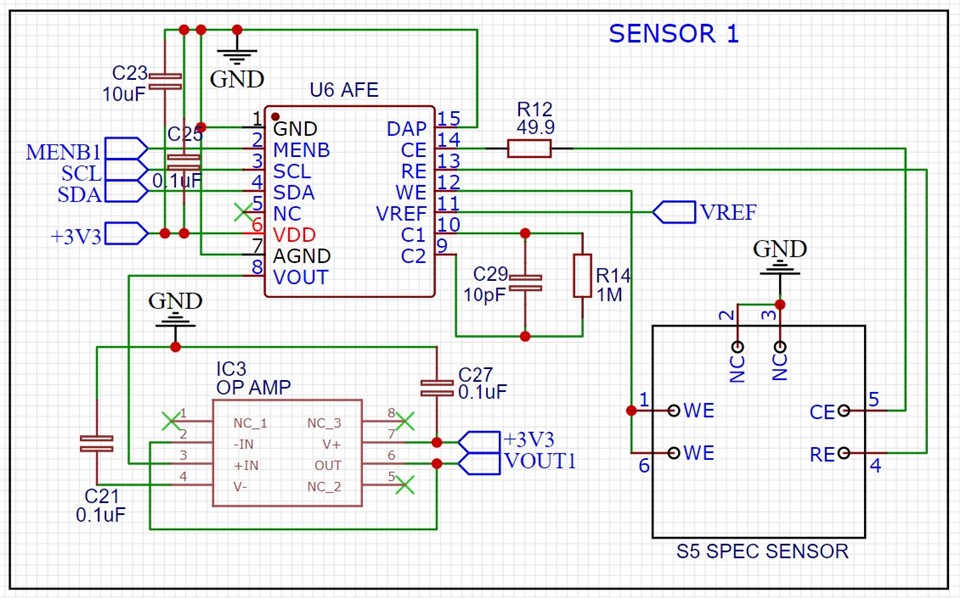
# 摘要
本文系统介绍了TI-LMP91000模块的基础知识、硬件操作、编程基础以及高级应用。首先,文章对TI-LMP91000模块进行了基础介绍,并详细阐述了其硬件操作,包括硬件连接初始化、模拟信号输入输出处理以及数字接口的应用。接着,本文聚
【SUSE Linux系统优化】:新手必学的15个最佳实践和安全设置
# 摘要
本文详细探讨了SUSE Linux系统的优化方法,涵盖了从基础系统配置到高级性能调优的各个方面。首先,概述了系统优化的重要性,随后详细介绍了基础系统优化实践,包括软件包管理、系统升级、服务管理以及性能监控工具的应用。接着,深入到存储与文件系统的优化,讲解了磁盘分区、挂载点管理、文件系统调整以及LVM逻辑卷的创建与管理。文章还强调了网络性能和安全优化,探讨了网络配置、防火墙设置、
企业微信服务商营销技巧:提高用户粘性

# 摘要
随着移动互联网和社交平台的蓬勃发展,企业微信营销已成为企业数字化转型的重要途径。本文首先概述了企业微信营销的基本概念,继而深入分析了提升用户粘性的理论基础,包括用户粘性的定义、重要性、用户行为分析以及关键影响因素。第三章探讨了企业微信营销的实战技巧,重点介绍了内容营销、互动营销和数据分析在提升营销效果中的应用。第四章通过分析成功案例和常见问题,提供营销实践中的策略和解决方案。最后,第五章展望了技术创新和市场适应性对微信营销未来趋势的
UG Block开发进阶:掌握性能分析与资源优化的秘技

# 摘要
UG Block作为一种在UG软件中使用的功能模块,它的开发和应用是提高设计效率和质量的关键。本文从UG Block的基本概念出发,详述了其基础知识、创建、编辑及高级功能,并通过理论与实践相结合的方式,深入分析了UG Block在性能分析和资源优化方面的重要技巧
TIMESAT案例解析:如何快速定位并解决性能难题

# 摘要
本文从理论基础出发,详细探讨了性能问题定位的策略和实践。首先介绍了性能监控工具的使用技巧,包括传统与现代工具对比、性能指标识别、数据收集与分析方法。随后深入剖析 TIMESAT 工具,阐述其架构、工作原理及在性能监控中的应用。文章进一步讨论了性能优化的原则、实践经验和持续过程,最后通过综合案例实践,展示了如何应用 TIMESAT 进行性能问题分析、定位、优
低位交叉存储器深度探究:工作机制与逻辑细节

# 摘要
本文系统地介绍了低位交叉存储器的基本概念、工作原理、结构分析以及设计实践。首先阐述了低位交叉存储器的核心概念和工作原理,然后深入探讨了其物理结构、逻辑结构和性能参数。接着,文中详细说明了设计低位交叉存储器的考虑因素、步骤、流程、工具和方法。文章还通过多个应用案例,展示了低位交叉存储器在计算机系统、嵌入式系统以及服务器与存储设备中的实际应用。最后,
系统分析师必学:如何在30天内掌握单头线号检测

# 摘要
单头线号检测作为工业自动化领域的重要技术,对于确保产品质量、提高生产效率具有显著作用。本文首先概述了单头线号检测的概念、作用与应用场景,随后详细介绍了其关键技术和行业标准。通过对线号成像技术、识别算法以及线号数据库管理的深入分析,文章旨在为业界提供一套系统的实践操作指南。同时,本文还探讨了在实施单头线号检测过程中可能遇到的问题和相应的解决方案,并展望了大数据与机器学习在该领域的应用前景。文章最终通过行业成功案例
Flink1.12.2-CDH6.3.2容错机制精讲:细节与原理,确保系统稳定运行
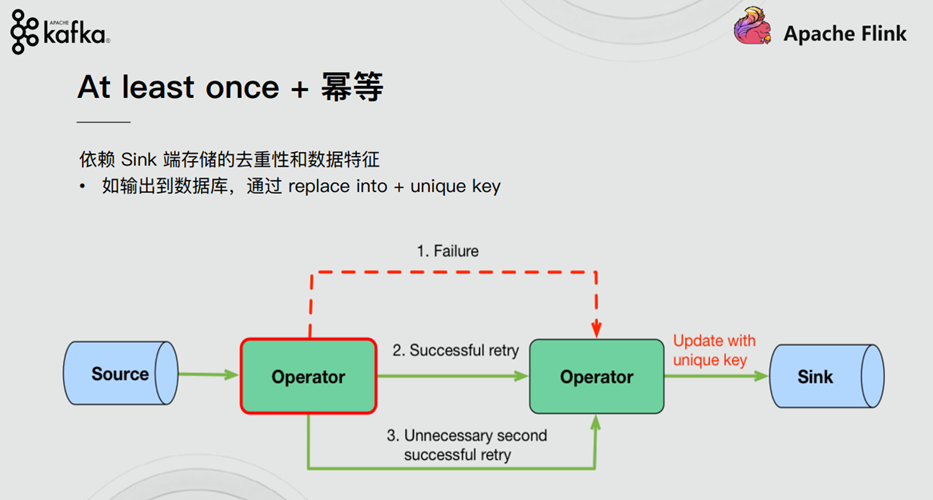
# 摘要
Flink容错机制是确保大规模分布式数据流处理系统稳定运行的关键技术。本文首先概述了Flink的容错机制,接着深入探讨了状态管理和检查点机制,包括状态的定义、分类、后端选择与配置以及检查点的原理和持久化策略。随后,文章分析了故障类型和恢复策略,提出了针对不同类型故障的自动与手动恢复流程,以及优化技术。在实践应用部分,本文展示了如何配置和优化检查点以及
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )