Best Practices for Model Deployment: 5 Steps to Ensure Your Model Runs Steadily
发布时间: 2024-09-15 11:29:51 阅读量: 34 订阅数: 32 

BRK2255 - OneNote best practices for your organization.pptx
# Model Deployment Best Practices: 5 Steps to Ensure Stable Model Operation
## Overview
Model deployment is the essential process of transforming machine learning models into actual applications. It is a critical step in the entire model lifecycle, involving careful considerations of technology, tools, and processes.
## Importance
The quality of the deployment process directly affects the performance and scalability of the model. A good deployment strategy ensures that the model runs stably in different environments and meets the business needs for real-time processing and resource efficiency.
## Key Steps
Pre-deployment preparations include model testing, optimization, and security evaluation. Specific operations involve model format conversion, performance optimization, and adaptability testing for both hardware and software environments.
```markdown
### Model Format Conversion Example
Before deployment, it is often necessary to convert the model from one format to another to accommodate different runtime environments. For instance, converting a trained TensorFlow model to the ONNX format to adapt to edge computing devices.
```python
import onnx
import tensorflow as tf
# Load TensorFlow model
model = tf.keras.models.load_model('path/to/your/model.h5')
# Convert the model to ONNX
tf_rep = tf2onnx.convert.from_keras(model)
onnx.save(tf_rep, 'model.onnx')
```
### Hardware Acceleration Technologies
For applications requiring high-performance computing, hardware acceleration technologies like GPUs, TPUs, or FPGA chips can provide significant speed improvements during model deployment.
```markdown
## Code Explanation
### Performance Optimization Strategies
Performance optimization strategies may include but are not limited to:
- Model pruning and compression to reduce computation
- Utilization of hardware acceleration technologies, such as GPUs
- Software optimization methods, such as quantization and parallel computing
- Compatibility testing to ensure consistent model behavior across environments
### Identifying Compatibility Issues
Compatibility issues might include:
- Incompatibilities between the model and the target platform versions
- Missing or inconsistent dependencies required for the model's runtime environment
These issues typically require identification and resolution through a detailed testing process.
```
In subsequent chapters, we will explore how to prepare and optimize models for deployment, the specifics of setting up the deployment environment, and how to monitor and maintain models. Each part is a critical element in achieving successful deployment, providing IT professionals with in-depth theoretical and practical guidance.
# 2. Model Preparation and Optimization
## 2.1 Preparations for the Model
### 2.1.1 Model Pruning and Compression
Model pruning and compression are key steps in optimizing the size of machine learning models and improving their operational efficiency. Model pruning involves removing redundant or unimportant parameters, while model compression includes applying specific techniques to reduce the overall size of the model. These methods help reduce the computational complexity of the model, lower storage requirements, and maintain performance as much as possible.
- **Pruning**
- **Technical Principle**: Reduces model complexity by removing certain connections with smaller weights in the neural network, retaining only those connections that most affect the model's performance.
- **Operational Steps**: First determine the pruning ratio, ***mon methods include L1 regularization and sensitivity-based pruning.
- **Weight Sharing**
- **Technical Principle**: By sharing weights, multiple neurons use the same parameters to reduce the number of model parameters.
- **Operational Steps**: Analyze the model structure to find layers that can share weights and then modify the network structure to allow these layers' weights to be shared by all relevant neurons.
- **Quantization**
- **Technical Principle**: Converts model weights and activations from floating-point representations to lower precision representations (like integers) to reduce the model size and computational requirements.
- **Operational Steps**: Use a series of algorithms to map floating-point values to a smaller range of bit values. Quantization-aware training is typically used during the training process to adapt the model to quantized weights.
For example, here is how to perform simple pruning using the `torch` library in Python code:
```python
import torch
# Assume net is a pretrained model
def prune_model(net, amount_to_prune=0.1):
# For each layer
for name, module in net.named_children():
# This is just an example; in practice, weights would be selected based on size
if len(module.weight) > 100 and 'conv' in name:
# Select the smallest weights for pruning
prune_target = module.weight.data.abs().argmin()
prune_amount = int(amount_to_prune * len(module.weight))
module.weight.data = torch.cat((module.weight.data[:prune_target],
module.weight.data[prune_target + prune_amount:]))
print(f'Pruning {prune_amount} weights from layer {name}')
return net
```
### 2.1.2 Model Format Conversion
Converting trained models into deployment-ready formats such as ONNX, TensorRT, or OpenVINO not only optimizes model performance but also enhances deployment flexibility.
- **ONNX (Open Neural Network Exchange)**
- **Technical Principle**: ONNX provides a common format that allows model conversion between different deep learning frameworks.
- **Operational Steps**: Use the tools provided by the framework, such as `torch.onnx.export`, to export the model to ONNX format.
- **TensorRT**
- **Technical Principle**: Offered by NVIDIA, TensorRT optimizes models through techniques like layer fusion and kernel auto-tuning.
- **Operational Steps**: Use the TensorRT API to optimize and serialize the model.
- **OpenVINO**
- **Technical Principle**: Provided by Intel, OpenVINO optimizes deep learning models to run on Intel hardware.
- **Operational Steps**: Use the Model Optimizer to convert the model into IR (Intermediate Representation), then deploy with the Inference Engine.
## 2.2 Model Performance Optimization Strategies
### 2.2.1 Hardware Acceleration Technologies
Hardware acceleration technologies, such as GPU acceleration, TPU usage, and specialized hardware like FPGAs and ASICs, can greatly enhance the computational performance of machine learning models.
- **GPU Acceleration**
- **Technical Principle**: Uses GPUs for parallel computing, significantly improving efficiency in scenarios with large data volumes and complex operations.
- **Operational Steps**: Construct and train models using deep learning frameworks that support GPU acceleration (such as TensorFlow or PyTorch).
- **TPU (Tensor Processing Unit)**
- **Technical Principle**: A processor developed by Google, optimized specifically for machine learning tasks.
- **Operational Steps**: When using TensorFlow, specify TPUs as the computing resource for model training and inference.
### 2.2.2 Software Optimization Methods
At the software level, improving model performance through algorithm selection, optimization, and code-level optimization is also crucial.
- **Algorithm Optimization**
- **Technical Principle**: Choosing the appropriate algorithms and model structures can reduce computational load and increase running speed.
- **Operational Steps**: Select the optimal algorithms based on the type of problem and the characteristics of the data.
- **Parallel Computing and Multithreading**
- **Technical Principle**: Utilize the multi-core capabilities of modern CPUs to enhance performance through parallel computing and multithreading.
- **Operational Steps**: Use parallel computing libraries like OpenMP, MPI, or multithreading libraries like Python's `threading` and `multiprocessing`.
## 2.3 Model Compatibility Testing
### 2.3.1 Identifying Compatibility Issues
Model compatibility issues may stem from differences between deep learning frameworks and inconsistencies in system environments.
- **Framework Differences**
- **Analysis**: Different deep learning frameworks may have discrepancies in numerical computations and function implementations.
- **Solution**: Use cross-framework tools for compatibility testing before model conv
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
技术手册制作流程:如何打造完美的IT产品手册?
# 摘要
技术手册作为重要的技术沟通工具,在产品交付和使用过程中发挥着不可或缺的作用。本文系统性地探讨了技术手册撰写的重要性和作用,详述了撰写前期准备工作的细节,包括明确编写目的与受众分析、构建内容框架与风格指南、收集整理技术资料等。同时,本文进一步阐述了内容创作与管理的方法,包含文本内容的编写、图表和视觉元素的设计制作,以及版本控制与文档管理策略。在手册编辑与校对方面,本文强调了建立高效流程和标准、校对工作的方法与技巧以及互动反馈与持续改进的重要性。最后,本文分析了技术手册发布的渠道与格式选择、分发策略与用户培训,并对技术手册的未来趋势进行了展望,特别是数字化、智能化的发展以及技术更新对手册
【SQL Server触发器实战课】:自动化操作,效率倍增!

# 摘要
SQL Server触发器是数据库中强大的自动化功能,允许在数据表上的特定数据操作发生时自动执行预定义的SQL语句。本文
高效优化车载诊断流程:ISO15765-3标准的应用指南

# 摘要
本文详细介绍了ISO15765-3标准及其在车载诊断系统中的应用。首先概述了ISO15765-3标准的基本概念,并探讨了车载诊断系统的功能组成和关键技术挑战。接着,本文深入分析了该标准的工作原理,包括数据链路层协议、消息类型、帧结构以及故障诊断通信流程
【Sysmac Studio模板与库】:提升编程效率与NJ指令的高效应用
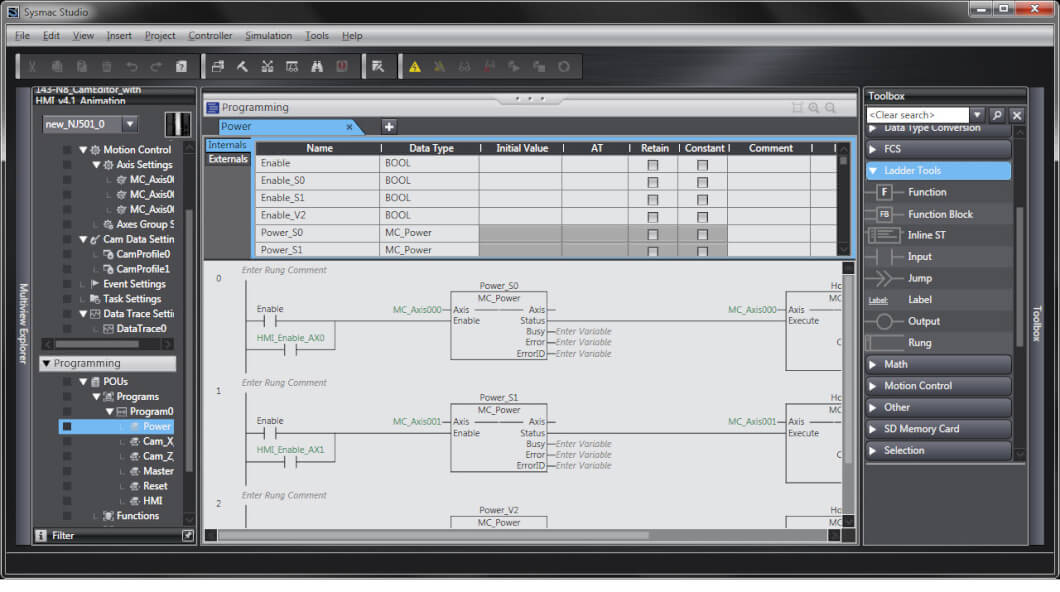
# 摘要
本文旨在深入介绍Sysmac Studio的开发环境配置、模板和库的应用,以及NJ指令集在高效编程中的实践。首先,我们将概述Sysmac Studio的界面和基础开发环境设置。随后,深入探讨模板的概念、创建、管理和与库的关系,包括模板在自动化项目中的重要性、常见模板类型、版本控制策略及其与库的协作机制。文章继续分析了
【内存管理技术】:缓存一致性与内存层次结构的终极解读
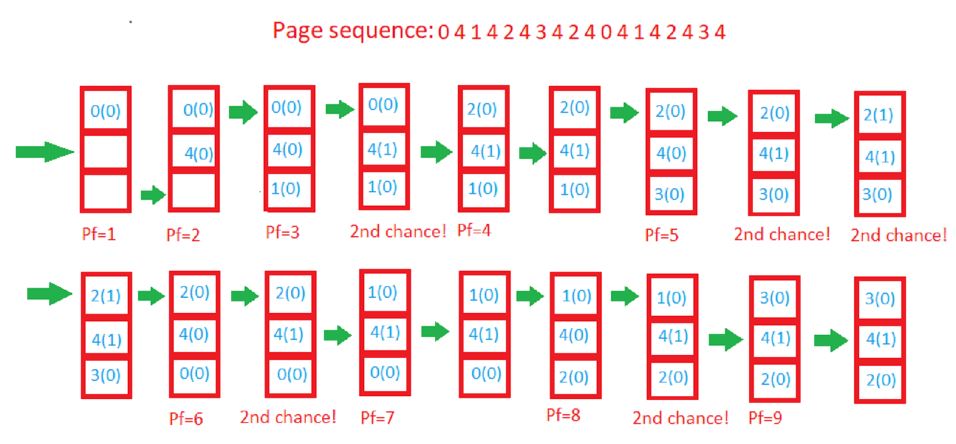
# 摘要
本文对现代计算机系统中内存管理技术进行了全面概述,深入分析了缓存一致性机制及其成因、缓存一致性协议和硬件支持,以及它们对系统性能的影响。随后,本文探讨了内存层次结构与架构设计,包括内存管理策略、页面替换算法和预取技术。文中还提供了内存管理实践案例,分析了大数据环境和实时系统中内存管理的挑战、内存泄漏的诊断技术以及性能调优策略。最后,本文展望了新兴内存技术、软件层面创新和面向未来的内存管理挑战,包括安全性、隐私保护、可持续性和能效问题。
#
【APS系统常见问题解答】:故障速查手册与性能提升指南

# 摘要
本文全面概述了APS系统故障排查、性能优化、故障处理及维护管理的最佳实践。首先,介绍了故障排查的理论依据、工具和案例分析,为系统故障诊断提供了坚实的基础。随后,探讨了性能优化的评估指标、优化策略和监控工具的应用,
SEMI-S2标准实施细节:从理论到实践
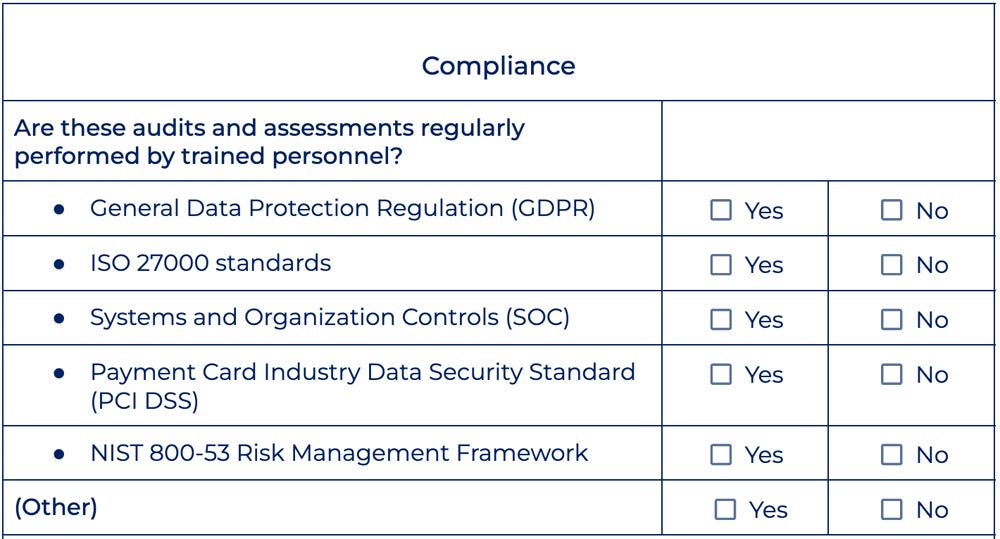
# 摘要
本文全面介绍了SEMI-S2标准的理论基础、实践应用以及实施策略,并探讨了相关技术创新。首先概述了SEMI-S2标准的发展历程和核心条款,随后解析了其技术框架、合规要求以及监控与报告机制。接着,文中分析了SEMI-S2标准在半导体制造中的具体应用,并通过案例分析,展示了在工厂环境控制与设备操作维护中的实践效果。此外,本文还提出了实
康耐视扫码枪数据通讯秘籍:三菱PLC响应优化技巧

# 摘要
本文详细探讨了康耐视扫码枪与三菱PLC之间数据通信的基础技术与实践应用,包括通讯协议的选择与配置、数据接口与信号流程分析以及数据包结构的封装和解析。随后,文章针对数据通讯故障的诊断与调试提供了方法,并深入分析了三菱PLC的响应时间优化策略,包括编程响应时间分析、硬件配置改进和系统级优化。通过实践案例分析与应用,提出了系统集成、部署以及维护与升级策略。最后,文章展
【Deli得力DL-888B打印机耗材管理黄金法则】:减少浪费与提升效率的专业策略

# 摘要
Deli得力DL-888B打印机的高效耗材管理对于保障打印品质和降低运营成本至关重要。本文从耗材管理的基础理论入手,详细介绍了打印机耗材的基本分类、特性及生命周期,探讨了如何通过实践实现耗材使用的高效监控。接着,本文提出了减少耗材浪费和提升打印效率的优化策略。在成本控制与采购策略方面,文章讨论了耗材成本的精确计算方法以及如何优化耗材供应链。最后,本
物流效率的秘密武器:圆通视角下的优博讯i6310B_HB版升级效果解析
# 摘要
随着技术的发展,物流效率的提升已成为行业关注的焦点。本文首先介绍了物流效率与技术驱动之间的关系,接着详细阐述了优博讯i6310B_HB版的基础特性和核心功能。文章深入分析了传统物流处理流程中的问题,并探讨了i6310B_HB版升级对物流处理流程带来的变革,包括数据处理效率的提高和操作流程的改进。通过实际案例分析,展示了升级效果,并对未来物流行业的技术趋势及圆通在技术创新中的角色进行了展望,强调了持续改进的重要性。
# 关键字
物流效率;技术驱动;优博讯i6310B_HB;数据处理;操作流程;技术创新
参考资源链接:[圆通工业手机i6310B升级指南及刷机风险提示](https:/
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )