Selection and Optimization of Anomaly Detection Models: 4 Tips to Ensure Your Model Is Smarter
发布时间: 2024-09-15 11:48:09 阅读量: 10 订阅数: 17 
# 1. Overview of Anomaly Detection Models
## 1.1 Introduction to Anomaly Detection
Anomaly detection is a significant part of data science that primarily aims to identify anomalies—data points that deviate from expected patterns or behaviors—from vast amounts of data. These anomalies might represent errors, fraud, system failures, or other conditions that warrant special attention.
## 1.2 Application Scenarios
Anomaly detection technology is applied in various fields, such as credit card fraud detection, network security intrusion detection, and the identification of rare diseases in medical diagnoses. It aids businesses in discovering potential risks in a timely manner and responding accordingly.
## 1.3 Basic Workflow of the Model
The basic workflow of anomaly detection models typically includes data collection, preprocessing, feature extraction, model selection, training and evaluation, and the final model deployment and monitoring. Each step is designed to enhance the accuracy and efficiency of the model in real-world scenarios.
# 2. Theoretical Foundation of Model Selection
## 2.1 Types of Anomaly Detection Models
### 2.1.1 Statistical Methods
Statistical methods form the foundation of anomaly detection, ***mon approaches are parametric and non-parametric methods.
**Parametric methods** assume that data follows a specific distribution, such as the Gaussian distribution, and use model parameters to describe this distribution. For instance, if we assume data follows a Gaussian distribution, we can calculate the mean and variance, and set thresholds based on these parameters. Any data points beyond these thresholds may be considered anomalous. This method performs well when the data distribution is known and stable.
```python
import numpy as np
from scipy import stats
# Assuming we have normally distributed data
data = np.random.randn(1000)
# Calculate mean and standard deviation
mean, std = data.mean(), data.std()
# Set a threshold: typically, a range of standard deviations
threshold = 3 * std
# Find outliers
outliers = data[(np.abs(data - mean) > threshold)]
print("Number of outliers:", len(outliers))
```
**Non-parametric methods** do not rely on data's parameter models but directly analyze the data. For example, the k-nearest neighbors (k-NN) method can detect anomalies based on the assumption that data points in high-density areas are normal, whereas those in low-density areas may be anomalous. The algorithm calculates the distance from a point to its k nearest neighbors and considers the point to be anomalous if this distance exceeds a certain threshold.
```python
from sklearn.neighbors import NearestNeighbors
# Using k-NN to detect anomalies
model = NearestNeighbors(n_neighbors=5)
model.fit(data.reshape(-1, 1))
distances, indices = model.kneighbors(data.reshape(-1, 1))
# Find outliers: those beyond twice the average distance may be anomalous
mean_dist = distances.mean(axis=1)
outliers = data[mean_dist > 2 * mean_dist.mean()]
print("Number of outliers:", len(outliers))
```
### 2.1.2 Machine Learning Methods
Compared to statistical methods, machine learning methods do not req***mon machine learning methods include Support Vector Machines (SVM), Isolation Forest, and neural network-based methods.
**Support Vector Machines (SVM)** can be used for anomaly detection by constructing a hyperplane that separates normal data from anomalies. SVM builds this hyperplane by maximizing the margin between normal and anomalous data. After training, any point on the other side of the hyperplane can be considered an anomaly.
```python
from sklearn.svm import OneClassSVM
# Using One-Class SVM for anomaly detection
svm = OneClassSVM(kernel="rbf", nu=0.05)
svm.fit(data.reshape(-1, 1))
# Predict anomalies
outliers = svm.predict(data.reshape(-1, 1)) == -1
print("Number of outliers:", sum(outliers))
```
**Isolation Forest** is a tree-based algorithm that randomly selects features and randomly chooses split values to "isolate" sample points. Since anomalies are sparse and differ significantly from other data points, they are typically isolated earlier in the decision tree.
```python
from sklearn.ensemble import IsolationForest
# Using Isolation Forest for anomaly detection
iso_forest = IsolationForest(contamination=0.05)
outliers = iso_forest.fit_predict(data.reshape(-1, 1))
# Find outliers
print("Number of outliers:", sum(outliers == -1))
```
## 2.2 Model Evaluation Criteria
### 2.2.1 Accuracy Me***
***mon accuracy metrics include Precision, Recall, and the F1 score.
- **Precision** refers to the proportion of actual anomalies among the data points predicted as anomalous by the model. It indicates the model's ability to accurately predict anomalies in marked abnormal data.
- **Recall** refers to the proportion of all actual anomalies that the model successfully identifies. It reflects the model's ability to detect anomalies.
- The **F1 score** is the harmonic mean of Precision and Recall, serving as a measure of the overall model performance.
```python
from sklearn.metrics import precision_score, recall_score, f1_score
# Assuming we have actual and predicted values
true_values = np.array([1, 0, 1, 1, 0, 0, 1])
predicted_values = np.array([1, 0, 0, 1, 0, 1, 0])
# Calculate accuracy metrics
precision = precision_score(true_values, predicted_values)
recall = recall_score(true_values, predicted_values)
f1 = f1_score(true_values, predicted_values)
print(f"Precision: {precision}, Recall: {recall}, F1 score: {f1}")
```
### 2.2.2 Predictive Quality Metrics
In addition to accuracy metrics, there are other indicators used to assess the quality of a model's predictions. For example, ROC-AUC (Receiver Operating Characteristic - Area Under Curve) is widely used in classification problems and is particularly suitable for imbalanced datasets.
- **ROC-AUC** is assessed by calculating the area under the ROC curve, which evaluates the model's performance at different thresholds. An ideal model's ROC curve is close to the top left corner, indicating high recall and high precision.
```python
from sklearn.metrics import roc_auc_score
# Assuming we have actual and predicted probabilities
true_values = np.array([1, 0, 1, 1, 0, 0, 1])
predicted_probabilities = np.array([0.9, 0.1, 0.8, 0.65, 0.1, 0.2, 0.3])
# Calculate ROC-AUC
roc_auc = roc_auc_score(true_values, predicted_probabilities)
print(f"ROC-AUC: {roc_auc}")
```
## 2.3 Influencing Factors for Model Selection
### 2.3.1 Data Characteristic Analysis
Before selecting an appropriate anomaly detection model, a thorough analysis of the data is necessary. Data characteristics include the dimensionality, distribution, noise level, and presence of missing values.
- **Data Dimensionality**: High dimensionality may result in sparsity, which can make distance-based methods (like k-NN) less effective. In high-dimensional data, dimensionality reduction techniques like PCA can be considered, or algorithms capable of handling high-dimensional data, such as the Isolation Forest, can be used.
- **Data Distribution**: Some algorithms assume a specific data distribution, such as the Gaussian distribution. If the data does not follow such a distribution, the performance of these algorithms may degrade.
- **Noise Level**: In the presence of significant noise, statistical models may not be suitable as noise can interfere with the model's judgment on anomalies. In such cases, machine learning methods may be needed.
- **Missing Values**: Missing values can be handled in various ways, such as filling (interpolation), ignoring, or using robust model versions.
### 2.3.2 Considerations for Real-world Application Scenarios
In addition to data characteristics, the requirements and constraints of real-world application scenarios are crucial for model selection. These requirements include model real-time performance, interpretability, complexity, and deployment environment.
- **Real-time Performance**: For applications that require real-time or near-real-time detection (such as credit card fraud detection), model selection must consider computational efficiency. It may be necessary to sacrifice some accuracy to ensure detection speed.
- **Interpretability**: In some fields (like medical diagnostics), model interpretability is equally important. Statistical methods and tree-based machine learning methods are typically easier to interpret.
- **Complexity**: Simple models are easier to understand and deploy but may not handle complex data structures. More complex models may offer better performance but increase computational costs and maintenance difficulties.
- **Deployment Environment**: The model deployment environment also influences model selection, such as whether a GPU can be used, or the model needs to run on edge devices.
These factors should be considered comprehensively when selecting an anomaly detection model. In practice, it may be necessary to experiment with various models and use techniques like cross-validation to evaluate model performance and ultimately select the model that best suits the application requirements.
# 3. Model Optimization Techniques in Practice
## 3.1 Feature Engineering
### 3.1.1 Feature Selection Methods
Feature selection is an important step in reducing model complexity, improving model running efficiency, and avoiding overfitting. ***mon feature selection methods include:
- Filter Methods: Select features through statistical tests without considering model performance. Typical methods include the chi-squared test, mutual information, and analysis of variance (ANOVA).
- Wrapper Methods: Use a learner to evaluate the effect of feature subsets, such as Recursive Feature Elimination (RFE).
- Embedded Methods: Perform feature selection during the learner training process, such as Lasso and Ridge Regression.
Each method corresponds to different scenarios and needs. Choosing the appropriate feature selection method can significantly enhance model performance. When dealing with large datasets, Wrapper and Embedded methods may increase computational costs, while Filter methods are more efficient.
**Code Example**: Using Recursive Feature Elimination (RFE) for feature selection.
```python
from sklearn.feature_selection import RFE
from sklearn.ensemble import RandomForestClassifier
```
 最低0.47元/天 解锁专栏
最低0.47元/天 解锁专栏 送3个月
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Python装饰模式实现:类设计中的可插拔功能扩展指南
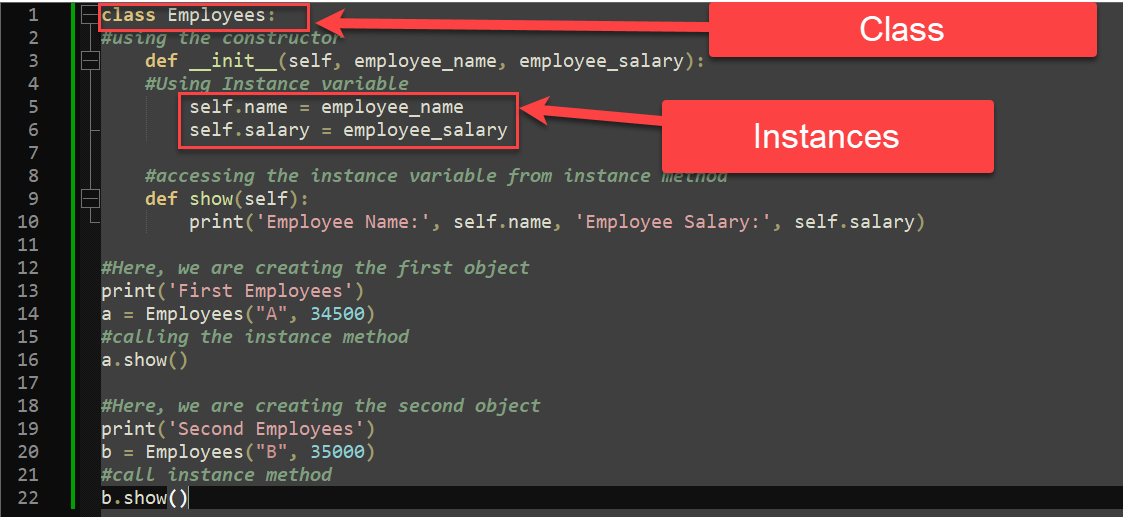
# 1. Python装饰模式概述
装饰模式(Decorator Pattern)是一种结构型设计模式,它允许动态地添加或修改对象的行为。在Python中,由于其灵活性和动态语言特性,装饰模式得到了广泛的应用。装饰模式通过使用“装饰者”(Decorator)来包裹真实的对象,以此来为原始对象添加新的功能或改变其行为,而不需要修改原始对象的代码。本章将简要介绍Python中装饰模式的概念及其重要性,为理解后
Python序列化与反序列化高级技巧:精通pickle模块用法

# 1. Python序列化与反序列化概述
在信息处理和数据交换日益频繁的今天,数据持久化成为了软件开发中不可或缺的一环。序列化(Serialization)和反序列化(Deserialization)是数据持久化的重要组成部分,它们能够将复杂的数据结构或对象状态转换为可存储或可传输的格式,以及还原成原始数据结构的过程。
序列化通常用于数据存储、
Python print语句装饰器魔法:代码复用与增强的终极指南

# 1. Python print语句基础
## 1.1 print函数的基本用法
Python中的`print`函数是最基本的输出工具,几乎所有程序员都曾频繁地使用它来查看变量值或调试程序。以下是一个简单的例子来说明`print`的基本用法:
```python
print("Hello, World!")
```
这个简单的语句会输出字符串到标准输出,即你的控制台或终端。`prin
Python数组在科学计算中的高级技巧:专家分享

# 1. Python数组基础及其在科学计算中的角色
数据是科学研究和工程应用中的核心要素,而数组作为处理大量数据的主要工具,在Python科学计算中占据着举足轻重的地位。在本章中,我们将从Python基础出发,逐步介绍数组的概念、类型,以及在科学计算中扮演的重要角色。
## 1.1 Python数组的基本概念
数组是同类型元素的有序集合,相较于Python的列表,数组在内存中连续存储,允
【Python中的深浅拷贝】:揭秘字典复制的正确姿势,避免数据混乱

# 1. 深浅拷贝概念解析
在开始深入理解拷贝机制之前,我们需要先明确拷贝的基本概念。拷贝主要分为两种类型:浅拷贝(Shallow Copy)和深拷贝(Deep Copy)。浅拷贝是指在创建一个新的容器对象,然后将原容器中的元素的引用复制到新容器中,这样新容器和原容器中的元素引用是相同的。在Python中,浅拷贝通常可以通过多种方式实现,例如使用切片操作、工厂函数、或者列表
Python版本与性能优化:选择合适版本的5个关键因素

# 1. Python版本选择的重要性
Python是不断发展的编程语言,每个新版本都会带来改进和新特性。选择合适的Python版本至关重要,因为不同的项目对语言特性的需求差异较大,错误的版本选择可能会导致不必要的兼容性问题、性能瓶颈甚至项目失败。本章将深入探讨Python版本选择的重要性,为读者提供选择和评估Python版本的决策依据。
Python的版本更新速度和特性变化需要开发者们保持敏锐的洞
Python pip性能提升之道
# 1. Python pip工具概述
Python开发者几乎每天都会与pip打交道,它是Python包的安装和管理工具,使得安装第三方库变得像“pip install 包名”一样简单。本章将带你进入pip的世界,从其功能特性到安装方法,再到对常见问题的解答,我们一步步深入了解这一Python生态系统中不可或缺的工具。
首先,pip是一个全称“Pip Installs Pac
【Python集合异常处理攻略】:集合在错误控制中的有效策略

# 1. Python集合的基础知识
Python集合是一种无序的、不重复的数据结构,提供了丰富的操作用于处理数据集合。集合(set)与列表(list)、元组(tuple)、字典(dict)一样,是Python中的内置数据类型之一。它擅长于去除重复元素并进行成员关系测试,是进行集合操作和数学集合运算的理想选择。
集合的基础操作包括创建集合、添加元素、删除元素、成员测试和集合之间的运
Parallelization Techniques for Matlab Autocorrelation Function: Enhancing Efficiency in Big Data Analysis
# 1. Introduction to Matlab Autocorrelation Function
The autocorrelation function is a vital analytical tool in time-domain signal processing, capable of measuring the similarity of a signal with itself at varying time lags. In Matlab, the autocorrelation function can be calculated using the `xcorr
Pandas中的文本数据处理:字符串操作与正则表达式的高级应用

# 1. Pandas文本数据处理概览
Pandas库不仅在数据清洗、数据处理领域享有盛誉,而且在文本数据处理方面也有着独特的优势。在本章中,我们将介绍Pandas处理文本数据的核心概念和基础应用。通过Pandas,我们可以轻松地对数据集中的文本进行各种形式的操作,比如提取信息、转换格式、数据清洗等。
我们会从基础的字
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )