YOLOv8 Practical Case: Quality Inspection Applications in the Field of Food Safety
发布时间: 2024-09-15 07:41:10 阅读量: 22 订阅数: 23 

Practical JSF in Java EE 8 Web Applications in Java for the Enterprise 无水印原版pdf
# 1. Overview of Food Safety Quality Inspection
Food safety quality inspection is a crucial aspect of the food industry, aimed at ensuring the safety, hygiene, and quality of food products. With the continuous development of the food industry chain and the rising awareness of food safety among consumers, the quality inspection of food safety faces increasingly severe challenges.
Traditional manual inspection methods suffer from low efficiency, poor accuracy, and high costs. In recent years, computer vision technology has been widely applied in the field of food safety quality inspection. Among these technologies, YOLOv8, as an advanced deep learning algorithm, has become a research hotspot in the field due to its speed and high precision advantages.
# 2. Theoretical Foundation of YOLOv8
### 2.1 YOLOv8 Network Structure and Algorithm Principle
As the latest version of the YOLO series of object detection algorithms, YOLOv8 has made significant improvements in network structure and algorithm principles, further enhancing the accuracy and speed of the model.
#### 2.1.1 YOLOv8 Backbone Network
YOLOv8 adopts CSPDarknet53 as its backbone network, which consists of 53 convolutional layers. It combines residual connections and CSP structures, effectively reducing the amount of computation while ensuring model accuracy.
#### 2.1.2 YOLOv8 Neck Network
The neck network of YOLOv8 uses the PANet structure, which enhances the model's ability to detect objects of different sizes by fusing feature maps at different scales. PANet includes multiple SPP modules for extracting features at different scales and an FPN module for fusion.
#### 2.1.3 YOLOv8 Head Network
The head network of YOLOv8 adopts the YOLO Head structure, which includes a convolutional layer and an output layer. The convolutional layer is used for feature extraction, and the output layer is responsible for predicting the category and location of the objects. YOLOv8 uses the CIOU loss function and DIOU-NMS algorithm, further improving the model's positioning accuracy.
### 2.2 Training and Evaluation of YOLOv8
#### 2.2.1 Preparation of Training Dataset
YOLOv8 training requires high-quality annotated datasets, typically trained on the COCO dataset. The COCO dataset includes 80 object categories, over 120,000 images, and 1.5 million annotated boxes.
#### 2.2.2 Training Process and Hyperparameter Optimization
The training of YOLOv8 uses the Adam optimizer with a learning rate set to 0.001 and a training batch size of 64. During training, data augmentation techniques such as random cropping, flipping, and color jittering are used to improve the model's generalization ability.
#### 2.2.3 Model Evaluation Metrics and Result Analysis
The evaluation metrics for YOLOv8 include precision (AP), recall rate (AR), and mean average precision (mAP). mAP is the average of APs at different IOU thresholds and is commonly used to comprehensively assess the model's performance. YOLOv8 has achieved outstanding mAP of 56.8% on the COCO dataset, surpassing other object detection algorithms in both accuracy and speed.
```python
import torch
from torch import nn
from torch.nn import functional as F
class YOLOv8Head(nn.Module):
def __init__(self, num_classes, anchors):
super(YOLOv8Head, self).__init__()
self.num_classes = num_classes
self.anchors = anchors
self.conv1 = nn.Conv2d(1024, 512, 1)
self.conv2 = nn.Conv2d(512, 1024, 3, padding=1)
self.conv3 = nn.Conv2d(1024, 512, 1)
self.conv4 = nn.Conv2d(512, 256, 3, padding=1)
self.conv5 = nn.Conv2d(256, 255, 1)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.conv5(x)
# Reshape the output to (batch_size, num_anchors, grid_size, grid_size, 5 + num_classes)
x = x.permute(0, 2, 3, 1).contiguous()
x = x.view(x.shape[0], -1, 5 + self.num_classes)
# Compute the class probabilities and bounding box offsets
class_logits = x[..., 5:]
class_probs = F.softmax(class_logits, dim=-1)
bbox_offsets = x[..., :4]
# Compute the anchor boxes
anchors = self.anchors.view(1, -1, 1, 1, 2)
anchors = anchors.expand(x.shape[0], -1, -1, -1, -1)
# Compute the predicted bounding boxes
bboxes = anchors + bbox_offsets
return class_p
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
ABB机器人SetGo指令脚本编写:掌握自定义功能的秘诀

# 摘要
本文详细介绍了ABB机器人及其SetGo指令集,强调了SetGo指令在机器人编程中的重要性及其脚本编写的基本理论和实践。从SetGo脚本的结构分析到实际生产线的应用,以及故障诊断与远程监控案例,本文深入探讨了SetGo脚本的实现、高级功能开发以及性能优化
【Wireshark与Python结合】:自动化网络数据包处理,效率飞跃!
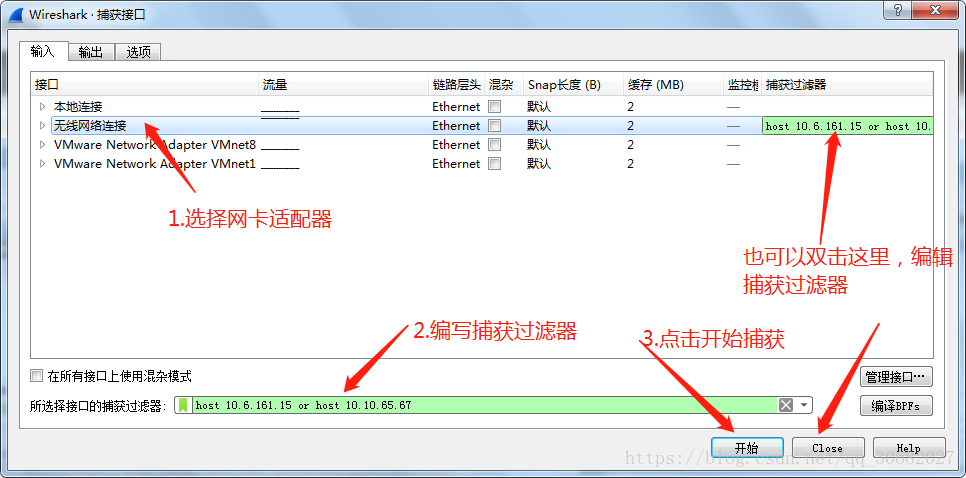
# 摘要
本文旨在探讨Wireshark与Python结合在网络安全和网络分析中的应用。首先介绍了网络数据包分析的基础知识,包括Wireshark的使用方法和网络数据包的结构解析。接着,转
OPPO手机工程模式:硬件状态监测与故障预测的高效方法

# 摘要
本论文全面介绍了OPPO手机工程模式的综合应用,从硬件监测原理到故障预测技术,再到工程模式在硬件维护中的优势,最后探讨了故障解决与预防策略。本研究详细阐述了工程模式在快速定位故障、提升维修效率、用户自检以及故障预防等方面的应用价值。通过对硬件监测技术的深入分析、故障预测机制的工作原理以及工程模式下的故障诊断与修复方法的探索,本文旨在为
NPOI高级定制:实现复杂单元格合并与分组功能的三大绝招
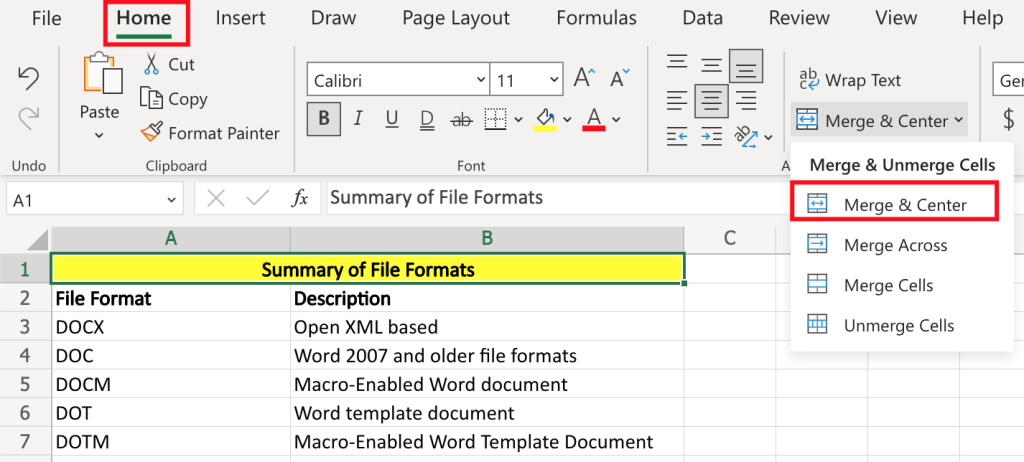
# 摘要
本文详细介绍了NPOI库在处理Excel文件时的各种操作技巧,包括安装配置、基础单元格操作、样式定制、数据类型与格式化、复杂单元格合并、分组功能实现以及高级定制案例分析。通过具体的案例分析,本文旨在为开发者提供一套全面的NPOI使用技巧和最佳实践,帮助他们在企业级应用中优化编程效率,提
【矩阵排序技巧】:Origin转置后矩阵排序的有效方法

# 摘要
矩阵排序是数据分析和工程计算中的重要技术,本文对矩阵排序技巧进行了全面的概述和探讨。首先介绍了矩阵排序的基础理论,包括排序算法的分类和性能比较,以及矩阵排序与常规数据排序的差异。接着,本文详细阐述了在Origin软件中矩阵的基础操作,包括矩阵的创建、导入、转置操作,以及转置后矩阵的结构分析。在实践中,本文进一步介绍了Origin中基于行和列的矩阵排序步骤和策略,以及转置后
SPI总线编程实战:从初始化到数据传输的全面指导
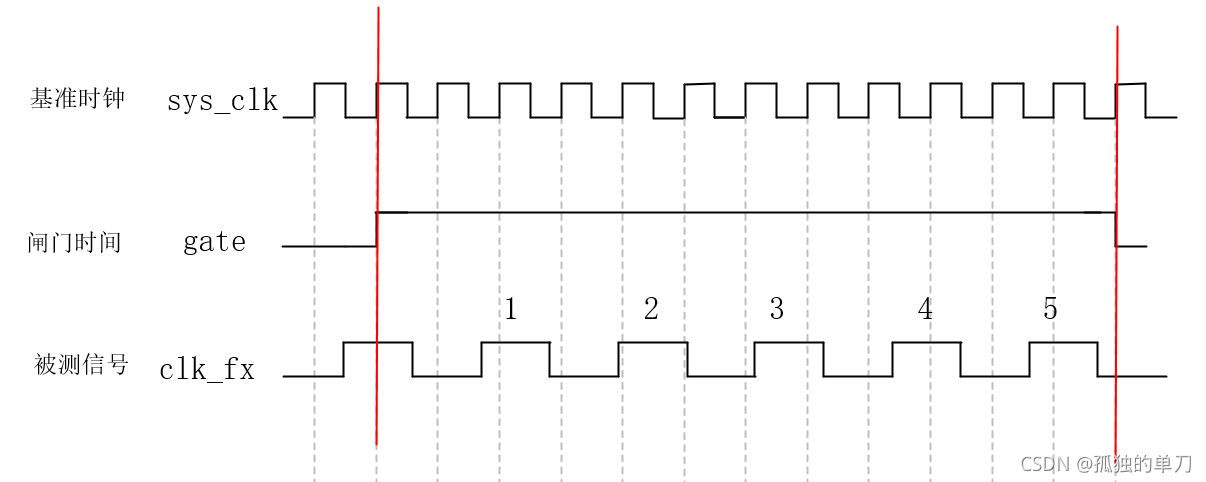
# 摘要
SPI总线技术作为高速串行通信的主流协议之一,在嵌入式系统和外设接口领域占有重要地位。本文首先概述了SPI总线的基本概念和特点,并与其他串行通信协议进行
电路分析难题突破术:Electric Circuit第10版高级技巧揭秘
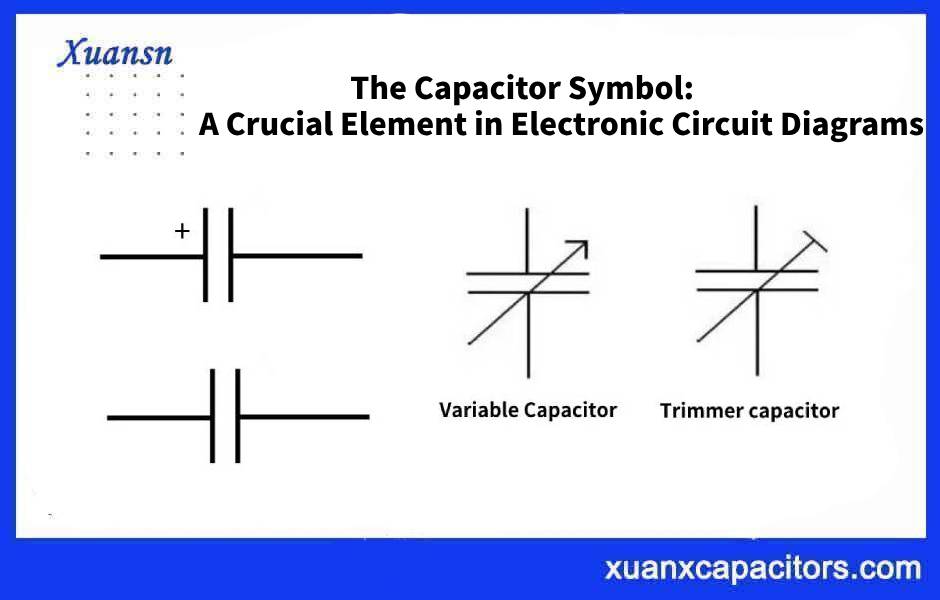
# 摘要
本文系统地介绍了电路理论的核心基础与分析方法,涵盖了复杂电路建模、时域与频域分析以及数字逻辑与模拟电路的高级技术。首先,我们讨论了理想与实际电路元件模型之间的差异,电路图的简化和等效转换技巧,以及线性和非线性电路的分析方法。接着,文章深入探讨了时域和频域分析的关键技巧,包括微分方程、拉普拉斯变换、傅里叶变换的应用以及相互转换的策略。此外,本文还详
ISO 9001:2015标准中文版详解:掌握企业成功实施的核心秘诀
# 摘要
ISO 9001:2015是国际上广泛认可的质量管理体系标准,它提供了组织实现持续改进和顾客满意的框架。本文首先概述了ISO 9001:2015标准的基本内容,并详细探讨了七个质量管理原则及其在实践中的应用策略。接着,本文对标准的关键条款进行了解析,阐明了组织环境、领导作用、资源管理等方面的具体要求。通过分析不同行业,包括制造业、服务业和IT行业中的应
计算几何:3D建模与渲染的数学工具,专业级应用教程

# 摘要
计算几何和3D建模是现代计算机图形学和视觉媒体领域的核心组成部分,涉及到从基础的数学原理到高级的渲染技术和工具实践。本文从计算几何的基础知识出发,深入
PS2250量产兼容性解决方案:设备无缝对接,效率升级

# 摘要
PS2250设备作为特定技术产品,在量产过程中面临诸多兼容性挑战和效率优化的需求。本文首先介绍了PS2250设备的背景及量产需求,随后深入探讨了兼容性问题的分类、理论基础和提升策略。重点分析了设备驱动的适配更新、跨平台兼容性解决方案以及诊断与问题解决的方法。此外,文章还
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )