YOLOv8 Real-World Case Study: Real-Time Action Recognition in Sports Events
发布时间: 2024-09-15 07:47:58 阅读量: 23 订阅数: 21 
# 1. Overview of YOLOv8
YOLOv8 is the latest version of the YOLO (You Only Look Once) series of object detection algorithms, ***pared to previous YOLO versions, YOLOv8 has seen significant improvements in accuracy, speed, and robustness.
YOLOv8 employs a new network architecture known as Cross-Stage Partial Connections (CSP), which reduces computational load while maintaining model precision. Additionally, YOLOv8 introduces new training strategies such as adaptive learning rate adjustments and label smoothing, which can further enhance model performance.
On the COCO dataset, YOLOv8 achieves state-of-the-art performance in both AP (Average Precision) and FPS (Frames Per Second). Specifically, YOLOv8-S reaches an AP50 of 56.8% with an FPS of 150, while YOLOv8-L achieves an AP50 of 61.7% with an FPS of 80.
# 2. Training the YOLOv8 Model
### 2.1 Dataset Preparation and Preprocessing
#### 2.1.1 Data Collection and Annotation
**Data Collection**
Training the YOLOv8 model requires a large amount of annotated data, which can be collected from various sources such as:
* Public datasets: COCO, VOC, ImageNet
* Proprietary datasets: Images captured or collected and manually annotated
* Crowdsourcing platforms: Amazon Mechanical Turk, Labelbox
**Data Annotation**
After collecting data, it must be annotated to provide the ground truth required for model training. Annotation typically involves the following steps:
***Bounding Box Annotation:** Drawing boxes around targets in images.
***Class Annotation:** Assigning a class label to each target.
***Keypoint Annotation:** Annotating key points on targets, such as the eyes, nose, and mouth in faces.
#### 2.1.2 Data Augmentation and Preprocessing
**Data Augmentation**
To improve the model's generalization capabilities, ***mon augmentation methods include:
***Random Cropping:** Randomly cropping areas of different sizes and aspect ratios from images.
***Random Flipping:** Horizontally or vertically flipping images.
***Color Jittering:** Adjusting the brightness, contrast, saturation, and hue of images.
**Data Preprocessing**
Before training the model, data preprocessing is required, including:
***Image Resizing:** Scaling images to the input size of the model.
***Data Normalization:** Normalizing pixel values of images to a range between 0 and 1.
***Data Format Conversion:** Converting images into a format required for model training, such as PyTorch Tensors or NumPy arrays.
### 2.2 Model Architecture and Training Parameters
#### 2.2.1 YOLOv8's Network Architecture
YOLOv8 utilizes an innovative network architecture called Cross-Stage Partial Connections (CSP), which improves model efficiency and accuracy by connecting different layers at various stages of the network.
The YOLOv8 network architecture mainly includes the following components:
***Backbone:** Extracts image features, typically using pre-trained models such as ResNet, DarkNet, or EfficientNet.
***Neck:** Fuses features from different stages, enhancing semantic information.
***Detection Head:** Predicts object boxes and class probabilities.
#### 2.2.2 Setting and Optimizing Training Parameters
The following training parameters need to be set and optimized for YOLOv8 model training:
***Learning Rate:** Controls the step size of model parameter updates.
***Batch Size:** The number of images used in each training iteration.
***Epochs:** The number of times the model is trained on the entire dataset.
***Optimizer:** The algorithm used to update model parameters, such as Adam, SGD, or RMSprop.
***Loss Function:** Measures the difference between model predictions and ground truth, such as cross-entropy loss or IOU loss.
**Training Parameter Optimization**
To achieve the best training results, the following methods can be used to optimize training parameters:
***Hyperparameter Tuning:** Explore the best parameter combinations using techniques like grid search or Bayesian optimization.
***Learning Rate Decay:** Gradually reduce the learning rate as training progresses to improve model stability.
***Data Augmentation:** Use the aforementioned augmentation techniques to enhance the model's generalization ability.
# 3. YOLOv8 Model Evaluation and Deployment
### 3.1 Model Evaluation and Optimization
#### 3.1.1 Selection and Calculation of Evaluation Metrics
When evaluating the YOLOv8 model, commonly used metrics include:
- **Mean Average Precision (mAP):**

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
大样本理论在假设检验中的应用:中心极限定理的力量与实践

# 1. 中心极限定理的理论基础
## 1.1 概率论的开篇
概率论是数学的一个分支,它研究随机事件及其发生的可能性。中心极限定理是概率论中最重要的定理之一,它描述了在一定条件下,大量独立随机变量之和(或平均值)的分布趋向于正态分布的性
p值在机器学习中的角色:理论与实践的结合

# 1. p值在统计假设检验中的作用
## 1.1 统计假设检验简介
统计假设检验是数据分析中的核心概念之一,旨在通过观察数据来评估关于总体参数的假设是否成立。在假设检验中,p值扮演着决定性的角色。p值是指在原
【PCA算法优化】:减少计算复杂度,提升处理速度的关键技术

# 1. PCA算法简介及原理
## 1.1 PCA算法定义
主成分分析(PCA)是一种数学技术,它使用正交变换来将一组可能相关的变量转换成一组线性不相关的变量,这些新变量被称为主成分。
## 1.2 应用场景概述
PCA广泛应用于图像处理、降维、模式识别和数据压缩等领域。它通过减少数据的维度,帮助去除冗余信息,同时尽可能保
零基础学习独热编码:打造首个特征工程里程碑
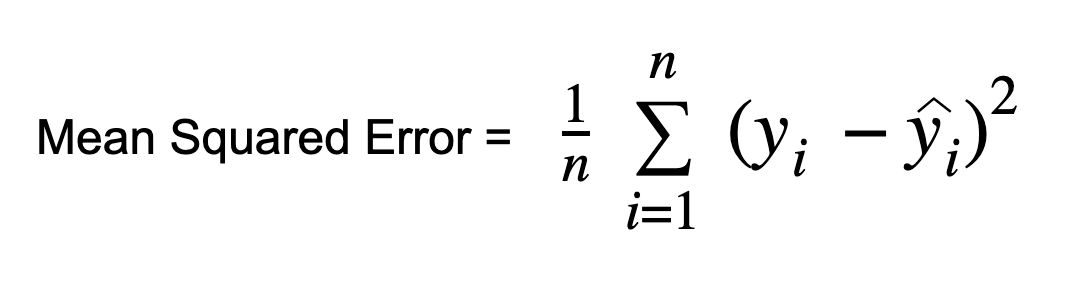
# 1. 独热编码的基本概念
在机器学习和数据科学中,独热编码(One-Hot Encoding)是一种将分类变量转换为机器学习模型能够理解的形式的技术。每一个类别都被转换成一个新的二进制特征列,这些列中的值不是0就是1,代表了某个特定类别的存在与否。
独热编码方法特别适用于处理类别型特征,尤其是在这些特征是无序(nominal)的时候。例如,如果有一个特征表示颜色,可能的类别值为“红”、“蓝”和“绿”,
【线性回归时间序列预测】:掌握步骤与技巧,预测未来不是梦
# 1. 线性回归时间序列预测概述
## 1.1 预测方法简介
线性回归作为统计学中的一种基础而强大的工具,被广泛应用于时间序列预测。它通过分析变量之间的关系来预测未来的数据点。时间序列预测是指利用历史时间点上的数据来预测未来某个时间点上的数据。
## 1.2 时间序列预测的重要性
在金融分析、库存管理、经济预测等领域,时间序列预测的准确性对于制定战略和决策具有重要意义。线性回归方法因其简单性和解释性,成为这一领域中一个不可或缺的工具。
## 1.3 线性回归模型的适用场景
尽管线性回归在处理非线性关系时存在局限,但在许多情况下,线性模型可以提供足够的准确度,并且计算效率高。本章将介绍线
【时间序列分析】:如何在金融数据中提取关键特征以提升预测准确性

# 1. 时间序列分析基础
在数据分析和金融预测中,时间序列分析是一种关键的工具。时间序列是按时间顺序排列的数据点,可以反映出某
正态分布与信号处理:噪声模型的正态分布应用解析

# 1. 正态分布的基础理论
正态分布,又称为高斯分布,是一种在自然界和社会科学中广泛存在的统计分布。其因数学表达形式简洁且具有重要的统计意义而广受关注。本章节我们将从以下几个方面对正态分布的基础理论进行探讨。
## 正态分布的数学定义
正态分布可以用参数均值(μ)和标准差(σ)完全描述,其概率密度函数(PDF)表达式为:
```math
f(x|\mu,\sigma^2) = \frac{1}{\sqrt{2\pi\sigma^2}} e
数据清洗的概率分布理解:数据背后的分布特性

# 1. 数据清洗的概述和重要性
数据清洗是数据预处理的一个关键环节,它直接关系到数据分析和挖掘的准确性和有效性。在大数据时代,数据清洗的地位尤为重要,因为数据量巨大且复杂性高,清洗过程的优劣可以显著影响最终结果的质量。
## 1.1 数据清洗的目的
数据清洗
【复杂数据的置信区间工具】:计算与解读的实用技巧
# 1. 置信区间的概念和意义
置信区间是统计学中一个核心概念,它代表着在一定置信水平下,参数可能存在的区间范围。它是估计总体参数的一种方式,通过样本来推断总体,从而允许在统计推断中存在一定的不确定性。理解置信区间的概念和意义,可以帮助我们更好地进行数据解释、预测和决策,从而在科研、市场调研、实验分析等多个领域发挥作用。在本章中,我们将深入探讨置信区间的定义、其在现实世界中的重要性以及如何合理地解释置信区间。我们将逐步揭开这个统计学概念的神秘面纱,为后续章节中具体计算方法和实际应用打下坚实的理论基础。
# 2. 置信区间的计算方法
## 2.1 置信区间的理论基础
### 2.1.1
【特征选择工具箱】:R语言中的特征选择库全面解析

# 1. 特征选择在机器学习中的重要性
在机器学习和数据分析的实践中,数据集往往包含大量的特征,而这些特征对于最终模型的性能有着直接的影响。特征选择就是从原始特征中挑选出最有用的特征,以提升模型的预测能力和可解释性,同时减少计算资源的消耗。特征选择不仅能够帮助我
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )