YOLOv8 Real-World Case Study: Drone Real-Time Object Recognition Technology
发布时间: 2024-09-15 07:38:30 阅读量: 26 订阅数: 23 

terraform-provider-drone:drone.io的terraform提供商
# 1. Theoretical Foundation of the YOLOv8 Model
The YOLOv8 model is an advanced single-stage object detection algorithm, renowned for its speed and accuracy. It is based on the Convolutional Neural Network (CNN) architecture and utilizes techniques such as the Feature Pyramid Network (FPN) and Path Aggregation Network (PAN) to effectively detect objects of various sizes.
The input to the YOLOv8 model is an image, and the output is a set of bounding boxes and corresponding confidence scores. The bounding boxes represent the position and size of the objects, while the confidence scores indicate the model's confidence in the detections. The YOLOv8 model c***
***pared to other object detection algorithms, the YOLOv8 model has the following advantages:
***Speed:** The YOLOv8 model can process images in real-time, handling hundreds of images per second.
***Accuracy:** The YOLOv8 model has achieved high detection accuracy on the COCO dataset, performing excellently in object detection tasks.
***Versatility:** The YOLOv8 model can be applied to various object detection tasks, including image classification, object tracking, and instance segmentation.
# 2. Practical Training of the YOLOv8 Model
### 2.1 Dataset Preparation and Preprocessing
#### 2.1.1 Collection and Filtering of the Dataset
Training the YOLOv8 model requires a large amount of high-quality image data. These images should contain various poses, sizes, and backgrounds of the objects. When collecting the dataset, the following points should be considered:
- **Data Volume:** The dataset should be large enough to ensure that the model can learn the various features of the objects. Generally, the training set should contain at least 10,000 images.
- **Data Quality:** The images should be clear and not blurry. The objects of interest should be clearly visible and not occluded or truncated.
- **Data Diversity:** The dataset should include images of the objects in various poses, sizes, and backgrounds. This will help the model learn the general features of the objects.
#### 2.1.2 Annotation and Format Conversion of Data
After collecting the dataset, the images need to be annotated. The annotation process involves drawing bounding boxes around each object and specifying its category. Specialized annotation tools (such as LabelImg) can be used to complete this task.
After annotation, the data needs to be converted into the format required for YOLOv8 model training. The YOLOv8 model uses the PASCAL VOC format, which includes an XML file and a JPEG image file. The XML file contains information about the bounding boxes and categories.
### 2.2 Model Training and Parameter Tuning
#### 2.2.1 Setting and Optimization of Training Parameters
When training the YOLOv8 model, various training parameters need to be set, including:
- **Learning Rate:** The learning rate controls the magnitude of weight updates in the model. A too-high learning rate can cause the model to be unstable, while a too-low learning rate can result in slow training.
- **Batch Size:** The batch size refers to the number of images used in each training step. A too-large batch size can lead to insufficient video memory, while a too-small batch size can slow down the training.
- **Iterations:** The number of iterations refers to the total number of times the model is trained. The more iterations, the better the model's performance, but the longer the training time.
#### 2.2.2 Improvement and Integration of Model Structure
The YOLOv8 model is a pre-trained model, but it can be improved through the following methods:
- **Fine-tuning:** Fine-tuning involves further training on a pre-trained model using a new dataset. This can improve the model's performance on specific tasks.
- **Feature Fusion:** Feature fusion involves combining features extracted from different layers to obtain a richer feature representation. This can improve the model's detection accuracy.
### 2.3 Model Evaluation and Deployment
#### 2.3.1 Selection and Calculation of Evaluation Metrics
After training, ***mon evaluation metrics include:
- **Mean Average Precision (mAP):** mAP is a comprehensive metric for detection model performance, considering both precision and recall.
- **Precision:** Precision is the proportion of true positives among the samples predicted as positive by the model.
- **Recall:** Recall is the proportion of true positives among all the actual positives.
#### 2.3.2 Deployment and Optimization of the Model
After training, the model needs to be deployed into practical applications. When deploying the model, consider the following factors:
- **Hardware Platform:** The deployment platform must meet the computational requirements of the model.
- **Deployment Method:** The model can be deployed on the cloud or edge devices.
- **Optimization Strategy:** Optimization strategies such as quantization and pruning can be used to improve the efficiency of model deployment.
# 3.1 Selection and Modification of the Drone Platform
#### 3.1.1 Performance Requirements and Selection of Drones
**Performance Requirements for Drones**
In the application of the YOLOv8 model, the drone platform plays a crucial role, directly affecting the deployment and execution efficiency of the model. The following performance requirements need to be considered for the drone platform:
- **Endurance:** The drone needs to have a long flight time to meet the needs of long-duration flights and task execution.
- **Payload Capacity:** The drone needs to be able to carry the YOLOv8 model's computing equipment, cameras, and other payloads.
- **Flight Stability:** The drone needs to have good flight stability to ensure stable flight even in complex environments, guaranteeing accurate image acquisition and object recognition.
- **Interference Resistance:** The drone needs to have strong interference resistance to cope with the impacts of severe weather, electromagnetic interference, etc.
**Selection of Drones**
Based on the above performance req

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
数据加密实战:IEC62055-41标准在电能表中的应用案例
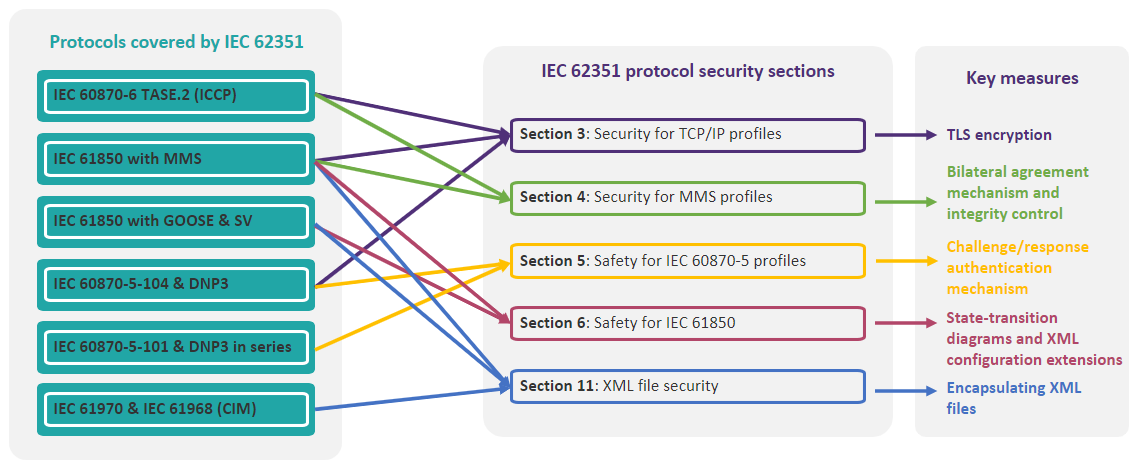
# 摘要
本文全面审视了IEC62055-41标准在电能表数据加密领域的应用,从数据加密的基本理论讲起,涵盖了对称与非对称加密算法、哈希函数以及加密技术的实现原理。进一步地,本文探讨了IEC62055-41标准对电能表加密的具体要求,并分析了电能表加密机制的构建方法,包括硬件和软件技术的应用。通过电能表加密实施过程的案例研
ZYPLAYER影视源的用户权限管理:资源安全保护的有效策略与实施

# 摘要
本文全面探讨了ZYPLAYER影视源的权限管理需求及其实现技术,提供了理论基础和实践应用的深入分析。通过研究用户权限管理的定义、目的、常用模型和身份验证机制,本文阐述了如何设计出既满足安全需求又能提供良好用户体验的权限管理系统。此外,文章还详细描述了ZYPLAYER影
TLE9278-3BQX电源管理大师级技巧:揭秘系统稳定性提升秘籍
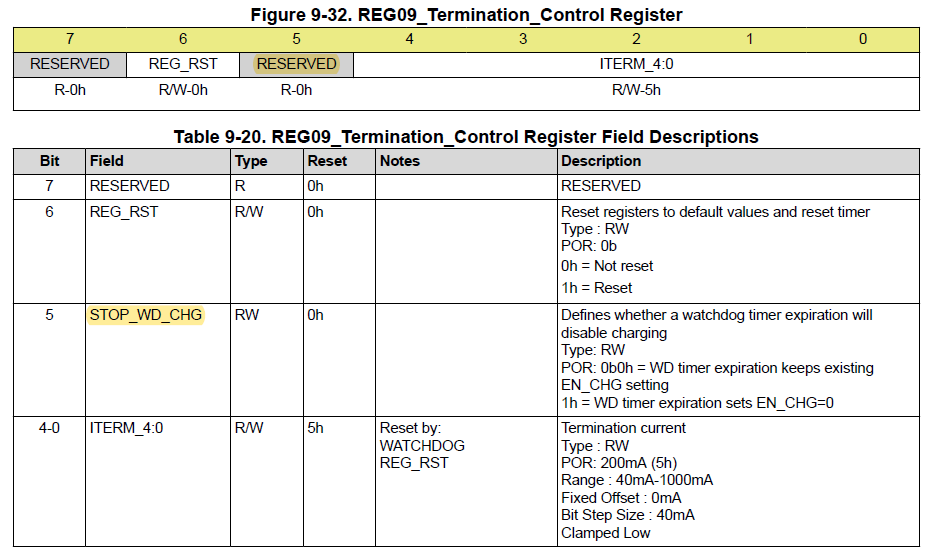
# 摘要
本文详细介绍了TLE9278-3BQX电源管理模块的功能、特性及其在电源系统中的应用。首先概述了TLE9278-3BQX的基本功能和关键特性,并探讨了其在电源系统部署时的硬件连接、软件初始化和校准过程。随后,文章深入分析了TLE9278-3BQX的高级电源管理技术,包括动态电源管理策略、故障诊断保护机制以及软件集成方法。文中
差分编码技术历史演变:如何从基础走向高级应用的7大转折点

# 摘要
差分编码技术是一种在数据传输和信号处理中广泛应用的技术,它利用差分信号来降低噪声和干扰的影响,增强通信系统的性能。本文对差分编码技术进行了全面的概述,包括其理论基础、硬件和软件实现,以及在通信系统中的实际应用。文中详细介绍了差分编码的基本概念、发展历程、数学模型,以及与通信系统的关系,特别是在无线通信和编码增益方面的应用
【汇川PLC项目搭建教程】:一步步带你从零构建专业系统
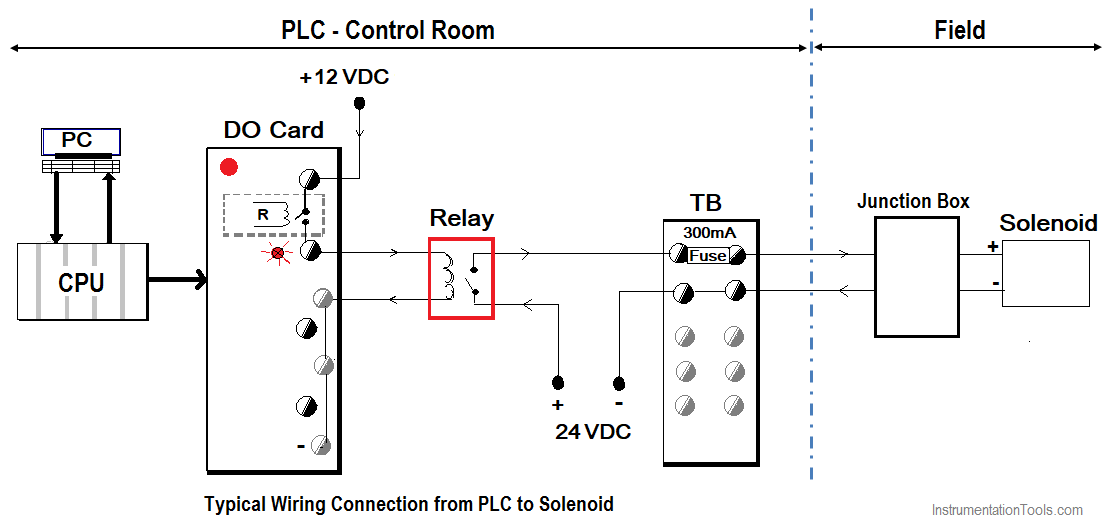
# 摘要
本文系统地介绍了汇川PLC(可编程逻辑控制器)项目从基础概述、硬件配置、软件编程到系统集成和案例分析的全过程。首先概述了PLC项目的基础知识,随后深入探讨了硬件配置的重要性,包括核心模块特性、扩展模块接口卡的选型,安装过程中的注意事项以及硬件测试与维护方法。第三章转向软件编程,讲解了编程基础、结构化设计
HyperView脚本性能优化:提升执行效率的关键技术
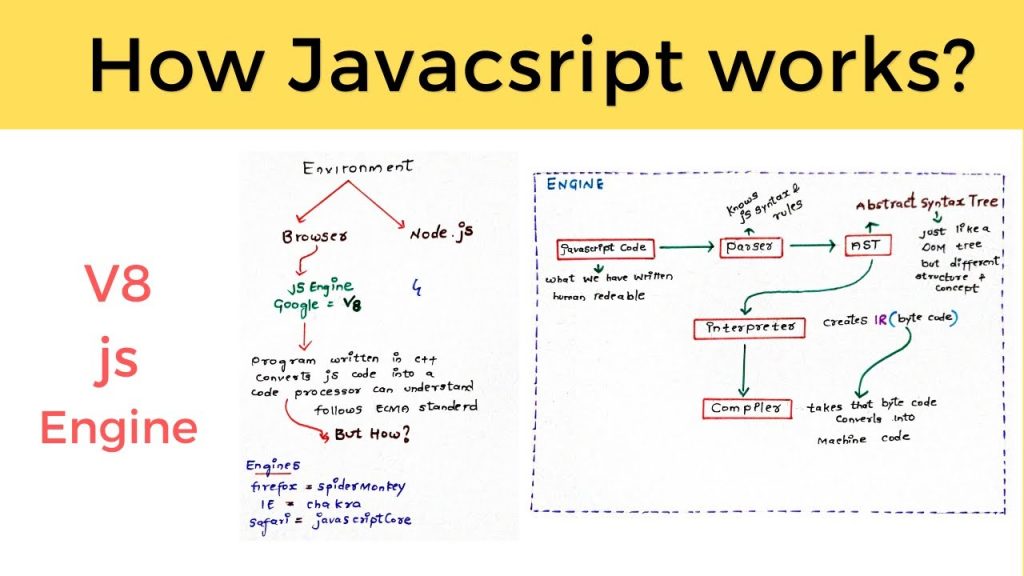
# 摘要
本文深入探讨了HyperView脚本性能优化的各个方面,从性能瓶颈的理解到优化理论的介绍,再到实践技术的详细讲解和案例研究。首先概述了HyperView脚本的性能优化必要性,接着详细分析了脚本的工作原理和常见性能瓶颈,例如I/O操作、CPU计算和内存管理,并介绍了性能监控工具的使用。第三章介绍了优化的基础理论,包括原则、数据结构和编码优化策略。在实践中,第四
【机器学习基础】:掌握支持向量机(SVM)的精髓及其应用

# 摘要
本文对支持向量机(SVM)的基本概念、理论原理、应用实践以及高级应用挑战进行了全面分析。首先介绍了SVM的核心原理和数学基础,包括线性可分和非线性SVM模型以及核技巧的应用。然后,深入探讨了SVM在分类和回归问题中的实践方法,重点关注了模型构建、超参数优化、性能评估以及在特定领域的案例应用。此外,本文还分析了SVM在处理多分类问题和大规模数据集时所面临的挑战,并讨论
ASAP3协议QoS控制详解:确保服务质量的策略与实践
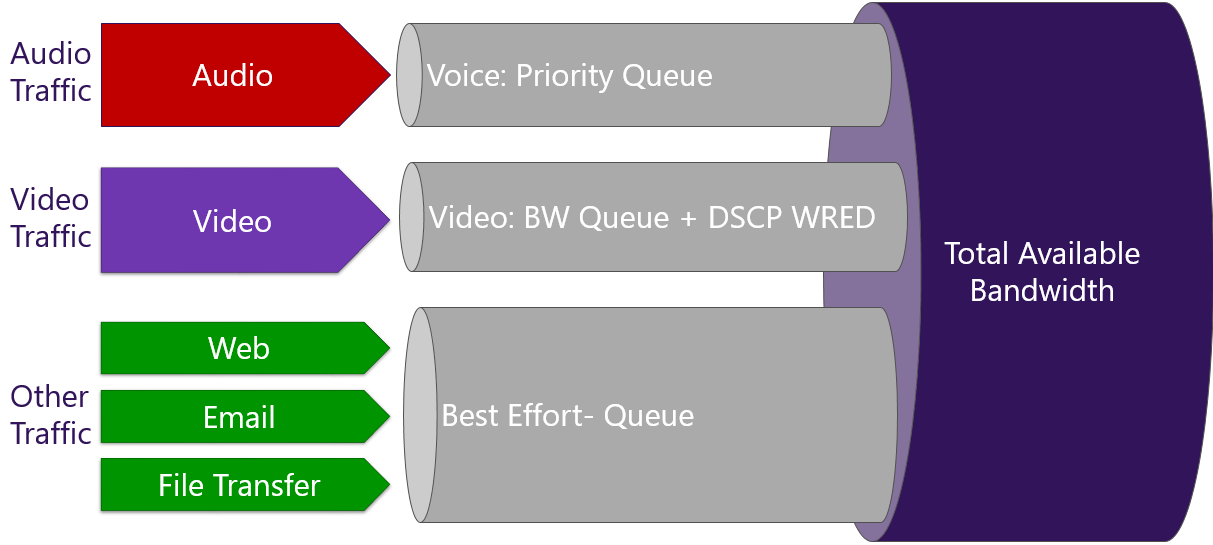
# 摘要
随着网络技术的快速发展,服务质量(QoS)成为了网络性能优化的重要指标。本文首先对ASAP3协议进行概述,并详细分析了QoS的基本原理和控制策略,包括优先级控制、流量监管与整形、带宽保证和分配等。随后,文中探讨了ASAP3协议中QoS控制机制的实现,以及如何通过消息优先级管理、流量控制和拥塞管理、服务质量保障策略来提升网络性能。在此基础上,本文提出了ASAP3协议
系统需求变更确认书模板V1.1版:确保变更一致性和完整性的3大关键步骤
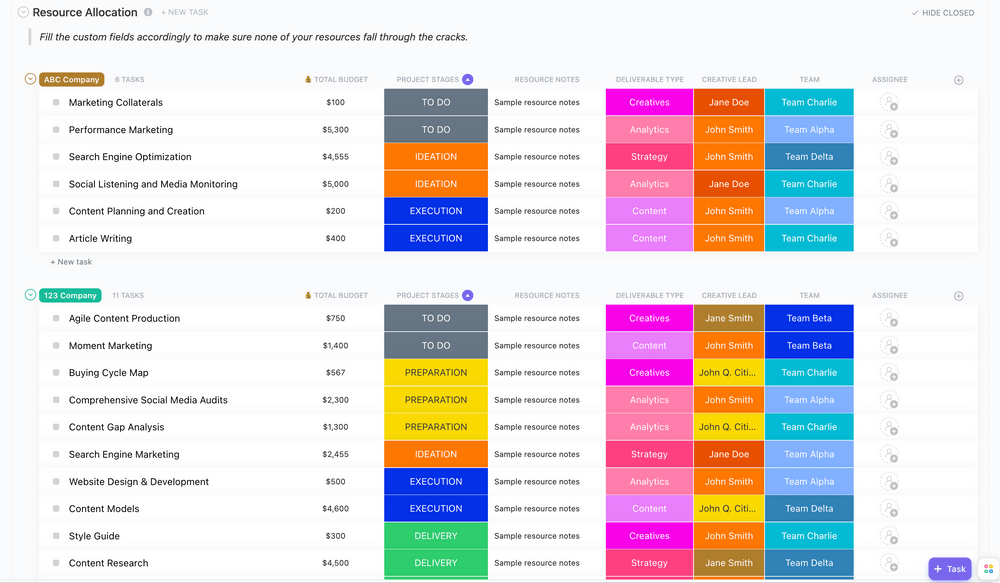
# 摘要
系统需求变更管理是确保信息系统适应业务发展和技术演进的关键环节。本文系统阐述了系统需求变更的基本概念,详细讨论了变更确认书的编制过程,包括变更需求的搜集评估、确认书的结构性要素、核心内容编写以及技术性检查。文章还深入分析了变更确认书的审批流程、审批后的行动指南,并通过案例展示了变更确认书模板的实际应用和优化建议。本文旨在
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )